2021先定个小目标?搞清楚MyCat分片的两种拆分方法和分片规则!(三):分片规则的十四种算法详细解读&代码实现(上)!
目录
- 一、取模分片
- 二、范围分片
- 三、枚举分片
- 四、范围求模算法
- 五、固定分片hash算法
- 六、取模范围算法
- 七、字符串hash求模范围算法
MyCat的分片规则配置在
conf目录下的
rule.xml文件中定义 ;
环境准备 :
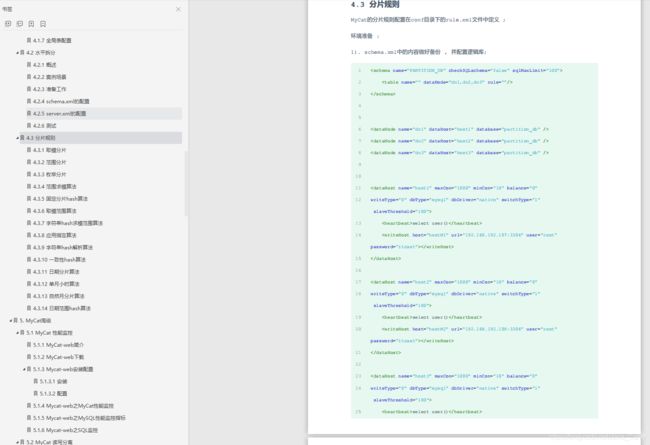
schema.xml中的内容做好备份 , 并配置逻辑库;
<schema name="PARTITION_DB" checkSQLschema="false" sqlMaxLimit="100">
<table name="" dataNode="dn1,dn2,dn3" rule=""/>
</schema>
<dataNode name="dn1" dataHost="host1" database="partition_db" />
<dataNode name="dn2" dataHost="host2" database="partition_db" />
<dataNode name="dn3" dataHost="host3" database="partition_db" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.192.157:3306" user="root" password="itcast"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.192.158:3306" user="root" password="itcast"></writeHost>
</dataHost>
<dataHost name="host3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM3" url="192.168.192.159:3306" user="root" password="itcast"></writeHost>
</dataHost>
- 在MySQL的三个节点的数据库中 , 创建数据库
partition_db
create database partition_db DEFAULT CHARACTER SET utf8mb4;
一、取模分片
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>
配置说明 :
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| count | 数据节点的数量 |
二、范围分片
根据指定的字段及其配置的范围与数据节点的对应情况, 来决定该数据属于哪一个分片 , 配置如下:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
autopartition-long.txt 配置如下:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
含义为 : 0 - 500 万之间的值 , 存储在0号数据节点 ; 500万 - 1000万之间的数据存储在1号数据节点 ; 1000万 - 1500 万的数据节点存储在2号节点 ;
配置说明:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为0 ; 0 表示Integer , 1 表示String |
| defaultNode | 默认节点 默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。 |
测试:
配置
<table name="tb_log" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"/>
数据
1). 创建表
CREATE TABLE `tb_log` (
id bigint(20) NOT NULL COMMENT 'ID',
operateuser varchar(200) DEFAULT NULL COMMENT '姓名',
operation int(2) DEFAULT NULL COMMENT '1: insert, 2: delete, 3: update , 4: select',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
insert into tb_log (id,operateuser ,operation) values(1,'Tom',1);
insert into tb_log (id,operateuser ,operation) values(2,'Cat',2);
insert into tb_log (id,operateuser ,operation) values(3,'Rose',3);
insert into tb_log (id,operateuser ,operation) values(4,'Coco',2);
insert into tb_log (id,operateuser ,operation) values(5,'Lily',1);
参考资料:
《开源数据库中间件MyCat实战笔记》
想要快速获取资料的同学:请添加助理VX:C18173184271,备注一下CSDN+工作年限!免费获取
以便能够充分理解学习!
三、枚举分片
通过在配置文件中配置可能的枚举值, 指定数据分布到不同数据节点上, 本规则适用于按照省份或状态拆分数据等业务 , 配置如下:
<tableRule name="sharding-by-intfile">
<rule>
<columns>status</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
partition-hash-int.txt ,内容如下 :
1=0
2=1
3=2
配置说明:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为0 ; 0 表示Integer , 1 表示String |
| defaultNode | 默认节点 ; 小于0 标识不设置默认节点 , 大于等于0代表设置默认节点 ; 默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。 |
测试:
配置
<table name="tb_user" dataNode="dn1,dn2,dn3" rule="sharding-by-enum-status"/>
数据
1). 创建表
CREATE TABLE `tb_user` (
id bigint(20) NOT NULL COMMENT 'ID',
username varchar(200) DEFAULT NULL COMMENT '姓名',
status int(2) DEFAULT '1' COMMENT '1: 未启用, 2: 已启用, 3: 已关闭',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
insert into tb_user (id,username ,status) values(1,'Tom',1);
insert into tb_user (id,username ,status) values(2,'Cat',2);
insert into tb_user (id,username ,status) values(3,'Rose',3);
insert into tb_user (id,username ,status) values(4,'Coco',2);
insert into tb_user (id,username ,status) values(5,'Lily',1);
四、范围求模算法
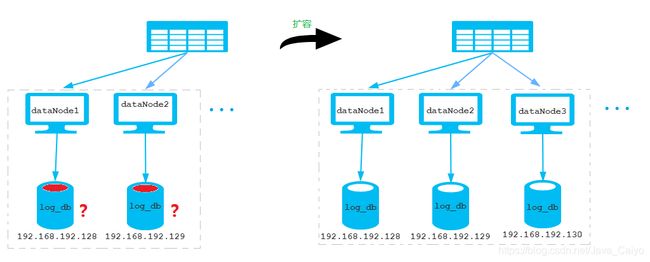
该算法为先进行范围分片, 计算出分片组 , 再进行组内求模。
优点: 综合了范围分片和求模分片的优点。 分片组内使用求模可以保证组内的数据分布比较均匀,分片组之间采用范围分片可以兼顾范围分片的特点。
缺点: 在数据范围时固定值(非递增值)时,存在不方便扩展的情况,例如将 dataNode Group size 从 2 扩展为 4 时,需要进行数据迁移才能完成 ; 如图所示:
配置如下:
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">autopartition-range-mod.txt</property>
<property name="defaultNode">0</property>
</function>
autopartition-range-mod.txt 配置格式 :
#range start-end , data node group size
0-500M=1
500M1-2000M=2
在上述配置文件中, 等号前面的范围代表一个分片组 , 等号后面的数字代表该分片组所拥有的分片数量;
配置说明:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段名 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| defaultNode | 默认节点 ; 未包含以上规则的数据存储在defaultNode节点中, 节点从0开始 |
测试:
配置
<table name="tb_stu" dataNode="dn1,dn2,dn3" rule="auto-sharding-rang-mod"/>
数据
1). 创建表
CREATE TABLE `tb_stu` (
id bigint(20) NOT NULL COMMENT 'ID',
username varchar(200) DEFAULT NULL COMMENT '姓名',
status int(2) DEFAULT '1' COMMENT '1: 未启用, 2: 已启用, 3: 已关闭',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
insert into tb_stu (id,username ,status) values(1,'Tom',1);
insert into tb_stu (id,username ,status) values(2,'Cat',2);
insert into tb_stu (id,username ,status) values(3,'Rose',3);
insert into tb_stu (id,username ,status) values(4,'Coco',2);
insert into tb_stu (id,username ,status) values(5,'Lily',1);
insert into tb_stu (id,username ,status) values(5000001,'Roce',1);
insert into tb_stu (id,username ,status) values(5000002,'Jexi',2);
insert into tb_stu (id,username ,status) values(5000003,'Mini',1);
五、固定分片hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算。
最小值:
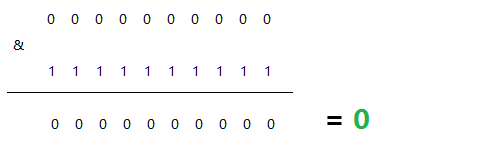
最大值:
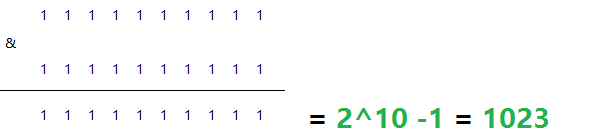
优点: 这种策略比较灵活,可以均匀分配也可以非均匀分配,各节点的分配比例和容量大小由 partitionCount 和 partitionLength 两个参数决定
缺点:和取模分片类似。
配置如下 :
<tableRule name="sharding-by-long-hash">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
在示例中配置的分片策略,希望将数据水平分成3份,前两份各占 25%,第三份占 50%。
配置说明:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段名 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| partitionCount | 分片个数列表 |
| partitionLength | 分片范围列表 |
约束 :
- 分片长度 : 默认最大2^10 , 为 1024 ;
- count, length的数组长度必须是一致的 ;
- 两组数据的对应情况:
(partitionCount[0]partitionLength[0])= (partitionCount[1]partitionLength[1])
以上分为三个分区:0-255,256-511,512-1023
测试:
配置
<table name="tb_brand" dataNode="dn1,dn2,dn3" rule="sharding-by-long-hash"/>
数据
1). 创建表
CREATE TABLE `tb_brand` (
id int(11) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
firstChar char(1) COMMENT '首字母',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
insert into tb_brand (id,name ,firstChar) values(1,'七匹狼','Q');
insert into tb_brand (id,name ,firstChar) values(529,'八匹狼','B');
insert into tb_brand (id,name ,firstChar) values(1203,'九匹狼','J');
insert into tb_brand (id,name ,firstChar) values(1205,'十匹狼','S');
insert into tb_brand (id,name ,firstChar) values(1719,'六匹狼','L');
六、取模范围算法
该算法先进行取模,然后根据取模值所属范围进行分片。
优点:可以自主决定取模后数据的节点分布
缺点:dataNode 划分节点是事先建好的,需要扩展时比较麻烦。
配置如下:
<tableRule name="sharding-by-pattern">
<rule>
<columns>id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern" class="io.mycat.route.function.PartitionByPattern">
<property name="mapFile">partition-pattern.txt</property>
<property name="defaultNode">0</property>
<property name="patternValue">96</property>
</function>
partition-pattern.txt 配置如下:
0-32=0
33-64=1
65-96=2
在mapFile配置文件中, 1-32即代表id%96后的分布情况。如果在1-32, 则在分片0上 ; 如果在33-64, 则在分片1上 ; 如果在65-96, 则在分片2上。
配置说明:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| defaultNode | 默认节点 ; 如果id不是数字, 无法求模, 将分配在defaultNode上 |
| patternValue | 求模基数 |
测试:
配置
<table name="tb_mod_range" dataNode="dn1,dn2,dn3" rule="sharding-by-pattern"/>
数据
1). 创建表
CREATE TABLE `tb_mod_range` (
id int(11) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
insert into tb_mod_range (id,name) values(1,'Test1');
insert into tb_mod_range (id,name) values(2,'Test2');
insert into tb_mod_range (id,name) values(3,'Test3');
insert into tb_mod_range (id,name) values(4,'Test4');
insert into tb_mod_range (id,name) values(5,'Test5');
注意 : 取模范围算法只能针对于数字类型进行取模运算 ; 如果是字符串则无法进行取模分片 ;
七、字符串hash求模范围算法
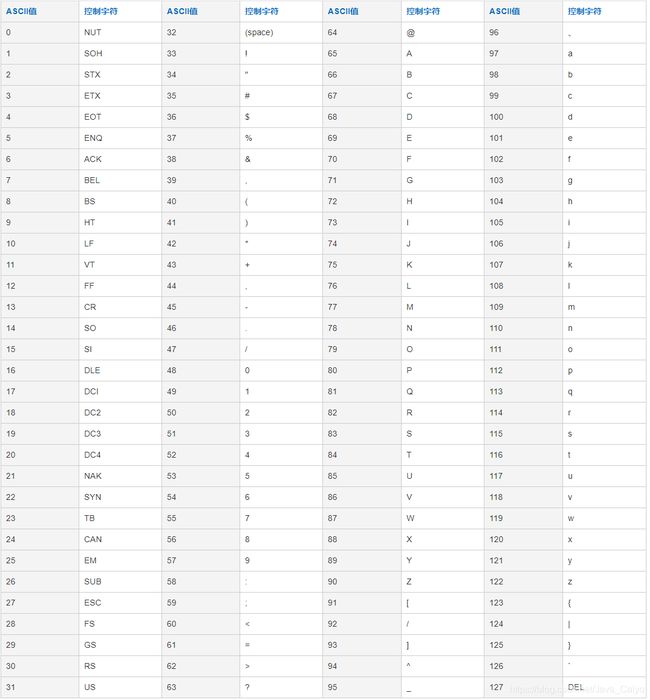
与取模范围算法类似, 该算法支持数值、符号、字母取模,首先截取长度为 prefixLength 的子串,在对子串中每一个字符的 ASCII 码求和,然后对求和值进行取模运算(sum%patternValue),就可以计算出子串的分片数。
优点:可以自主决定取模后数据的节点分布
缺点:dataNode 划分节点是事先建好的,需要扩展时比较麻烦。
配置如下:
<tableRule name="sharding-by-prefixpattern">
<rule>
<columns>id</columns>
<algorithm>sharding-by-prefixpattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-prefixpattern" class="io.mycat.route.function.PartitionByPrefixPattern">
<property name="mapFile">partition-prefixpattern.txt</property>
<property name="prefixLength">5</property>
<property name="patternValue">96</property>
</function>
partition-prefixpattern.txt 配置如下:
# range start-end ,data node index
# ASCII
# 48-57=0-9
# 64、65-90=@、A-Z
# 97-122=a-z
###### first host configuration
0-32=0
33-64=1
65-96=2
配置说明:
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| prefixLength | 截取的位数; 将该字段获取前prefixLength位所有ASCII码的和, 进行求模sum%patternValue ,获取的值,在通配范围内的即分片数 ; |
| patternValue | 求模基数 |
如 :
字符串 :
gf89f9a
截取字符串的前5位进行ASCII的累加运算 :
g - 103
f - 102
8 - 56
9 - 57
f - 102
sum求和 : 103 + 102 + + 56 + 57 + 102 = 420
求模 : 420 % 96 = 36
附录 ASCII码表 :
测试:
配置
<table name="tb_u" dataNode="dn1,dn2,dn3" rule="sharding-by-prefixpattern"/>
数据
1). 创建表
CREATE TABLE `tb_u` (
username varchar(50) NOT NULL COMMENT '用户名',
age int(11) default 0 COMMENT '年龄',
PRIMARY KEY (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
insert into tb_u (username,age) values('Test100001',18);
insert into tb_u (username,age) values('Test200001',20);
insert into tb_u (username,age) values('Test300001',19);
insert into tb_u (username,age) values('Test400001',25);
insert into tb_u (username,age) values('Test500001',22);
如果你需要这份完整版的
《开源数据库中间件MyCat实战笔记》,只需你多多支持我这篇文章。
多多支持,即可免费获取资料——三连之后(承诺:100%免费)
快速入手通道:添加助理VX:
C18173184271,备注一下CSDN+工作年限!免费获取!诚意满满!!!