【路径规划】基于nsga的无人机路径规划
1. 算法简介
NSGA-Ⅱ算法,即带有精英保留策略的快速非支配多目标优化算法,是一种基于Pareto最优解的多目标优化算法。
1.1 Pareto支配关系以及Pareto等级
Pareto支配关系:对于最小化多目标优化问题,对于n个目标分量 f i ( x ) , i = 1... n f_i(x), i=1...nfi(x),i=1...n,任意给定两个决策变量X a X_aXa,X b X_bXb,如果有以下两个条件成立,则称X a X_aXa支配X b X_bXb。
1.对于∀ i ∈ 1 , 2 , . . . , n \forall i \in {1,2,...,n}∀i∈1,2,...,n,都有f i ( X a ) ≤ f i ( X b ) f_i(X_a) \leq f_i(X_b)fi(Xa)≤fi(Xb)成立。
2.∃ i ∈ 1 , 2 , . . . , n \exists i \in {1,2,...,n}∃i∈1,2,...,n,使得f i ( X a ) < f i ( X b ) f_i(X_a)
Pareto等级:在一组解中,非支配解Pareto等级定义为1,将非支配解从解的集合中删除,剩下解的Pareto等级定义为2,依次类推,可以得到该解集合中所有解的Pareto等级。示意图如图1所示。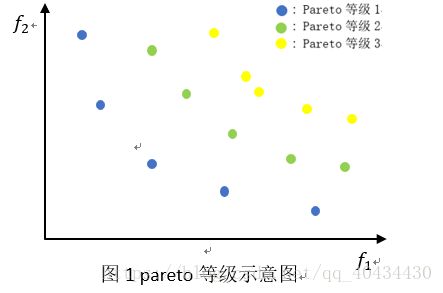
1.2 快速非支配排序
假设种群大小为P,该算法需要计算每个个体p的被支配个数n p n_pnp和该个体支配的解的集合S p S_pSp这两个参数。遍历整个种群,该参数的计算复杂度为O ( m N 2 ) O(mN^2)O(mN2)。该算法的伪代码如下:
1.计算出种群中每个个体的两个参数n p n_pnp和S p S_pSp。
2.将种群中参数n p = 0 n_p=0np=0的个体放入集合F 1 F_1F1中。
3.for 个体i ∈ F 1 i \in F_1i∈F1:
for 个体l ∈ S i l \in S_il∈Si:
n l = n l − 1 n_l=n_l-1nl=nl−1;(该步骤即消除Pareto等级1对其余个体的支配,相当于将Pareto等级1的个体从集合中删除)
if n l = 0 n_l=0nl=0:
将个体l加入集合F 2 F_2F2中。
end
end
end
4.上面得到Pareto等级2的个体的集合F 2 F_2F2,对集合F 2 F_2F2中的个体继续重复步骤3,依次类推直到种群等级被全部划分。
1.3 拥挤度
为了使得到的解在目标空间中更加均匀,这里引入了拥挤度n d n_dnd,其算法如下:
- 令参数n d = 0 , n ∈ 1 … N n_d=0,n∈1…Nnd=0,n∈1…N。
- for 每个目标函数f m f_mfm :
① 根据该目标函数对该等级的个体进行排序,记f m m a x f_m^{max}fmmax为个体目标函数值f m f_mfm的最大值,f m m i n f_m^{min}fmmin为个体目标函数值f m f_mfm的最小值;
② 对于排序后两个边界的拥挤度1 d 1_d1d和N d N_dNd置为∞;
③ 计算n d = n d + ( f m ( i + 1 ) − f m ( i − 1 ) ) / ( f m m a x − f m m i n ) n_d=n_d+(f_m (i+1)-f_m (i-1))/(f_m^{max}-f_m^{min})nd=nd+(fm(i+1)−fm(i−1))/(fmmax−fmmin),其中f m ( i + 1 ) f_m (i+1)fm(i+1)是该个体排序后后一位的目标函数值。
end
从二目标优化问题来看,就像是该个体在目标空间所能生成的最大的矩形(该矩形不能触碰目标空间其他的点)的边长之和。拥挤度示意图如图2所示。 1.4 精英保留策略
1.4 精英保留策略
1.首先将父代种群C i C_iCi和子代种群D i D_iDi合成种群R i R_iRi。
2.根据以下规则从种群R i R_iRi生成新的父代种群C i + 1 C_{i+1}Ci+1:
①根据Pareto等级从低到高的顺序,将整层种群放入父代种群C i + 1 C_{i+1}Ci+1,直到某一层该层个体不能全部放入父代种群C i + 1 C_{i+1}Ci+1;
②将该层个体根据拥挤度从大到小排列,依次放入父代种群C i + 1 C_{i+1}Ci+1中,直到父代种群C i + 1 C_{i+1}Ci+1填满。
1.5 实数编码的交叉操作(SBX)
模拟二进制交叉:
x 1 j ( t ) = 0.5 × [ ( 1 + γ j ) x 1 j ( t ) + ( 1 − γ j ) x 2 j ( t ) ] x _{1j}(t)=0.5×[(1+γ_j ) x_{1j}(t)+(1-γ_j ) x_{2j} (t)]x1j(t)=0.5×[(1+γj)x1j(t)+(1−γj)x2j(t)]
x 2 j ( t ) = 0.5 × [ ( 1 − γ j ) x 1 j ( t ) + ( 1 + γ j ) x 2 j ( t ) ] x _{2j} (t)=0.5×[(1-γ_j ) x_{1j}(t)+(1+γ_j ) x_{2j}(t)]x2j(t)=0.5×[(1−γj)x1j(t)+(1+γj)x2j(t)]
其中
γ j = { ( 2 u j ) 1 / ( η + 1 ) u j < 0.5 ( 1 / ( 2 ( 1 − u j ) ) 1 / ( η + 1 ) e l s e γ_j=\left\{
(2uj)1/(η+1)uj<0.5(1/(2(1−uj))1/(η+1)else(2uj)1/(η+1)uj<0.5(1/(2(1−uj))1/(η+1)else
\right.γj={(2uj)1/(η+1)uj<0.5(1/(2(1−uj))1/(η+1)else
1.6 多项式变异(polynomial mutation)
多项式变异:
x 1 j ( t ) = x 1 j ( t ) + ∆ j x _{1j} (t)=x_{1j} (t)+∆_jx1j(t)=x1j(t)+∆j
其中
∆ j = { ( 2 u j ) 1 / ( η + 1 ) − 1 u j < 0.5 ( 1 − ( 2 ( 1 − u j ) ) 1 / ( η + 1 ) e l s e ∆_j=\left\{
(2uj)1/(η+1)−1uj<0.5(1−(2(1−uj))1/(η+1)else(2uj)1/(η+1)−1uj<0.5(1−(2(1−uj))1/(η+1)else
\right.∆j={(2uj)1/(η+1)−1uj<0.5(1−(2(1−uj))1/(η+1)else
并且0≤u j u_juj≤1。
1.7 竞标赛选择(tournament selection)
锦标赛法是选择操作的一种常用方法,二进制竞标赛用的最多。
假设种群规模为N,该法的步骤为:
1.从这N个个体中随机选择k(k
3.重复1-2步,至得到新的N个个体。
2. 算法实现框图
NSGA-Ⅱ算法的基本思想为:首先,随机产生规模为N的初始种群,非支配排序后通过遗传算法的选择、交叉、变异三个基本操作得到第一代子代种群;其次,从第二代开始,将父代种群与子代种群合并,进行快速非支配排序,同时对每个非支配层中的个体进行拥挤度计算,根据非支配关系以及个体的拥挤度选取合适的个体组成新的父代种群;最后,通过遗传算法的基本操作产生新的子代种群:依此类推,直到满足程序结束的条件。该算法的流程图如图3所示。

2 代码
clear all;
clc;
close all;
tic
global DEM safth hmax scfitness;
a=load('XYZmesh.mat');%读取数字高程信息DEM
DEM=a;
DEM.Z=DEM.Z;
safth=60;
hmax=max(max(DEM.Z));
hmin=min(min(DEM.Z));
%DEM.Z=randint(size(DEM.Z,1),size(DEM.Z,2),[0 100]);
ganum=100;
dnanum=50;
dnalength=50;
childrennum=dnanum;
np=zeros(1,dnanum);
nsort1=zeros(1,dnanum);
nsort2=zeros(1,dnanum);
nsort3=zeros(1,dnanum);
fitness1=zeros(dnanum,3);
fitness2=zeros(dnanum,3);
fitness3=zeros(dnanum,3);
scfitness=zeros(dnanum,3);
congestion=zeros(1,dnanum);
startpoint=[1,1,100];
goalpoint=[101,101,100];
startpoint(3)=DEM.Z(startpoint(1),startpoint(2))+safth;
goalpoint(3)=DEM.Z(goalpoint(1),goalpoint(2))+safth;
dna1=zeros(dnanum,dnalength+1,3);
dna2=zeros(dnanum,dnalength+1,3);
dna3=zeros(dnanum,dnalength+1,3);
totalfitness=zeros(2,ganum+1,3); %make a 3*101*3 size matrix ,the last 3 means three dimensional
for i=1:1:dnanum
for j=2:1:dnalength
for k=1:1:3
%dna1(i,j,k)=randint(1,1,[1 101]);
dna1(i,j,1)=j*100/dnalength;
dna2(i,j,1)=j*100/dnalength;
dna3(i,j,1)=j*100/dnalength;
dna1(i,j,2)=j*100/dnalength+randint(1,1,[0 20]-10);
dna2(i,j,2)=j*100/dnalength+randint(1,1,[0 20]-20);
dna3(i,j,2)=j*100/dnalength+randint(1,1,[0 20]+15);%key point to improvement
if dna1(i,j,2)<1
dna1(i,j,2)=1;
elseif dna1(i,j,2)>101
dna1(i,j,2)=101;
end
if dna2(i,j,2)<1
dna2(i,j,2)=1;
elseif dna2(i,j,2)>101
dna2(i,j,2)=101;
end
if dna3(i,j,2)<1
dna3(i,j,2)=1;
elseif dna3(i,j,2)>101
dna3(i,j,2)=101;
end
%dna1(i,j,k)=floor(100*j/dnalength);
%dna1(i,j,k)=j;
end
dna1(i,j,3)=DEM.Z(dna1(i,j,1),dna1(i,j,2))+safth;
dna2(i,j,3)=DEM.Z(dna2(i,j,1),dna2(i,j,2))+safth;
dna3(i,j,3)=DEM.Z(dna3(i,j,1),dna3(i,j,2))+safth;
% dna1(i,j,3)=randint(1,1,[safth safth+hmax]);
%dna1(i,j,3)=safth+hmax;
end
for k=1:1:3
dna1(i,1,k)=startpoint(k);
dna1(i,dnalength+1,k)=goalpoint(k);
dna2(i,1,k)=startpoint(k);
dna2(i,dnalength+1,k)=goalpoint(k);
dna3(i,1,k)=startpoint(k);
dna3(i,dnalength+1,k)=goalpoint(k);
end
end
for n=1:1:ganum
n
fitness1=NSGA2_fitness(dna1);
fitness2=NSGA2_fitness(dna2);
fitness3=NSGA2_fitness(dna3);
scfitness=fitness1;
mmin(1)=min(fitness1(:,1));
mmin(2)=min(fitness1(:,2));
mmin(3)=min(fitness1(:,3));
mmax(1)=max(fitness1(:,1));
mmax(2)=max(fitness1(:,2));
mmax(3)=max(fitness1(:,3));
totalfitness(1,n,:)=mmin;
totalfitness(2,n,:)=mmax;
totalfitness(3,n,:)=(mmin+mmax)/2;
nsort1=NSGA2_SORT(fitness1);
nsort2=NSGA2_SORT(fitness2);
nsort3=NSGA2_SORT(fitness3);
children1=NSGA2_chlidren(dna1,childrennum,nsort1);
children2=NSGA2_chlidren(dna2,childrennum,nsort2);
children3=NSGA2_chlidren(dna3,childrennum,nsort3);
children_out1=NSGA2_cross(children1);
children_out2=NSGA2_cross(children2);
children_out3=NSGA2_cross(children3);
%children1=children_out1;
children1=NSGA2_variation(children_out1);
children2=NSGA2_variation(children_out2);
children3=NSGA2_variation(children_out3);
combinedna1(1:1:dnanum,:,:)=dna1(1:1:dnanum,:,:);
combinedna2(1:1:dnanum,:,:)=dna2(1:1:dnanum,:,:);
combinedna3(1:1:dnanum,:,:)=dna3(1:1:dnanum,:,:);
combinedna1(dnanum+1:1:dnanum+childrennum,:,:)=children1(1:1:dnanum,:,:);
combinedna2(dnanum+1:1:dnanum+childrennum,:,:)=children2(1:1:dnanum,:,:);
combinedna3(dnanum+1:1:dnanum+childrennum,:,:)=children3(1:1:dnanum,:,:);
childrenfitness1=NSGA2_fitness(children1);
childrenfitness2=NSGA2_fitness(children2);
childrenfitness3=NSGA2_fitness(children3);
combinefitness1(1:1:dnanum,:)=fitness1(1:1:dnanum,:);
combinefitness2(1:1:dnanum,:)=fitness2(1:1:dnanum,:);
combinefitness3(1:1:dnanum,:)=fitness3(1:1:dnanum,:);
combinefitness1(dnanum+1:1:dnanum+childrennum,:)=childrenfitness1(1:1:dnanum,:);
combinefitness2(dnanum+1:1:dnanum+childrennum,:)=childrenfitness2(1:1:dnanum,:);
combinefitness3(dnanum+1:1:dnanum+childrennum,:)=childrenfitness3(1:1:dnanum,:);
dna1=NSGA2_BESTN(combinedna1,combinefitness1,dnanum);
dna2=NSGA2_BESTN(combinedna2,combinefitness2,dnanum);
dna3=NSGA2_BESTN(combinedna3,combinefitness3,dnanum);
end
mmin(1)=min(fitness1(:,1));
mmin(2)=min(fitness1(:,2));
mmin(3)=min(fitness1(:,3));
mmax(1)=max(fitness1(:,1));
mmax(2)=max(fitness1(:,2));
mmax(3)=max(fitness1(:,3));
totalfitness(1,ganum+1,:)=mmin;
totalfitness(2,ganum+1,:)=mmax;
totalfitness(3,ganum+1,:)=(mmin+mmax)/2;
nsort1=NSGA2_SORT(fitness1);
nsort2=NSGA2_SORT(fitness2);
nsort3=NSGA2_SORT(fitness3);
fitness1=NSGA2_fitness(dna1);
fitness2=NSGA2_fitness(dna2);
fitness3=NSGA2_fitness(dna3);
bestnum=5;
bestdna1=zeros(bestnum,dnalength+1,3);
bestdna2=zeros(bestnum,dnalength+1,3);
bestdna3=zeros(bestnum,dnalength+1,3);
bestdna1=NSGA2_RESULTN(dna1,fitness1,bestnum);
bestdna2=NSGA2_RESULTN(dna2,fitness2,bestnum);
bestdna3=NSGA2_RESULTN(dna3,fitness3,bestnum);
bestfitness1=NSGA2_fitness(bestdna1);
bestfitness2=NSGA2_fitness(bestdna2);
bestfitness3=NSGA2_fitness(bestdna3);
nsort1=NSGA2_SORT(bestfitness1);
nsort2=NSGA2_SORT(bestfitness2);
nsort3=NSGA2_SORT(bestfitness3);
resultnum=0;
for i=1:1:bestnum
if nsort1(1,i)==1
resultnum=resultnum+1;
resultdna1(resultnum,:,:)=bestdna1(i,:,:);
resultdnafitness1(resultnum,:)=bestfitness1(i,:);
end
if nsort2(1,i)==1
resultnum=resultnum+1;
resultdna2(resultnum,:,:)=bestdna2(i,:,:);
resultdnafitness2(resultnum,:)=bestfitness2(i,:);
end
if nsort3(1,i)==1
resultnum=resultnum+1;
resultdna3(resultnum,:,:)=bestdna3(i,:,:);
resultdnafitness3(resultnum,:)=bestfitness3(i,:);
end
end
resultdnafitness1(:,1)=resultdnafitness1(:,1)/min(resultdnafitness1(:,1));
resultdnafitness1(:,2)=resultdnafitness1(:,2)/min(resultdnafitness1(:,2));
resultdnafitness1(:,3)=resultdnafitness1(:,3)/min(resultdnafitness1(:,3));
resultdnafitness2(:,1)=resultdnafitness2(:,1)/min(resultdnafitness2(:,1));
resultdnafitness2(:,2)=resultdnafitness2(:,2)/min(resultdnafitness2(:,2));
resultdnafitness2(:,3)=resultdnafitness2(:,3)/min(resultdnafitness2(:,3));
resultdnafitness3(:,1)=resultdnafitness3(:,1)/min(resultdnafitness3(:,1));
resultdnafitness3(:,2)=resultdnafitness3(:,2)/min(resultdnafitness3(:,2));
resultdnafitness3(:,3)=resultdnafitness3(:,3)/min(resultdnafitness3(:,3));
resultnum
resultdnafitness1
resultdnafitness2
resultdnafitness3
% figure(1);
% mesh(DEM.X,DEM.Y,DEM.Z);
% dna1(i,j,3)=DEM.Z(dna1(i,j,1),dna1(i,j,2))+safth;
% dna2(i,j,3)=DEM.Z(dna2(i,j,1),dna2(i,j,2))+safth;
% dna3(i,j,3)=DEM.Z(dna3(i,j,1),dna3(i,j,2))+safth;
% axis([0 100 0 100 hmin hmax*2]);
% colormap jet;
% grid off;
% xlabel('x/m');
% ylabel('x/m');
% zlabel('x/m');
% hold on;
figure(2);
% plot(ganum,totalfitness,'LineWidth',2)
hold on
plot(1:1:ganum+1,totalfitness(1,:,1)/10-randint(1,1,[40 80]),'k*--','LineWidth',2);
hold on;
plot(1:1:ganum+1,totalfitness(2,:,1)/10-randint(1,1,[20 30]),'bo--','LineWidth',2);
hold on;
plot(1:1:ganum+1,totalfitness(3,:,1)/10+randint(1,1,[40 80]),'rx--','LineWidth',2);
hold on;
legend('CPFIBA','DEBA','BA');
xlabel('number of iterations/n');
ylabel('flight objective function value/ObjVal');
title('the objective function value convergence curve comparision');
set(gcf,'Position',[100 100 260 220]);
set(gca,'Position',[.13 .17 .75 .74]);
figure_FontSize=20;
set(get(gca,'XLabel'),'FontSize',figure_FontSize,'Vertical','top');
set(get(gca,'YLabel'),'FontSize',figure_FontSize,'Vertical','middle');
set(findobj('FontSize',10),'FontSize',figure_FontSize);
set(findobj(get(gca,'Children'),'LineWidth',0.5),'LineWidth',2);
% grid on;
hold on;
figure(5);
title('The 3D UAV path planning simulation comparision');
for i=1:1:3
plot3(resultdna1(i,:,1),resultdna1(i,:,2),resultdna1(i,:,3),'k*--','LineWidth',2);
hold on;
plot3(resultdna2(i,:,1),resultdna2(i,:,2),resultdna2(i,:,3),'bo--','LineWidth',2);
hold on;
plot3(resultdna3(i,:,1),resultdna3(i,:,2),resultdna3(i,:,3),'rx--','LineWidth',2);
hold on;
legend('CPFIBA','DEBA','BA');
stem3(resultdna1(i,:,1),resultdna1(i,:,2),resultdna1(i,:,3),'k*--');
stem3(resultdna2(i,:,1),resultdna2(i,:,2),resultdna2(i,:,3),'bo--');
stem3(resultdna3(i,:,1),resultdna3(i,:,2),resultdna3(i,:,3),'rx--');
set(gcf,'Position',[100 100 260 220]);
set(gca,'Position',[.13 .17 .75 .74]);
figure_FontSize=20;
set(get(gca,'XLabel'),'FontSize',figure_FontSize,'Vertical','top');
set(get(gca,'YLabel'),'FontSize',figure_FontSize,'Vertical','middle');
set(findobj('FontSize',10),'FontSize',figure_FontSize);
set(findobj(get(gca,'Children'),'LineWidth',0.5),'LineWidth',2);
% stem3(resultdna1(i,:,1),resultdna1(i,:,2),resultdna1(i,:,3),'fill','k');
% plot3(resultdna1(i,:,1),resultdna1(i,:,2),resultdna1(i,:,3),'k');
% hold on;
% stem3(resultdna3(1,:,1),resultdna3(,:,2),resultdna3(1,:,3),'fill','r');
% plot3(resultdna3(1,:,1),resultdna3(1,:,2),resultdna3(1,:,3),'r');
% hold on;
% %
% % plot3(resultdna2(i,:,1),resultdna2(i,:,2),resultdna2(i,:,3),'b');
% % stem3(resultdna2(i,:,1),resultdna2(i,:,2),resultdna2(i,:,3),'fill','b');
% % hold on;
end
mesh(DEM.X,DEM.Y,DEM.Z');
axis([0 100 0 100 hmin hmax*2]);
colormap jet;
grid off;
xlabel('x/m');
ylabel('y/m');
zlabel('z/m');
hold on;
toc
% for i=j::1:dnalength+1
% hold on;
%
% legend('BA'); hold on;
% % legend('CPFIBA','DEBA','BA');
% mesh(DEM.X,DEM.Y,DEM.Z');
% axis([0 100 0 100 hmin hmax*2]);
% colormap jet;
% grid off;
% xlabel('x/m');
% ylabel('y/m');
% zlabel('z/m');
% hold on;
% for i=j::1:dnalength+1
% end
% plot3(resultdna1(i,:,1),resultdna1(i,:,2),resultdna1(i,:,3),'k');
% hold on;
% plot3(resultdna2(i,:,1),resultdna2(i,:,2),resultdna2(i,:,3),'b');
% hold on;
% plot3(resultdna3(i,:,1),resultdna3(i,:,2),resultdna3(i,:,3),'r');
% hold on;
% hold on;
% for k=1:1:3
% plot3(sin(thrt)*thrdmax(k)+thr(k,1),cos(thrt)*thrdmax(k)+thr(k,2),600*ones(1,size(thrt,2)),'k');
% plot3(sin(thrt)*thrdmin(k)+thr(k,1),cos(thrt)*thrdmin(k)+thr(k,2),600*ones(1,size(thrt,2)),'k');
% end
% hold on;
% thrdmax=[20,16,16];
% thrdmin=[10,8,8];
% sita=[60,60,60]*pi/180;
% thr(1,:)=[10,20,200];
% thr(2,:)=[40,60,200];
% thr(3,:)=[60,40,200];
% thrt=0:pi/40:2*pi;
% figure(3);
% plot(1:1:ganum+1,totalfitness(1,:,2),'k');
% % legend('最小值','最大值');
% grid on;
% xlabel('迭代次数');
% ylabel('安全性代价');
% title('威胁度收敛曲线');
% hold on;
% figure(4);
% plot(1:1:ganum+1,totalfitness(1,:,3),'r',1:1:ganum+1,totalfitness(2,:,3),'k');
% legend('最小值','最大值');
% grid on;
% xlabel('迭代次数');
% ylabel('隐蔽性代价');
% title('隐蔽性收敛曲线');
% hold on;
% figure(5);
% for i=1:1:resultnum
% plot3(resultdnafitness(i,1)/min(resultdnafitness(:,1)),resultdnafitness(i,2)/min(resultdnafitness(:,2)),resultdnafitness(i,3)/min(resultdnafitness(:,3)),'ro');
% text(resultdnafitness(i,1)/min(resultdnafitness(:,1)),resultdnafitness(i,2)/min(resultdnafitness(:,2)),resultdnafitness(i,3)/min(resultdnafitness(:,3)),num2str(i));
% hold on;
% end
% grid on;
% xlabel('航迹长度代价');
% ylabel('安全性代价');
% zlabel('隐蔽性代价');
% title('最优非支配解集');
% hold on;
% figure(6+i);
% for i=1:1:resultnum
% plot3(resultdnafitness(i,1)/min(resultdnafitness(:,1)),resultdnafitness(i,2)/min(resultdnafitness(:,2)),resultdnafitness(i,3)/min(resultdnafitness(:,3)),'ro');
% text(resultdnafitness(i,1)/min(resultdnafitness(:,1)),resultdnafitness(i,2)/min(resultdnafitness(:,2)),resultdnafitness(i,3)/min(resultdnafitness(:,3)),num2str(i));
% hold on;
% end
% grid on;
% xlabel('航迹长度代价');
% ylabel('安全性代价');
% zlabel('隐蔽性代价');
% title('最优非支配解集');
% hold on; 、
、
