GoogLeNet论文详解
原文地址:
https://arxiv.org/pdf/1409.4842.pdf
论文研究目标:
利用赫布理论和多尺度处理直觉设计一种增加深度和宽度的提高内部计算资源利用率的(同时保持了计算预算不变)网络。
传统提神网络性能的方法和缺点:
最简单的CNN性能提升办法是增大网络的depth和width,这里的width指的是每一层的神经元数量。这种方式要两个缺点:
1.增加网络参数数量会增加过拟合的风险;
2.其次,增加参数数量增加了计算量。
从传统提升方法上得到的感悟:
提高网络计算资源的有效分布优于盲目增加网络的大小。
避开传统方法缺点的方法:
用稀疏层代替全连接层(甚至连卷积层也可以替代):
这个方案是对生物系统的一种模仿,同时由于Arora等人[2]的开创性工作,这也具有更坚固的理论基础优势。他们的主要成果说明如果数据集的概率分布可以通过一个大型稀疏的深度神经网络表示,则最优的网络拓扑结构可以通过分析前一层激活的相关性统计和聚类高度相关的神经元来一层层的构建。虽然严格的数学证明需要在很强的条件下,但事实上这个声明与著名的赫布理论产生共鸣——神经元一起激发,一起连接——实践表明,基础概念甚至适用于不严格的条件下。(一起激发,一起连接,我的理解是,神经元传递信息可能不是简单的复制逐层传递,而是并行的同时传递,并行的、大宽度的结构也是神经网络稀疏性的一种表示)。
稀疏数据机构上的计算效率是个问题:
当碰到在非均匀的稀疏数据结构上进行数值计算时,现在的计算架构效率非常低下。即使算法运算的数量减少100倍,查询和缓存丢失上的开销仍占主导地位:切换到稀疏矩阵可能是不可行的。数值库要求极度快速密集的矩阵乘法,随着稳定提升和高度调整的数值库的应用,差距仍在进一步扩大,利用底层的CPU或GPU硬件[16, 9]的微小细节。非均匀的稀疏模型也要求更多的复杂工程和计算基础结构。
从传统方法的缺点和解决办法的难处提出新解决方案:
提出一个架构能利用滤波器水平的稀疏性,正如理论所认为的那样,但能通过利用密集矩阵计算来利用我们目前的硬件。
Inception架构设计前的思考
根据上述分析,我们已经很明确我们需要设计一个什么样的架构了:
考虑怎样近似卷积视觉网络的最优稀疏结构(卷积核的多数量并行,它们得到的结果是一个稀疏结构,这也就是结构稀疏性的体现)并用容易获得的密集组件(一个个的卷积核就是密集组件)进行覆盖。
用什么来构建我们的模块,卷积:
根据平移不变性,这意味着我们的网络将以卷积构建块为基础。我们所需要做的是找到最优的局部构造并在空间上重复它。
并行使用的卷积块的尺寸选择的方法:
我们使用不用大小尺寸的卷积块,这其实是为了覆盖不同大小的特征单元的聚类。我们假设较早层的每个单元都对应输入层的某些区域,并且这些单元被分成滤波器组。在较低的层(接近输入的层)相关单元集中在局部区域。因此,如[12]所示,我们最终会有许多聚类集中在单个区域,它们可以通过下一层的1×1卷积层覆盖。然而也可以预期,将存在更小数目的在更大空间上扩展的聚类,其可以被更大块上的卷积覆盖,在越来越大的区域上块的数量将会下降。为了避免块校正的问题,目前Inception架构形式的滤波器的尺寸仅限于1×1、3×3、5×5,这个决定更多的是基于便易性而不是必要性。
直观上分析就能得出的一个设计思想:
由于这些“Inception模块”在彼此的顶部堆叠,其输出相关统计必然有变化:由于较高层会捕获较高的抽象特征,其空间集中度预计会减少。这表明随着转移到更高层,3×3和5×5卷积的比例应该会增加。
Inception结构的设计过程:
1.作者也是根据理论假设了Inception结构,对输入数据进行1*1,3*3,5*5的卷积,将各自的卷积结构连接构成下一层的输入。同时由于polling操作的必要性,进行了并行的polling操作,结果也合并到3个卷积的输出中构成整体的输出。这就是naive版本的Inception结构。
该设计的合理性:
设计遵循了实践直觉,即视觉信息应该在不同的尺度上处理然后聚合,为的是下一阶段可以从不同尺度同时抽象特征。
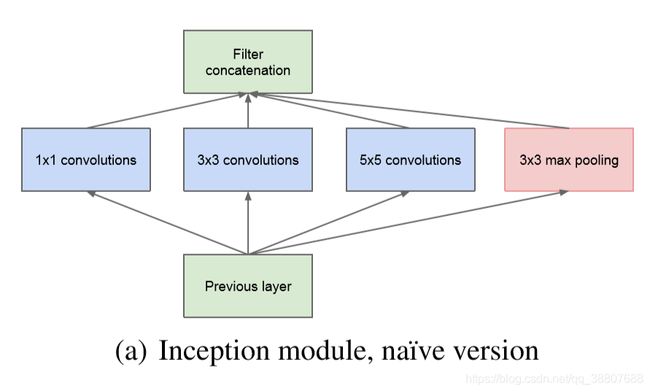
缺点分析:
上述实现方式的问题就是计算量大,即使当前Inception结构的输入数据的channel数大小适中,进行一个大规模卷积核的5*5的卷积操作的计算量依然很大,并且池化操作的输出channel和输入相同,这样进行合并操作之后,输出的channel数肯定会增加,这样逐层增加会显著增加计算量,降低模型的使用效率。
2.改进设计(使用NiN):
根据上述存在的问题,需要对inception结构进行降维操作,办法就是在3*3和5*5的卷积之前使用1*1的卷积(NiN)操作,这样做一方面减少了参数,同时使用了更多的激活函数,增加了非线性表达能力。进行降维和升维引起人们重视的(可能)是在GoogLeNet里。
使用NiN应该注意的一点:
bottleneck layer以密集、压缩形式表示信息并且压缩信息更难处理。这种表示应该在大多数地方保持稀疏并且仅在它们必须汇总时才压缩信号。也就是说,在昂贵的3×3和5×5卷积之前,1×1卷积用来计算降维。
使用1*1卷积的思想由来:
这个思想被叫做“bottleneck layer”,主要意思是减小计算量,防止计算瓶颈的产生。Network-in-Network是Lin等人为了增加神经网络表现能力而提出的一种方法。在他们的模型中,网络中添加了额外的1 × 1卷积层,增加了网络的深度。我们的架构中大量的使用了这个方法。实际上,Bottleneck layer已经在ImageNet数据集上表现非常出色,并且也将在稍后的架构例如ResNet中使用到。
我们使用NiN的目的:
1.和"bottleneck layer"的目的一样,作为降维模块来移除卷积瓶颈,否则将会限制我们网络的大小。
2.允许我们增加网络的深度的同时没有明显的性能损失(通过增加网络的宽度,即卷积核种类数)。
该方法成功的原因解释:
输入特征是相关的,因此可以通过适当地与1x1卷积组合来去除冗余。
举例分析该设计的好处:
假设输入时256个feature map进来,256个feature map输出,假设Inception层只执行3x3的卷积,那么这就需要执行 (256x256) x (3x3) 次乘法(大约589,000次计算操作)。现在Bottleneck layer的思想是先来减少特征的数量,我们首先执行256 -> 64 的1×1卷积,然后在所有Bottleneck layer的分支上对64大小的feature map进行卷积,最后再64 -> 256 1x1卷积。
操作量是:
256×64 × 1×1 = 16,384 64x1x1卷积核对上一层输出卷积计算
64×256 × 3×3= 147456 256x3x3卷积核对1x1卷积输出进行卷积计算
总共约163840,而我们以前有近600,000。减少3倍多的操作。
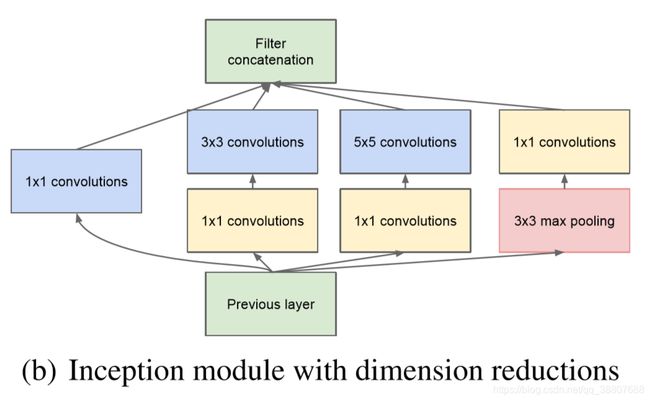
暂时未解决的一个小缺陷:
出于技术原因(训练过程中内存效率),只在更高层开始使用Inception模块而在更低层仍保持传统的卷积形式似乎是有益的。这不是绝对必要的,只是反映了我们目前实现中的一些基础结构效率低下。
3.改进设计(去掉全连接):
我们发现从全连接层变为平均池化,提高了大约top-1 %0.6的准确率,然而即使在移除了全连接层之后,droupout我们还是使用了的。
4.改进设计(添加辅助分类器):
添加理由:
更浅网络的强大性能表明网络中部层产生的特征应该是非常有识别力的
添加目的:
通过将辅助分类器添加到这些中间层,可以期望较低阶段分类器的判别力。
实际做法:
这些分类器采用较小卷积网络的形式,放置在Inception (4a)和Inception (4b)模块的输出之上。在训练期间,它们的损失以折扣权重(辅助分类器损失的权重是0.3)加到网络的整个损失上。在推断时,这些辅助网络被丢弃。后面的控制实验表明辅助网络的影响相对较小(约0.5),只需要其中一个就能取得同样的效果。
添加后的效果:
1.克服了梯度消失
2.提供正则化
5.最终使用的实例架构:
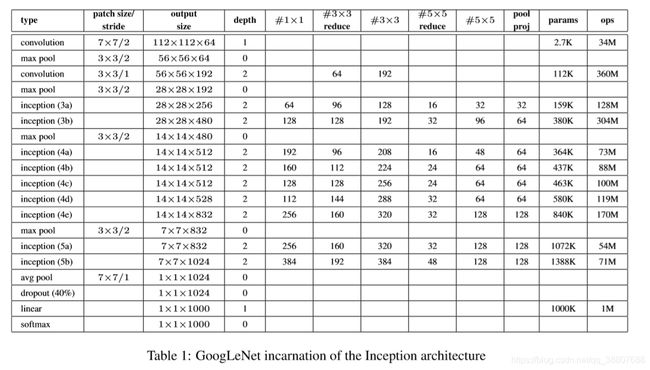
1.所有的卷积都使用了修正线性激活,包括Inception模块内部的卷积。
2.在我们的网络中感受野是在均值为0的RGB颜色空间中,大小是224×224。
3.“#3×3 reduce”和“#5×5 reduce”表示在3×3和5×5卷积之前的降维层使用的1×1滤波器的数量。而"1x1"表示单独的1x1卷积层.
4.在pool proj列可以看到内置的最大池化之后,投影层中1×1滤波器的数量。所有的这些降维/投影层也都使用了线性修正激活。
5.分类器之前的平均池化是基于[12]的,尽管我们的实现有一个额外的线性层。线性层使我们的网络能很容易地适应其它的标签集,但它主要是为了方便使用,我们不期望它有重大的影响。
6.网络最后采用了average pooling来代替全连接层,想法来自NIN, 事实证明可以将TOP1 accuracy提高0.6%。
6.但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家微调; (不是全局平均池化)
7.然而即使在移除了全连接层之后,dropout的使用还是必不可少的。
8.显然GoogLeNet采用了模块化的结构,方便增添和修改;
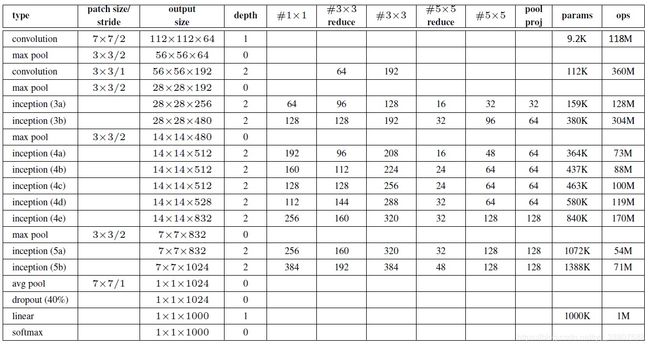
一个小问题:
论文中的参数量有问题,单看第一行的参数量就应该是64*7*7*3=9408。
正确参数与计算量应该是:
6.辅助网络的结构:
1.一个滤波器大小5×5,步长为3的平均池化层,导致(4a)阶段的输出为4×4×512,(4d)的输出为4×4×528。
2.具有128个滤波器的1×1卷积,用于降维和修正线性激活。
3.一个全连接层,具有1024个单元和修正线性激活。
4.丢弃70%输出的丢弃层。
5.使用带有softmax损失的线性层作为分类器(作为主分类器预测同样的1000类,但在推断时移除)。
7.完整网络架构图示:

Inception网络训练过程:
训练方法:
我们的训练使用异步随机梯度下降,动量参数为0.9[17],固定的学习率计划(每8次遍历下降学习率4%)。
数据预处理:
各种尺寸的图像块的采样,它的尺寸均匀分布在图像区域的8%——100%之间,方向角限制为[3/4,4/3]之间。另外,光度扭曲对于克服训练数据成像条件的过拟合是有用的。
Inception网络在分类赛上使用的技巧:
1.多模型预测:
我们独立训练了7个版本的相同的GoogLeNet模型(包括一个更广泛的版本),并用它们进行了整体预测。这些模型的训练具有相同的初始化(甚至具有相同的初始权重,由于监督)和学习率策略。它们仅在采样方法和随机输入的图像顺序方面不同。
2.采用更复杂的裁剪方法:
我们将图像归一化为四个尺度,其中较短维度(高度或宽度)分别为256,288,320和352,取这些归一化的图像的左,中,右方块(在肖像图片中,我们采用顶部,中心和底部方块),对于每个方块,我们将采用以下6种调整结果:
4个角延伸的
从中心延伸的224×224裁剪图像
重塑形到224×224方块的图像
以上图像的镜像版本
这导致每张图像会得到 4(四个尺度)×3(三个原始块)×6(六种调整结果)×2(镜像处理) = 144 的裁剪图像。前一年的输入中,Andrew Howard[8]采用了类似的方法,经过我们实证验证,其方法略差于我们提出的方案。我们注意到,在实际应用中,这种过分裁剪可能是不必要的,因为存在合理数量的裁剪图像后,更多裁剪图像的好处会变得很微小(正如我们后面展示的那样)。
欢迎批评指正,讨论学习~
最近在github放了两份分类的代码,分别是用Tensorflow和Pytorch实现的,主要用于深度学习入门,学习Tensorflow和Pytorch搭建网络基本的操作。打算将各网络实现一下放入这两份代码中,有兴趣可以看一看,期待和大家一起维护更新。
代码地址:
Tensorflow实现分类网络
Pytorch实现分类网络