海量数据时代,谁能终结污染数据爆发式的扩散?
2020年初新冠疫情爆发,然后迅速在全球范围内扩散,其蔓延速度之快、后果之严重令人生畏。在大数据领域,也存在着类似的扩散问题(异常数据流向下游),其带来的危害有时也是灾难性的。面对这样的问题,我们又该如何解决?本文就对该问题,说明网易有数大数据平台是如何解决离线开发中的快速阻断和高效恢复。
作者:网易有数
起源:数据开发的灾难不期而遇
2020年4月的某一天凌晨,分析师小易在凌晨3点接到一个电话。在迷迷糊糊中,听到了电话那头传来网易有数电话报警的声音,小易瞬间明白是自己负责的任务出错了(“离线开发”的实例失败电话报警功能)!
于是他迅速起床并打开了电脑,通过“任务运维中心”找到被报警的实例,发现是实例触发了质量监控阻断(“数据质量中心”的强规则阻断实例运行功能),具体的原因是数据量行数波动超过阈值。随后,小易在网易有数大数据平台的“自助分析”模块进行相关数据探查,发现是上游数仓的dwd明细表出现明显地丢失,数据量骤降。于是小易赶紧电话联系数仓值班人员小孙反馈该问题。
小孙挂断电话后,心想:“完蛋了,早知道应该多配置些数据质量监控规则,今天要是真出了问题,那么多下游都已经调度起来,明天一大早,丁三石(丁磊先生花名三石)都要找过来,我三年出任CEO的计划就要泡汤了!” 于是,小孙赶紧起来排查,最终发现是ODS原始层就出现了数据丢失。之后,小孙又联系团队平台组的小徐来定位原因。小徐经过一番排查,发现是团队自研的数据采集工具的设计缺陷,导致特定场景下数据会延迟写入。到目前为止,数据已全部采集完成。
说明一下问题发生的原因:该自研的数据采集工具独立于网易有数大数据平台,没有任务依赖可配置,是采用在有数中启动script脚本,持续去检查文件产出标记,这种设计在数据量过大或挤压到一定量时,就会出错。对于大数据平台的“数据传输”产品,就可以很好地解决上述问题。
至此,数仓团队的负责人老魏也已经起来在了解问题,此时,已经过去了2个小时……大量的下游任务实例在继续调度运行,也有部分因为配置的数据质量监控规则执行异常被终止,其下游暂时未被调起。有不少人也因为实例失败,被电话报警唤起。
故事讲到这,也许已经勾起了有些人的相似经历,沉浸在慢慢长夜人肉处理这种问题的无限痛苦中。确实,故事中数仓团队的老魏和小孙,在当天夜里从5点开始,从出问题的源头任务实例开始,查找下游依赖的任务实例,如果实例已经运行,则手动终止。在人肉遍历期间,小孙也完成了ODS层表的重跑。由于依赖是网状的,下游任务中同一个任务就可能处在不同的深度,因此需要人工去按照最小的深度逐级去重跑。当几千个任务构成的任务依赖DAG图,有几百个任务的实例已经运行成功,想要逐级去重跑是多么费时费力,需要逐个触发重跑,然后等待重跑运行结束,再继续下一层的实例的重跑,直至所有已经运行成功的下游实例都运行成功。最终,花了3天时间才完全把问题解决,而且中间还存在部分未进行重跑的实例。
看完上面这个惨淡的故事,当同样的黑天鹅落在我们身边时,我们该如何应对?下面,我们来看一下网易有数大数据平台是如何解决的。
利器出世:冻结池的登场
在发生上面的事故之后,网易有数大数据平台的产品与该团队的相关人员做了多次沟通。最终,大数据平台的任务运维中心上线了“冻结池”功能。除了上面故事中提到的ods原始层数据异常,也会有任务加工逻辑错误、依赖缺失导致任务提交计算等其他场景导致数据被污染,向下游扩散的情况。此时,都可以使用“冻结池”功能来解决。对于数据污染扩散时的处理,可以总结为以下三步:第一步:停止受影响实例的继续执行;第二步:恢复异常的数据;第三步:重跑受影响的所有实例。
对于“冻结池”而言,主要完成了其中的第一步和第三步。当用户遇到数据异常时,需要先定位到直接受影响的源头离线开发任务集(比如叫任务集G1),接着可以创建一个冻结池任务,通过批量导入方式,将任务集G1添加到冻结池中,这些任务将作为源头任务。之后创建并执行冻结池,系统会自动扫描任务集G1中任务的所有下游依赖任务,并放入冻结池的任务列表中。
生成冻结池后,冻结池中的所有任务将被冻结,所有运行中的实例将被终止,未生成的实例会停止生成。至此,完成扩散处理的第一步——切断污染传播。
第二步,则需要数据开发人员来分析出现问题的原因,制定解决方案,并尽快恢复问题数据。
第三步,对冻结池执行解冻操作,系统会自动从源头任务开始,开始逐个解冻任务。单个任务的解冻过程为:任务会从冻结状态变为解冻中,之后对应的实例(如有)执行重跑,重跑成功后,任务状态变为已解冻。通过基于依赖的重跑,即可实现被污染数据的重刷。如果期间出现重跑失败等,则需要人工介入处理,强制置为成功,任务继续往下解冻,直至所有任务都被解冻。
下面,通过一张图来说明冻结和解冻是如何影响任务实例的。对于下图中的第一个DAG图,包含A、B、C、D和E共计5个任务,依赖关系和对应实例的状态已经标记在节点中。如果管理者发现A任务产出的数据有异常,则管理者可以创建一个冻结池,并把A放入其中,然后执行冻结操作。则系统会把所有潜在受影响的下游B、D和E冻结,将运行中的B和就绪的E的实例终止。当执行解冻时,则会把A、B和E的实例都重跑一次,对于D则直接解冻。在整个过程中,任务解冻后,下游任务没有被解冻的,则实例会正常生成和运行,如下图第三个DAG的C。
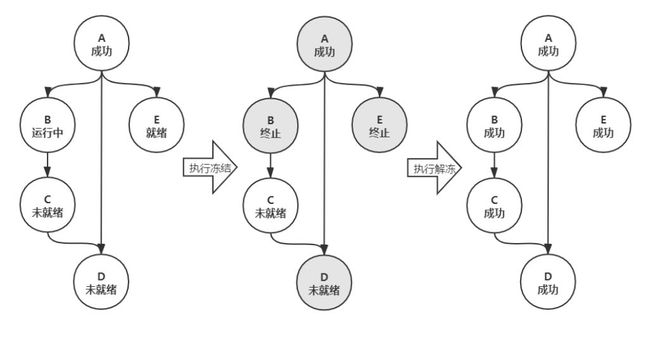
此外,冻结池还支持暂停、更新、废弃等功能,应对问题修复过程中出现的多种突发情况。比如,当日解决完数据问题时已经很晚,没办法解冻所有的任务,为避免夜间资源抢占,影响第二天的调度,则可以将冻结池暂停,等第二天白天再来恢复解冻。再比如,开始解冻任务时,发现遗漏了部分任务等,可以执行更新,添加任务再重新生成冻结池。
所以对于拯救被连锁扩散污染的数据,是不是就像把大象放进冰箱需要几步一样简单?“冻结池”帮你打开冰箱门,最后再帮你关上冰箱门,你只需要完成第二步——把大象塞进冰箱(即修复数据)。
结局:1分钟和0介入
2020年的黑天鹅事件特别多,似乎黑天鹅们喜欢在2020年成群结队出现。就在网易有数大数据平台的任务运维中心的“冻结池”功能上线后不久,故事中的团队又出现了一次日志文件重复问题,巧合的是,当天又是小孙值班,虽然在定位问题上花了一些时间,但是系统最终在1分钟之内,把1370多个的任务生成并冻结,及时阻断了异常数据向下游扩散。
后来,冻结池解冻,250多个实例自动完成了重跑,并恢复了下游,完全不需要人工介入处理。这对于分秒必争的故障恢复场景,极大的提高了故障恢复的速度。
从业务方使用的效果看,“冻结池”极大程度降低了数据污染扩散时带来的风险,也有效节约了人力处理成本。相信大家也不愿看到 “冻结池”隔三差五就上去力挽狂澜。
目前,网易有数大数据平台还提供了“数据质量中心”、“数据测试中心”、“离线开发的CI/CD流程管控”等辅助企业提升数据质量的利器,为需要提升数据质量的企业提供服务。