pytorch list转tensor_PyTorch入门笔记创建张量
 关注"
AI机器学习与深度学习算法"公众号 选择"
星标 "公众号,原创干货,第一时间送达
关注"
AI机器学习与深度学习算法"公众号 选择"
星标 "公众号,原创干货,第一时间送达
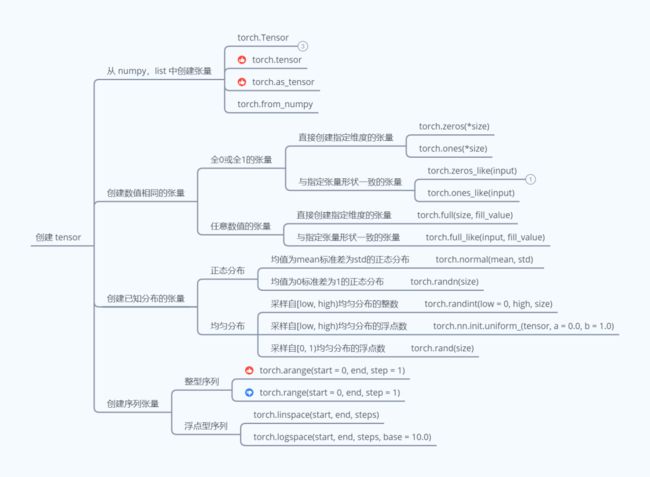
1. 从数组、列表对象创建
Numpy Array 数组和 Python List 列表是 Python 程序中间非常重要的数据载体容器,很多数据都是通过 Python 语言将数据加载至 Array 数组或者 List 列表容器,再转换到 Tensor 类型。(为了方便描述,后面将 Numpy Array 数组称为数组,将 Python List 列表称为列表。)
PyTorch 从数组或者列表对象中创建 Tensor 有四种方式:
- torch.Tensor
- torch.tensor
- torch.as_tensor
- torch.from_numpy
>>> import torch
>>> import numpy as np
>>> array = np.array([1, 2, 3])
>>> list = [4, 5, 6]
# 方式一:使用torch.Tensor类
>>> tensor_array_a = torch.Tensor(array)
>>> tensor_list_a = torch.Tensor(list)
>>> print(isinstance(tensor_array_a, torch.Tensor)
, tensor_array_a.type())
True torch.FloatTensor
>>> print(isinstance(tensor_list_a, torch.Tensor)
, tensor_list_a.type())
True torch.FloatTensor
# 方式二:使用torch.tensor函数
>>> tensor_array_b = torch.tensor(array)
>>> tensor_list_b = torch.tensor(list)
>>> print(isinstance(tensor_array_b, torch.Tensor)
, tensor_array_b.type())
True torch.LongTensor
>>> print(isinstance(tensor_list_b, torch.Tensor)
, tensor_list_b.type())
True torch.LongTensor
# 方式三:使用torch.as_tensor函数
>>> tensor_array_c = torch.as_tensor(array)
>>> tensor_list_c = torch.as_tensor(list)
>>> print(isinstance(tensor_array_c, torch.Tensor)
, tensor_array_c.type())
True torch.LongTensor
>>> print(isinstance(tensor_list_c, torch.Tensor)
, tensor_list_c.type())
True torch.LongTensor
# 方式四:使用torch.from_numpy函数
>>> tensor_array_d = torch.from_numpy(array)
# tensor_list_d = torch.from_numpy(list) error code
>>> print(isinstance(tensor_array_d, torch.Tensor)
, tensor_array_d.type())
True torch.LongTensor
# print(isinstance(tensor_list_d, torch.Tensor)
# , tensor_list_d.type())
通过上面代码的执行结果可以简单归纳出四种创建 Tensor 方式的差异:
- 只有 torch.Tensor 是类,其余的三种方式都是函数;
- torch.Tensor、torch.tensor 和 torch.as_tensor 三种方式可以将数组和列表转换为 Tensor,但是 torch.from_numpy 只能将数组转换为 Tensor(为 torch.from_numpy 函数传入列表,程序会报错);
- 从程序的输出结果可以看出,四种方式最终都将数组或列表转换为 Tensor(使用 isinstance 返回的结果都为 True),**但是转换后的 Tensor 数据类型却有所不同,在上一小节区分 torch.Tensor 和 torch.tensor 的时候提到过,当接收数据内容时,torch.Tensor 创建的 Tensor 会使用默认的全局数据类型,而 torch.tensor 创建的 Tensor 会使用根据传入数据推断出的数据类型。**可以通过
torch.get_default_dtype()来获取当前的全局数据类型,也可以通过torch.set_default_dtype(torch.XXXTensor)来设置当前环境默认的全局数据类型;
>>> import torch
>>> import numpy as np
>>> array = np.array([1, 2, 3])
>>> print(array)
int64
# 获取当前全局环境的数据类型
>>> print(torch.get_default_dtype())
torch.float32
# 方式一:使用torch.Tensor类
>>> tensor_array_a = torch.Tensor(array)
>>> print(tensor_array_a.type())
torch.FloatTensor
# 方式二:使用torch.tensor函数
>>> tensor_array_b = torch.tensor(array)
>>> print(tensor_array_b.type())
torch.LongTensor
# 设置当前全局环境的数据类型为torch.DoubleTensor
>>> torch.set_default_tensor_type(torch.DoubleTensor)
>>> tensor_array_a = torch.Tensor(array)
>>> print(tensor_array_a.type())
torch.DoubleTensor
>>> tensor_array_b = torch.tensor(array)
>>> print(tensor_array_b.type())
torch.LongTensor
**PyTorch 默认的全局数据类型为 torch.float32,因此使用 torch.Tensor 类创建 Tensor 的数据类型和默认的全局数据类型一致,为 torch.FloatTensor,而使用 torch.tensor 函数创建的 Tensor 会根据传入的数组和列表中元素的数据类型进行推断,此时 np.array([1, 2, 3]) 数组的数据类型为 int64,因此使用 torch.tensor 函数创建的 Tensor 的数据类型为 torch.LongTensor。**使用 torch.set_default_tensor_type(torch.DoubleTensor) 更改了默认的全局数据类型之后,使用 torch.Tensor 生成的 Tensor 数据类型会变成更改后的数据类型,而使用 torch.tensor 函数生成的 Tensor 数据类型依然没有改变,「当然可以在使用 torch.tensor 函数创建 Tensor 的时候指定 dtype 参数来生成指定类型的 Tensor。」
PyTorch 提供了这么多方式从数组和列表中创建 Tensor。一般来说,不推荐使用 torch.Tensor 类,因为不仅可以为 torch.Tensor 传入数据还可以传入形状(torch.tensor 只能传入数据,这样单一的功能可以防止出错),当为 torch.Tensor 传入形状时会生成指定形状且包含未初始化数据的 Tensor,如果忘记替换掉这些未初始化的值,直接输入到神经网络中,可能会让神经网络输出 NAN 或者 INF。「如果不考虑性能的话,推荐使用 torch.tensor。如果考虑性能,推荐使用 torch.as_tensor(torch.from_numpy 只能接受数组类型),因为使用 torch.as_tensor 生成的 tensor 会和数组共享内存,从而节省内存的开销。」
2. 创建全 0 或全 1 的张量
创建元素值为全 0 或全 1 的张量是非常常见的初始化手段,通过 torch.zeros() 和 torch.ones() 函数即可创建任意形状,且元素值全为 0 或全为 1 的张量。
torch.zeros(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)和torch.ones(*size, out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False) 两个函数的参数相同,这里简单介绍一下这些参数:
- *size: 定义输出张量形状的整数序列,这个整数序列可以是列表和数组之类的集合也可以是整数的 torch.Size(执行 tensor.size() 获取 tensor 形状的结果为 torch.Size);
- out = None(可选参数): 指定输出的张量。比如执行
torch.zeros([2, 2], out = tensor_a),相当于执行tensor_a = torch.zeros([2, 2]); - dtype = None(可选参数):指定返回张量的数据类型,默认(dtype = None)使用全局默认的数据类型,我们可以使用 torch.get_default_tensor_type() 获取全局默认的数据类型,同时可以通过 torch.set_default_tensor_type(torch.XXXTensor) 更改全局默认的数据类型为 torch.XXXTensor;
- layout = torch.strided(可选参数): 定义张量在物理设备中的存储结构,torch.layout 可选的参数值有 torch.strided(默认)或 torch.sparse_coo,分别对应顺序存储和离散存储。「通常情况下,如果张量中的元素值 0 比较少为稠密张量,则指定 layout = torch.strided。如果张量中的元素值中 0 比较多为稀疏张量,则指定 layout = torch.sparse_coo」;
- device = None(可选参数): 指定张量所在的计算设备是 CPU 还是 GPU;
- requires_grad=False(可选参数): 指定此张量是否需要记录梯度;
torch.zeros() 和 torch.ones() 两个函数中只有 *size 参数为必须指定的参数,其余参数都是可选参数,因此接下来只关注指定 *size 参数的 torch.zeros(*size) 和 torch.ones(*size)。
>>> import torch
>>> # 创建全为0或1的0D张量(标量)
>>> scalar_zero = torch.zeros([])
>>> scalar_one = torch.ones([])
>>> print("张量的维度:{},张量的值:{}".
format(scalar_zero.dim(), scalar_zero))
张量的维度:0,张量的值:0.0
>>> print("张量的维度:{},张量的值:{}".
format(scalar_one.dim(), scalar_one))
张量的维度:0,张量的值:1.0
>>> # 创建全为0或1的1D张量(向量)
>>> vec_zero = torch.zeros([3])
>>> vec_one = torch.ones([3])
>>> print("张量的维度:{},张量的值:{}".
format(vec_zero.dim(), vec_zero))
张量的维度:1,张量的值:tensor([0., 0., 0.])
>>> print("张量的维度:{},张量的值:{}".
format(vec_one.dim(), vec_one))
张量的维度:1,张量的值:tensor([1., 1., 1.])
>>> # 创建全为0或1的2D张量(矩阵)
>>> mat_zero = torch.zeros([2, 2])
>>> mat_one = torch.ones([2, 2])
>>> print("张量的维度:{},张量的值:{}".
format(mat_zero.dim(), mat_zero))
张量的维度:2,张量的值:tensor([[0., 0.],
[0., 0.]])
>>> print("张量的维度:{},张量的值:{}".
format(mat_one.dim(), mat_one))
张量的维度:2,张量的值:tensor([[1., 1.],
[1., 1.]])
通过torch.zeros(*size)和torch.ones(*size)函数创建了元素值全为 0 和全为 1 的 0D 张量、1D 张量和 2D 张量,创建 nD 张量与之类似,这里不再赘述。*size 参数指定创建张量的形状,不同维度张量的形状可以参考下表。
比如:
- 创建 0D 张量只需要指定 size = [];
- 创建 1D 张量只需要指定 size = [dim0],其中 dim0 为第 0 个维度的元素个数;
- 创建 2D 张量只需要指定 size = [dim0, dim1],其中 dim0 为第 0 个维度的元素个数,dim1 为第 1 个维度的元素个数;
- 依次类推,创建 nD 张量只需要指定 size = [dim0, dim1, ..., dimn],其中 dim0 为第 0 个维度的元素个数,dim1 为第 1 个维度的元素个数,...,dimn 为第 n 个维度的元素个数;

通过 torch.zeros_like(input) 和 torch.ones_like(input) 函数可以方便地创建与 input 张量形状一致,且元素值全为 0 或者 1 的张量,需要注意此时的 input 必须是张量。
>>> import torch
>>> scalar_a = torch.tensor(1.)
>>> vec_a = torch.tensor([1., 2., 3.])
>>> mat_a = torch.tensor([[1., 2.], [3., 4.]])
>>> print("张量的形状:{}".format(scalar_a.size()))
张量的形状:torch.Size([])
>>> print("张量的形状:{}".format(vec_a.size()))
张量的形状:torch.Size([3])
>>> print("张量的形状:{}".format(mat_a.size()))
张量的形状:torch.Size([2, 2])
>>> # 创建和张量scalar_a相同形状的全为0或1的张量
>>> scalar_zero = torch.zeros_like(scalar_a)
>>> scalar_one = torch.ones_like(scalar_a)
>>> print("张量的维度:{},张量的值:{}".
format(scalar_zero.dim(), scalar_zero))
张量的维度:0,张量的值:0.0
>>> print("张量的维度:{},张量的值:{}".
format(scalar_one.dim(), scalar_one))
张量的维度:0,张量的值:1.0
>>> # 创建和张量scalar_a相同形状的全为0或1的张量
>>> vec_zero = torch.zeros_like(vec_a)
>>> vec_one = torch.ones_like(vec_a)
>>> print("张量的维度:{},张量的值:{}".
format(vec_zero.dim(), vec_zero))
张量的维度:1,张量的值:tensor([0., 0., 0.])
>>> print("张量的维度:{},张量的值:{}".
format(vec_one.dim(), vec_one))
张量的维度:1,张量的值:tensor([1., 1., 1.])
>>> # 创建和张量scalar_a相同形状的全为0或1的张量
>>> mat_zero = torch.zeros_like(mat_a)
>>> mat_one = torch.ones_like(mat_a)
>>> print("张量的维度:{},张量的值:{}".
format(mat_zero.dim(), mat_zero))
张量的维度:2,张量的值:tensor([[0., 0.],
[0., 0.]])
>>> print("张量的维度:{},张量的值:{}".
format(mat_one.dim(), mat_one))
张量的维度:2,张量的值:tensor([[1., 1.],
[1., 1.]])
3. 创建自定义数值张量
除了将张量的元素值初始化全为 0 或全为 1 的张量依然,有时候也需要全部初始化为某个自定义数值的张量。通过 torch.full(size,fill_value,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False) 可以创建全为自定义数值 fill_value 的张量,形状由 size 参数指定。
torch.full() 函数中除了 size 和 fill_value 参数外,其余都是可选参数且和 torch.zeros() 和 torch.ones() 两个函数的参数一致,同样不再赘述。
- size: 定义输出张量形状的整数序列,这个整数序列可以是列表和数组之类的集合也可以是整数的 torch.Size(执行 tensor.size() 获取 tensor 形状的结果为 torch.Size);
- fill_value: 填充到张量中的元素值,必须为标量值;
>>> import torch
>>> # 创建0D且元素值为5的张量
>>> scalar_a = torch.full([], 5)
>>> # 创建1D且元素值为5的张量
>>> vec_a = torch.full([3], 5)
>>> # 创建2D且元素值为5的张量
>>> mat_a = torch.full([2, 2], 5)
>>> print("张量的维度:{},张量的值:{}".
format(scalar_a.dim(), scalar_a))
张量的维度:0,张量的值:5.0
>>> print("张量的维度:{},张量的值:{}".
format(vec_a.dim(), vec_a))
张量的维度:1,张量的值:tensor([5., 5., 5.])
>>> print("张量的维度:{},张量的值:{}".
format(mat_a.dim(), mat_a))
张量的维度:2,张量的值:tensor([[5., 5.],
[5., 5.]])
「通过 torch.full_like(input,fill_value) 函数来创建全为自定义数值 fill_value 的张量,形状由参数 input 的形状指定,input 必须是张量。」
4. 创建已知分布的张量
正态分布(Normal Distribution)和均匀分布(Uniform Distribution)是最常见的分布之一,创建采样自这 2 个分布的张量非常有用,「比如在卷积神经网络中,卷积核张量 初始化为正态分布有利于网络的训练;在对抗生成网络中,隐藏变量 一般采样自均匀分布。」
通过 torch.normal(mean,std,generator=None,out=None) 可以创建均值为 mean,标准差为 std 的正态分布 ,先来简单看一看这些参数:
- mean(Tensor) - 传入参数 mean 的张量中的每个元素都是对应输出元素的正态分布的均值;
- std(Tensor) - 传入参数 std 的张量中的每个元素都是对应输出元素的正态分布的标准差;
- generator = None(torch.Generator, optional) - 用于采样的伪随机数,可以暂时不用关注;
- out = None(Tensor, optional) - 指定输出的张量。比如执行
torch.normal(mean = torch.tensor(0.), std = torch.tensor(1.), out = tensor_a),相当于执行tensor_a = torch.normal(mean = torch.tensor(0.), std = torch.tensor(1.));
torch.normal(mean,std,generator=None,out=None) 函数传入的 mean 和 std 参数的两个张量的形状不一定要匹配,但是这两个张量中的元素总个数必须相等,「这里需要注意此时两个张量中的元素总个数必须相等不仅仅包括显式的相等,还包含隐式的相等。」
- 显式相等非常好理解,简单来说就是传入张量的元素总个数相等。比如传入参数 mean 的张量形状为 [1, 4],那么传入参数 std 的张量形状必须是 [1, 4]、[2, 2]、[4, 1] 中的任意一个,必须满足 mean.numel() == std.numel()(tensor.numel() 函数返回 tensor 中的元素个数);
- 隐式相等其实就是 PyTorch 中的广播机制,PyTorch 中的广播机制和 TensorFlow 以及 Numpy 中的广播机制类似。比如传入参数 mean 的张量形状为 [1, 2],而传入参数 std 的张量形状为 [2, 2],PyTorch 会根据广播机制的规则将传入 mean 参数的张量形状广播成 [2, 2]。「虽然传入的两个张量元素总个数不相等,但是通过 PyTorch 中的广播机制可以将符合广播机制的张量扩展成相同元素总个数的两个张量;」
>>> import torch
>>> # 传入mean和std的两个张量:
>>> # 1. 形状不匹配
>>> # 2. 两个张量中的元素个数显式相等
>>> normal_a = torch.normal(mean = torch.full([1, 4], 0.),std = torch.full([2, 2], 1.))
>>> print(normal_a.size())
torch.Size([1, 4])
>>> print(normal_a)
tensor([[-1.7489, -1.4797, 1.1246, 0.4521]])
>>> # 传入mean和std的两个张量:
>>> # 1. 形状不匹配
>>> # 2. 两个张量中的元素个数显式不相等,但是符合广播机制的规则
>>> normal_b = torch.normal(mean = torch.full([1, 2], 0.),std = torch.full([2, 2], 1.))
>>> print(normal_b.size())
torch.Size([2, 2])
>>> print(normal_b)
tensor([[-1.1370, -1.1644],
[-1.5242, -0.9315]])
>>> # 传入mean和std的两个张量:
>>> # 1. 形状不匹配
>>> # 2. 两个张量中的元素个数显式不相等,且不符合广播机制的规则
>>> # 程序会报错error
>>> # normal_c = torch.normal(mean = torch.full([1, 3], 0.),
>>> # std = torch.full([2, 2], 1.))
PyTorch 的官方文档中强调:"当输入参数 mean 和 std 的张量形状不匹配的时候,输出张量的形状由传入 mean 参数的张量形状所决定。"通过前面的介绍后这句话非常好理解,因为不管传入 mean 和 std 参数的张量形状如何,只要代码正确,最终都会被转换为相同的形状。
不过有可能会有 UserWarning 的警告(我的 PyTorch 为 1.5),这个警告因为 torch.normal(mean = torch.full((1, 4), 0.),std = torch.full((2, 2), 1.)) 代码段,「这是因为当传入的两个张量形状不匹配,但是元素总个数相等的情况下,PyTorch 会使用 reshape 函数将传入参数 std 的张量形状改变成和传入 mean 参数张量相同的形状,这可能会引发一些问题,所以在 PyTorch 1.6 以后的版本这种方法将会舍弃,这里只需要注意一下即可。」
通过 torch.randint(low=0,high,size,generator=None,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False) 函数能够创建采样自 [low, high) 区间(包左不包右)的均匀分布的张量,函数中的很多参数都介绍过,这里不再赘述,这里只关注 low 和 high 两个参数。
- low(int, optional) - 从均匀分布中采样的最小整数,默认为 0;
- high(int) - 从均匀分布中采样的最大整数,不包括最大整数;
>>> import torch
>>> # 创建采样自[1, 10)均匀分布的0D张量
>>> scalar_a = torch.randint(1, 10, ())
>>> print(scalar_a.size())
torch.Size([])
>>> print(scalar_a)
tensor(4)
>>> # 创建采样自[2, 5)均匀分布的1D张量
>>> vec_b = torch.randint(2, 5, (3, ))
>>> print(vec_b.size())
torch.Size([3])
>>> print(vec_b)
tensor([2, 2, 2])
>>> # 创建采样自[0, 10)均匀分布的2D张量
>>> mat_c = torch.randint(10, (2, 2))
>>> print(mat_c.size())
torch.Size([2, 2])
>>> print(mat_c)
tensor([[3, 8],
[4, 2]])
通过 torch.randint(low, high, size) 函数创建采样自 [low, high) 均匀分布的 0D 张量、1D 张量和 2D 张量,创建 nD 张量与之类似,这里不再赘述。*size 参数指定创建张量的形状。
torch.normal() 函数相对比较复杂,而 torch.randint() 函数和前面介绍的函数类似,只不过需要指定采样的区间范围。针对比较常见的标准正态分布和采样自 [0, 1) 区间的均匀分布,PyTorch 又提供了 torch.randn(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)和torch.rand(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False) 两个函数。
>>> import torch
>>> # 创建采样自均值0.标准差1.正态分布的2D张量
>>> # 等价torch.normal(mean = torch.full([2, 2], 0.)
>>> # std = torch.full([2, 2], 1.))
>>> normal_a = torch.randn([2, 2])
>>> print(normal_a)
tensor([[-0.4471, -0.2377],
[ 0.6442, -0.1024]])
>>> # 创建采样自[0, 1)均匀分布的2D张量
>>> # !不等价torch.randint(0, 1, [2, 2])
>>> uniform_b = torch.rand([2, 2])
>>> print(uniform_b)
tensor([[0.9690, 0.6938],
[0.1431, 0.4861]])
还有一点需要注意:「torch.randint() 函数只能采样指定范围均匀分布的整数,而 torch.rand() 函数能够采样 [0, 1) 范围内均匀分布的浮点数,如果你想要采样自指定范围内的浮点数,可以使用 torch.rand() 函数进行改造,不过最简单的方法就是使用 torch.nn.init.uniform_(tensor, a=0.0, b=1.0) 函数。」
比如创建一个采样自 [2, 10) 范围均匀分布且形状为 [2, 2] 的 2D 张量。
>>> import torch
>>> uniform_c = torch.FloatTensor(2, 2).uniform_(2, 10)
>>> print(uniform_c)
tensor([[8.9692, 6.4037],
[4.4121, 7.0056]])
5. 创建序列张量
在循环计算或者对张量进行索引时,经常需要创建一段连续的整型或浮点型的序列张量。PyTorch 提供了一些能够创建序列张量的方法。
创建整型序列:
- torch.arange(start = 0, end, step = 1, out = None, layout = torch.strided, device = None, requires_grad = False) 可以创建长度为 ( 为向上取整,返回大于或者等于表达式的最小整数) 的 1D 张量,张量的元素值为在 [start, end) 之间,步长为 step 的整型序列,不包含 end 本身;
- torch.range(start = 0, end, step = 1, out = None, layout = torch.strided, device = None, requires_grad = False) 可以创建长度为 ( 为向下取整,返回小于或者等于表达式的最大整数) 的 1D 张量,张量的元素值为在 [start, end] 之间,步长为 step 的整型序列,包含 end 本身;
使用 torch.range() 函数会出现 Warning 警告:未来的 Pytorch 版本会将 torch.range() 函数丢弃。因为 torch.range() 函数和 Python 的内建函数 range 行为不一致,Python 中的 range 函数生成的整数序列范围为 [start, end) (包左不包右,Python中习惯使用包左不包右的规范),而 torch.range() 函数生成的整数序列范围为 [start, end] (包左包右)。
torch.arange() 函数和 torch.range() 函数功能相似。「如果想要创建整型序列,推荐使用 torch.arange() 函数。」
>>> import torch
>>> # 创建元素值为范围[0, 10)步长为1的1D整数序列张量
>>> a = torch.arange(0, 10)
>>> print(a)
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> # 创建元素值为范围[1, 10)步长为2的1D整数序列张量
>>> b = torch.arange(1, 10, 2)
>>> print(b)
tensor([1, 3, 5, 7, 9])
>>> # 使用torch.range()函数创建元素值为范围[0, 10)步长为1的1D整数序列张量
>>> c = torch.range(0, 10)
>>> print(c)
tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
/home/chenkc/code/create_tensor.py:298: UserWarning: torch.range is deprecated in favor of torch.arange and will be removed in 0.5. Note that arange generates values in [start; end), not [start; end].
c = torch.range(0, 10)
对于张量 b 来说,由于 ,因此最终张量 b 为长度为 5 的 1D 张量。
创建浮点型序列:
- torch.linspace(start, end, steps, out = None, dtype = None, layout = torch.strided, device = None, requires_grad = False) 可以创建长度为 steps 的 1D 张量,张量的元素值为在 [start, end] 之间均匀间隔的 steps 个点。序列张量的值为 ;
- torch.logspace(start, end, steps, base = 10.0, out = None, layout = torch.strided, device = None, requires_grad = False) 可以创建长度为 steps 的 1D 张量,张量的元素值为在 之间均匀间隔的 steps 个点。序列张量的值为 ;
>>> import torch
>>> # 创建元素值为范围[0, 10]之间均匀间隔的5个值的1D浮点型序列张量
>>> a = torch.linspace(0., 10., 5)
>>> print(a)
tensor([ 0.0000, 2.5000, 5.0000, 7.5000, 10.0000])
>>> # 创建元素值为范围[10^0, 10^10]之间均匀间隔的5个值的1D浮点型序列张量
>>> b = torch.logspace(0., 10., 5)
>>> print(b)
tensor([1.0000e+00, 3.1623e+02, 1.0000e+05, 3.1623e+07, 1.0000e+10])
