stata面板数据gmm回归_Stata:面板数据模型一文读懂
? 连享会主页:lianxh.cn

New!
lianxh命令发布了: GIF 动图介绍
随时搜索 Stata 推文、教程、手册、论坛,安装命令如下:. ssc install lianxh
连享会 · 最受欢迎的课
? 2021 Stata 寒假班
⌚ 2021 年 1.25-2.4? 主讲:连玉君 (中山大学);江艇 (中国人民大学)
? 课程主页:https://gitee.com/arlionn/PX

作者: 游万海 (福州大学) | 连玉君 (中山大学)主页: www.lianxh.cn
目录
1. 模型形式设定
2. 模型分类与选择
2.1. 固定效应的检验
2.2. 随机效应的检验
2.3. 固定效应还是随机效应?
3. Stata 实现
3.1. 读取数据与面板数据设定
3.2. 模型检验与模型选择
3.3 几点说明
4. 总结
5. 附录:文中所用 Stata dofiles
6. 参考文献和扩展阅读
7. 相关推文
导言:
面板数据模型的使用几乎遍及所有研究领域,但对于初学者而言,似乎总有一道心结始终无法解开,总觉得「面板数据」很高大上,无形中给自己施加了很大的压力。为此,中山大学连玉君老师做了一个公开课 —— 直击面板数据模型 ( 课程主页:https://gitee.com/arlionn/PanelData )。目前,这个课程的受众超过 5000 人次。连老师为此课程定制了课程主页,用于分享课件、dofile 和参考文献,欢迎各位前往下载或【Fork】。
如下是连玉君老师公开课 直击面板数据模型 ( 课程主页:https://gitee.com/arlionn/PanelData ) 上课的板书。你可以看出什么是 「固定效应」,什么是 「双向固定效应模型」,什么是 「POLS」 v.s. 「FE」 以及二者的差别。
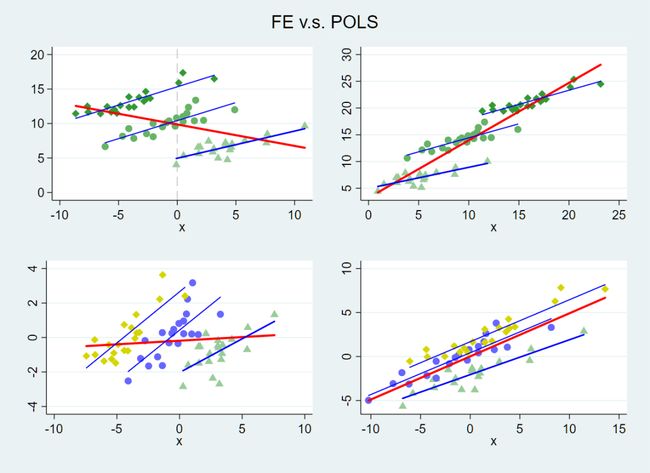
所以,面板数据模型其实没有你想象的那么复杂!

常见的数据形式有时间序列数据( Time series data ),截面数据( Cross-sectional data )和面板数据( Panel data )。
从维度来看,时间序列数据和截面数据均为一维。面板数据可以看做为时间序列与截面混合数据,因此它是二维数据。数据形式如下:

世界是复杂的,所表现出来的行为特征也是复杂的,我们需要面板数据。
例如,欲研究影响企业利润的决定因素,我们认为企业规模 (截面维度)和技术进步(时间维度)是两个重要的因素。截面数据仅能研究企业规模对企业利润的影响程度,时间序列数据仅能研究技术进步对企业利润的影响,而面板数据同时考虑了截面和时间两个维度 (从哪个维度看都好看),可以同时研究企业规模和技术进步对企业利润的影响。
正因为面板数据所具有的独特优势,许多模型从截面数据扩展到面板数据框架下。通过 findit panel data 命令可以发现目前 Stata 已有许多相关面板数据模型命令,包括(不限于):
xtreg/reghdfe:普通面板数据模型,包括固定效应与随机效应xtivreg2:工具变量面板估计xtabond/xtdpdsys/xtabond2/xtdpdqml/xtlsdvc/xtdpdgmm:动态面板数据模型spxtregress/xsmle: 空间面板数据模型xthreg: 面板门限模型xtqreg/qregpd/xtrifreg: 面板分位数模型xtunitroot: 面板单位根检验xtcointtest/ xtpedroni/xtwest: 面板协整检验sfpanel: 面板随机前沿模型xtpmg/xtmg:非平稳异质面板模型- ……
本文主要就普通静态面板数据模型进行介绍,包括模型形式设定、模型分类与选择及 Stata 程序实现等。
1. 模型形式设定
面板数据模型同时包含了截面和时间两个维度,设 (=1, , ) 表示截面 (个体), () 表示时间,设定如下线性模型:
其中,
- 为 因变量,
- 为 自变量,
- 为模型误差项, 是待估计参数,表示 对 的边际影响。
- 表示个体效应,表示那些不随时间改变的影响因素,如个人的消费习惯、企业文化和经营风格等;
- 表示时间效应,用于控制随时间改变因素的影响 (时间虚拟变量包括时间趋势项,时间趋势主要用于控制技术进步),如广告的投放 (往往通过电视或广播,我们可以认为在特定的年份所有个体所接受的广告投放量相同)。
显然, 和 在多数情况下都是无法直接观测或难以量化的,因此也就无法进入模型。在截面分析中往往会引起遗漏变量的问题。
面板数据模型的主要用途之一就在于处理这些不可观测的个体效应或时间效应。当对所有的 , 均相等时,模型退化为混合数据模型 ( Pooled OLS ),可直接用 reg y x 命令进行参数估计。
根据个体数 和时期数 的大小,通常可以将面板数据分为宏观面板和微观面板:宏观面板一般为 「大 小 」,微观面板一般为「小 大 」。依据 、 大小不同,所采用的参数估计方法和分析中关注的重点也不尽相同。
2. 模型分类与选择
面板数据模型可以分为固定效应( Fixed effect model )和随机效应模型( Random effect model )。当 和 相关,即 ,则该模型为固定效应模型;反之为随机效应模型。
两种模型的差异主要反映在对 “个体效应” 的处理上。
固定效应模型假设个体效应在组内是固定不变的,个体间的差异反映在每个个体都有一个特定的截距项上;随机效应模型则假设所有的个体具有相同的截距项, 个体间的差异是随机的,这些差异主要反应在随机干扰项的设定上。
基于此,一种常见的观点认为, 当我们的样本来自一个较小的母体时,我们应该使用固定效应模型,而当样本来自一个很大的母体时, 应当采用随机效应模型。
然而,在具体的实例应用中,大母体和小母体并没有一个严格的界限,我们并不能明确地区分我们的样本来自一个较大母体还是较小的母体。因此,有些学者认为,区分固定效应模型和随机效应模型应当通过检验使用二者的假设条件是否满足。
下面我们讨论混合数据模型、固定效应模型和随机效应模型的选择。
2.1. 固定效应的检验
固定效应的检验本质即检验个体间截距项的差异是否显著,即 ====0。根据假设检验原理,设定如下原假设
若结果拒绝原假设,则表明个体间截距项存在显著差异,模型中需要考虑固定效应。反之,混合 OLS 模型更为合适。通常可以利用 统计量来检验上述假设是否成立:
其中: 为固定效应模型的拟合优度系数(不受约束模型), 为混合数据模型的拟合优度系数(受约束模型); 和 分别为截面与时期数; 为解释变量个数。若原假设被拒绝,则说明个体效应显著,固定效应模型比混合数据模型更优。同理,可以构造相似的 统计量检验时期效应是否显著。
2.2. 随机效应的检验
Breusch and Pagan (1980) 提出了基于面板随机效应模型残差的 LM统计量,构造如下原假设来检验随机效应:
相应的检验统计量LM为:
在原假设下,该统计量服从自由度为 1 的卡方分布。若拒绝原假设则表明存在随机效应。
2.3. 固定效应还是随机效应?
通过检验说明个体效应 () 需要被纳入到模型中后,应该将 看成随机干扰项的一部分(随机效应模型)还是待估计参数 (固定效应模型),下面介绍一些基本方法。
(1) Hausman 检验
从基本定义出发,可以通过通过检验个体效应 与其它解释变量是否相关作为进行固定效应和随机效应模型筛选的依据。此时,我们可以采用 Hausman 检验。其基本思想是:在 和其他解释变量不相关假定下,采用组内变换法估计固定效应模型和采用 GLS 法随机效应模型得到的参数估计都是无偏且一致的,只是前者不具有效性。若原假设不成立,则固定效应模型的参数估计仍然是一致的,但随机效应模型不一致。因此,在原假设下,二者的参数估计应该不会有显著的差异, 可以基于二者参数估计的差异构造统计检验量。
假设 为固定效应模型的组内估计量, 为随机效应模型的 GLS 估计。在原假设成立下,有
根据方差公式
又因为 ,因此有
Hausman 检验基于如下 Wald 统计量
若拒绝原假设,表明个体效应 与解释变量相关,此时随机效应模型的结果不一致,应选择固定效应模型。
(2) 稳健 Hausman 检验 (Wooldridge, 2002)
当不服从同方差假设时,传统的 Hausman 检验方法失效。Wooldridge (2002) 提出了一种稳健版的 Hausman 检验方法。建立如下辅助模型:
其中: 为时变解释变量。当 RE 估计为完全有效估计时,利用 Wald 统计量做 检验所得结果应该渐近相等于标准的检验。当 RE 估计为不是完全有效估计时,Wooldridge (2002) 提出在 cluster-robust 标准误下做上述检验。
(3) 修正的 Hausman 统计量
在固定效应模型与随机效应模型选择上,Hausman 统计量被广泛地应用于实证研究中。从上述看,该检验统计量渐近服从卡方分布,值应该为正数。然而,实际问题中计算出的统计值常出现负值的情况。针对出现负值这一现象,许多学者进行了研究,但并未形成一致的观点。
一种观点认为出现这样的情况主要是由小样本偏误引起,并建议此时应该解释为不能拒绝原假设,应选择随机效应模型 (如,Baltagi, 2008; Hsiao, 2003;Statacrop, 2009)。
另一种观点认为该统计量出现负值恰恰表明原假设不合理,此时应该选择固定效应模型。这些研究表明这种状况不仅仅出现在小样本情况下,在大样本情况下也时有发生 (Schreiber, 2008; Magazzini and Calzolarr, 2010)。如沈根祥 (2010) 在利用高频数据时也出现统计量为负值的情形。
连玉君等 (2014) 利用蒙特卡洛模拟方法得到内生性问题 (即解释变量与个体效应相关) 是导致统计量出现负值的主要原因。模拟分析表明,修正的 Hausman 统计量,以及过度识别检验方法能够很好地克服上述缺陷。
修正的 Hausman 统计量主要是对 或 进行调整。调整后的统计量为
或者为
其中: 和 分别为固定效应模型和随机效应模型下的均方根误差。
(4) 基于过度识别检验的 Wald 统计量
基于通常的 Hausman 统计量在存在异方差 (heteroskedastic) 情况下失效且当定义 cluster-robust 标准误时不再适用问题,Arellano (1993) 基于过度识别检验提出了 Wald 检验统计量解决这一问题。在条件同方差情况下,该检验统计量与通常的Hausman统计量渐近相等。此外,该统计量始终为正数。
如前所述,FE 估计和 RE 估计都需要满足一般意义上的外生性假设条件,即 ,而 RE 估计还要进一步满足面板特定的外生性假设条件,即 。
我们可以将这个新增加的正交条件视为一个过度识别约束,以此来区分 RE 估计的前提假设是否合理。我们可以通过估计如下模型来构造 Wald 统计量
其中:,。 和 具有相似的定义。显然,在上式中, 的 OLS 估计即为 RE 估计量 ,而 的 OLS 估计即为 之间的差异,即
利用 Wald 检验假设 ,所得统计量即为过度识别检验的 Wald 统计量 。
(5) Mundlak’s (1978) 方法
在原假设成立情况下,估计量的有效性假设 (存在最小渐近方差) 是运用Hausman 检验的前提条件。然而,当误差项存在异方差或者序列相关时,这个条件往往不能够被满足。即使在这个条件满足情况下,该方法也可能存在小样本问题。这里介绍另外一种方法,即 Mundlak’s(1978) 提出的一种检验方法。与通常的 Hausman检验不同,该方法在误差项不满足同方差和序列不相关情况下也是有效的。设定如下线性模型:
Mundlak 方法的思想为检验和解释变量 是否存在相关。因此,建立如下关系式:
其中: 是 的组内平均, 是非时变的,且与自变量不相关的。
要保证 和解释变量 不相关,只需=0。根据以上式子,可以转化为检验如下方程的系数
因此,只需要回归这个方程,并检验 是否成立。若拒绝原假设,则 和解释变量 存在相关,应选择固定效应模型。
(6) Bootstrap Hausman检验
传统的 Hausman 检验统计量可定义为
传统 Hausman 检验有效的前提条件是,在原假设为真的情况下,其中一个估计量为完全有效的。然而,实际应用中这个假设通常不被满足。特别地,当利用稳健标准误时,估计量通常非有效。
Bootstrap方法可以在估计量非有效的情况估计 。假设重复进行 B 次抽样,可以得到 B 个 和 估计值,进而可得到 B 个 估计值。 可以利用下面式子进行估计
其中:。

3. Stata 实现
本部分以 Kleiber 和 Zeileis (2008) 的 Grunfeld.dta 数据集为例,说明运用面板数据模型的一般步骤。
3.1. 读取数据与面板数据设定
. webuse "grunfeld", clear //利用webuse从网络读取数据
. list in 1/50 if time<6 //显示每家公司前五年的数据
+--------------------------------------------------+
| company year invest mvalue kstock time |
|--------------------------------------------------|
1. | 1 1935 317.6 3078.5 2.8 1 |
2. | 1 1936 391.8 4661.7 52.6 2 |
3. | 1 1937 410.6 5387.1 156.9 3 |
4. | 1 1938 257.7 2792.2 209.2 4 |
5. | 1 1939 330.8 4313.2 203.4 5 |
|--------------------------------------------------|
21. | 2 1935 209.9 1362.4 53.8 1 |
22. | 2 1936 355.3 1807.1 50.5 2 |
23. | 2 1937 469.9 2676.3 118.1 3 |
24. | 2 1938 262.3 1801.9 260.2 4 |
25. | 2 1939 230.4 1957.3 312.7 5 |
|--------------------------------------------------|
41. | 3 1935 33.1 1170.6 97.8 1 |
42. | 3 1936 45 2015.8 104.4 2 |
43. | 3 1937 77.2 2803.3 118 3 |
44. | 3 1938 44.6 2039.7 156.2 4 |
45. | 3 1939 48.1 2256.2 172.6 5 |
+--------------------------------------------------+
多数情况下,数据中的前两个变量分别为面板数据的「截面标识变量 (panel variable)」和「时间标识变量 (time variable)」,本列中分别为 company 和 year。由于面板数据分析中经常涉及 滞后项 和 差分项,我们需要预先声明我们的数据是面板数据结构,基本命令为:
. xtset company year
panel variable: company (strongly balanced)
time variable: year, 1935 to 1954
delta: 1 year
执行上述命令的过程中,Stata 至少完成了如下动作:
- 将我们的数据依次按照 company 和 year 升序排列,以便于后续进行滞后项和差分项的操作。
- 分析数据的结构。company (strongly balanced) 表明每家公司都有相同的年数 ( T = 20年 = 1954-1935+1),且年份上完全对应。year, 1935 to 1954 表明数据的时间区间为 1935 到 1954 年,间隔为 1 年,且连续。
有关 xtset 的详情可以查看帮助文件 help xtset,通过选项来设定数据的时间间隔等参数 (针对日数据、周数据等)。
3.2. 模型检验与模型选择
本部分内容安排如下:
(1)个体效应和随机效应的联合显著性检验,以判别是否需要利用面板数据模型;
(2)若表明需用面板数据模型,利用Hausman统计量选择固定效应模型或随机效应模型更优;
(3)考虑到一般的Hausman检验在异方差和自相关情况下失效风险问题,对异方差,序列相关进行检验,以说明是否需要利用其它方法进行选择;
(4)针对一般的Hausman检验统计量可能为负值且对在异方差和序列相关情况不稳健问题,对稳健 Hausman 检验,修正的 Hausman统计量, 基于过度识别检验的Wald统计量法,Mundlak’s (1978)法,基于 bootstrap法的hausman检验等方法的Stata实现进行讲解。
(5)在选定固定效应模型或随机效应模型后,依据误差项结构(异方差,序列相关,截面相依)以及不同面板结构(「大 小 」,「大 小 」), 介绍相应的参数估计命令。
(1)个体效应和随机效应的联合显著性检验
以 invest 为因变量,mvalue kstock 为自变量,建立如下模型:
其中: 和 为待估系数。
利用Stata中 xtreg 可以方便实现面板固定效应模型与面板随机效应模型的估计。xtreg命令的语法如下:
 image
image
xtreg invest mvalue kstock, fe // fe表示固定效应; 若同时包括时期虚拟变量,xtreg invest mvalue kstock i.year, fe,利用 testparm 检验
 image
image
xtreg invest mvalue kstock,re //re表示随机效应
 image
image
xttest0 //检验随机效应是否显著,需要运行随机效应模型后使用
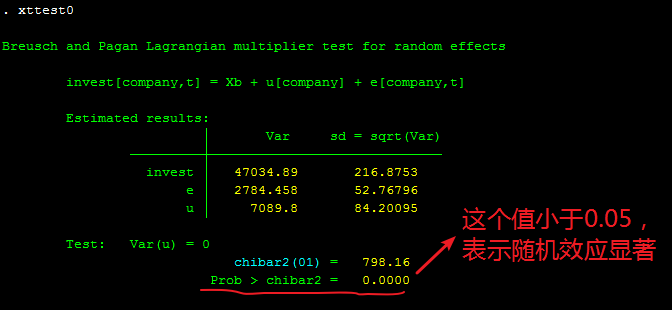 image
image
(2)Hausman检验
上述结果说明了有必要考虑个体效应和随机效应,接下来利用hausman 命令进行固定效应模型和随机效应模型的选择,主要步骤为:
- 步骤一:估计固定效应模型,存储估计结果;
- 步骤二:估计随机效应模型,存储估计结果;
- 步骤三:进行Hausman检验;
利用hausman 命令之前,有必要对其语法进行说明:
. hausman name-consistent [name-efficient] [, options]
 image
image
接下来进行hausman检验,
xtreg invest mvalue kstock,fe
est store fe_result
xtreg invest mvalue kstock,re
est store re_result
hausman fe_result re_result
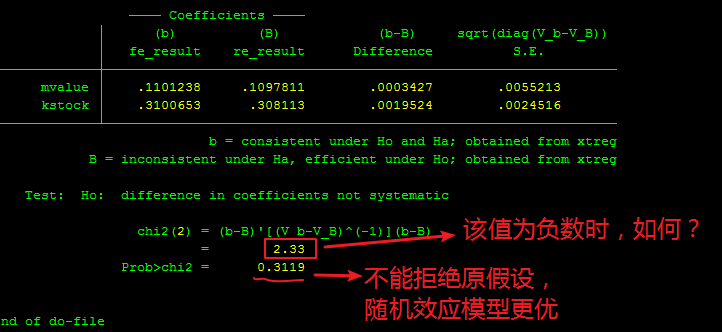 image
image
(3)异方差和序列相关检验
前文已经说明,当模型误差项存在序列相关或异方差时,此时经典的Hausman 检验不在适用,下面我们进行序列相关和异方差检验。
序列相关检验
先进行序列相关检验,在固定效应模型时可以利用命令xtserial,原假设为不存在序列相关。
xtserial invest mvalue kstock
 image
image
同样地,在随机效应时可以利用命令xttest1,原假设为不存在序列相关。
 image
image
异方差检验
Greene (2000, p598) 提出一种修正的Wald统计量检验异方差,与标准的Wald统计量、LR和LM统计量不同,修正Wald检验同样适用于模型残差不服从 正态分布情况下。值得一提的是,在大 小 情况下,该方法的检验功效较低。该检验的原假设为同方差。
xtreg invest mvalue kstock,fe
xttest3
 image
image
(4)模型选择其它方法
第一种:稳健 Hausman 检验
目前 Stata 中没有相应的命令进行稳健 Hausman检验, 根据 2.3 中 (2) 部分公式,可以编写如下代码进行检验
webuse grunfeld, clear
xtset company year
quiet xtreg invest mvalue kstock,re
scalar theta = e(theta)
global xlist2 invest mvalue kstock
sort company
foreach x of varlist $xlist2 {
by company: egen mean`x' = mean(`x')
generate md`x' = `x' - mean`x'
generate red`x' = `x' - theta*mean`x'
}
quiet reg redinvest redmvalue redkstock mdmvalue mdkstock, vce(cluster company)
test mdmvalue mdkstock
 image
image
第二种:修正的 Hausman统计量
xtreg invest mvalue kstock,fe
est store fe_result
xtreg invest mvalue kstock,re
est store re_result
hausman fe_result re_result,sigmamore
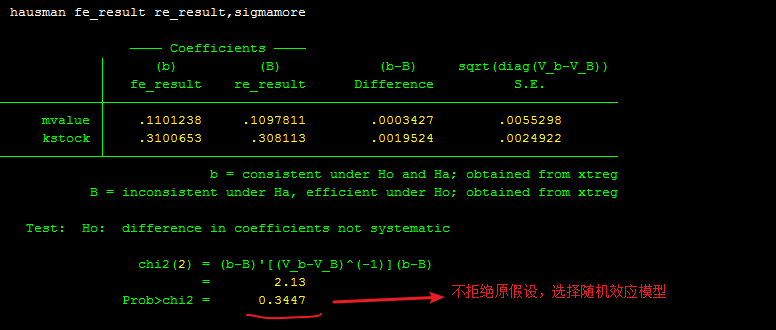 输入图片说明
输入图片说明
hausman fe_result re_result,sigmaless
 输入图片说明
输入图片说明
第三种:基于过度识别检验的Wald统计量
xtreg invest mvalue kstock, re cluster(company)
xtoverid
 image
image
运行后提示需要更高版本的ivreg2等命令,可以通过 net install ivreg2,from("http://fmwww.bc.edu/RePEc/bocode/i")进行更新。然后再运行
 image
image
上述结果表明拒绝 假设,应该选择固定效应模型。
第四种:Mundlak’s (1978)法
根据上文所述原理,可通过如下三个步骤实现该方法:
第一:计算解释变量 均值
local xlist "mvalue kstock"
foreach f of local xlist{
bysort company: egen mean_`f' = mean(`f')
}
第二步:估计包含均值的回归方程:
xtreg invest mvalue kstock mean_mvalue mean_kstock,re vce(robust)
est store Mundlak_result
第三步:利用test进行假设检验
test mean_mvalue mean_kstock
结果如下
 image
image
此外,也可以通过外部命令 mundlak 实现相同的系数估计,不过应该注意的是由于 mundlak不能得到稳健的标准误,得到的标准误和上述 手动运行方法不一致,所以test结果也就不一致。
mundlak invest mvalue kstock,full
test mean__mvalue mean__kstock
 image
image
第五种:基于 bootstrap法的hausman检验
由于存在序列相关和异方差,经典的hausman命令不再适用,下面使用基于bootstrap的hausman检验命令rhausman进行检验。
xtreg invest mvalue kstock,fe
est store fe_result
xtreg invest mvalue kstock,re
est store re_result
rhausman fe_result re_result,reps(200) cluster
 image
image
从检验结果可以发现,利用经典的hausman 和bootstraphausman均显示应该选择随机效应模型,而利用其他方法结果显示选择固定效应模型。
除了序列相关和异方差检验之外,截面相依检验也尤为重要。在固定效应模型中,可以利用命令xttest2进行检验,该方法是基于似不相关回归(SUR)进行 估计,所以一般要求截面数 比时期数 小;在随机效应模型中利用xtcsd进行检验,当然该命令也适用于固定效应模型。
(5)相关 Stata 命令推荐
依据误差项结构(异方差,序列相关,截面相依)以及不同面板结构(「大TT小NN」,「大NN小TT」), 下文介绍相应的参数估计命令。
截面相依检验
qui xtreg invest mvalue kstock, fe
xttest2
 image
image
qui xtreg invest mvalue kstock, re
xtcsd, pesaran
 image
image
当误差项存在序列相关,异方差或截面相依时,依据形式不同,可以利用不同的方法和命令进行估计,详细可以参考 Hoechle (2007)。
 image
image
3.3 几点说明
vce(robust)和vce(cluster): 前者适用于异方差且观测值之间独立情况(heteroscedasticity-consistent standard errors);后者 适用于异方差且允许观测值组内相关。例如cluster(group)的含义是:假设干扰项在 group 之间不相关,而在 group 内部存在相关性。若 group 代表行业类别,则表示行业间的公司所面临的随机干扰不相关,而行业内部不同公司间的干扰项存在相关性,或者是说,行业内的公司受到了一些共同的干扰因素。这部分内容将在后续的推文中详细介绍。固定效应模型与随机效应模型选择,学者们存在不同的观点。一些学者检验利用严格的统计检验选择,有些学者认为应该根据实际分析的需要进行选择,比如主要变量为不随时变的,那则必须采用随机效应模型。
面板固定效应模型的估计除了可利用
xtreg,fe进行估计外,也可以利用areg或者reg+ dummy variables进行估计,注意这些方法的差异。上文中涉及到的一些命令,如
xttest0,xttest1,xttest2,xttest3,xtserial,xtcsd,rhausman等需要下载安装。
4. 总结
虽然本文系统地介绍了静态面板数据模型的各种检验方法,但从现有的文献来看,实操层面的做法往往是单刀直入,甚至多少有些粗暴。
具体而言:
- 多数情况下 (90% 以上),学者们都直接使用 FE,而 RE 则鲜有使用 (至少在公司金融和会计领域是如此)。
- 如果一定要在 FE 和 RE 之间进行筛选 (通常是为了应对审稿人),建议采用假设较为宽松的 稳健 Hausman 检验 (
help xtoverid) 或 bootstrap hausman 检验法 (help rhausman)。 - 在估计 FE 时,主流的做法是使用 「双向固定效应模型+聚类标准误」,即同时包含个体效应与时间效应的面板固定效应模型。对应的 Stata 命令为:
xtreg y x1 x2 i.year, fe robust。注意:若仅关注系数估计值和其标准误,该命令等价于xtreg y x1 x2 i.year, vce(cluster id)以及reg y x1 x2 i.id i.year, vce(cluster id)。换言之,xtreg, fe robust中的robust选项本身就是在公司层面上聚类调整后的异方差稳健性标准误。
5. 文中所用 Stata dofiles
clear
webuse grunfeld,clear //利用webuse从网络读取数据
list in 1/10 // 显示该数据集的前10行
xtset company year,yearly //设置面板数据格式
xtreg invest mvalue kstock,fe //fe表示固定效应;若同时包括时期虚拟变量,xtreg invest mvalue kstock i.year,fe,利用 testparm 检验
xtreg invest mvalue kstock,re //re表示随机效应
xttest0 //检验随机效应是否显著,需要运行随机效应模型后使用
** 传统 hausman 检验
xtreg invest mvalue kstock,fe
est store fe_result
xtreg invest mvalue kstock,re
est store re_result
hausman fe_result re_result
xtserial invest mvalue kstock //序列相关检验,随机效应可以使用xttest1
xtreg invest mvalue kstock,fe
xttest3 //异方差检验
** 稳健 hausman 检验方法
quiet xtreg invest mvalue kstock,re
scalar theta = e(theta)
global xlist2 invest mvalue kstock
sort company
foreach x of varlist $xlist2 {
by company: egen mean`x' = mean(`x')
generate md`x' = `x' - mean`x'
generate red`x' = `x' - theta*mean`x'
}
quiet reg redinvest redmvalue redkstock mdmvalue mdkstock, vce(cluster company)
test mdmvalue mdkstock
**修正hausman检验方法
xtreg invest mvalue kstock,fe
est store fe_result
xtreg invest mvalue kstock,re
est store re_result
hausman fe_result re_result,sigmamore
hausman fe_result re_result,sigmaless
** 基于过度识别检验法
xtreg invest mvalue kstock, re cluster(company)
xtoverid
** Mundlak’s (1978)法
local xlist "mvalue kstock"
foreach f of local xlist{
bysort company: egen mean_`f' = mean(`f')
}
xtreg invest mvalue kstock mean_mvalue mean_kstock,re vce(robust)
est store Mundlak_result
test mean_mvalue mean_kstock
** 基于 bootstrap 法的 hausman 检验
xtreg invest mvalue kstock,fe
est store fe_result
xtreg invest mvalue kstock,re
est store re_result
rhausman fe_result re_result,reps(200) cluster
** 截面相依检验
qui xtreg invest mvalue kstock, fe
xttest2
qui xtreg invest mvalue kstock, re
xtcsd, pesaran
6. 参考文献和扩展阅读
- 钟经樊和连玉君. 计量分析与 STATA 应用, 2010.
- Hoechle D. Robust standard errors for panel regressions with cross–sectional dependence[J]. Stata Journal, 2007, 7(3):281-312.
- Breusch T S, Pagan A R. The Lagrange Multiplier Test and its Applications to Model Specification in Econometrics[J]. Review of Economic Studies, 1980, 47(1):239-253.
- Mundlak, Y. On the pooling of time series and cross section data. Econometrica, 1978, 46:69-85.
- Greene, W. 2000. Econometric Analysis. Upper Saddle River, NJ: Prentice--Hall.
- Stata Blogs: How can the standard errors with the vce(cluster clustvar) option be smaller than those without the vce(cluster clustvar) option?
- Stata Blogs: Fixed effects or random effects: The Mundlak approach, 2015.
- Kleiber C, Zeileis A (2008). Applied Econometrics with R. Springer-Verlag, New York. ISBN978-0-387-77316-2.
- Arellano, M. 1993. On the testing of correlated effects with panel data. Journal of Econometrics, Vol. 59, Nos. 1-2, pp. 87-97.
- Wooldridge, J.M. 2002. Econometric Analysis of Cross Section and Panel Data. Cambridge, MA: MIT Press.
7. 相关推文
温馨提示: 文中链接在微信中无法生效。请点击底部
- 专题: Stata命令
- 专题: 数据处理
- 专题: 面板数据
- 专题: 空间计量
- xtseqreg:面板模型如何估计不随时间变化的变量
- Stata新命令:ppmlhdfe-面板计数模型-多维固定效应泊松估计
- Stata新命令:面板-LogitFE-ProbitFE
- Stata新命令-tobalance:非平行面板转换为平行面板数据
- Stata面板:suest支持面板数据的似无相关检验
- Stata:面板中如何合理控制不可观测的异质性特征
- Stata面板:Granger-因果检验
- Stata: 面板分位数回归
- reghdfe:多维面板固定效应估计
- Stata: 动态面板门槛模型
- Stata: 面板数据模型一文读懂
- 空间面板数据模型及Stata实现
- 直播课 - 空间面板模型及动态设定
- Stata数据处理:xtbalance-非平衡面板之转换
- Stata新命令-tobalance:非平行面板转换为平行面板数据
- Stata数据处理:面板数据的填充和补漏
连享会 · 最受欢迎的课
? 2021 Stata 寒假班
⌚ 2021 年 1.25-2.4? 主讲:连玉君 (中山大学);江艇 (中国人民大学)
? 课程主页:https://gitee.com/arlionn/PX

? ? ? ?
连享会主页:? www.lianxh.cn
直播视频:lianxh.duanshu.com

免费公开课:
- 直击面板数据模型:https://gitee.com/arlionn/PanelData - 连玉君,时长:1小时40分钟
- Stata 33 讲:https://gitee.com/arlionn/stata101 - 连玉君, 每讲 15 分钟.
- Stata 小白的取经之路:https://gitee.com/arlionn/StataBin - 龙志能, 2 小时
- 部分直播课课程资料下载 ? https://gitee.com/arlionn/Live (PPT,dofiles等)
温馨提示: 文中链接在微信中无法生效,请点击底部
关于我们
- ? 连享会 ( 主页:lianxh.cn ) 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- ? 直达连享会:【百度一下:连享会】即可直达连享会主页。亦可进一步添加 主页,知乎,面板数据,研究设计 等关键词细化搜索。
- New!
lianxh命令发布了: 在 Stata 命令窗口中输入ssc install lianxh即可安装,随时搜索连享会推文、Stata 资源,详情:help lianxh。
 连享会主页 lianxh.cn
连享会主页 lianxh.cn
? 连享会小程序:扫一扫,看推文,看视频……

? 扫码加入连享会微信群,提问交流更方便

? 连享会学习群-常见问题解答汇总:
? https://gitee.com/arlionn/WD
New!
lianxh命令发布了: GIF 动图介绍
随时搜索连享会推文、Stata 资源,安装命令如下:. ssc install lianxh
使用详情参见帮助文件 (有惊喜):. help lianxh