Python爬虫 :字体加密和字体反爬
前言:字体反爬,也是一种常见的反爬技术,例如58同城,猫眼电影票房,汽车之家,天眼查,实习僧等网站。这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符,是因为他们采用自定义字体文件,通过在线加载来引用样式,这是CSS3的新特性,通过 CSS3,web 设计师可以使用他们喜欢的任意字体 ,然后因为爬虫不会主动加载在线的字体,
字体加密一般是网页修改了默认的字符编码集,在网页上加载他们自己定义的字体文件作为字体的样式,可以正确地显示数字,但是在源码上同样的二进制数由于未加载自定义的字体文件就由计算机默认编码成了乱码。
目标
目标:我们今天来学习爬取58同城的租房信息,获取房源信息。
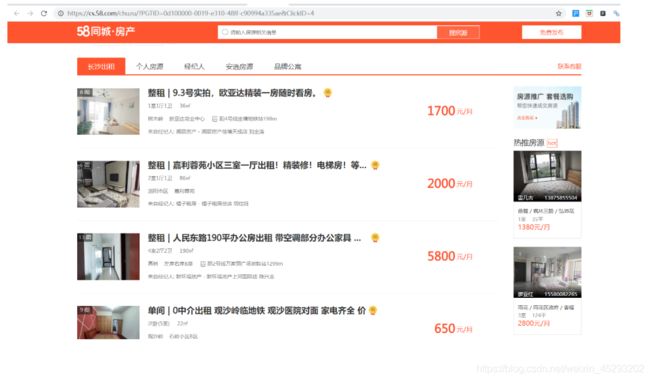
数据爬取
我们先按照前面学的爬虫基本知识,拿起键盘直接开干(无经验不知道字体反爬是啥玩意),一直在用xpath进行解析,都忘记了BeautifulSoup提取了,这里来用这个提取,回顾回顾。
import requests
from bs4 import BeautifulSoup
url = 'https://cs.58.com/chuzu/?PGTID=0d100000-0019-e310-48ff-c90994a335ae&ClickID=4'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
}
response = requests.get(url,headers=headers)
html_text = response.text
bs = BeautifulSoup(html_text, 'lxml')
# 获取房源列表信息,通过css选择器来
lis = bs.select('li.house-cell')
# 获取每个li下的信息
for li in lis:
title = li.select('h2 a')[0].stripped_strings # stripped_strings获取某个标签下的子孙非标签字符串,会去掉空白字符。返回来的是个生成器
room = li.select('div.des p')[0].stripped_strings
money = li.select('.money b')[0].string # 获取某个标签下的非标签字符串。返回来的是个字符串。
print(list(title)[0], list(room)[0], money)输出的结果:

显示乱码,在页面上看也是乱码
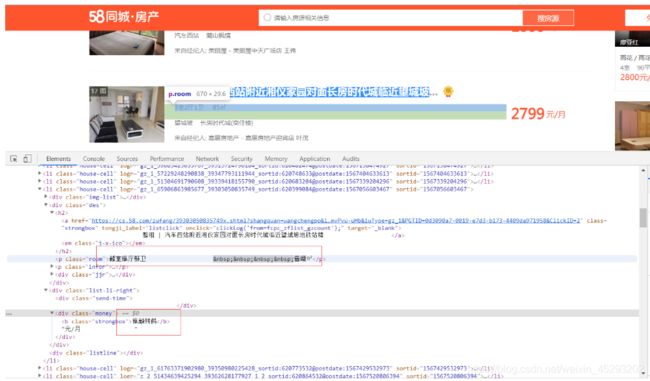
我们右击选择查看网页源代码
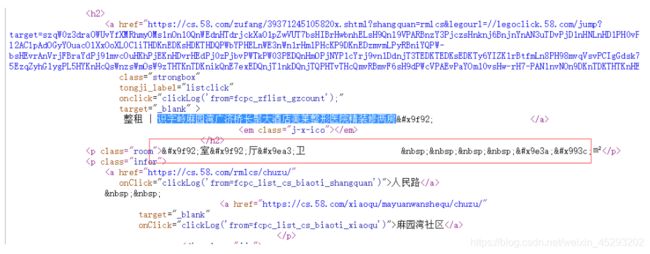
看起来是unicode 编码导致的,这种就是对字体进行了加密了,通用解决办法是找到字体文件,分析文件中的映射关系,一般来说,字体文件都是作为样式加在加密字体的部位,所以我们在html头部里面找相关样式,找了头部信息字体样式font-face,CSS中的@font-face,它允许网页开发者为其网页指定在线字体。
我们ctrl+f搜索@font-face

关于字体
fontTools操作相关
这里我们使用到一个模块fontTools,它是用来操作字体的库,用于将woff或ttf这种字体文件转化成XML文件。
1.我们可以直接使用pip进行安装:
pip install fontTools2.加载字体文件:
font = TTFont('58.woff')3.转为xml文件:
font.saveXML('58.xml')4.各节点名称:
font.keys()5.按序获取GlyphOrder节点name值:
font.getGlyphOrder() 或 font['cmap'].tables[0].ttFont.getGlyphOrder()6.获取cmap节点code与name值映射:
font.getBestCmap()7.获取字体坐标信息:
font['glyf'][i].coordinates8.获取坐标的0或1:
font['glyf'][i].flags **注:** 0表示弧形区域 1表示矩形字体基础与XML
一个字体由数个表(table)构成,字体的信息储存在表中。1、一个最基本的字体文件一定会包含以下的表:
- cmap: Character to glyph mapping unicode跟 Name的映射关系
- head: Font header 字体全局信息
- hhea: Horizontal header 定义了水平header
- hmtx: Horizontal metrics 定义了水平metric
- maxp: Maximum profile 用于为字体分配内存
- name: Naming table 定义字体名称、风格名以及版权说明等
- glyf: 字形数据即轮廓定义和调整指令
- OS2: OS2 and Windows specific metrics
- post: PostScript information
我们将字体解密并保存到本地看看:
import requests
from fontTools.ttLib import TTFont
import re
import base64
url = 'https://cs.58.com/chuzu/?PGTID=0d100000-0019-e310-48ff-c90994a335ae&ClickID=4'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
}
response = requests.get(url,headers=headers)
html_text = response.text
# print(html_text)
pattern = r"base64,(.*?)'" # 提取加密信息
result = re.findall(pattern, html_text) # 返回列表
if result: # 避免有的页面没有使用加密
print(type(result), len(result))
base64str = result[0]
fontfile_content = base64.b64decode(base64str) # 通过base64编码的数据进行解码,输出二进制
with open('58.ttf', 'wb') as f: # 生成字体文件
f.write(fontfile_content)
font = TTFont('58.ttf') # 加载字体文件
font.saveXML('58.xml') # 转换成xml文件
else:
print('没有内容')
base64str = ""生成的字体库文件58.ttf。

生成的xml文件:
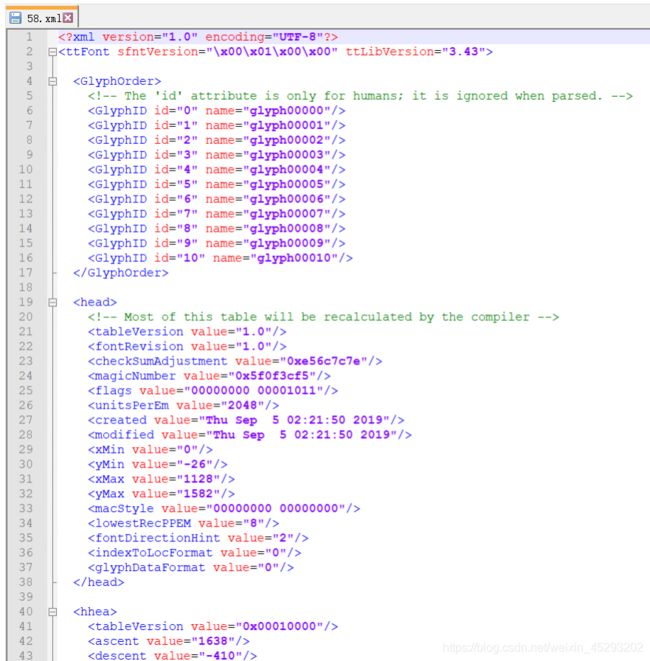
分析xml文件
我们来分析xml文件中映射关系。
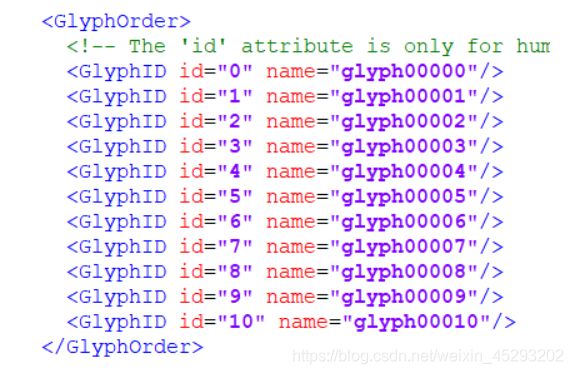
点开GlyphOrder标签,可以看到Id和name。这里id仅表示序号而已,而不是对应具体的数字:
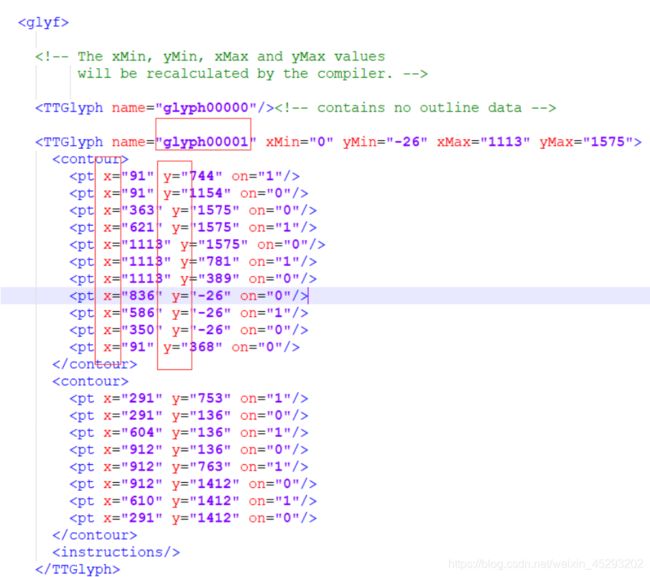
点开glyf标签,看到的是name和一些坐标点,这些座标点就是描绘字体形状的,这里不需要关注这些坐标点。
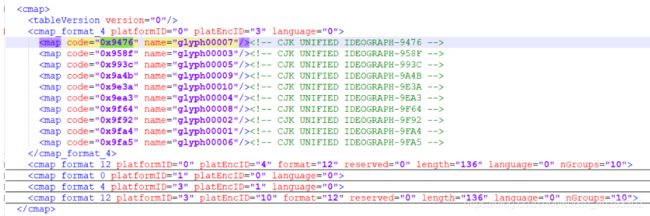
点开cmap标签,是编码和name的对应关系:
这里将字体文件导入到 http://fontstore.baidu.com/static/editor/index.html 网页将其打开,显示如下:

网页源码中显示的 鑶 跟这里显示的是不是有点像?事实上确实如此,去掉开头的 &#x 和结尾的 ; 后,剩余的4个16进制显示的数字加上 uni 就是字体文件中的编码。所以鑶对应的就是数字“6”,按照此就对应到glyph00007从这2张图我们可以发现,glyph00001对应的是数字0,glyph00002对应的是数字1,以此类推……glyph00010对应的是数字9。
用代码来获取编码和name的对应关系:
from fontTools.ttLib import TTFont
font = TTFont('58.ttf') # 打开本地的ttf文件
font.saveXML('58.xml') # 转换为xml文件
bestcmap = font['cmap'].getBestCmap() # 获取cmap节点code与name值映射
print(bestcmap)输出:
{38006: 'glyph00010', 38287: 'glyph00006', 39228: 'glyph00007', 39499: 'glyph00005', 40506: 'glyph00009', 40611: 'glyph00002', 40804: 'glyph00008', 40850: 'glyph00003', 40868: 'glyph00001', 40869: 'glyph00004'}输出的是一个字典,key是编码的int型,我们要将其转换为我们在xml看到的16进制一样以及与具体的数字映射关系:
for key,value in bestcmap.items():
key = hex(key) # 10进制转16进制
value = int(re.search(r'(\d+)', value).group()) -1 # 通过上面分析得出glyph00001对应的是数字0依次类推。
print(key,value)输出结果:
0x9476 6
0x958f 5
0x993c 4
0x9a4b 3
0x9e3a 7
0x9ea3 2
0x9f64 9
0x9f92 1
0x9fa4 0
0x9fa5 8现在就可以把页面上的自定义字体替换成正常字体,再解析了,全部代码如下:
import requests
from bs4 import BeautifulSoup
from fontTools.ttLib import TTFont
import re
import base64
import io
def base46_str(html_text):
pattern = r"base64,(.*?)'" # 提取加密部分
result = re.findall(pattern, html_text) # 返回列表
if result: # 避免有的页面没有使用加密
# print(type(result), len(result))
base64str = result[0]
bin_data = base64.b64decode(base64str) # 通过base64编码的数据进行解码,输出二进制
# # print(fontfile_content)
# with open('58.ttf', 'wb') as f:
# f.write(bin_data)
# font = TTFont('58.ttf') # 打开本地的ttf文件
# font.saveXML('58.xml')
# bestcmap = font['cmap'].getBestCmap()
# print(bestcmap)
fonts = TTFont(io.BytesIO(bin_data)) # BytesIO实现了在内存中读写bytes,提高性能
bestcmap = fonts['cmap'].getBestCmap()
# print(bestcmap) # 字典
# for key,value in bestcmap.items():
# key = hex(key) # 10进制转16进制
# value = int(re.search(r'(\d+)', value).group()) -1
# print(key,value)
# 使用字典推导式
cmap = {hex(key).replace('0x', '&#x') + ';' : int(re.search(r'(\d+)', value).group(1)) - 1 for key, value in bestcmap.items()}
# print(cmap)
for k,v in cmap.items():
html_text = html_text.replace(k, str(v))
return html_text
else:
print('没有内容')
base64str = ""
return html_text
def parse_html(html_text):
bs = BeautifulSoup(html_text, 'lxml')
# 获取房源列表信息,通过css选择器来
lis = bs.select('li.house-cell')
# 获取每个li下的信息
for li in lis:
href = li.select('h2 a')[0]['href']
title = li.select('h2 a')[0].stripped_strings # stripped_strings获取某个标签下的子孙非标签字符串,会去掉空白字符。返回来的是个生成器
room = li.select('div.des p')[0].stripped_strings
money = li.select('.money')[0].get_text().replace('\n','') # 获取某个标签下的非标签字符串。返回来的是个字符串。
print(href, list(title)[0], list(room)[0], money)
if __name__ == '__main__':
url = 'https://cs.58.com/chuzu/?PGTID=0d100000-0019-e310-48ff-c90994a335ae&ClickID=4'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
}
response = requests.get(url, headers=headers)
html_text = response.text
html_text = base46_str(html_text)
parse_html(html_text)输出结果:
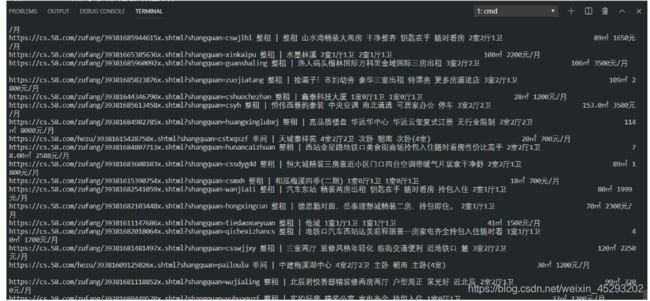
至此,58同城字体相关差不多了。
拓展
上面只是简单的字体反爬,像汽车之家,猫眼电影,我们可以去挑战一下。