Pytorch入门之张量
PyTorch是什么?
这是一个基于Python的科学计算包,其旨在服务两类场合:
- 替代numpy发挥GPU潜能
- 一个提供了高度灵活性和效率的深度学习实验性平台
pytorch下的张量类似于numpy下的数组,并且张量也可用于在GPU上对程序进行加速
Tensor的定义:
torch.tensor(data, dtype=None, device=None, requires_grad=False)
1、Tensor的创建:
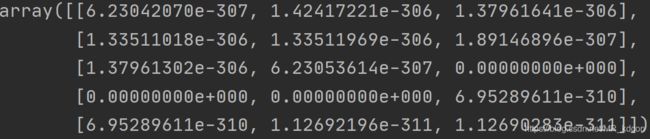
1.1、创建(5,3)未初始化的数据:
数组:numpy.empty([5, 3])
张量:torch.empty(5, 3)
运行结果:
数组
张量
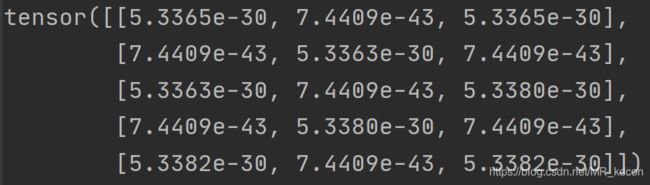
note:numpy下创建多维数组,参数要是一个列表;torch下只需直接输入数字;同理初始化张量的方式还有ones、zeros。
1.2、创建随机初始化的Tensor
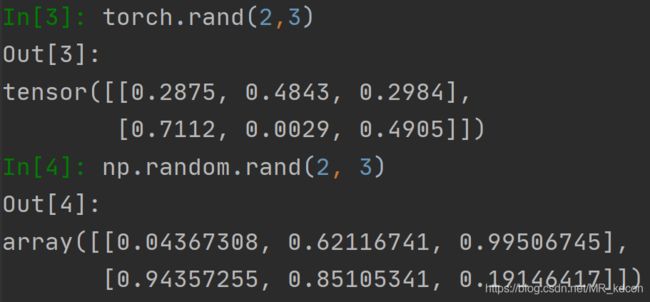
显然,pytorch创建随机数更方便
1.3、创建指定内容的Tensor

1.4、张量和数组的继承
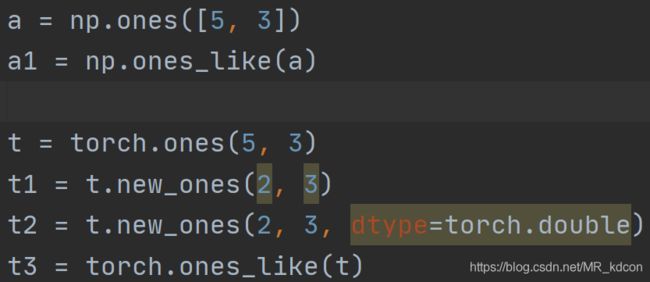
note:数组没有new_ones这种方法
1.5、张量和数组创建标准正态分布的数据
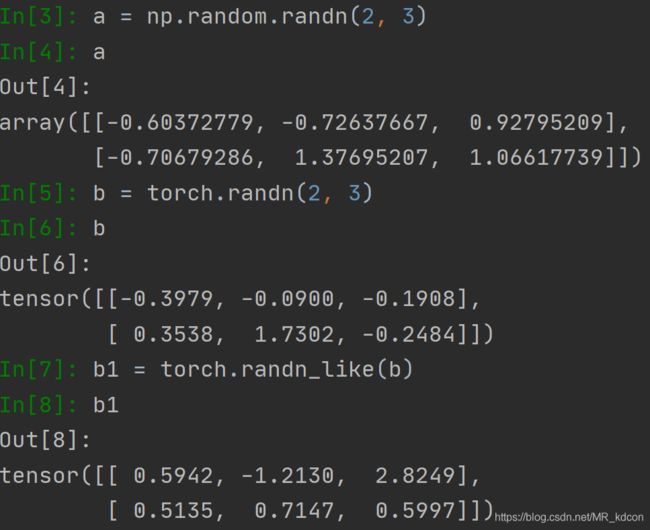
note:数组没有randn_like这种继承方式
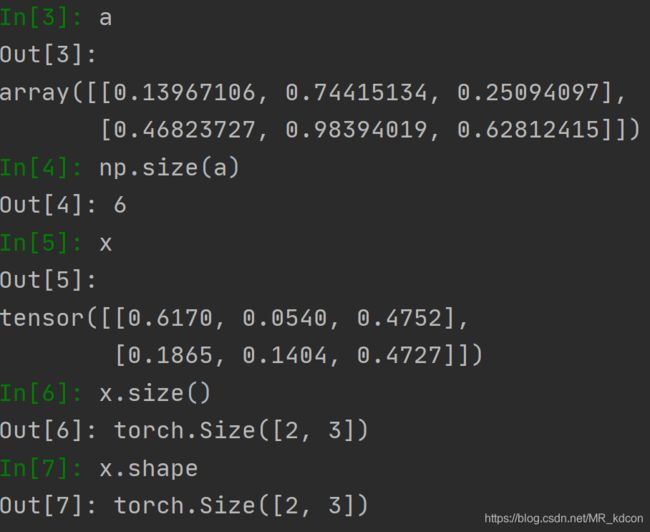
1.6、size的用法,
数组和张量的用法是不一样的,数组返回元素个数,张量返回其规模,类似于shape.size()方法返回一个Size类对象,和Tensor类对象一样具有相同的索引方式
size()写参数,输出特定维度上的维数:
x = torch.FloatTensor(2, 4)
print(x.size(0), x.size(1)) #2 4
除了上面这些创建Tensor的方法之外,还有
arange(first,last,step),从first到last,步长为step
linspace(first,last,steps),从first到last切成steps等分
normal(mean,std,*size) 均值为mean,方差std的标准正太分布
另外还有构建Tensor的基础构造函数,参考https://blog.csdn.net/MR_kdcon/article/details/108916724
note:这些函数都可以指定dtpye、device
2、Tensor的操作
2.1、add用法(总算来了一个数组和张量都一样的用法)
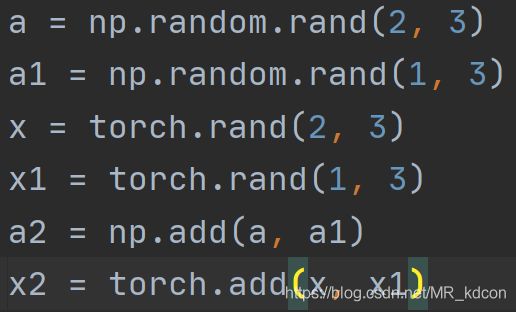
note:
add函数会生成一个新的tensor变量, add_ 函数会直接再当前tensor变量上进行操作,于函数名末尾带有"_" 的函数都是会对Tensor变量本身进行操作的,称为in-place操作。add_是针对类的方法,而不能当函数调用
另外add还可以指定输出,torch.add(x, x1, out=x),这也是in-place操作,所有的in-place操作的是和原数据共享内存,即id一样
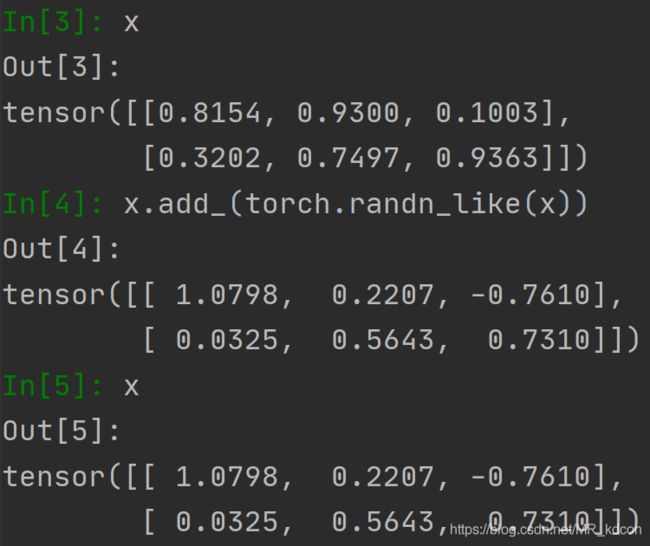
add_还可以实现乘法操作:
lr = 10
g = torch.rand(2, 3)
p = torch.arange(6, dtype=torch.float32).view(2, 3)
print(g)
print(p)
print(p.add_(lr, g)) # 等价于p += lr*g
2.2、更改数组或张量的规模reshape、view
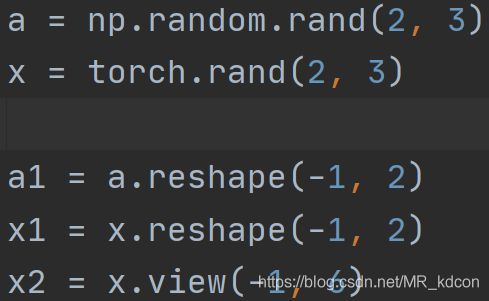
note:对于张量,reshape和view都可以用,但数组没有view这个用法。view这也是个in-place操作,即操作后的新Tensor和旧Tensor共享内存。至于reshape,我们却不能保证起返回的也是个拷贝,不推荐使用。想要获得一个不共享内存的副本的推荐做法:
x_1 = x.clone().view(-1, 6)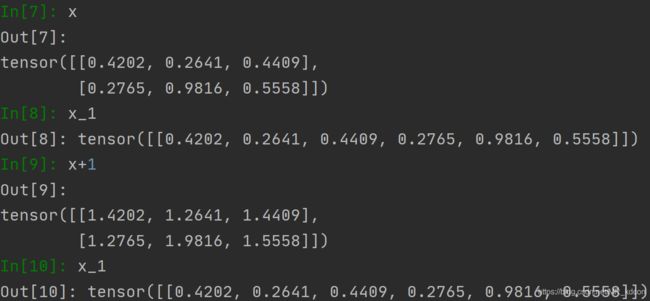
可以看出x_1和x是完全独立的2个Tensor了!
关于复制,也要提一下
张量复制运用 clone、detach函数
clone():完全复制、开辟新内存,仍留在计算图中,即参与梯度运算
detach():完全复制,和原变量为共享存储器,但离开计算图
clone().detach():完全复制,开辟新内存,离开计算图
copy_:完全复制,开辟新内存,仍留在计算图中,即参与梯度运算
x = torch.tensor([5.,6,2,1,4], requires_grad=True)
y = torch.Tensor(5) # 只是复制数据,不共享,所以size要一样
y.copy_(x)
print(id(x) == id(y)) # False
print(x, y) # tensor([5., 6., 2., 1., 4.], requires_grad=True) tensor([5., 6., 2., 1., 4.], grad_fn=)
print(y.requires_grad) # True
y += 1
print(x, y) # tensor([5., 6., 2., 1., 4.], requires_grad=True) tensor([6., 7., 3., 2., 5.], grad_fn=) clone和copy的区别在于,clone可以size不一样或者不需要有一个Tensor等着被复制:
x = torch.tensor([5.,6,2,1,4], requires_grad=True)
y = x.clone()
print(id(x) == id(y)) # False
print(x, y) # tensor([5., 6., 2., 1., 4.], requires_grad=True) tensor([5., 6., 2., 1., 4.], grad_fn=)
print(y.requires_grad) # True
y += 1
print(x, y) # tensor([5., 6., 2., 1., 4.], requires_grad=True) tensor([6., 7., 3., 2., 5.], grad_fn=)
Note:
列表、自定义类、python数字、字典的复制用copy()、deepcopy()。
numpy数组的复制用copy
张量的复制用clone()、detach()、clone().detach()
2.3、张量的索引:
索引出的新Tensor和源Tensor共享内存
x_1 = x[1, :]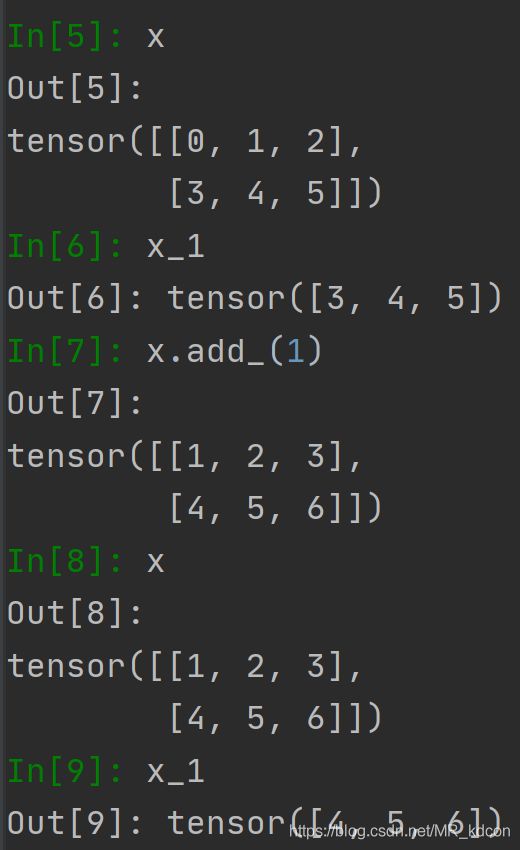
列表、numpy数组、张量索引的小区别:
a = [1, 2, 3, 4, 5]
b = np.array(a)
c = torch.tensor(a)
print(a[3], type(a[3]))
print(b[3], type(b[3]))
print(c[3], type(c[3]))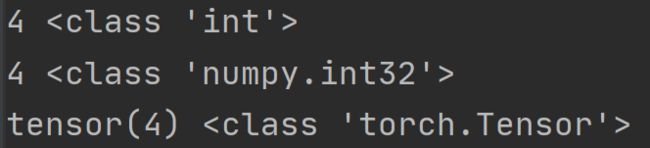
带“:”这种整行整列的索引是具有降维的功能的,而部分索引是不会改变原始的维度的
x = torch.rand(2, 3, 4)
print(x)
y = x[:, -1, :]
print(y)输出:
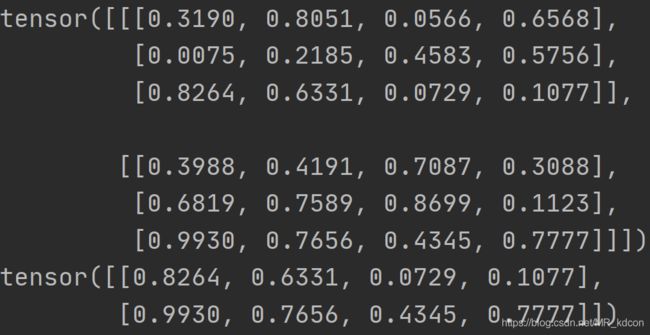
注意:tensors used as indices must be long, byte or bool tensors
tensor做索引的时候,必须为long类
index = torch.from_numpy(np.random.choice(6, 3))
index = index.long()
x = torch.rand(6, 5)
y = x[index, :3]
z = x[index, -1]
注意:当切片为1时,如z,输出是向量
2.4、张量之线性代数
pytorch还支持线性函数,这里不具体写出来了,给个表,大家用的时候可以去查看

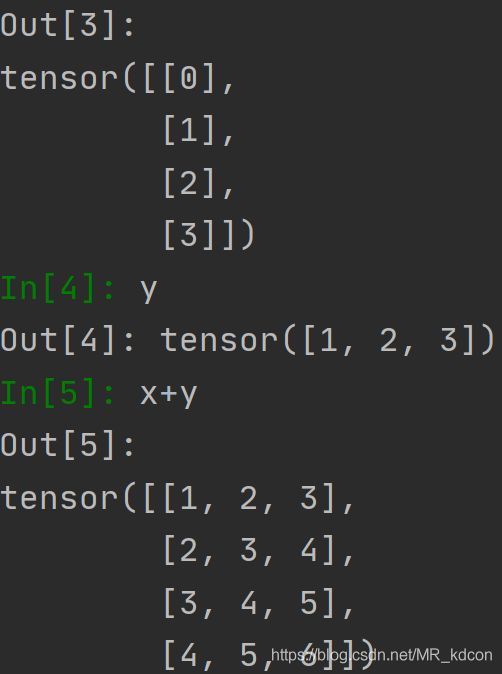
2.5、张量的广播机制:
相信用过numpy的都知道这个吧,Tensor也支持
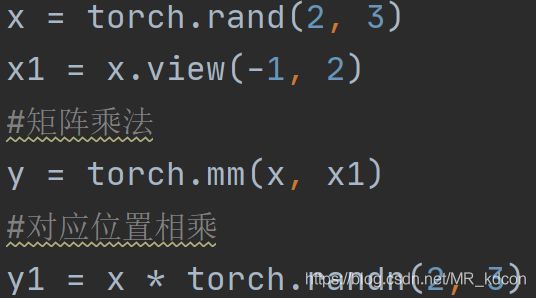
2.6、张量乘法
mm:二维张量做矩阵乘法、对应位置相乘
matmul:多维张量做矩阵乘法,带广播机制。
Note:matmul,其输入可以是一维张量(即张量向量),也可以是多维张量,但不能是张量标量。
例如:
x = torch.tensor([2,3,4])
y = torch.arange(12).view(3, 4)
z = torch.matmul(x, y) # 一维张量:tensor([44, 53, 62, 71])
注意:输出和输入一样都是1维的,不要误认为输出的shape是(1, 4)x = torch.tensor(5)
y = torch.arange(8).view(1,8)
# 或者
y = torch.arange(8).view(8)
z = torch.matmul(x, y) # RuntimeError: both arguments to matmul need to be at least 1D, but they are 0D and 2D
print(z)具体可参考:https://blog.csdn.net/weixin_42105432/article/details/100691592?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf
关于addmm:由于是mat1和mat2参与矩阵乘法,所以dim>=2
x = torch.tensor([2, 3, 0, 5])
y = torch.arange(12).view(3, 4)
z = torch.arange(6).view(2, 3)
res = x.addmm(mat1=z, mat2=y, beta=1, alpha=1) # res = β*x + α*(mat1@mat2),@为矩阵乘法符号
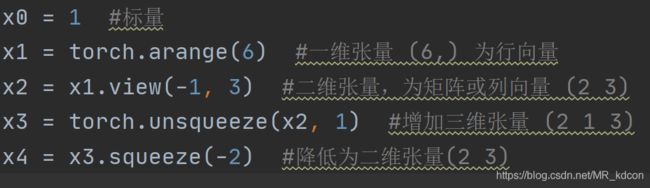
2.7、张量的增维和减维(挤维) unsqueeze、squeeze
torch.squeeze(input, dim=None, out=None)
1、当不给定dim时,将输入张量形状中的1 去除并返回
2、当给定dim时,那么挤压操作只在给定维度上,当这个给定的dim为1的时候,才有效,否则,函数是无效的
3、返回张量与输入张量共享数据内存,所以改变其中一个的内容会改变另一个。
4、dim为负数时候,-1表示最后一个,以此类推,如数据的维度(2,3,1),squeeze(input,-1)降低第二维成(2,3)
torch.unsqueeze(input, dim, out=None)
1、给定的dim是最终生成的dim,如dim=2,是最终生成的张量中,第二维的大小为1
2、返回张量与输入张量内存不共享。
3、dim为负数时候,-1表示最后一个,以此类推,如数据的维度(2,3),unsqueeze(input,-1)扩张第二维成(2,3,1)
2.8、堆叠函数stack:用于扩展张量的维数
调用格式 d=torch.stack( (a,b,c) ,dim) 其中a、b、c为相同维数的张量,dim为指定的张量堆积方向。如abc分别为二维张量,dim=0,表明形成三维张量后第0维为堆积方向。
先来看一下三维的数据大致的形状,三维是几个2维数据按一定方向堆叠起来的,但不管怎么堆叠,可以始终看成一个长方体
以此类推
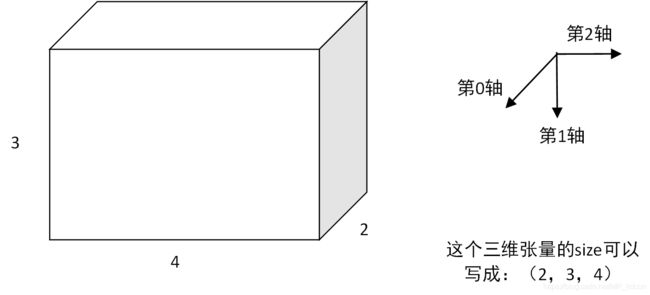
以具体例子来看
abc分别为(2,4)的二维张量
当dim=0,表明3张平面向着第0轴的方向堆叠,故容易得出最后的规模为(3,2,4)
然后用数据验证下:
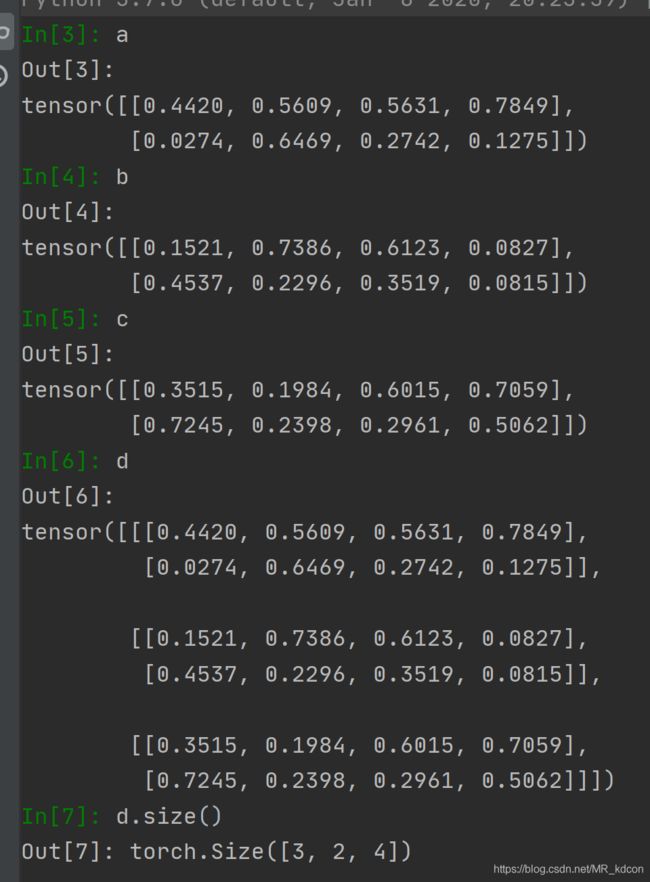
继续,当dim=1时,表明3张平面按第1维的方向堆叠,易得出最后的规模(2,3,4)
验证:
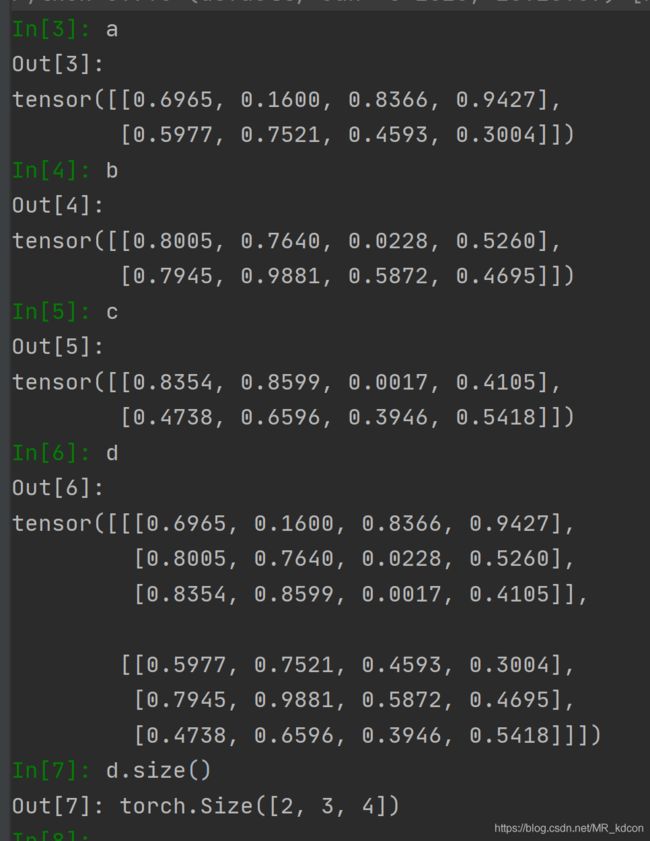
继续,当dim=2,表明3个平面按第2轴的方向堆叠,容易的出最后的张量规模(2,4,3)
验证:
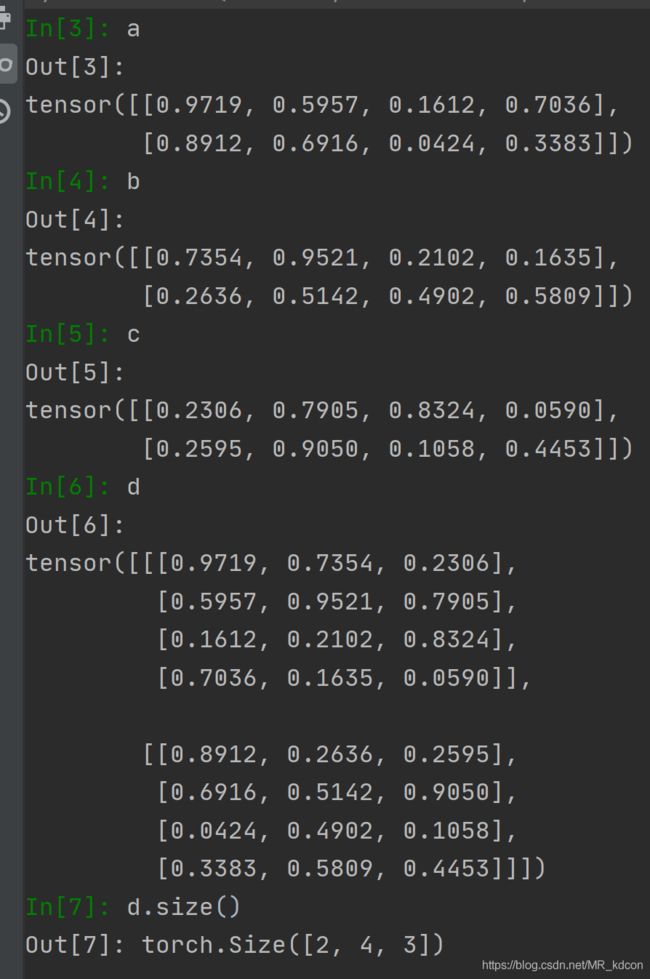
需要注意的是,d=torch.stack( (a,b,c) ,dim) ,表示堆叠的时候,按abc的顺序依次向着堆叠方向放平面,顺序不要错了。
2.9、CUDA张量,将张量移送到GPU上进行运算
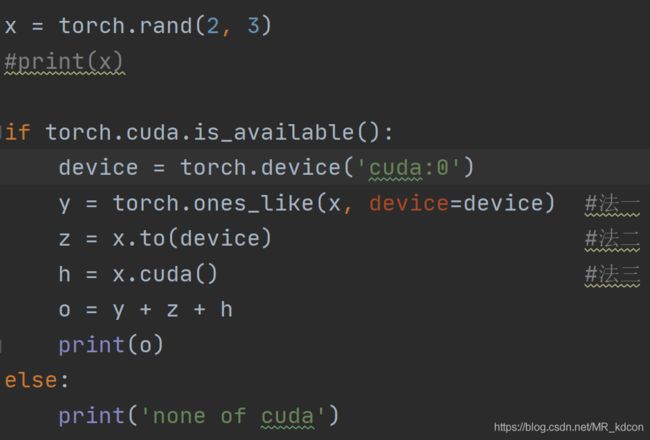
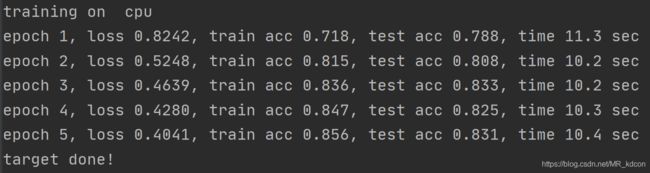
脚本的运行时间将比cpu下快很多
下面这个是我以前跑的一个网络在cpu和gpu下的速度对比,记录的时间差是一个epoch训练的时间:
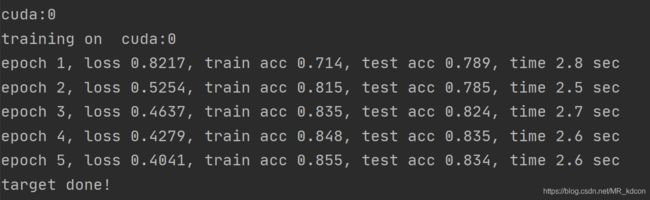
我们将代码在cpu转到gpu上运行的时候,要注意将导入的训练集、测试集数据、搭建的网络模型、模型内部新建的张量是否放到了CUDA上 p = torch.tensor([1]).to(device),之后再在gpu上跑才不会出错。
比如
device = torch.device('cuda:0')
train_set = train_set.to(device)
net = net.to(device)note:
1、net、和train_set必须得是张量
2、GPU Tensor不能直接转为numpy数组,必须先转到CPU Tensor。
output,cuda().data.numpy()是不对的
output.cuda().data.cpu().numpy()才是正确的
3、自己写的模块也要导入到服务器同目录下,且该文件对应解释器也要换,比如d2lzh_pytorch_ton.py
3、张量的高级用法1
3.1、张量的求平均、最大值
运用mean函数,通过设置参数,该函数具有降维的作用,具体来看
调用格式:torch.mean(x, dim, keepdim)
x为求取平均的tensor对象,需要为float型,dim为指定维的方向求平均,keepdim为保持输出维度,True时为指定的dim维度+1,False为默认值,即不保持输入维度,即dim维度消失,实现了降维。
接下来看3个例子就可以明白这个函数具体怎么工作了:
第一个例子
x = torch.rand(4, 2, 3) #三维张量
x1 = torch.mean(x, dim=0, keepdim=True) #因为keepdim=True,所以x1维度保持3维
x2 = torch.mean(x1, dim=1, keepdim=True) #因为keepdim=True,所以x2维度保持3维
x3 = torch.mean(x2, dim=2, keepdim=True) #因为keepdim=True,所以x3维度保持3维
输出

第二个例子
x = torch.rand(4, 2, 3)
x1 = torch.mean(x, dim=0) #keepdim=False,则x1为2维张量
x2 = torch.mean(x1, dim=0, keepdim=True)
x3 = torch.mean(x2, dim=1, keepdim=True)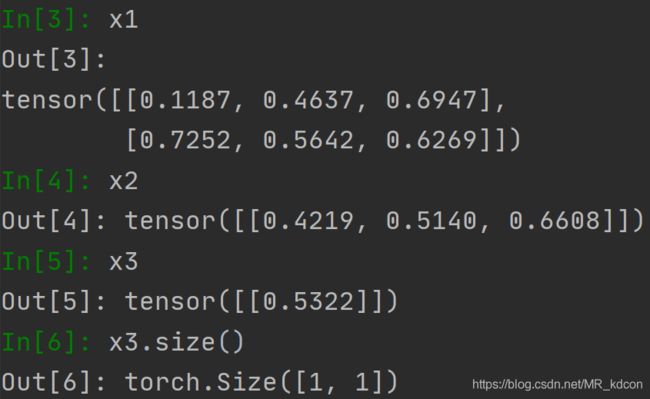
第三个例子
x4 = torch.mean(x),无任何参数,直接降成标量
同理,sum和mean一模一样的调用格式,不用keepdim的话也是会减维的:
a = torch.arange(6).reshape(2, 3)
b = torch.sum(a, dim=0)
bb = torch.sum(a, dim=1)
bbb = torch.sum(a, dim=1, keepdim=True)
c = np.arange(6).reshape(2, 3)
d = np.sum(c, axis=0)
dd = np.sum(c, axis=1)
ddd = np.sum(c, axis=1, keepdims=True)
torch.max():默认下起着降维作用,且输出为最大值和索引
Note:np.max(input,dim)只返回最大值,而没有相应的索引。

举例:
x = torch.rand(3, 4)
y = torch.max(x, 1)
print(y[0])
print('-----')
print(y[1])
x
tensor([[0.3912, 0.3590, 0.0779, 0.2653],
[0.3708, 0.0964, 0.9801, 0.1620],
[0.8771, 0.9678, 0.4596, 0.0743]]
y
torch.return_types.max(
values=tensor([0.3912, 0.9801, 0.9678]),
indices=tensor([0, 2, 1]))
输出结果:
tensor([0.3912, 0.9801, 0.9678])
-----
tensor([0, 2, 1])
或者Tensor.max(dim):
x = torch.rand(6, 5)
y = x.max(1)
max方法也是返回2个对象,和torch.max是一样的。
Note:无dim下,没有索引,相当于torch.mean(x)输出只有一个值
x = [1,5,2]
x = torch.tensor(x)
y = torch.max(x) # tensor(5)
对比:
x = [1,5,2]
x = torch.tensor(x)
y = torch.max(x, dim=0)
输出:
# torch.return_types.max(
# values=tensor(5),
# indices=tensor(1)) 3.2、张量的选择性抽取index_select()
经常用于抽取batch数据
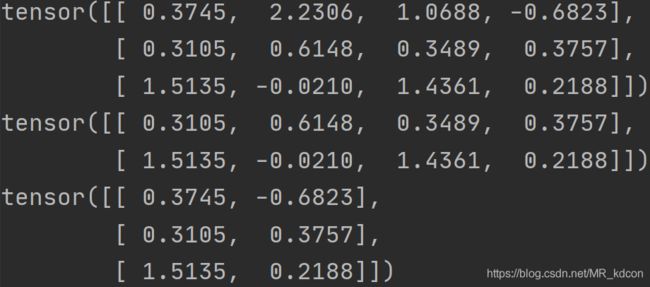
x = torch.normal(0, 1, (3, 4))
print(x)
row_select = torch.index_select(x, 0, torch.tensor([1, 2])) # 选择性按行抽取
col_select = torch.index_select(x, 1, torch.tensor([0, 3])) # 选择性按列抽取
print(row_select)
print(col_select)第一个参数是抽取对象x
第二个参数0:按行抽取 1:按列抽取
第三个参数:为一个Tensor,其值为抽取哪几行(列),至于抽行还是抽列,取决于第二个参数为0还是1
运行结果:
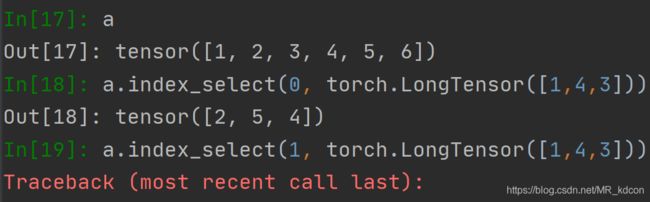
当抽取的数据是向量的时候,第二个参数只能为0,为按列抽取,为1的话会报错:
3.3、张量数组的互相转化
必须要强调一下,数组和张量相互转化时候,两者共用一个存储地址,因此两者的相互转化会非常快
3.3.1、张量转为数组
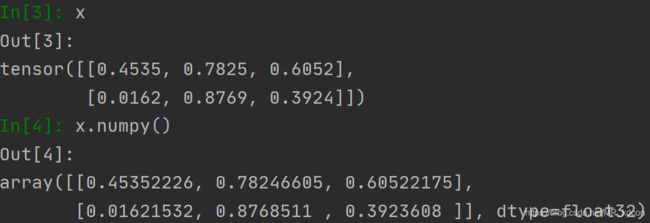
note:
需要注意的是如果待转换的张量带有梯度信息,则转换成numpy会破坏其计算图,故要在转换前用detach解除掉required_grad。
具体可参考:https://blog.csdn.net/discoverer100/article/details/103902130
3.3.2、数组转为张量 调用函数from_numpy
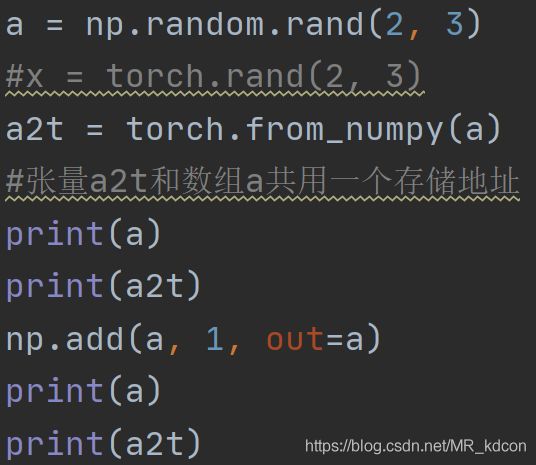
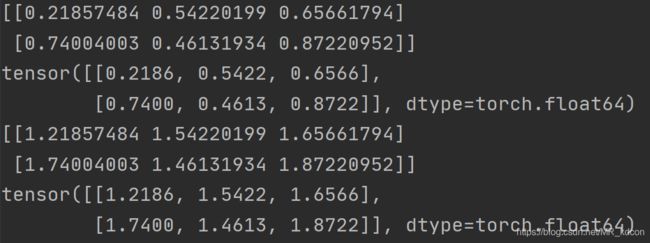
从最后4行结果也可以看出,从数组转化而来的张量和数组共用一个地址
那想要不共享地址咋办呢?
这是数组转为张量的另一种做法
y = torch.tensor(x)运行一下:
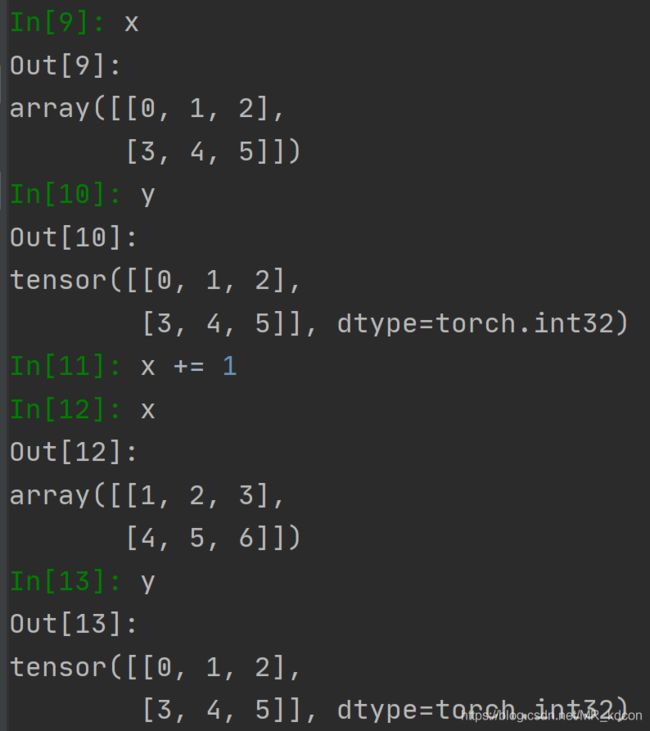
数组改变,张量并没变,两者内存独立!
3.4 内存
这个必须得说一下,因为大家从上面可以看出,有些张量用法会共享内存,有些则不会,这个其实是很重要的,比如a、b共享内存,你改了a的数据,要是不知道共享关系,b暗暗改了你都不知道,那么下面我来解释一下,相信你们看就知道咋回事了。
首先大框架下,python的内存管理采用“引用”机制,就是说变量是一份内存的引用,每个变量不一定都占据一份单独的内存空间,可能有多个变量对应同一个内存空间的情况。比如
x = torch.tensor(5)
y = x
print(id(x) == id(y)) # True
然后我们到pytorch下,在pytorch中,张量的存储分为头信息区(Tensor)和存储区(Storage)。信息区主要保存着tensor的形状(size)、步长(stride)、数据类型(type)等信息,而真正的数据则保存成连续数组,存储在存储区。
通过id(tensor.storage)来获取“存储区”,id(tensor)是整个tensor所占的内存地址(包括信息区和存储区),而 id(tensor.storage)只是该tensor存储区的内存地址,因此我们常说的共享内存一般都是指存储区相同,即id(tensor.storage)
那么对于张量的操作,哪些是整个id相同,哪些只是内存共享呢?
内存共享(存储区相同)
切片操作、view方法、data和detach复制、与numpy.Array转换、数据类型转换
id完全相同(内存相同)
in-place操作、自增操作等
例1
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
y[:] = x + y
id_now = id(y)
print(id_before == id_now) #True例2
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
y += x
id_now = id(y)
print(id_before == id_now) #Truenote:y=y+x,是会开辟新的内存空间的
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
y = x + y
id_now = id(y)
print(id_before == id_now) #False例3
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
torch.add(x, y, out=y)
id_now = id(y)
print(id_before == id_now) #True例4
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
y.add_(x)
id_now = id(y)
print(id_before == id_now) #True例5
#2个张量内存共享并比代表2个张量的值相等
x = torch.rand(2, 3, requires_grad=True)
print(x.requires_grad) #True
y = torch.detach(x) #或者y = x.detach()
z = x.detach_() #或者x.detach()
print(id(x) == id(y)) #False
print(id(x) == id(z)) #True
print(id(x.storage()) == id(y.storage())) #True
print(id(x.storage()) == id(z.storage())) #True
print(x.requires_grad) #False
print(y.requires_grad) #False
print(z.requires_grad) #False例6
x = torch.arange(6).view(2, 3)
y = x.view(3, 2)
z = x.add_(1)
y = y.float()
print(id(x.storage()) == id(y.storage())) # True
print(id(x) == id(z)) # True
print(x.dtype) # torch.int64
z = z.float()
print(id(x) == id(z)) # False因为dtype属性在信息区,所以y的改变不影响x,因为x和z的信息区不共享,但是z的改变,直接导致x与y变成了数据共享。
例7
x = torch.rand(2, 3, requires_grad=True)
y = x.view(3, 2)
z = x
print(y.requires_grad) #True
print(z.requires_grad) #True
x.requires_grad_(False)
print(y.requires_grad) #True
print(z.requires_grad) #False因为requires_grad在信息区,所以x的requires_grad改变不会影响到y,但是直接影响到了z,因为z和y信息区是共享的。例8:存储区有共享的说法,共享就是一个变,另外一个也跟着变(地址一样不等同于共享)。但是头信息区没有共享的说法
x = torch.tensor([5,6,2,1,4], dtype=torch.float64)
y = x
print(id(y), id(x)) # 2379049157080 2379049157080
y = y.long()
print(id(y), id(x), x.dtype) # 2379095510936 2379049157080 torch.float64
y += 1
print(y, x) # tensor([6, 7, 3, 2, 5]) tensor([5., 6., 2., 1., 4.], dtype=torch.float64)
3.5、gather用法
用于抽取所需要的值
关于gather的用法,网上一位博主说的挺好的了,唯一就有个错误,dim=0应该是沿着列方向,dim=1,沿着行方向,那位博主可能笔误写反了。原文链接:https://blog.csdn.net/lucky_rocks/article/details/79676095
note:
1、gather的第二个参数必须为long或者int64。
2、返回的size和第二个参数的size一模一样
3、也可以用Tensor.gather方法:Tensor.gather(dim, src)
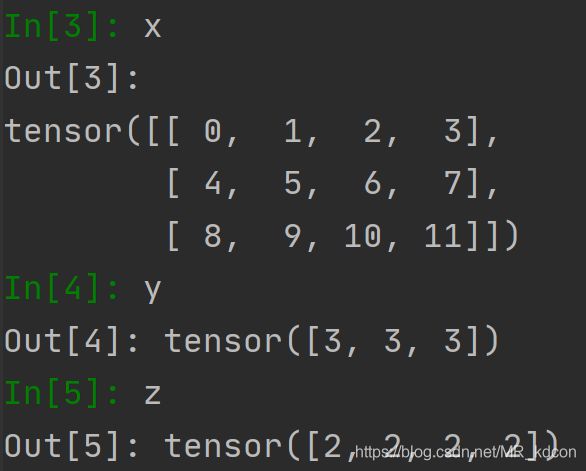
3.6、argmax用法
x = torch.arange(12).view(3, 4)
y = x.argmax(dim=1)
z = x.argmax(dim=0)
note:
不管沿着哪个轴,结果都是向量。
3.7、拼接函数torch.cat
用法1:用于拼接2个Tensor
用法2:用于拼接list中的Tensor
直接上examples
例1:
x = torch.arange(9, dtype=torch.float32).view(-1, 3)
y = torch.rand(3, 3)
z = torch.cat((x, y), 0)
t = torch.cat((x, y), 1)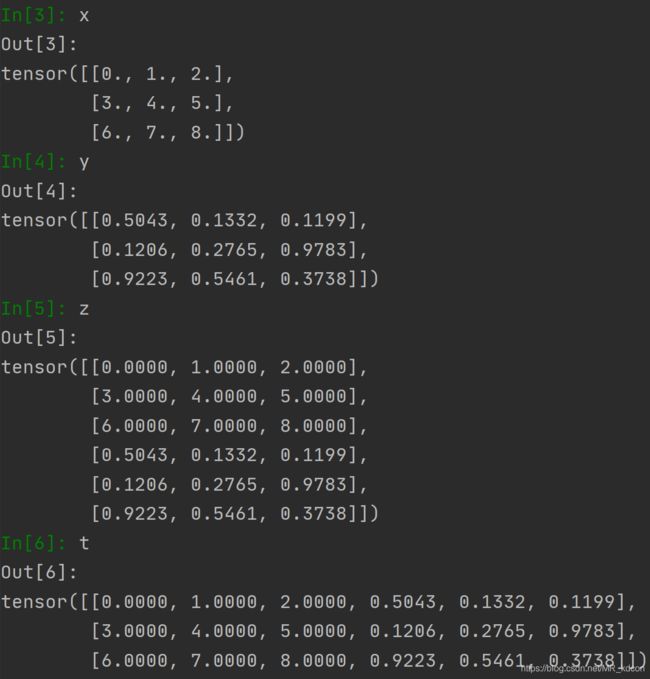
例2:
x = torch.tensor([[1], [2], [3]])
y = [x*2 for i in range(3)]
z = torch.cat(y, 1)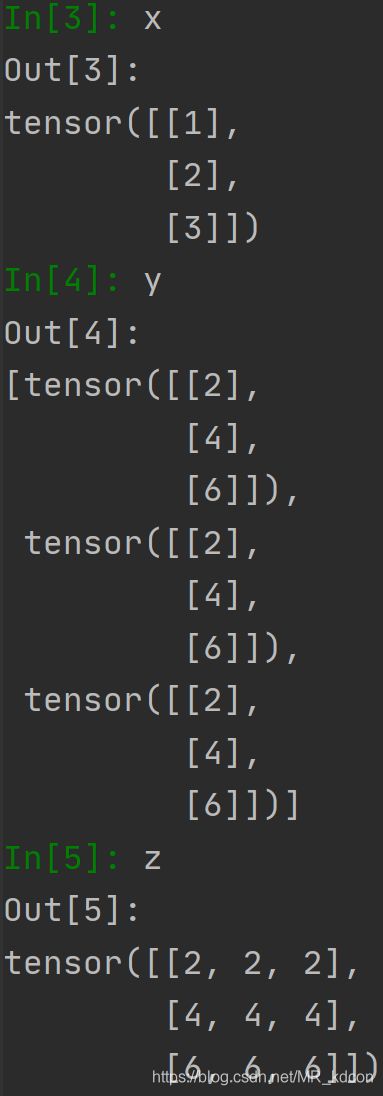
例3:向量的cat用法:第二个参数只能为0
a = torch.tensor([1, 2, 3, 4, 2])
b = torch.tensor([5, 12, 8, 3, 2])
c = torch.cat((a, b), 0)

3.8、求范数norm
参考一位博主的链接,挺详细的:https://www.cnblogs.com/wanghui-garcia/p/11266298.html
3.9、张量类型转换:
在已知某个张量a时候,想转为torch.float32型
在pytorch中,数据我们都要求是float32(不能是double),而在crossentropy的loss中,对于标签必须是long,所以有必要对这两个常用转换说明下:
a = torch.arange(6).view(2, 3) # torch.int64
b = a.float() # torch.float32
b = b.long() # torch.long
# c = float(a) # 报错,只能是一个元素的tensor才可以转为float类型的python数字
c = torch.tensor(1)
d = float(c) # 1.0
e = c.item() # 1
4、张量的高级用法2
4.1、scatter
转载一位网友的博客:https://www.cnblogs.com/dogecheng/p/11938009.html
总的来说,就是修改源张量在指定位置上的值。
scatter经常用来制作one-hot格式的张量,
此时index应该是一个(self.size()[0], 1)格式的张量,src=1, dim=1
index中的数字k表示self中为各个行中第k列需要填1。
4.2、torch.topk(输出不改变输入的维度)
取前k个最大值
https://blog.csdn.net/u014264373/article/details/86525621
x = torch.rand(1, 1, 4, 4)
topk_score, topk_index = torch.topk(x.view(1, 1, -1), 5)结果:
topk_score
Out[3]: tensor([[[0.9532, 0.8936, 0.7963, 0.7864, 0.7533]]])
topk_index
Out[4]: tensor([[[ 1, 3, 5, 15, 10]]])
x
Out[5]:
tensor([[[[0.4969, 0.9532, 0.0645, 0.8936],
[0.7131, 0.7963, 0.5657, 0.0109],
[0.3206, 0.5667, 0.7533, 0.5983],
[0.5734, 0.2227, 0.6943, 0.7864]]]])
x = torch.rand(1, 1, 4, 4)
topk_score, topk_index = torch.topk(x, 1)结果:
x
Out[3]:
tensor([[[[0.3721, 0.8697, 0.8054, 0.4166],
[0.5272, 0.9096, 0.0176, 0.7818],
[0.4071, 0.9833, 0.1836, 0.8599],
[0.9032, 0.4303, 0.3872, 0.8872]]]])
topk_score
Out[4]:
tensor([[[[0.8697],
[0.9096],
[0.9833],
[0.9032]]]])
topk_index
Out[5]:
tensor([[[[1],
[1],
[1],
[0]]]])
4.3、expand
维度扩展
注意:
1、新增的维度写在前面
2、数据共享
例1
x = torch.tensor([1, 2, 3], dtype=torch.float32) # (3, )
y = x.expand(5, 3) # y = x.expand(3, 5)就不行
print(x)
print(y)
print(id(x) == id(y))
print(id(x.storage()) == id(y.storage()))结果:
tensor([1., 2., 3.])
tensor([[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.]])
False
True
例2:
x = torch.arange(6, dtype=torch.float32).view(2, 3)
y = x.expand(4, 2, 3)
print(x)
print(y)
结果:
tensor([[0., 1., 2.],
[3., 4., 5.]])
tensor([[[0., 1., 2.],
[3., 4., 5.]],
[[0., 1., 2.],
[3., 4., 5.]],
[[0., 1., 2.],
[3., 4., 5.]],
[[0., 1., 2.],
[3., 4., 5.]]])
例3:
与Size类联用:
x = torch.Size((2, 3))
y = torch.tensor([1,2,3])
y = y.expand(x)
结果:
tensor([[1, 2, 3],
[1, 2, 3]])
例4:任意维数的扩展
如果最后维度为1,则可以直接用expand扩展为任意
x = torch.rand(2, 3, 1)
y = x.expand(2, 3, 20)
如果是0维或(1,)的张量,则可以任意扩展
x = torch.tensor([3]) # 或者x = torch.tensor(3)
y = x.expand(torch.Size((2, 3)))
res:
tensor([[3, 3, 3],
[3, 3, 3]])
4.4、转置
permute:图片img的size比如是(28,28,3)就可以利用img.permute(2,0,1)得到一个size为(3,28,28)的tensor。
或者
transpose:https://blog.csdn.net/a250225/article/details/102636425
4.5、张量的连续性
continue
https://zhuanlan.zhihu.com/p/64551412
Note:numpy中数组Array也是行优先。
x = torch.arange(6).view(2, 3)
print(x)
print(x.stride()) # (3, 1)
print(x.is_contiguous()) # True
y = x.transpose(0, 1) # 或者 x.permute(1, 0)
print(y)
print(y.stride()) # (1, 3)
print(id(y.storage()) == id(x.storage())) # True
print(id(y) == id(x)) # False
print(y.is_contiguous()) # False
# z = y.view(-1) # 报错,因为view的工作方式只能根据底层一维数组按指定形状变形
# print(z)
t = y.contiguous()
print(t)
print(t.stride()) # 会创建一种新的底层一维数组存储方式 (2, 1)
print(id(y.storage()) == id(t.storage())) # True
print(id(y) == id(t)) # False
print(t.is_contiguous()) # True关于tensor.stride()
https://zhuanlan.zhihu.com/p/101434655
总结:Tensor在用transform或permute之后是不连续的,想要之后用view会报错,故要用方法contiguous先连续化
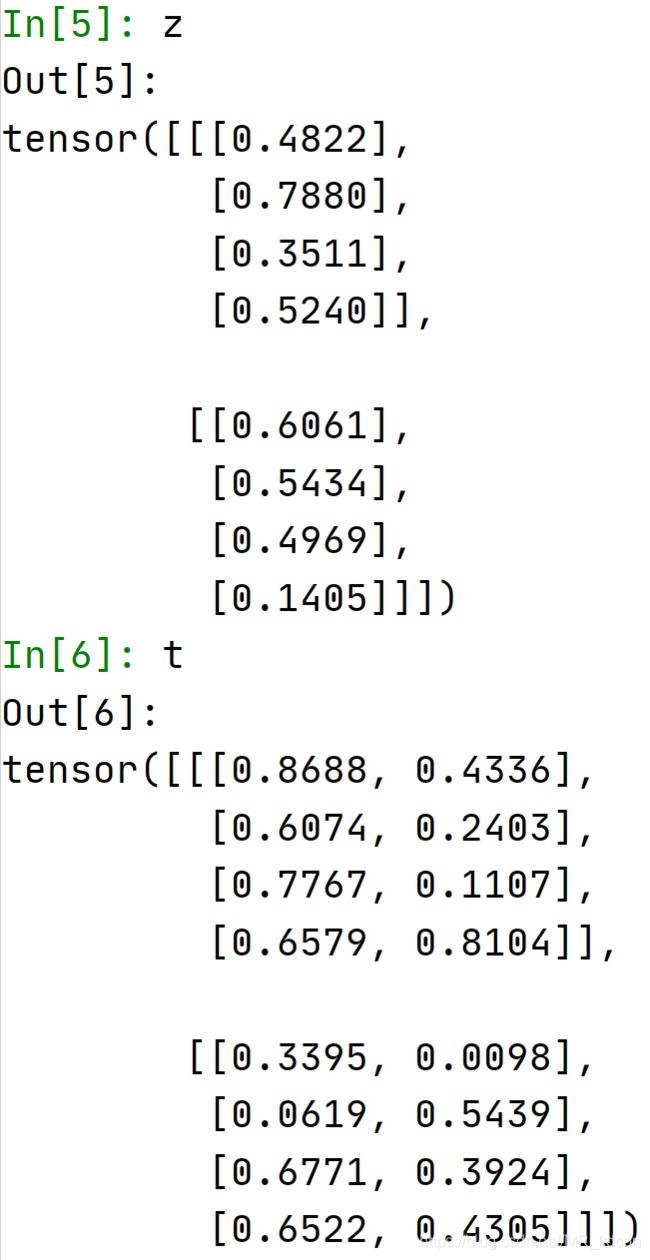
4.6、块抽取
多维数组按块抽取
x = torch.rand(2, 4, 3)
y = x[..., 0:1]
z = x[..., 2:3]
t = x[..., 0:2]
4.7、torch.nn.functional.max_pool2d(*args, **kwargs)
参数和池化层一样。
取一个map上每一块区域的最大值(或平均值)
x = torch.arange(16, dtype=torch.float32).view(4, 4)
x = torch.unsqueeze(x, 0)
x = x.unsqueeze(1)
y = F.max_pool2d(x, 2)
print(x)
print(y)结果:
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
tensor([[[[ 5., 7.],
[13., 15.]]]])
4.8、维度:
x = torch.rand(2,4,5)
print(x.dim()) # 3
y = np.random.rand(2,4,5)
print(y.ndim) # 3pytorch中的维度个数用dim,numpy中用ndim