Python数据分析基础——CSV文件——从多个文件中连接数据
参考文献:《Python数据分析基础》
前言
对于包含相似数据的多个文件,常常希望将其中的数据连接起来,以使所有数据都在一个文件中。如果需要处理的文件数量和文件大小过大时,手动处理根本不可能完成。文件将介绍如何通过Python完成这个任务。
创建多个CSV文件
首先,创建三个CSV文件
将第一个CSV文件命名为:sales_january_2014.csv
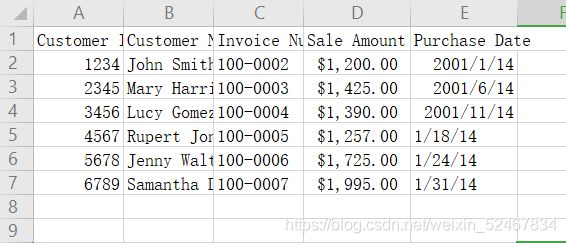
将第二个CSV文件命名为:sales_january_2014.csv
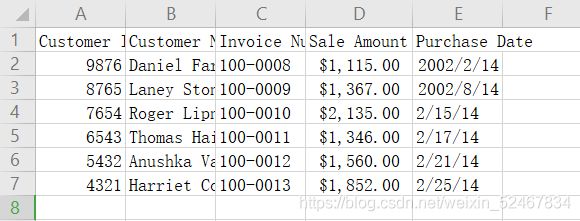
将第三个CSV文件命名为:sales_march_2014.csv
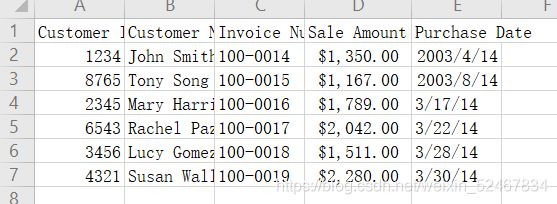
最后,将上述三个CSV文件存储在名为sale的文件夹中。
创建Python脚本
在文本编辑器中输入一段代码,然后将文件保存为:9csv_reader_concat_rows_from_multiple_files.py
#!/usr/bin/env python3
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
first_file = True
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
print(os.path.basename(input_file))
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'a', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
if first_file:
for row in filereader:
filewriter.writerow(row)
first_file = False
else:
header = next(filereader, None)
for row in filereader:
filewriter.writerow(row)
脚本代码注释
input_path = sys.argv[1]
output_file = sys.argv[2]
这两行代码,第一行将文件夹sale的文件路径存到sys.argv[1]中,并赋值给变量input_path。第二行将将输出文件的路径存到sys.argv[2]中,并赋值给变量output_file。
first_file = True
第一行代码创建了变量first_file,用于后续判断是否为第一个输入文件。
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
在这行代码中,os模块的os.path.join函数将其圆括号中的两部分连接起来。glob模块中的glob.glob函数将’sales_*'转为实际的文件名。这两个函数创建了一个包含三个输入文件的列表。此外,创建了for循环体,将每一个输入文件进行下面的循环操作。
with open(output_file, 'a', newline='') as csv_out_file:
在这行代码中,使用‘a’代替‘w’以追加的方式打开输出文件,使每个输入文件中的数据可以追加(也就是添加)到输出文件中。如果以可写的方式,那么最后的输出文件只包含最后处理的那个输入文件中的数据。
if first_file:
for row in filereader:
filewriter.writerow(row)
first_file = False
else:
header = next(filereader, None)
for row in filereader:
filewriter.writerow(row)
这一部分代码使用if-else语句,区分针对首文件与非首文件的操作。当输入文件为首文件时,执行if语句,将首文件的每一行都写入输出文件,然后将变量first_file赋值为False。若输入文件为非首文件,将执行else语句,首先使用next函数将其标题行存入变量header中,使标题行不再写入输出文件。此后将剩余的行依次写入输出文件。
运行脚本
在命令行输入以下命令,然后按回车键:
![]()
查看结果

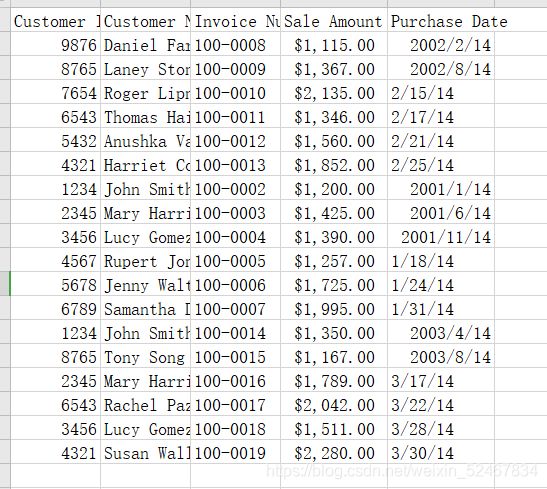
结语
本文重点介绍了CSV文件中从多个文件中连接数据的相关知识,总结了实际操作。需重点理解其操作思想。