对象在内存中的存储&&基本类型和包装类&&java类型转换
对象在内存中的存储
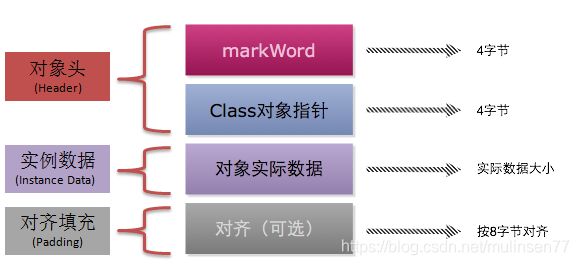
对象头、实例数据和填充数据(为了对齐)
-
实例变量:存放类的属性数据信息,包括父类的属性信息,如果是数组的实例部分还包括数组的长度,这部分内存按4字节对齐。
-
填充数据:由于虚拟机要求对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐,这点了解即可。
-
对象头:包括Mark Word和类型指针
Mark Word
Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机位长一致(4字节 32位)。
类型指针
类型指针指向对象的类元数据,虚拟机通过这个指针确定该对象是哪个类的实例。
markOop实现
HotSpot通过markOop类型实现Mark Word,具体实现位于markOop.hpp文件中。
由于对象需要存储的运行时数据很多,考虑到虚拟机的内存使用,markOop被设计成一个非固定的数据结构,以便在极小的空间存储尽量多的数据,根据对象的状态复用自己的存储空间。
markOop中提供了大量方法用于查看当前对象头的状态,以及更新对象头的数据,为synchronized锁的实现提供了基础。
在32位的HotSpot虚拟机 中对象未被锁定的状态下,Mark Word的32个Bits空间中的25Bits用于存储对象哈希码(HashCode),4Bits用于存储对象分代年龄,2Bits用于存储锁标志 位,1Bit固定为0,在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如下表所示。

对象头部分转自:https://www.jianshu.com/p/9c19eb0ea4d8
java对象的内存结构(特别详细 很细节):https://www.cnblogs.com/duanxz/p/4967042.html
八大基本类型
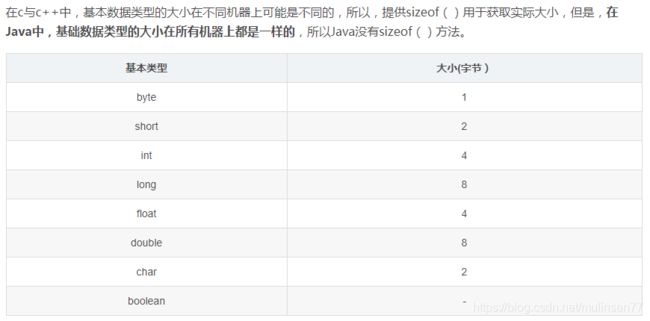
包装类
Byte Short Integer Long Float Double Character Boolean
还有两个 BigDecimal BigInteger,分别表示,(任意精度的)高精度的整型数字和高精度的定点数,不会出现精度缺失。BigDecimal可以用于货币的计算。
BigDecimal的知识详见我的另一篇文章:
《java中BigDecimalh和BigInteger详解》
为啥出现包装类:
Java是一个面向对象的语言,基本类型并不具有对象的性质,为了与其他对象“接轨”就出现了包装类型(如我们在使用集合类型Collection时就一定要使用包装类型而非基本类型),它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
关于boolean的大小:
boolean类型只有两个值:false/true;与其它的几个基本类型不同的是,在Java规范中并没有明确的给出boolean类型的大小,因为在Java虚拟机中,并没有与之对应的类型,而是使用其它的类型代替。
基本类型的默认值

如上表所示,在java中,基本类型大多默认值为0;
特殊的是:其中boolean类型的默认值为false。char默认值为null(’/uooooo’)。
另外,要注意,只有在基本类型的变量作为类成员使用的时候,java才确保给定其初始值。但是不建议使用,建议大家明确指定初始值。
在某个方法中定义的基本类型的局部变量初始值不一定是0.所以必须赋初值,否则会编译错误,告知该变量没有被初始化。
另外,引用类型的变量初始值是null。
总之:
如果是基本类型的变量,一般来说是会有默认值的,但是不安全;
如果是包装类型的变量,那么就会报错,因为没有初始值(初始值为null)。
引申的,我们来看一下基本类型和包装类的区别:
基本类型和包装类的联系和区别
联系
从Java5.0(1.5)开始,JAVA虚拟机(Java Virtual Machine)可以完成基本类型和它们对应包装类之间的自动转换。
自动装箱就是可以把一个基本类型变量赋给对应的包装类变量。自动拆箱与之相反。
包装类的特性
所有基本类型的包装类都用final关键字修饰,因此我们无法继承它们扩展新的类,也无法重写它们的任何方法。
即包装类和java.lang.String类都是不可变的类。
Boolean和Char父类是Object,剩下的六个包装类是Number类
包装类提供了基本类型变量和字符串之间的转换的方法。有两种方式把字符串类型值转换成基本类型的值:
a)利用包装类提供的**parseXxx(String s)**静态方法(除了Character之外的所有包装类都提供了该方法。)
b)利用包装类提供的Xxx(String s)构造器
String类提供了多个重载valueOf()方法,用于将基本类型变量转换成字符串,也有从字符串转化为基本类型的valueOf(String str).
两个128自动装箱后,比较它们的大小并不相等,因此Java 7增强了包装类的功能,为所有的包装类提供了一个**静态的compare(xxx val1,xxx val2)**方法,来比较两个基本类型值的大小。
Java 8再次增强包装类的功能,可以支持无符号运算。
包装类比较大小
直接上代码:
Integer a = new Integer(100);
Integer b = new Integer(100);
/* compareTo返回值:若a>b则返回1;若a==b则返回0;若a b);//false
System.out.println(a == b);//false(两个对象的==比较还要比较两个对象的地址是否一致(详见==和equals的区别:equals比较的是两个对象的内容是否相等;==比较的是对象地址))
System.out.println(a > b);//false
System.out.println(result);//输出为0
Java包装类常量池
常量池技术,又称对象池:为了一定程度上减少频繁创建对象,将一些对象保存到一个”容器”中。
常量池(包括静态常量池和运行时常量池)其实也就是一个内存空间,不同于使用new关键字创建的对象所在的堆空间。常量池中除了包含代码中所定义的各种基本类型(如int、long等等)和对象型(如String及数组)的常量值之外,还包含一些以文本形式出现的符号引用,比如:
类和接口的全限定名;
字段的名称和描述符;
方法和名称和描述符。
Java的8种基本类型(Byte, Short, Integer, Long, Character, Boolean, Float, Double), 除Float和Double以外, 其它六种都实现了常量池, 但是它们只在大于等于-128并且小于等于127时才使用常量池(-128~127之间)。
为什么是-128~127。我们来看一下Integer的valueOf方法的源码:
public static Integer valueOf(int i) {
final int offset = 128;
if (i >= -128 && i <= 127) { // must cache
return IntegerCache.cache[i + offset];
}
return new Integer(i);
}
private statintegerCache {
private IntegerCache(){}
static final Integer cache[] = new Integer[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Integer(i - 128);
}
}
String也实现了常量池技术。
String s1=new String("hello");
String s2=new String("hello");
System.out.println(s1==s2);//输出false
System.out.println(s1.equals(s2));//输入true
//s3,s4位于池中同一空间
String s3="hello";
String s4="hello";
System.out.println(s3==s4);//输出true
Integer integer = new Integer(127);
因为使用了new关键字,一定是创建了一个新的对象,无法进行缓存优化。
//常量池的测试
System.out.println("Integer的测试");
Integer a = 127;
Integer b = 127;
System.out.println(a == b); //true
a = 128;
b = 128;
System.out.println(a == b); //false
a = -128;
b = -128;
System.out.println(a == b); //true
a = -129;
b = -129;
System.out.println(a == b); //false
// 测试Boolean
System.out.println("测试Boolean");
Boolean c = true;
Boolean d = true;
System.out.println(c == d); //true
d = new Boolean(true);
System.out.println(c == d); //false
//浮点类型的包装类没有实现常量池技术
Double d1=1.0;
Double d2=1.0;
System.out.println(d1==d2)//输出false
包装类和基本类型的区别:
- 初始值的不同:见上面所述:封装类型的初始值为null(没有初始化的话,会报出NullPointException异常),基本类型的初始值为0(char为null;boolean为false);
- java中一起皆对象,但是基本类型不是对象;
- 存储位置的不同:基本类型存储在jvm的栈中,包装类的实例存储在堆中,指向其实例的引用存储在栈中。
- 声明方式的不同:包装类需要new,基本类型不需要;
- 使用方式的不同:和集合类合作使用的时候只能用包装类型,因为一些集合中的元素只能为对象,就要用到包装类型。
- (??)什么时候该用包装类,什么时候用基本类型,看基本的业务来定:这个字段允不允许null值,如果允许null值,则必然要用封装类,否则值类型就可以了,用到比如泛型和反射调用函数.,就需要用包装类!
在阿里巴巴的规范里所有的POJO类必须使用包装类型,而在本地变量推荐使用基本类型。
因为基本类型存储 简单,运算效率较高。
包装类型的加减运算
涉及到基本类型和包装类型的自动拆箱和自动装箱
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
System.out.println("i1=i2 " + (i1 == i2));//true
System.out.println("i1=i2+i3 " + (i1 == i2 + i3));//true
System.out.println("i1=i4 " + (i1 == i4));//false
System.out.println("i4=i5 " + (i4 == i5));//false
System.out.println("i4=i5+i6 " + (i4 == i5 + i6));//true
System.out.println("40=i5+i6 " + (40 == i5 + i6)); //true
语句i4 = = i5 + i6,因为+这个操作符不适用于Integer对象,首先i5和i6进行自动拆箱操作,进行数值相加,即i4 = = 40。然后Integer对象无法与数值进行直接比较,所以i4自动拆箱转为int值40,最终这条语句转为40 = = 40进行数值比较。
java类型转换
首先,boolean类型与其他基本类型不能进行类型的转换,否则将编译出错。(肯定啊 boolean类型表示的含义比较特殊(占一个字节8bit))
还有char类型本身是unsigned类型,同时具有两个字节,其数值范围是0 ~ 2^16-1,因为,这直接导致byte型不能自动类型提升到char,char和short直接也不会发生自动类型提升(因为负数的问题),同时,byte当然可以直接提升到short型。
另外,java中 未声明数据类型的整形,默认值为int型。未声明数据类型的浮点型,默认为double型。
so,傻瓜记录:long类型要在 数值后面加上L;float类型要在后面加上f。
先说一下,大的转小的:如果在小的类型范围内,就会隐式转换,但是如果数值在小的数值类型范围之外,就会报错,所以需要进行显式转换。
小的转大的,一般JVM就会自动提升(float转double精度自动变高)。
(注意特例)int到float,long到float,long到double 是不会自动转换的,不然将会丢失精度
进行数学运算的时候,数据类型会自动发生提升到运算符左右之较大者。
- 自动转换(隐式类型转换):小的转大的(byte ->short(char)->int->long->float->double):byte b1=12; int a=b1*2;//byte类型自动转为int类型
- 强制转换(显式类型转换):大的转小的:可能会丢失精度
byte a=3;//3是常量,直接量,编译期间可以直接进行判定
int b=233;
byte c=b;//报错,需要进行强制类型转换。b是变量,变量是在 运行期间才确定的,编译期间以防万一,不可通过
byte d=(byte) b;//d不是233,而是-23.
//解释一下原因:233的二进制表示为:24位0 + 11101001,byte型只有8位,于是从高位开始舍弃,截断后剩下:11101001,由于二进制最高位1表示负数,0表示正数,其相应的负数为-23。
- 包装器过渡类型转换
- 字符串和其他类型之间的转换
- Date和其他数据 类型之间的转换
//3.包装器过渡转换
String s = "123";
int value = Integer.parseInt(s); //方法返回int值,赋给value
String str1 = "123";
int value1 = Integer.valueOf(str1); //valueOf是返回的Integer类型,结果是int 123
//4.字符串和其他类型的转换
int num = 2017;
String time= ""+num; //右边最终结果是String
//5.Date与其他数据类型的相互转换
Date date = new Date();
SimpleDateFormat format = new SimpleDateFormat("yyyyMMDD");
String timeString = format.format(date);
valueof和parseInt的区别 :
从返回类型可以看出parseInt返回的是基本类型int,而valueOf返回的是对象。
valueOf的内部其实就是调用了parseInt方法。
JDK5以后实现了自动拆装箱,因而两者的差别也不是特别大了,但是从效率上考虑,建议首先考虑parseInt方法。
类型转换中的符号扩展Sign Extension
先说一下在java中的负数表示的方法。
为了把减法当成加法来计算,我们采用补码 的形式表示负数。
负数的补码如何 获取:正数的二进制的最高位取1;取反码:各位取反;加1。得到补码。
举个简单的例子,一个byte型数据,它在计算机中占8位,-7可以表示为10000111,最高位的1代表负号,它的反码是除去符号位各位取反为11111000,然后加1得到补码11111001。8的二进制表示为00001000,现在我们运算8 - 7,在计算机并不是用8减去7,而是用8 + (-7),也就是用00001000加上-7的补码11111001,两个有符号数相加,如果符号位相加有近位就删去符号位的进位,得到00000001,也就是1.
符号扩展(Sign Extension)用于在数值类型转换时扩展二进制位的长度,以保证转换后的数值和原数值的符号(正或负)和大小相同,一般用于较窄的类型(如byte)向较宽的类型(如int)转换。
符号扩展:对于正数来讲,在前面补0; 负数时在前面补1。比如8位的二进制数10000111扩展为16位,我们在前面加上8个1,1111111110000111;如果是正数,则在前面补0。这样进行扩展后,符号和数值的大小都不变。
举例说明:
-
byte型转为char型
因为byte是有符号类型,再转成char型时需要进行符号位扩展,如果是正数就在前面不上8个0, 如果是负数就在前面补上8个1。例如11111111(0xff)左边连续补上8个1结果是0xffff。因为char是无符号类型,所以0xffff表示的十进制数是65535。 -
char型转为int型
因为char是无符号类型,转换成int型时进行在前面补上16个0,用十进制表示结果为结果0x0000ffff,对应的十进制数是65535。 -
int型转为byte型
因为int是32位,而byte类型值只占8位,直接截取最后8位。例如-1的补码为0xffffffff,转换为byte型后为0xff,值为-1。
《Java解惑》:如果最初的数值类型是有符号的,那么就执行符号扩展;如果是char类型,那么不管它要被转换成什么类型,都执行零扩展。还有另外一条规则也需要记住,如果目标类型的长度小于源类型的长度,则直接截取目标类型的长度。例如将int型转换成byte型,直接截取int型的右边8位。
多重转型
例如:int n=(int)(char)(byte)-1;
整个转换过程如下:
1.int(32位)->byte(8位)
-1是int型的字面量,根据“2的补码”编码规则,编码结果为0xffffffff,即32位全部置1.转换成byte类型时,直接截取最后8位,所以byte结果为0xff,对应的十进制值是-1.
2.byte->char(16位)
由于byte是有符号类型,所以在转换成char型(16位)时需要进行符号扩展,即在0xff左边连续补上8个1(1是0xff的符号位),结果是0xffff。由于char是无符号类型,所以0xffff表示的十进制数是65535。
3.char->int(32位)
由于char是无符号类型,转换成int型时进行零扩展,即在0xffff左边连续补上16个0,结果是0x0000ffff,对应的十进制数是65535。
其他:
几个转型的例子
在进行类型转换时,一定要了解表达式的含义,不能光靠感觉。最好的方法是将你的意图明确表达出来。
在将一个char型数值c转型为一个宽度更宽的类型时,并且不希望有符号扩展,可以如下编码:
![]()
上文曾提到过,0xffff是int型字面量,所以在进行&操作之前,编译器会自动将c转型成int型,即在c的二进制编码前添加16个0,然后再和0xffff进行&操作,所表达的意图是强制将前16置0,后16位保持不变。虽然这个操作不是必须的,但是明确表达了不进行符号扩展的意图。
如果需要符号扩展,则可以如下编码:
![]()
首先将c转换成short类型,它和char是 等宽度的,并且是有符号类型,再将short类型转换成int类型时,会自动进行符号扩展,即如果short为负数,则在左边补上16个1,否则补上16个0.
如果在将一个byte数值b转型为一个char时,并且不希望有符号扩展,那么必须使用一个位掩码来限制它:
![]()
(b & 0xff)的结果是32位的int类型,前24被强制置0,后8位保持不变,然后转换成char型时,直接截取后16位。这样不管b是正数还是负数,转换成char时,都相当于是在左边补上8个0,即进行零扩展而不是符号扩展。
如果需要符号扩展,则编码如下:注意要写注释。
![]()
部分转自:https://blog.csdn.net/u011480603/article/details/75364931
类型转换部分,转自:https://www.cnblogs.com/liujinhong/p/6005714.html
符号扩展 部分转自:https://blog.csdn.net/msg1122/article/details/80485793