数学建模3 插值算法
数模比赛中,常常需要根据已知的函数点进行数据、模型的处理和分析,而有时候现有的数据是极少的,不足以支撑分析的进行,这时就需要使用一些数学的方法,“模拟产生”一些新的但又比较靠谱的值来满足需求,这是就需要插值法。
插值法是数值分析中最基本的方法之一。 在实际问题中遇到的函数是许许多多的,有的甚至给不出表达式,只供给了一些离散数据,例如,在查对数表时,需要查的数值在表中却找不到,所以只能先找到它相邻的数,再从旁边找出它的更正值,按一定的关系把相邻的数加以更正,从而找出要找的数,这种更正关系事实上就是一种插值。在实际应用中,采用不同的插值函数,逼近的效果也不同。有五种基本的插值方法,有拉格朗日插值、牛顿插值、分段线性插值、分段三次埃尔米特插值和样条插值函数。
一、一维插值问题
问题如下:已经有n+1个节点(xi,yi)(i=0,1,…n)其中xi互不相同,不妨假设a=x0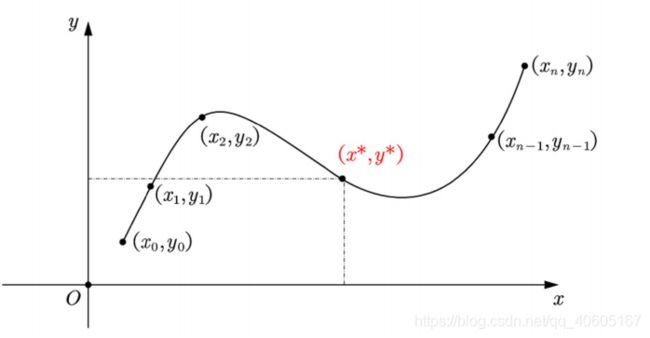
思路:只需构造出函数fx,使得fx经过所有节点*,把x*代入fx函数中,即可得到y**。
通过上题思路,我们可以简单理解插值法定义。
插值法定义:

二、插值法分类
一般分为分段插值,插值多项式,三角插值。
三、插值法原理

多项式经过n+1个点,就可以写出n+1个等式,解方程组就要把这些系数写成矩阵的形式,A就是系数矩阵。A如果可逆有唯一解,即A的行列式不得0,A为范德蒙德行列式,满足可逆。

四、拉格朗日插值法
两个点的:

三个点的:

四个点的:


拉格朗日插值法存在的问题:龙格现象
龙格现象:插值多项式次数越高误差越小吗?

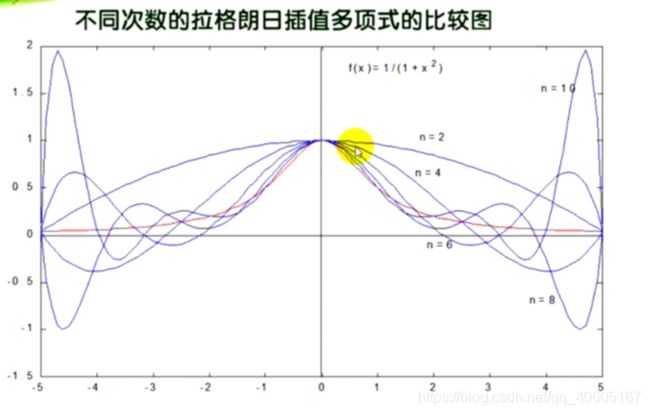
高次插值会产生龙格现象,即在两端处波动较大,产生明显的震荡。在不熟悉曲线运动趋势的前提下,不要轻易使用高次插值。
由以上可得,插值多项式次数高,精度未必显著提高。那么如何提高插值精度呢?因为存在龙格现象,所以采用分段线性插值来解决。
五、分段插值
1、分段线性插值
对于一个多项式的点,我们先找距离这个横坐标最近的两个点,然后这两个点连成一个线。然后根据横坐标的点,找到线上纵坐标的点。一般我们常用分段二次插值或者分段三次插值。
2、分段二次插值
选取跟节点x最近的三个节点xi-1,xi,xi+1进行二次插值。即在每一个区间[xi-1,xi+1]上,取:

这种分段的低次插值称为分段二次插值,在几何上就是用分段抛物线代替y=f(x),故分段二次插值又称为分段抛物插值。
3、牛顿插值法
评价:
与拉格朗日插值法相比,牛顿插值法的计算过程具有继承性,牛顿插值法每次插值只和前面n项的值有关,这样每次只要在原来的函数上添加新的项,就能够产生新的函数,但是牛顿插值也存在龙格现象。
总结:


以上两种插值法的缺点:1.存在龙格现象,2.上面的两种插值仅仅要求插值多项式在插值点处与被插函数有相等的函数值,而这种插值多项式却不能全面反映被插值函数的形态,在实际问题种,不仅仅要求被插函数和插值函数在所有节点处有相同的函数值,也需要在一个或全部节点上插值多项式与被插值函数有相同的低阶或者高阶的导数值。然而牛顿法和拉格朗日插值法都不能满足。
4、埃尔米特插值

一般插值的要求是函数值要求,但是更高级的插值法的要求是导数值也要对应起来。甚至要求高阶导数值也相等。满足这种要求的插值多项式就是埃尔米特插值多项式。导数值对应起来的原因是保持插值曲线在节点处有切线,也就是保证曲线光滑,使插值函数和被插值函数的密和程度更好。

直接使用埃尔米特插值得到的多项式次数较高,也存在着龙格现象,因此在实际应用中,往往使用分段三次埃尔米特插值多项式。
分段三次埃尔米特插值,就是找四个点分段三次。
matlab有内置的函数:
p=pchip(x,y,new_x)
x是已知的样本点的横坐标,y是已知的样本点的纵坐标;new_x是要插入处对应的横坐标。new_x是要插入处对应的横坐标。
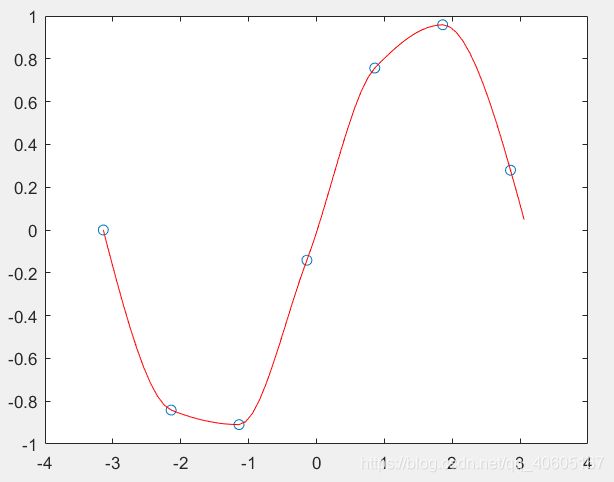
例如:
x=-pi:pi;
y=sin(x);
new_x=-pi:0.1:pi;
p=pchip(x,y,new_x);
plot(x,y,'o',new_x,p,'r-')
绘制图像如下:
5、三次样条插值

由上可知:需要S(x)是一个三次多项式。还要求S(x)上二阶连续可微。

matlab里面的内置函数为:spline
p=spline(x,y,new_x)
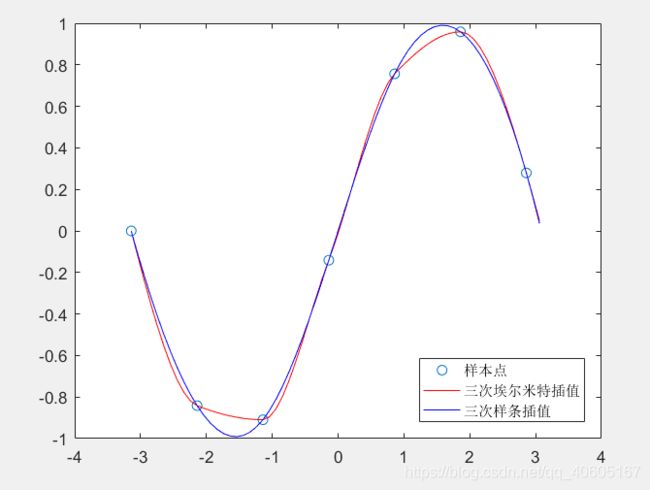
% 三次样条插值和分段三次埃尔米特插值的对比
x = -pi:pi;
y = sin(x);
new_x = -pi:0.1:pi;
p1 = pchip(x,y,new_x); %分段三次埃尔米特插值
p2 = spline(x,y,new_x); %三次样条插值
figure(2);
plot(x,y,'o',new_x,p1,'r-',new_x,p2,'b-')
legend('样本点','三次埃尔米特插值','三次样条插值','Location','SouthEast') %标注显示在东南方向
% 说明:
% LEGEND(string1,string2,string3, ⋯)
% 分别将字符串1、字符串2、字符串3⋯⋯标注到图中,每个字符串对应的图标为画图时的图标。
% ‘Location’用来指定标注显示的位置
结果如下:
n维数据的插值:

% n维数据的插值
x = -pi:pi; y = sin(x);
new_x = -pi:0.1:pi;
p = interpn (x, y, new_x, 'spline');
% 等价于 p = spline(x, y, new_x);
figure(3);
plot(x, y, 'o', new_x, p, 'r-')
举例
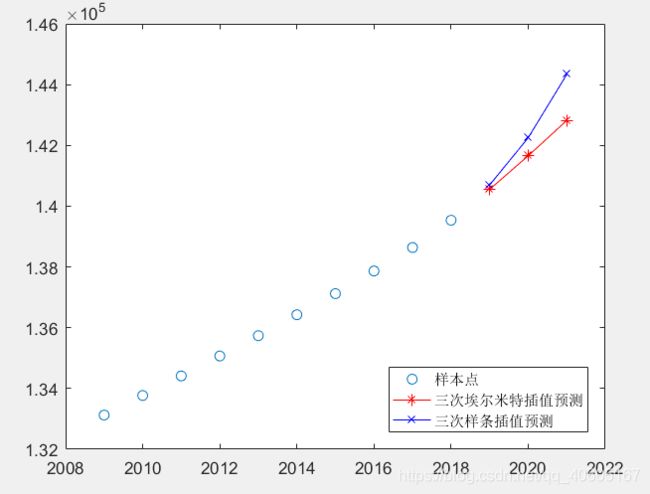
根据过去10年的中国人口数据,预测接下来三年的人口数据:
population=[133126,133770,134413,135069,135738,136427,137122,137866,138639, 139538];
% 人口预测
population=[133126,133770,134413,135069,135738,136427,137122,137866,138639, 139538];
year = 2009:2018;
p1 = pchip(year, population, 2019:2021) %分段三次埃尔米特插值预测
p2 = spline(year, population, 2019:2021) %三次样条插值预测
figure(4);
plot(year, population,'o',2019:2021,p1,'r*-',2019:2021,p2,'bx-')
legend('样本点','三次埃尔米特插值预测','三次样条插值预测','Location','SouthEast')
plot函数用法:
% plot函数用法:
% plot(x1,y1,x2,y2)
% 线方式: - 实线 :点线 -. 虚点线 - - 波折线
% 点方式: . 圆点 +加号 * 星号 x x形 o 小圆
% 颜色: y黄; r红; g绿; b蓝; w白; k黑; m紫; c青
建模实例:
MathorCup第六届A题 淡水养殖池塘水华发生及池水净化处理
附件一给的是1-15周数据,附件二给的是奇数1,3,5,…,15周数据

上面是数据,附件一中给出的是15周的数据,而附件二给出的是奇数十五周的数据。数据是不对称的。最好的方法是将附件二中缺失的值使用插值算法插进去,使得附件二的数据也是15周。
答案代码:
%插值预测中间周的水体评价指标
load Z.mat
x=Z(1,:); %Z的第一行是星期Z: 1 3 5 7 9 11 13 15
[n,m]=size(Z);%n为Z的行数,m为Z的列数
% 注意Matlab的数组中不能保存字符串,如果要生成字符串数组,就需要使用元胞数组,其用大括号{
}定义和引用
ylab={
'周数','轮虫','溶氧','COD','水温','PH值','盐度','透明度','总碱度','氯离子','透明度','生物量'}; % 等会要画的图形的标签
disp(['共有' num2str(n-1) '个指标要进行插值。'])
disp('正在对一号池三次埃尔米特插值,请等待')%一号池共有十一组要插值的数据,算上星期所在的第一行,共十二行
P=zeros(11,15);%对要储存数据的矩阵P赋予初值
for i=2:n%从第二行开始都是要进行插值的指标
y=Z(i,:);%将每一行依次赋值给y
new_x=1:15;%要进行插值的x
p1=pchip(x,y,new_x);%调用三次埃尔米特插值函数
subplot(4,3,i-1);%将所有图依次变现在4*3的一幅大图上
plot(x,y,'ro',new_x,p1,'-');%画出每次循环处理后的图像
axis([0 15,-inf,inf]) %设置坐标轴的范围,这里设置横坐标轴0-15,纵坐标不变化
% xlabel('星期')%x轴标题
ylabel(ylab{
i})%y轴标题 这里是直接引用元胞数组中的字符串哦
P(i-1,:)=p1;%将每次插值之后的结果保存在P矩阵中
end
legend('原始数据','三次埃尔米特插值数据','Location','SouthEast')%加上标注,注意要手动在图中拖动标注到图片右下角哦
P = [1:15; P] %把P的第一行加上周数