Python 网络爬虫——爬取小说网站
Python 网络爬虫实战——爬取小说网站
首先我们需要import requests这个模块,通过requests这个模块获取url数据。我这里获取的是一个盗版小说网站笔趣看中斗罗大陆第一章节的数据,先将网站字符串赋给target然后通过requests.get方法获取url,然后通过content方法直接获取bytes类型的原始网页数据,如果是使用text方法则获取到的为经过Unicode编码的数据,经过Unicode编码的数据在pycharm控制台会出现乱码的情况,所以还是建议直接获取原始数据。
import requests
def climb():
target = 'https://www.biqukan.net/book/121650/43344227.html'
rq = requests.get(url=target)
htmlc = rq.content
htmlt = rq.text
print("原始数据:{}".format(htmlc))
print("经过Unicode编码后的数据:{}".format(htmlt))
climb()
运行结果:

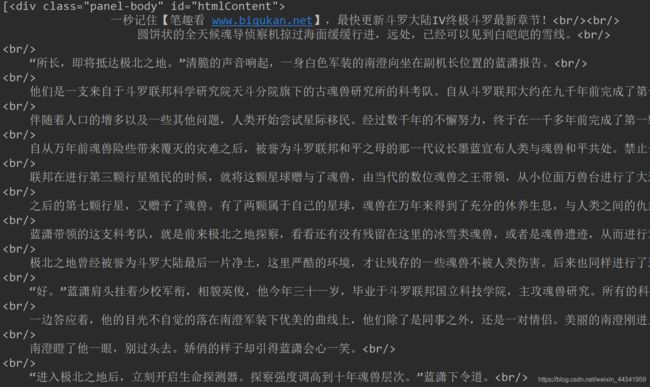
我们可以看到原始数据是bytes传入的,而后面的数据则是通过Unicode编码之后传入的,bytes类型的很难进行阅读,但是对后面的数据处理却是有非常大的遍历。接下来我们要进行的就是对通过requests获取的数据的处理,我们先去install一个专门用来处理网页数据的模块bs4,,直接通过pip安装或者通过pycharm设置中搜索安装都是可以的。然后将这个包import进来,from bs4 import BeautifulSoup,通过BeautifulSoup我们可以解析网页数据,比如说只将html中div中属于某个class的内容输出来。下图是笔趣看中斗罗大陆第一章节的网页源码,我们通过BeautifulSoup中find_all方法找到属于div且属于panel-body这个class的内容,panel-body是正文的内容。
import requests
from bs4 import BeautifulSoup
def climb():
target = 'https://www.biqukan.net/book/121650/43344227.html'
rq = requests.get(url=target)
html = rq.content
bs = BeautifulSoup(html)
details = bs.find_all('div', class_='panel-body')
print(details)
climb()
运行结果:

出现的红字警告是因为你解析数据的时候没有指定解析器,如果想要没有这条警告,可以通过pip安装html5lib这个模块,然后在解析的时候指定解析器为html5lib
import requests
from bs4 import BeautifulSoup
def climb():
target = 'https://www.biqukan.net/book/121650/43344227.html'
rq = requests.get(url=target)
html = rq.content
bs = BeautifulSoup(html, 'html5lib')
details = bs.find_all('div', class_='panel-body')
print(details)
climb()
运行结果:
可以发现这样一来就没有警告了,这样网页的初步爬取就已经完成了,我们要做的第二步就是将爬取解析之后的一些标签去掉,去掉标签最简单的方法就是用replace方法将标签代替掉,br标签可以使用回车代替。不难发现我们通过find_all得到的是一个列表,而这个列表只有一项,知道这个之后我们可以通过replace方法来将第一项中的br标签用回车代替。还有一个简单的办法就是使用text方法直接提取文本。
import requests
from bs4 import BeautifulSoup
def climb():
target = 'https://www.biqukan.net/book/121650/43344227.html'
rq = requests.get(url=target)
html = rq.content
bs = BeautifulSoup(html, 'html5lib')
details = bs.find_all('div', class_='panel-body')
print(details[0].text)
climb()
运行结果:

同样的方法我们可以从章节页获取所有章节,每个章节都是相同的class,然后通过每个章节的超链接从每个章节中获取文本。
import requests
from bs4 import BeautifulSoup
def climb():
target = "https://www.biqukan.net/book/121650/"
rq = requests.get(url=target)
html = rq.content
bs = BeautifulSoup(html, 'html5lib')
details = bs.find_all('dd', class_='col-md-3')
with open('test.text', 'a', encoding='utf-8') as f:
f.write("斗罗大陆IV终极斗罗\n")
i = 0
for d_each in details:
i += 1
a_buff = BeautifulSoup(str(d_each), 'html5lib')
a = a_buff.find_all('a')
if a:
f.write(a[0].string + '\n')
rq_buf = requests.get(url=target + a[0].get('href'))
text_1 = BeautifulSoup(rq_buf.content, 'html5lib').find_all('div', class_='panel-body')[0].text
text_buf = text_1.replace(" ", "")
text_buf = text_buf.replace("\n", "")
if text_buf[-4:] == "继续阅读":
rq_buf2 = requests.get(url=(target + a[0].get('href').replace(".html", "") + '_2.html'))
text_all = text_1 + BeautifulSoup(rq_buf2.content, 'html5lib').find_all('div', class_='panel-body')[0].text
f.write(text_all + '\n\n')
print("下载进度:%.3f%%" % float(i/len(details)))
climb()