《Linux多线程服务端编程:使用muduoC++网络库》学习笔记
文章目录
- 第1章 线程安全的对象生命期管理
-
- 1.1 当析构函数遇到多线程
-
- 1.1.1 线程安全的定义
- 1.1.3 线程安全实例
- 1.2 对象的创建很简单
- 1.3 销毁很难
- 1.4 线程安全的Observer有多难
- 1.6 神器 shared_ptr/weak_ptr
- 1.7 C++ 内存问题及其对策
- 1.8 应用到Observer上
- 1.9 shared_ptr的线程安全
- 1.10 shared_ptr技术与陷阱
-
- 意外延长对象的生命期
- 函数参数
- 析构动作在创建时被捕获
- 析构所在的线程
- 现成的 RAII handle
- 1.11 对象池
-
- 1.11.1 enable_shared_from_this
-
- 使用场景
- 1.11.2 弱回调
- 第2章 线程同步精要
- 2.1 互斥器(mutex)
-
- 2.1.1 只使用非递归的mutex
- 2.1.2 死锁
- 2.2 条件变量
- 2.3 不要用读写锁和信号量
-
- 读写锁
- 信号量
- 2.5 线程安全的Singleton实现
- 2.6 sleep函数不是同步原语
- 2.8 借 shared_ptr 实现 copy-on-write
-
- 适用场景
- 缺点
- 第3章 多线程服务器的适用场景与常用编程模型
-
- Reactor
- Proactor
- 3.1 进程和线程
- 3.2 单线程服务器的常用编程模型
- 3.3 多线程服务器的常用编程模型
-
- 3.3.1 one loop per thread
- 3.3.2 线程池
- 3.3.3 推荐模式
- 3.4 进程间通信只用TCP
-
- 分布系统中使用TCP长连接通信
- 3.5 多线程服务器的适用场合
-
- 3.5.1 必须使用单线程的场合
- 3.5.3 适用多线程程序的场景
-
- 线程的分类
- 3.6 多线程服务器适用场合 例释与答疑
- 第4章 C++多线程系统编程精要
-
- 4.1 基本线程原语的选用
- 4.2 C/C++系统库的线程安全性
- 4.3 Linux上的线程标识
- 4.4 线程创建与销毁的守则
-
- 4.4.2 exit在C++中不是线程安全的
- 4.5 善用__thread关键字
- 4.6 多线程与IO
- 4.7 用RAII包装文件描述符
- 4.8 RAII 与 fork()
- 4.9 多线程与fork()
- 4.10 多线程与signal
- 第5章 高效的多线程日志
-
- 5.1 功能需求
- 5.2 性能需求
- 5.3 多线程异步日志
-
- 实现
- 关键代码
- 如果日志消息堆积怎么办?
- 5.4 其他方案
- 第6章 muduo网络库简介(及并发网络服务程序设计方案)
-
- 6.4 使用教程
-
- 6.4.1 TCP网络编程本质论
- 6.4.2 echo服务的实现
- 6.4.3 finger服务的实现
- 6.6.2 常见的并发服务器设计方案
- 结语
- 第7章 muduo编程示例
-
- 7.1 五个简单TCP示例
- 7.2 文件传输
- 7.3 Boost.Asio 的聊天服务器
- 7.4 muduo Buffer类的设计与使用
-
- 7.4.3 Buffer的功能需求
-
- 线程安全?
- 7.4.4 Buffer的数据结构
- 7.5 —种自动反射消息类型的Protobuf网络传输方案
- 7.6 在muduo中实现Protobuf编解码器与消息分发器
-
- 7.6.1 什么是编解码器(codec)
- 7.6.3 消息分发器(dispatcher)
- 7.7 限制服务器的最大并发连接数
-
- 7.7.2 在muduo中限制并发连接数
- 7.8 定时器
-
- 7.8.2 Linux时间函数
- 7.8.3 muduo的定时器接口
- 7.10 用timing wheel踢掉空闲连接
-
- 7.10.1 Timing wheel 原理
- 7.10.2 代码实现与改进
- 7.11 简单的消息广播服务
- 7.12 "串并转换"连接服务器
- 7.15 与其他库集成
- 第8章 muduo 网络库设计与实现
-
- 8.0 什么都不做的EventLoop
- 8.1 Reactor的关键结构
-
- 8.1.1 Channel class
- 8.1.2 Poller class
- 8.1.3 总结
- 8.2 TimerQueue定时器
-
- Timer类
- TimerId类
- TimerQueue类
- 8.3 EventLoop::runInLoop()函数
-
- 唤醒IO监听阻塞
- 8.3.2 EventLoopThread class
- 8.4 实现TCP网络库
-
- Acceptor class
- 8.5 TcpServer接受新连接
-
- 8.5.1 TcpServer class
- 8.5.2 TcpConnection class
- 8.6 TcpConnection断开连接
- 8.7 Buffer读取数据
-
- 8.7.1 TcpConnection使用Buffer作为输入缓冲
- 8.7.2 Buffer::readFd()
- 8.8 TcpConnection发送数据
- 8.9 完善TcpConnection
-
- 8.9.1 SIGPIPE
- 8.9.2 TCP No Delay 和 TCP keepalive
- 8.9.3 WriteCompleteCallback和HighWaterMarkCallback
- 8.10 多线程程TcpServer
-
- EventLoopThreadPool
- 8.11 Connector
-
- TimerQueue::cancel()
- 8.12 TcpClient
- 8.13 epoll
- 第9章 分布式系统工程实践
-
- 9.2 分布式系统的可靠性浅说
-
- 9.2.1 分布式系统的软件不要求7x24可靠
- 9.2.2 “能随时重启进程”作为程序设计目标
- 9.3 分布式系统中心跳协议的设计
- 9.4 分布式系统中的进程标识
-
- 9.4.1 错误做法
- 9.4.2 正确做法
- 9.5 构建易于维护的分布式程序
- 9.6 为系统演化做准备
-
- 9.6.1 可扩展的消息格式
- 9.7 分布式程序的自动化回归测试
- 第10章 C++编译链接模型精要
-
- 10.1 C语言的编译模型及其成因
-
- 10.1.1 为什么C语言需要预处理
- 10.1.2 C语言的编译模型
- 10.2 C++的编译模型
-
- 10.2.2 前向声明
- 10.3 C++链接(Linking)
-
- 10.3.1 函数重载
- 10.3.2 inline函数
- 10.3.3 模板
-
- template和inline函数会不会导致代码膨胀
- 限制模板的具现化 / 隐藏模板实现
- 10.3.4 虚函数
- 10.4 共程项目中头文件的使用规则
-
- 10.4.1 头文件的害处
- 10.4.2 头文件的使用规则
- 10.5 程项目中库文件的组织原则
-
- 10.5.1 动态库的缺点
- 10.5.2 静态库的缺点
- 10.5.3 源码编译最优
- 第11章 反思C++面向对象与虚函数
-
- 11.1 朴实的C++设计
- 11.2 程序库的二进制兼容性
-
- 11.2.1 什么是二进制兼容性
- 11.2.2 有哪些情况会破坏库的ABI
-
- header-only库文件
- 11.2.5 解决办法
- 11.3 避免使用虚函数作为库的接口
-
- 11.3.1 C++程序库的作者的生存环境
- 1.3.3 虚函数作为接口的弊端
- 11.4 动态库接口的推荐做法
- 11.5 std::function和std::bind VS 虚函数
- 12.7 再探std::string
-
- 12.7.1 直接拷贝(eager copy)
- 12.7.2 写时复制(copy-on-write)
- 12.7.3 短字符串优化(SSO)
第1章 线程安全的对象生命期管理
1.1 当析构函数遇到多线程
C++多线程对象的销毁可能会碰到竞态条件,解决办法是使用shared_ptr。
1.1.1 线程安全的定义
依据[JCP],一个线程安全的class应当满足以下三个条件:
-
多个线程同时访问,表现出正确的行为。
-
无论操作系统如何调度,以及线程的执行顺序如何交织。
-
调用端代码不需要额外的同步或其他协调动作。
由此,STL大多数的class都不是线程安全的,包括std::string, vector, map等, 需要外部加锁才能多个线程同时访问。
1.1.3 线程安全实例
const对象的成员mutex不能进行加解锁操作,除非该mutex使用mutable修饰。
1.2 对象的创建很简单
对象构造要做到线程安全,唯一的要求是在构造期间不要泄漏this指针。
- 不要在构造函数中注册任何回调;
- 不要在构造函数中把this传给跨线程的对象;
- 即便在构造函数的最后一行也不行。
原因
构造期间对象还没有完成初始化,this泄漏给了别的对象(自身创建的子对象除外),别的线程有可能访问这个半成品对象。最后一行也不行,是因为当前类可能是父类,子类的对象依然没有初始化完成。
解决方法
二段式构造:构造函数+initialize
class Foo:public Observer
{
public:
Foo();
...
void observer(Obeserver* s){
s->register(this);
}
}
Foo* pFoo = new Foo;
Observable* s = getSubject();
pFoo->observe(s);
1.3 销毁很难
mutex不是办法:
- 作为数据成员的mutex不能保护析构,因为析构可能销毁mutex本身,而此时析构函数没有完成。
- 如果同时锁住一个class的两个对象,有潜在死锁可能,比如swap(a,b)与swap(b,a)在两个线程中同时执行,会发生死锁。
解决办法:一个函数如果要锁住相同类型的多个对象,为了保证始终按相同的顺序加锁,我们可以比较mutex对象的地址,始终先加锁地址较小的mutex。
1.4 线程安全的Observer有多难
三种对象关系的线程安全性
- 组合(composition):很明晰。它们的生命期都由其拥有者控制,是一致的,不会有什么问题。
- 关联(association):只有另一个对象的指针或引用,无法知道其是生是死。判断指针是否合法在 C++ 中没有高效的方法。
- 聚合(aggregation):其困难和关联类似。虽然是整体和部分的关系,但这个“部分”的生命期受外部影响。
Observer模式中的线程安全问题
多个 Observer 的指针(引用)注册到 Observable,这些指针的使用可能引发 race condition。
1.6 神器 shared_ptr/weak_ptr
shared_ptr 是引用计数型智能指针,谈几个关键点。
- shared_ptr 控制对象的生命期。shared_ptr 是强引用(想象成用铁丝绑住堆上的对象),只要有一个指向 x 对象的 shared_ptr 存在,该 x 对象就不会析构。当指向对象 x 的最后一个 shared_ptr 析构或 reset() 的时候,x 保证会被销毁。
- weak_ptr 不控制对象的生命期,但是它知道对象是否还活着(想象成用棉线轻轻拴住堆上的对象)。如果对象还活着,那么它可以提升为有效的shared_ptr;如果对象已经死了,提升会失败,返回一个空的 shared_ptr。“提升/lock()”行为是线程安全的。
- shared_ptr/weak_ptr 的“计数”在主流平台上是原子操作,没有用锁,性能不俗。
- shared_ptr/weak_ptr 的对象的读写不是线程安全的。
1.7 C++ 内存问题及其对策
C++里可能出现的内存问题大致有这么几个方面(以及解决办法):
- 缓冲区溢出 buffer overrun:使用
vector或者自己编写的 Buffer class 管理缓冲区。/ std::string - 空悬指针/野指针:使用 shared_ptr / weak_ptr。
- 重复释放 double delete:使用 shared_ptr。
- 内存泄露 memory leak:使用 shared_ptr
- 不配对的 new[]/delete:把 new[] 替换为 vector。
- 内存碎片 memory fragementation:见9.2.1和A.1.8。
1.8 应用到Observer上
既然通过weak_ptr能探查对象的生死,那么Observer模式的竞态条件就很容易解决,只要让observable保存weak_ptr即可:
class Observable // not 100% thread safe!
{
public:
void register_(weak_ptr x);
// void unregister(weak_ptr x); // 不再需要
void notifyObservers()
{
MutexLockGuard lock(mutex_);
Iterator it = observers_.begin();
while (it != observers_.end())
{
shared_ptr obj(it->lock());
if (obj)
{
obj->update();
++it;
}
else
{
it = observers_.erase(it);
}
}
}
private:
mutable MutexLock mutex_;
std::vector > observers_;
typedef std::vector >::iterator Iterator;
};
1.9 shared_ptr的线程安全
shared_ptr的引用计数本身是安全且无锁的,但对象的读写则不是。shared_ptr 的线程安全级别和内建类型、标准库容器、std::string 一样,即:
- 一个 shared_ptr 对象实体可被多个线程同时读取;
- 两个 shared_ptr 对象实体可以被两个线程同时写入,“析构”算写操作;
- 如果要从多个线程读写同一个 shared_ptr 对象,那么需要加锁。
请注意,以上是 shared_ptr 对象本身的线程安全级别,不是它管理的对象的线程安全级别。
不加锁读写shared_ptr竞态条件示例:https://blog.csdn.net/solstice/article/details/8547547
1.10 shared_ptr技术与陷阱
意外延长对象的生命期
shared_ptr允许拷贝构造和赋值的,如果不小心遗留了一个拷贝,那么对象生命期就被延长了。
一个出错的可能是bind,因为bind会把实参拷贝一份,如果参数是个 shared_ptr,那么对象的生命期就不会短于function对象:
class Foo {
void doit();
};
shared_ptr pFoo(new Foo);
function func = bind(&Foo::doit, pFoo); // long life foo
lambda函数同理。
函数参数
因为要修改引用计数(而且拷贝的时候通常要加锁),shared_ptr 的拷贝开销比拷贝原始指针要高,但是需要拷贝的时候并不多。多数情况下它可以以const reference (常引用)方式传递。
析构动作在创建时被捕获
这是一个非常有用的特性,这意味着:
-
虚析构不再是必需的。(通过shared_ptr去释放派生类对象,无需将析构函数置为virtual)
因为实际类型已经被记住,能够自动调用实际类型的析构。https://blog.csdn.net/elija940818/article/details/102868664
-
shared_ptr可以持有任何对象,而且能安全地释放。 -
shared_ptr对象可以安全地跨越模块边界,比如从DLL里返回,而不会造成从模块A分配的内存在模块B里被释放这种错误。
-
析构动作可以定制。
析构所在的线程
使用单独的线程做 shared_ptr 管理的对象的析构,避免耗时的析构发生在关键线程里。
现成的 RAII handle
每一个明确的资源配置动作(例如 new)都应该在单一语句中执行,并在该语句中立刻将配置获得的资源交给 handle对象,程序中一般不出现 delete。
shared_ptr是管理共享资源的利器,需要注意避免循环引用,通常的做法是owner持有指向child的shared_ptr,child持有指向owner的weak_ptr。
1.11 对象池
假设有 Stock 类,代表一只股票的价格。每一只股票有一个唯一的字符串标识,为了节省系统资源,同一个程序里每一只股票只有一个 Stock 对象,如果多处用到同一只股票,那么 Stock 对象应该被共享。如果某一只股票没有再在任何地方用到,其对应的 Stock 对象应该析构,以释放资源,这隐含了“引用计数”。
1.11.1 enable_shared_from_this
需求: 在类的内部获得自身的shared_ptr 而不是this裸指针 。
enable_shared_from_this是一个以其派生类为模板类型实参的基类模板,继承它,this指针就能变身为shared_ptr。
并且,在类内部通过 enable_shared_from_this 定义的 shared_from_this() 函数构造一个 shared_ptr 对象, 能和其他 shared_ptr 共享类对象。
| shared_from_this | 返回共享 *this 所有权的 shared_ptr (公开成员函数) |
| weak_from_this(C++17) | 返回共享 *this 所有权的 weak_ptr (公开成员函数) |
#include
#include
struct Good: std::enable_shared_from_this // 注意:继承
{
std::shared_ptr getptr() {
return shared_from_this();
}
};
struct Bad
{
// 错误写法:用不安全的表达式试图获得 this 的 shared_ptr 对象
std::shared_ptr getptr() {
return std::shared_ptr(this);
}
~Bad() { std::cout << "Bad::~Bad() called\n"; }
};
int main()
{
// 正确的示例:两个 shared_ptr 对象将会共享同一对象
std::shared_ptr gp1 = std::make_shared();
std::shared_ptr gp2 = gp1->getptr();
std::cout << "gp2.use_count() = " << gp2.use_count() << '\n';
// 错误的使用示例:调用 shared_from_this 但其没有被 std::shared_ptr 占有
try {
Good not_so_good;
std::shared_ptr gp1 = not_so_good.getptr();
} catch(std::bad_weak_ptr& e) {
// C++17 前为未定义行为; C++17 起抛出 std::bad_weak_ptr 异常
std::cout << e.what() << '\n';
}
// 错误的示例,每个 shared_ptr 都认为自己是对象仅有的所有者
std::shared_ptr bp1 = std::make_shared();
std::shared_ptr bp2 = bp1->getptr();
std::cout << "bp2.use_count() = " << bp2.use_count() << '\n';
} // UB : Bad 对象将会被删除两次
输出:
gp2.use_count() = 2
bad_weak_ptr
bp2.use_count() = 1
Bad::~Bad() called
Bad::~Bad() called
*** glibc detected *** ./test: double free or corruption
使用场景
在异步调用中,存在一个保活机制,异步函数执行的时间点我们是无法确定的,然而异步函数可能会使用到异步调用之前就存在的变量。为了保证该变量在异步函数执期间一直有效,我们可以传递一个指向自身的share_ptr给异步函数(通过bind函数),这样在异步函数执行期间share_ptr所管理的对象就不会析构,所使用的变量也会一直有效了(保活)。
1.11.2 弱回调
弱回调语义:如果对象还活着,就调用它的成员函数,否则忽略之。( 同observable::notifyobservers() )
实现:利用weak_ptr,我们可以把weak_ptr绑到function里,这样对象的生命期就不会被延长。然后在回调的时候先尝试提升为shared_ptr,如果提升成功,说明接受回调的对象还健在,那么就执行回调;如果提升失败,就不必劳神了。
class Stock {
public:
Stock(const std::string& name) :
stockName(name)
{
printf("Stock created.\n");
}
~Stock() {
printf("Stock destroyed.\n");
}
const std::string& getName() const {
return stockName;
}
private:
std::string stockName;
};
class Factory: public std::enable_shared_from_this {
public:
std::shared_ptr
getStock(const std::string& stockName) {
std::lock_guard lck(_mutex);
std::weak_ptr& wpSto = container[stockName];
std::shared_ptr spSto = wpSto.lock();
if (!spSto) {
std::weak_ptr wfac = std::weak_ptr(shared_from_this());
/*等价于C++17 weak_from_this()*/
//reset绑定删除器
spSto.reset(new Stock(stockName),
std::bind(&Factory::deleteStock,
wfac, std::placeholders::_1));
wpSto = spSto;
}
return spSto;
}
private:
// "static" is the key point
// 弱回调
static void deleteStock(std::weak_ptr& wptr, Stock* sto) {
std::shared_ptr sptr = wptr.lock();
if (sptr) {
sptr->container.erase(sto->getName());
}
delete sto;
}
private:
std::unordered_map> container;
mutable std::mutex _mutex;
};
心得:
- 没有垃圾回收的并发编程是困难的。
- 应该尽量减少使用跨线程的对象。
第2章 线程同步精要
线程同步四项原则:
- 尽量最低限度地共享对象,减少需要同步的场合。如果确实需要,优先考虑共享 immutable 对象。
- 使用高级的并发编程构建
- 不得已必须使用底层同步原语(primitives)时,只用非递归的互斥器和条件变量,慎用读写锁,不要用信号量。
- 除了使用 atomic 整数之外,不自己编写 lock-free 代码,也不要用“内核级”同步原语。不凭空猜测“哪种做法性能会更好”,比如 spin lock vs. mutex。
2.1 互斥器(mutex)
单独使用mutex时,我们主要为了保护共享数据。作者个人的原则是:
- 用 RAII 手法封装 mutex 的创建、销毁、加锁、解锁这四个操作。保证锁的生效期间等于一个作用域(scope)。
- 只用非递归的 mutex(即不可重入的 mutex)。使用非递归的锁调试更加的容易(栈的调用上分析)。
- 不手工调用 lock() 和 unlock() 函数,一切交给栈上的 Guard 对象的构造和析构函数负责(Scoped Locking)。
- 在每次构造 Guard 对象的时候,思考一路上(调用栈上)已经持有的锁,防止因加锁顺序不同而导致死锁。
次要原则:
- 不使用跨进程的mutex,进程间通信只使用TCP socket。
- 加锁解锁在同一个线程,不能跨线程解锁(RAII自动保证)。
- 别忘了解锁(RAII自动保证)。
- 不重复解锁(RAII自动保证)。
- 必要的时候用PTHREAD_MUTEX_ERROCHECK来排错。
2.1.1 只使用非递归的mutex
非递归的mutex优越性:把程序的逻辑错误暴露出来。
死锁比较容易debug,把各个线程的调用栈打印出来。
打印线程调用栈步骤:
- 使用SIGABRT终止死锁的程序(
kill -SIGABRT 进程pid),生成coredump文件(ulimit -c unlimited打开coredump选项); - 使用
gdb ./test core调试coredump文件; - 输入
thread apply all bt打印各线程调用栈。
如果一个函数既可能在已加锁的情况下调用,又可能在未加锁的情况下调用,可以拆成两个函数:
- 跟原来的函数同名,函数加锁,转而调用第2个函数。
- 给函数名加上后缀WithLockHold,不加锁,把原来的函数体搬过来。
如下
void post(const Foo& f) {
MutexLockGuard lock(mutex);
postWithLockHold(f) ; //不用担心开销,编译器会自动内联的
}
void postWithLockHold(const Foo& f) {
foos.push_back(f);
}
性能注脚:
- Linux的Pthreads mutex采用futex(2)实现,不必每次加锁、解锁都陷入系统调用,效率不错。
- Windows的CRITICAL_SECTION也是类似的,不过它可以嵌入一小段spin lock。在多CPU系统上,如果不能立刻拿到锁,它会先spin一小段时间,如果还不能拿到锁,才挂起当前线程。
2.1.2 死锁
不同线程同时对两个锁进行操作,如果加锁顺序不同,可能会造成死锁。
2.2 条件变量
如果需要等待某个条件成立,我们应该使用条件变量(condition variable)。
条件变量只有一种正确使用的方式,几乎不可能用错。
-
对于wait端:
- 必须与mutex一起使用,该布尔表达式的读写受mutex的保护;
- 在mutex已经上锁的时候才能调用wait();
- 把判断布尔条件和wait()放到while循环中(避免虚假唤醒)。
写成代码:
muduo::MutexLock mutex; muduo::Condition cond(mutex); std::dequequeue; int dequeue() { MutexLockGuard lock(mutex); while (queue.empty())//必须用循环;必须在判断之后再wait() { cond.wait(); //这一步会原子地unlock mutex并进入等待,不会与enqueue死锁 // wait执行完毕时会自动重新加锁 } assert(!queue.empty()); int top = queue.front(); queue.pop_front(); return top; } -
对于signal/broadcast 端:
- 不一定要在mutex已经上锁的情况下调用signal(理论上);
- 在signal之前一般要修改布尔表达式;
- 修改布尔表达式通常需要mutex保护;
- 注意区分signal和broadcast:“broadcast 通常用于表明状态变化,signal 通常用于表示资源可用。”
写成代码:
void enqueue(int x) { MutexLockGuard lock(mutex); queue.push_back(x); cond.notify(); //可以移出临界区之外 }
上面的dequeue()/enqueue()实际上实现了一个简单的容量无限的BlockingQueue。
条件变量是非常底层的同步原语,很少直接使用,一般都是用它来实现高层的同步措施,如BlockingQueue 或 CountDownLatch。
倒计时(CountDownLatch)是一种常用且易用的同步手段。它主要有两种用途:
- 主线程发起多个子线程,等这些子线程各自都完成一定的任务之后,主线程才继续执行。通常用于主线程等待多个子线程完成初始化。
- 主线程发起多个子线程,子线程都等待主线程,主线程完成其他一些任务之后通知所有子线程开始执行。通常用于多个子线程等待主线程发出“起跑"命令。
当然我们可以直接用条件变量来实现以上两种同步。不过如果用CountDownLatch 的话,程序的逻辑更清晰:
class CountDownLatch : noncopyable
{
public:
explicit CountDownLatch(int count)
: mutex_(),
condition_(mutex_),
count_(count)
{
}
void wait()
{
MutexLockGuard lock(mutex_);
while (count_ > 0)
{
condition_.wait();
}
}
void countDown()
{
MutexLockGuard lock(mutex_);
--count_;
if (count_ == 0)
{
condition_.notifyAll();
}
}
int getCount() const
{
MutexLockGuard lock(mutex_);
return count_;
}
private:
mutable MutexLock mutex_;
Condition condition_;
int count_;
};
互斥器和条件变量构成了多线程编程的全部必备同步原语,用它们即可完成任何多线程同步任务,二者不能相互替代。
2.3 不要用读写锁和信号量
读写锁
读写锁的缺陷:
-
正确性方面,一种典型的错误就是持有read lock时修改了共享数据,这通常发生在程序的维护阶段 新增功能时。
-
性能方面:读写锁不见得比普通mutex更高效。无论如何reader lock加锁的开销不会比mutex lock小,因为它要更新当前reader的数目。如果临界区很小,锁竞争不激烈,那么mutex往往会更快。
-
通常读锁是可重入的,写锁是不可重入的。但是为了防止writer饥饿,writer lock通常会阻塞后来的reader lock,因此reader lock在重入的时候可能死锁。
建议用mutex代替读写锁。
遇到并发读写,如果条件合适,可以用2.8章节的办法代替读写锁,同时避免reader被writer阻塞。如果确实对并发读写有极高的性能要求,可以考虑read-copy-update。
读-拷贝-更新(Read-Copy Update)
使用RCU保护的共享数据,读操作不需要获得任何锁就可以访问,不使用原子操作。写操作在访问前需要先复制一份副本,然后对副本进行修改,最后使用一个回调机制,在适当的时机把指向原来数据的指针重新指向新的被修改的数据。RCU可以看做读写锁的高性能版本。
信号量
作者认为信号量不是必备的同步原语,因为条件变量配合互斥器可以完全替代其功能,而且更不易用错。除了[RWC]指出的“semaphore has no notion of ownership”之外,信号量的另一个问题在于它有自己的计数值,而通常我们自己的数据结构也有长度值,这就造成了同样的信息存了两份,需要时刻保持一致,这增加了程序员的负担和出错的可能。如果要控制并发度,可以考虑用ThreadPool。
哲学家就餐问题的改进:
把“想吃饭”这个事情专门交给一个为各位哲学家分派餐具的线程来做,然后每个哲学家等在一个简单的condition variable上,到时间了有人通知他去吃饭。
2.5 线程安全的Singleton实现
class Singleton
{
private:
Singleton() {
}
~Singleton() {
}
Singleton(const Singleton &);
Singleton & operator = (const Singleton &);
public:
static Singleton & GetInstance()
{
static Singleton instance;
return instance;
}
};
2.6 sleep函数不是同步原语
sleep()类只能出现在测试代码中。比如写单元测试的时候,或者用于有意延长临界区,加速复现死锁的情况。
生产代码中线程的等待可分为两种:
- 一种是等待资源可用(要么等在select/poll/epoll-wait上,要么等在条件变量上);
- 一种是等着进入临界区(等在mutex上)以便读写共享数据。
后一种等待通常极短,否则程序性能和伸缩性就会有问题。
在程序的正常执行中,如果需要等待一段已知的时间,应该往event loop里注册一个timer,然后在timer的回调函数里接着干活,因为线程是个珍贵的共享资源,不能轻易浪费(阻塞也是浪费)。如果等待某个事件发生,那么应该采用条件变量或IO事件回调,不要用sleep来轮询。
2.8 借 shared_ptr 实现 copy-on-write
该copy-on-write并不是指操作系统中的写时复制,而是类似前面说过的RCU(read-copy-update),是一种代替读写锁,实现读写同时进行的并发方法:用shared_ptr来管理共享数据。原理如下:
- shared_ptr是引用计数型智能指针,如果当前只有一个观察者,则引用计数为1。
- 对于read端,在读之前把引用计数加1,读完之后减1,这样保证在读的期间其引用计数大于1,可以阻止并发写。
- 对于write端,
- 如果引用计数为1,这时可以安全地修改共享对象,不必担心有人正在读它。
- 如果引用计数大于1,则复制一份,在副本上修改。
示例:
typedef std::vector<Foo> FooList;
typedef shared_ptr<FooList> FooListPtr;
FooListPtr g_foos;
MutexLock mutex;
//读者
void traverse()
{
FooListPtr foos;
{
MutexLockGuard lock(mutex);
foos = g_foos;
assert(!g_foos.unique());
}
for (std::vector<Foo>::const_iterator it = foos->begin();
it != foos->end(); ++it)
{
//打印
it->doit();
}
}
//写者
void post(const Foo& f)
{
printf("post\n");
MutexLockGuard lock(mutex);
if (!g_foos.unique())
{
g_foos.reset(new FooList(*g_foos));
printf("copy the whole list\n");
}
assert(g_foos.unique());
g_foos->push_back(f);
}
在read端,用一个栈上局部FooListPtr 变量当做“观察者”,它使得g_foos的引用计数增加。traverse函数的临界区中,只读了一次共享变量g_foos(这里多线程并发读写shared_ptr,因此必须用mutex保护),这比原来的写法大为缩短。而且多个线程同时调用traverse也不会相互阻塞。
在write端,如果g_foos.unique()为true,说明当前没有读端,可以放心地在原地修改FooList;否则说明这时别的线程正在读取FooList,不能原地修改,需要复制一份FooList,在副本上修改。这样就避免了死锁。
此外,如果每次写的数据和原数据无关,则可以将new移到临界区前面,进一步缩小临界区,但如果需要用原数据new则不行(如该例)。
JAVA中有类似的库:java.util.Concurrent.CopyOnWriteArrayList
适用场景
copy-on-write 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
缺点
copy-on-write 有其缺陷:
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 copy-on-write 不适合内存敏感以及对实时性要求很高的场景。
[TIP]swap缩小临界区的小技巧:
void CustomerData::update(const string& message)
{
MapPtr newData = parseData(message);
if (newData)
{
muduo::MutexLockGuard lock(mutex_);
data_.swap(newData); //不用data_=newData,保证data_旧数据的析构不再临界区中
}
}
第3章 多线程服务器的适用场景与常用编程模型
Reactor
reactor设计模式是一种事件处理模式,处理由一个或多个输入同时传递给服务处理程序的服务请求。然后,服务处理程序将传入的请求分解,并将它们同步地分派给相关的请求处理程序。
Linux epoll 使用 Reactor 模式。Reactor 模式使用同步 I/O(一般来说)。Reactor 的标准(典型)的工作方式是:
- 应用程序注册读就绪事件和相关联的事件处理器;
- Reactor阻塞等待内核事件通知;
- Reactor收到通知,然后分发可读写事件(读写准备就绪)到用户事件处理函数;
- 用户读取数据,并处理数据;
- 事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
Proactor
Proactor是一种用于事件处理的软件设计模式,其中长时间运行的活动在异步部分中运行。在异步部分终止后调用完成处理程序。Proactor模式可以被认为是同步Reactor模式的异步变体。
Windows iocp 使用 Proactor 模式。Proactor 模式使用异步 I/O(一般来说)。Proactor 的标准(典型)的工作方式是:
- 应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键;
- 事件分离器等待读取操作完成事件;
- 在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作,并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区;
- 事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
3.1 进程和线程
线程的特点是共享地址空间,从而可以高效地共享数据。一台机器上的多个进程能高效地共享代码段,但不能共享数据。如果多个进程大量共享内存,等于是把多进程程序当成多线程来写,掩耳盗铃。
3.2 单线程服务器的常用编程模型
在高性能的网络程序中,使用最为广泛的恐怕要数”non-blocking IO + IO multiplexing”这种模型,即Reactor模式。这种模型中,程序的基本结构是一个事件循环(event loop),以事件驱动(event-driven)和事件回调的方式实现业务逻辑:
//代码仅为示意,没有完整考虑各种情况
while(!done)
{
int timeout_ms = max(1000, getNextTimedCallback());
int retval = poll(fds, nfds, timeout_ms);
if (retval<0){
处理错误,回调用户的error handler
}else{
处理到期的timers,回调用户的timer handler
if(retval>0){
处理IO事件,回调用户的IO event handler
}
}
}
3.3 多线程服务器的常用编程模型
大概有这么几种:
- 每个请求创建一个线程,使用阻塞式IO操作。这种方式伸缩性不佳(请求太多时,操作系统创建不了这许多线程)。
- 使用线程池,同样使用阻塞式IO操作。与第1种相比,这是提高性能的措施。
- 使用non-blocking IO + IO multiplexing。即Java NIO方式。
- Leader/Follower等高级模式。
在默认情况下,我会使用第3种,即non-blocking IO + one loop per thread模式来编写多线程C++网络服务程序。
3.3.1 one loop per thread
此种模型下,程序里的每个IO线程有一个event loop,用于处理读写和定时事件。代码框架跟3.2一节中的一样。
Event loop代表了线程的主循环,需要让哪个线程干活,就把timer或IO channel(如TCP连接)注册到哪个线程的loop里即可。对实时性有要求的connection可以单独用一个线程;数据量大的connection可以独占一个线程,并把数据处理任务分摊到另几个计算线程中(用线程池);其他次要的辅助性connections可以共享一个线程。
muduo::EventLoop解析:https://blog.csdn.net/wk_bjut_edu_cn/article/details/80856873
3.3.2 线程池
不过,对于没有IO而光有计算任务的线程,使用event loop有点浪费。可以使用一种补充方案,即用blocking queue实现的任务队列:
typedef functionFunctor;
BlockingQueue taskQueue; //线程安全的全局阻塞队列
//计算线程
void workerThread() {
while (running) //running变量是个全局标志
{
Functor task = taskQueue.take(); //this blocks
task(); //在产品代码中需要考虑异常处理
}
}
// 创建容量(并发数)为N的线程池
int N = num_of_computing_threads;
for (int i = 0; i < N; ++i)
{
create_thread(&workerThread); //启动线程
}
//向任务队列中追加任务
Foo foo; //Foo有calc()成员函数
function task = bind(&Foo::calc,&foo);
taskQueue.post(task);
上面十几行代码就实现了一个简单的固定数目的线程池。
除了任务队列,还可以用BlockingQueue实现数据的生产者消费者队列,即T是数据类型,而非函数对象,queue的消费者(s)从中拿到数据进行处理。
BlockingQueue是多线程编程的利器,它的实现可参照Java util.concurrent里的(Array I Linked)BlockingQueue。这份Java代码可读性很高,代码的基本结构和教科书一致(1个mutex,2个condition variables),健壮性要高得多。如果不想自己实现,用现成的库更好。muduo里有一个基本的实现,包括无界的BlockingQueue和有界的BoundedBlockingQueue两个class。
3.3.3 推荐模式
总结而言,我推荐的C++多线程服务端编程模式为:one (event) loop per thread + thread pool:
- event loop用作IO multiplexing,配合non-blocking IO和定时器;
- thread pool用来做计算,具体可以是任务队列或生产者消费者队列。
以这种方式写服务器程序,需要一个优质的基于Reactor模式的网络库来支撑,muduo正是这样的网络库。
程序里具体用几个loop、线程池的大小等参数需要根据应用来设定,基本的原则是“阻抗匹配”,使得CPU和IO都能高效地运作。
阻抗匹配原则:
如果池中线程在执行任务时,密集计算所占的时间比重为 P (0 < P <= 1),而系统一共有 C 个 CPU,为了让这 C 个 CPU 跑满而又不过载,线程池大小的经验公式 T = C/P。(T 是个 hint,考虑到 P 值的估计不是很准确,T 的最佳值可以上下浮动 50%)这个经验公式的原理很简单,T个线程,每个线程占用P的CPU时间,如果刚好占满C个CPU,所以必有T*P=C。下面验证边界条件的正确性。
假设 C = 8,P = 1.0,线程池的任务完全是密集计算,那么T = 8。只要 8 个活动线程就能让 8 个 CPU 饱和,再多也没用,因为 CPU 资源已经耗光了。
假设 C = 8,P = 0.5,线程池的任务有一半是计算,有一半等在 IO 上,那么T = 16。考虑操作系统能灵活合理地调度 sleeping/writing/running 线程,那么大概 16 个“50%繁忙的线程”能让 8 个 CPU 忙个不停。启动更多的线程并不能提高吞吐量,反而因为增加上下文切换的开销而降低性能。
如果 P < 0.2,这个公式就不适用了,T 可以取一个固定值,比如 5*C。
另外,公式里的 C 不一定是 CPU 总数,可以是“分配给这项任务的 CPU 数目”,比如在 8 核机器上分出 4 个核来做一项任务,那么 C=4。
3.4 进程间通信只用TCP
进程间通信我首选Sockets(主要指TCP)。其好处在于:
-
可以跨主机,具有伸缩性。反正都是多进程了,如果一台机器的处理能力不够,很自然地就能用多台机器来处理。把进程分散到同一局域网的多台机器上,程序改改host:port配置就能继续用;
-
TCP sockets和pipe都是操作文件描述符,用来收发字节流,都可以read/write/fcntl/select/poll等。不同的是,TCP是双向的,Linux的pipe是单向的,进程间双向通信还得开两个文件描述符,不方便;而且进程要有父子关系才能用pipe,这些都限制了pipe的使用;
-
TCP port由一个进程独占,且进程退出时操作系统会自动回收文件描述符。因此即使程序意外退出,也不会给系统留下垃圾,程序重启之后能比较容易地恢复,而不需要重启操作系统(用跨进程的mutex就有这个风险);而且,port是独占的,可以防止程序重复启动,后面那个进程抢不到port,自然就没法初始化了,避免造成意料之外的结果;
-
与其他IPC相比,TCP协议的一个天生的好处是“可记录、可重现”。tcpdump和Wireshark是解决两个进程间协议和状态争端的好帮手,也是性能(吞吐量、延迟)分析的利器。我们可以借此编写分布式程序的自动化回归测试。也可以用tcpcopy之类的工具进行压力测试。TCP还能跨语言,服务端和客户端不必使用同一种语言(需要选择合适的消息格式,比如ProtoBuffer)。
分布系统中使用TCP长连接通信
使用TCP长连接的好处有两点:
-
一是容易定位分布式系统中的服务之间的依赖关系。只要在机器上运行
netstat -tpna|grep就能立刻列出用到某服务的客户端地址(Foreign Address列),然后在客户端的机器上用netstat或lsof命令找出是哪个进程发起的连接。TCP短连接和UDP则不具备这一特性。 -
二是通过接收和发送队列的长度也较容易定位网络或程序故障。在正常运行的时候,netstat打印的Recv-Q(Recv Queue)和Send-Q都应该接近0,或者在0附近摆动。如果Recv-Q保持不变或持续增加,则通常意味着服务进程的处理速度变慢,可能发生了死锁或阻塞。如果Send-Q保持不变或持续增加,有可能是对方服务器太忙、来不及处理,也有可能是网络中间某个路由器或交换机故障造成丢包,甚至对方服务器掉线,这些因素都可能表现为数据发送不出去。通过持续监控Recv-Q和Send-Q就能及早预警性能或可用性故障。 Recv-Q和客户端Send-Q激增的例子:
$netstat -tn Proto Recv-Q Send-Q Local Address Foreign tcp 78393 0 10.0.0.10:2000 10.0.0.10:39748 #服务端连接 tcp 0 132608 10.0.0.10:39748 10.0.0.10:2000 #客户端连接 tcp 0 52 10.0.0.10:22 10.0.0.4:55572
3.5 多线程服务器的适用场合
开发服务端程序的一个基本任务是处理并发连接,现在服务端网络编程处理并发连接主要有两种方式:
- 语言内置廉价线程,例如,Python gevent,Go goroutine,Erlang actor。这里的“线程”由语言的runtime自行调度,与操作系统线程不是一回事。
- 原生线程,能被操作系统的任务调度器看见。
如果要在一台多核机器上提供一种服务或执行一个任务,可用的模式有:
-
运行一个单线程的进程;
-
运行一个多线程的进程;
-
运行多个单线程的进程,它有两种子模式:
3a. 简单的把模式1中的进程运行多份;
3b. 主进程+worker进程;
-
运行多个多线程的进程。
3.5.1 必须使用单线程的场合
有两种场合必须使用单线程:
- 程序可能会fork(2),多线程使用fork会遇到很多麻烦。
- 限制程序的CPU占用率,比如辅助程序 。
如果用很少的CPU负载就能让IO跑满, 或者用很少的IO流量就能让CPU跑满, 那么多线程就没有啥用处。
3.5.3 适用多线程程序的场景
多线程的适用场景:提高响应速度, 让IO和计算互相重叠, 降低latency(延迟),虽然多线程不能提高绝对性能, 但多线程能提高平均响应性能。一个程序要想做多线程, 大致要满足:
- 有多个CPU可用。
- 线程间有共享数据, 即内存中的全局状态, 如果没有共享数据, 用运行多个单线程的进程就行。
- 共享的数据是可以修改的,而不是静态的常量表。如果数据不能修改,那么采用多进程模式,进程间用共享内存即可;
- 提供非均质的服务; 事件的响应有优先级的差异, 用专门的线程来处理优先级高的事件, 防止优先级反转。
- latency和throughout(吞吐量)同样重要, 不是逻辑简单的IO bound或CPU bound程序(程序有相当的计算量)。
- 利用异步操作。
- 能scale up, 一个好的线程程序能享受增加CPU数目带来的好处。
- 具有可预测的性能, 线程数一般不随负载变化。
- 多线程能有效地划分责任和功能, 让每个线程的逻辑比较简单, 任务单一, 便于编码。
虽然线程数目可能略多于core数目,但是这些线程很多时候都是空闲的,可以依赖OS的进程调度来保证可控的延迟。
线程的分类
一个多线程服务程序中的线程大致可分为3类:
- IO线程,这类线程的主循环是IO muItiplexing,阻塞地等在select/poll/epoll_wait系统调用上。这类线程也处理定时事件。当然它的功能不止IO,有些简单计算也可以放入其中,比如消息的编码或解码;
- 计算线程,这类线程的主循环是blocking queue,阻塞地等在条件变量上。这类线程一般位于thread pool中。这种线程通常不涉及IO,一般要避免任何阻塞操作;
- 第三方库所用的线程,比如logging,又比如database connection。
3.6 多线程服务器适用场合 例释与答疑
1、Linux能同时启动多少个线程?
对于32位 Linux,一个进程的地址空间是4G,其中用户态能访问3G左右,而一个线程的默认栈大小是8MB(使用” ulimit -s”命令查看)。因此一个进程大约最多能同时启动300多个线程,程序的其他部分(数据段、代码段、堆、动态库等等)同样要占用内存地址空间。
64位系统,用户空间和内核空间各为2^47 Byte大小,线程数目大大增加。
2、多线程能提高并发度吗?
如果指的是“并发连接数”,不能。假如单纯采用 thread per connection 的模型,那么并发连接数大约350,这远远低于基于事件的单线程程序所能轻松达到的并发连接数(几千上万,甚至几万)。
所谓“基于事件”,指的是用 IO multiplexing event loop 的编程模型,又称 Reactor 模式。单个的event loop处理1万个并发长连接并不稀罕, 一个multi-loop的多线程程序应该能轻松支持5万并发连接。
3、多线程能提高吞吐量吗?
对于计算密集型服务,不能。但是比起多进程,首次响应延迟更小。
为了在并发请求数很高时也能保持稳定额吞吐量, 我们可以用线程池, 线程池的大小应该满足"阻抗匹配原则"。
但是线程池也不是万能的,如果响应一次请求需要做比较多的计算(比如计算的时间占整个response time的1/5),那么用线程池是合理的,能简化编程。如果在一次请求响应中,主要时间是在等待IO,那么为了进一步提高吞吐量,往往要用其他编程模型,比如Proactor。
4、多线程能降低响应时间么?
设计合理,充分利用多核资源,可以,在突发请求时尤为明显。
5、多线程程序如何让IO和“计算”相互重叠,降低latency ?
基本思路是,把IO操作(通常是写操作)通过BlockingQueue交给别的线程去做,自己不必等待。
比如在多线程服务器程序中,日志模块至关重要。在一次请求响应中,可能要写多条日志消息,而如果用同步的方式写文件(fprintf或fwrite),多半会降低性能,因为:
-
文件操作一般比较慢,服务线程会等在IO上,让CPU闲置,增加响应时间;
-
就算有buffer,还是不灵。多个线程一起写,为了不至于把buffer写错乱,往往要加锁。这会让服务线程互相等待,降低并发度。
解决办法是单独用一个logging线程,负责写磁盘文件,通过一个或多个BlockingQueue对外提供接口。别的线程要写日志的时候,先把消息准备好,然后往queue里一塞就行,基本不用等待。这样服务线程的计算就和logging线程的磁盘IO相互重叠,降低了服务线程的响应时间。
6、 除了Reactor + thread pool 还有什么多线程编程模型?
Proctor,如果一次请求响应中要和别的进程多次打交道,那么Proactor模型能做到更高的并发度,代价是代码变得支离破碎。
Proactor能提高吞吐,但不能降低延迟,所以我没有深入研究。另外,在没有语言直接支持的情况下,Proactor模式让代码非常破碎,在C++中使用Proactor是很痛苦的。因此最好在“线程”很廉价的语言中使用这种方式,这时runtime往往会屏蔽细节,程序用单线程阻塞的方式来处理TCP连接。
7、 多线程和单线程的多进程如何取舍?
S3.5中提到,模式2是一个多线程的进程,模式3a是多个相同的单线程进程。
在其他条件相同的情况下,可以根据工作集(work set)的大小来取含。工作集是指服务程序响应一次请求所访问的内存大小。
如果工作集较大,那么就用多线程,避免CPU cache换入换出,影响性能;否则,就用单线程多进程,享受单线程编程的便利。
第4章 C++多线程系统编程精要
4.1 基本线程原语的选用
POSIX threads的函数有110多个, 真正常用的不过十几个:
- 2个:线程的创建(pthread_create)和等待结束(pthread_join)。封装为muduo::Thread。
- 4个:mutex的创建(pthread_mutex_init)、销毁(pthread_mutex_destroy)、加锁(pthread_mutex_lock)、解锁(pthread_mutex_unlock)。封装为muduo::MutexLock。
- 5个:条件变量的创建(pthread_cond_init)、销毁(pthread_cond_destroy)、等待(pthread_cond_wait)、通知(pthread_cond_signal)、广播(pthread_cond_broadcast)。封装为muduo::Condition。
用这三样东西(thread,mutex,condition)可以完成任何多线程编程任务。当然我们一般也不会直接使用它们(mutex除外),而是使用更高层的封装,例如mutex::ThreadPool和mutex::CountDownLatch等,见第2章。
不建议使用:
- pthread_rwlock, 读写锁应慎用,因为降低了性能。
- sem_*, 避免使用信号量(semaphore), 它的功能与条件变量重合, 但容易用错。
- pthread_{cancel, kill}, 程序中出现了他们, 则通常意味着出现了设计问题。
4.2 C/C++系统库的线程安全性
多线程的出现给系统函数库带来了冲击:
- errno不再是一个全局变量,因为每个线程可能会执行不同的系统库函数。
- 有些“纯函数”不受影响,例如memset/strcpy/snprintf等等。
- 有些影响全局状态或者有副作用的函数可以通过加锁来实现线程安全,例如malloc/free,printf,fread/fseek等等。
- 有些返回或使用静态空间的函数不可能做到线程安全,因此要提供另外的版本,例如asctime_r/ctime_r/gmtime_r,stderror_r,strtok_r等等。
- 传统的fork()并发模型不再适用于多线程程序(S4.9)。
最早的SGI STL自己定制了内存分配器,而现在g++自带的STL已经直接使用 new/delete 来分配内存,std::allocator已经变成了鸡肋。 gcc放弃使用继承自sgi的内存池而使用new/delete是为了降低复杂度和增加可靠性。
不用担心系统调用的线程安全性,因为系统调用对于用户态程序来说是原子的。但是需要注意它的使用对内核状态的改变可能会影响其他线程。
可以说现在glibc库函数大部分都是线程安全的。特别是FILE*系列函数是安全的,glibc甚至提供了非线程安全的版本以应对某些特殊场合的性能需求。但是尽管单个函数是线程安全的,但两个或多个函数放到一起就不再安全了。 编写线程安全程序的一个难点在于线程安全是不可组合的。
线程安全遵循的基本原则:
- 凡是非共享的对象都是彼此独立的,如果一个对象从始至终只被一个线程用到, 那么就是线程安全的。
- 共享对象的read-only操作是安全的, 前提是不能有并发的写操作。
C++标准库中的绝大多数泛型算法是线程安全的, 因为这些都是无状态纯函数。
C++的iostream不是线程安全的,如果有需求可以改用printf,不过等价于用了全局锁,不高效。更好的方法是用高效日志。
4.3 Linux上的线程标识
-
pthread_self函数用于返回当前线程的标致符,类型为pthread_t注意pthread_t:
- 无法打印输出,不知道确切类型,因此日志中无法用它表示当前线程;
- 无法比较大小或计算其hash值;
- 无法定义一个非法的pthread_t值来表示不可能存在的线程id;
- 只在进程中有意义,与操作系统的任务调度之间无法建立有效管理。
-
pthread_equal对比两个线程标志符是否相等 -
Linux系统上建议gettid(2)系统调用的返回值来作为线程的id,原因如下
- 类型是pid_t,是一个小整数, 便于在日志中输出;
- 它直接表示任务调度id,在/proc文件系统中可以轻易找到对应项;
- 其他系统工具也容易定位到具体某一个线程,top(1);
- 任何时刻都是全局唯一的,分配新的pid是递增轮回办法;
- 0是非法的,系统第一个进程init的pid是1。
由于系统调用耗费时间,因此可以用Thread Local变量缓存。实现:
//CurrentThread.h
namespace CurrentThread {
extern __thread int t_cachedTid;
void cacheTid();
inline int tid() {
if (t_cachedTid == 0) {
cacheTid();
}
return t_cachedTid;
}
}
//CurrentThread.cpp
#include "CurrentThread.h"
#include 4.4 线程创建与销毁的守则
线程创建原则:
- 程序库不应该在为提前告知的情况下创建自己的“背景线程”。
- 尽量用相同的方式创建线程。
- 进入main函数之前不应该启动线程。
- 程序中线程的创建最好在初始化阶段全部完成。
线程数目可以从/pro/pid/status拿到。
在main()函数之前不应该启动线程,因为这会影响全局对象的安全构造。我们知道,C++保证在进入main()之前完成全局对象(除函数内静态变量外的所有全局、静态变量,包括类的静态变量)的构造。同时,各个编译单元之间的对象构造顺序是不确定的,我们也有一些办法来影响初始化顺序(比如全局变量改为函数内local静态变量),保证在初始化某个全局对象时使用到的其他全局对象都是构造完成的。但无论如何这些全局对象的构造是依次进行的,都在主线程中完成,无须考虑并发与线程安全。但是,提前启动线程后有可能访问还未初始化的全局对象。
如果有实时性方面的要求,线程数目不应该超过CPU数目,这样可以基本保证新任务总能及时得到执行,因为总有CPU是空闲的。
线程销毁方式:
- 自然死亡。从线程的主函数返回,线程正常退出。
- 非正常死亡。抛出异常或触发segfault信号等非法操作。
- 自杀。 自己调用pthread_exit()退出。
- 他杀。其他线程调用pthread_cancle()。
注意,线程正常退出的方式只有一个,自然死亡,任何从外部强行终止线程的做法和想法都是错误的。大部分库不提供这些函数。因为强行终止线程的话(无论是自杀还是他杀),它没有机会清理资源,也没有机会释放已经持有的锁。
如果确实需要强行终止一个耗时很长的计算任务,而又不想在计算期间周期性地检查某个全局退出标志,那么可以考虑把那一部分代码fork()为新的进程,杀—个进程比杀本进程内的线程要安全得多。
4.4.2 exit在C++中不是线程安全的
exit(3)函数在C++中的作用除了终止线程,还会析构全局对象和以及构造完成的函数静态对象,这有潜在死锁的可能 (比如exit前加锁,析构函数内也需要加锁)。
在编写长期运行的多线程服务程序的时候,可以不必追求安全地退出,而是让进程进入拒绝服务状态,然后就可以直接杀掉了(S9.3)。
4.5 善用__thread关键字
__thread是GCC内置的线程局部存储设施(thread local storage);它的实现非常高效, 比 pthread_key_t 快得多。
int g_var; //全局变量
__thread int t_var;
__thread使用规则:
- 只能用于修饰POD类型(plain old data), 不能修饰class类型,因为无法自动调用构造函数和析构函数。
- __thread可以用于修饰全局变量、函数内的静态变量, 但是不能修饰函数的局部变量或者是class的普通成员变量。
- __thread变量的初始化只能用编译期常量。
- __thread变量是每个线程有一份独立实体, 各个线程的变量值互不干扰。
4.6 多线程与IO
操作文件描述符的系统调用本身是线程安全的,我们不用担心多个线程同时操作文件描述符会造成进程崩溃或内核崩溃。
网络IO
多个线程同时操作同一个socket文件描述符需要考虑的情况如下:
- 如果一个线程正在阻塞地read某个socket,而另一个线程close了此socket。
- 如果一个线程正在阻塞地accept某个listening socket,而另一个线程close了此socket。
- 一个线程正准备read某个socket,而另一个线程close了此socket,第三个线程又恰好open了另一个文件描述符,而fd号码刚好和之前的socket相同。
磁盘IO
首先要避免lseek()/read()的race condition。做到这一点之后,用多个线程read或write同一个文件也不会提速。
不仅如此,多个线程分别read或write同一个磁盘上的多个文件也不见得能提速。因为每块磁盘都有一个操作队列,多个线程的读写请求到了内核是排队执行的。只有在内核缓存了大部分数据的情况下,多线程读这些热数据才可能比单线程快。最好一个文件只由一个进程中的一个线程来读写,这种做法显然是正确的。
多线程程序应该遵循的原则:
- 每个文件描述符只由一个线程操作,从而轻松解决消息收发的顺序性问题,也避免了关闭文件描述符的各种race condition。
- epoll也遵循相同的原则:为了稳妥起见, 我们应该把对同一个epoll fd的操作(添加, 删除, 修改, 等待)都放到同一个线程中执行。
这条规则有两个例外:
- 对于磁盘文件,在必要的时候多个线程可以同时调用 pread(2)/pwrite(2)来读写同一个文件;
- 对于UDP,由于协议本身保证消息的原子性,在适当的条件下(比如消息之间彼此独立)可以多个线程同时读写同一个UDP 文件描述符。
4.7 用RAII包装文件描述符
本节谈一谈在多线程程序中如何管理文件描述符。
POSIX标准要求每次打开文件的时候必须是当前最小可以文件描述符符号,因此这种方式会造成串话。
举例:
- 一个线程正准备read(2)某个socket,而第二个线程几乎同时close(2) 了此socket;第三个线程又恰好open(2)了另一个文件描述符,其号码正好与前面的 socket相同。这时第一个线程可能会读到不属于它的数据,而且还把第三个线程的功能也破坏了 。
- 一个线程从fd=8收到了比较耗时的请求,它开始处理这个请求,并记住要把响应结果发给fd=8。但是在处理过程中,fd=8断开连接,被关闭了(被其他线程close),又有新的连接到来,碰巧使用了相同的fd=8( 只有主动close了fd =8 的socket后 fd=8 才会再次出现 )。当线程完成响应的计算,把结果发给fd=8时,接收方已经物是人非 。
在单线程程序中,或许可以通过某种全局表来避免串话;在多线程程序中,我不认为这种做法会是高效的(通常意味着每次读写都要对全局表加锁)。
解决方法:RAII
用Socket对象包装文件描述符, 所有对此文件描述符的读写操作都通过此对象进行, 在对象的析构函数里关闭文件描述符。只要Socket还活着,就不会有其他的Socket对象有相同的文件描述符。自然需要用到shared_ptr的引用计数来做好多线程中的对象生命期管理。
4.8 RAII 与 fork()
fork()之后,子进程继承了父进程的几乎全部状态,但也有少数例外。
子进程会继承地址空间和文件描述符,因此用于管理动态内存和文件描述符的RAII class都能正常工作。但是子进程不会继承:
- 父进程的内存锁,mlock、mlockall。
- 父进程的文件锁,fcntl。
- 父进程的某些定时器,setitimer、alarm、timer_create等等。
- 其他,见man 2 fork。
通常我们会用RAII手法来管理以上种类的资源(加锁解锁、创建销毁定时器等等),但是在fork()出来的子进程中不一定正常工作,因为资源在fork()时已经被释放了。 比方说用RAII封装timer_create()/timer_delete(),在子进程中析构函数调用timer_delete()可能会出错,因为试图释放一个不存在的资源。
因此,我们在编写服务端程序的时候,“是否允许fork()”是在一开始就应该慎重考虑的问题,在一个没有为fork()做好准备的程序中使用fork(),会遇到难以预料的问题。
4.9 多线程与fork()
多线程和fork()的协作性很差。 fork()一般不能在多线程中调用, 因为Linux的fork()只克隆当前线程, 不克隆其他线程。
这就造成一个危险的局面:其他线程可能正好位于临界区之内,持有了某个锁, 而它突然死亡,再也没有机会去解锁了。如果子进程试图再对同一个mutex加锁,就会立刻死锁。
在fork()之后,子进程就相当于处于signal handler之中,你不能调用线程安全的函数(除非它是可重入的),而只能调用异步信号安全(async-signal-safe)的函数。(所以不能调用malloc/printf等函数)
因此,唯一安全的做法是:在fork()之后立即调用exec()执行另一个程序,彻底隔断子进程与父进程的联系。
4.10 多线程与signal
Linux/Unix的信号与多线程可谓是水火不容。
在多线程程序中,使用signal的第一原则是不要使用signal:
-
不要用signal作为IPC的手段,包括不要用SIGUSR1等信号来触发服务端的行为。如果确实需要,可以用9.5介绍的增加监听端口的方式来实现双向的、可远程访问的进程控制;
-
不要使用基于signal实现的定时函数,包括alarm/ualarm/setitimer/timer_create/sleep/usleep 等等;
-
不主动处理各种异常信号(SIGTERM、SIGINT等等),只用默认语义:结束进程。有一个例外:SIGPIPE,服务器程序通常的做法是忽略此信号,否则如果对方断开连接,而本机继续write的话,会导致程序意外终止。
SIGPIPE信号产生的规则:当一个进程向某个已收到RST的套接字执行写操作时,内核向该进程发送SIGPIPE信号。
-
在没有别的替代方法的情况下(比方说需要处理SIGCHLD信号),把异步信号转换为同步的文件描述符事件:采用signalfd(2)把信号直接转换为文件描述符事件,从而从根本上避免使用signal handler。
Linux2.6新增了三种fd: signalfd 、 timerfd 、 eventfd。
-
signalfd:传统的处理信号的方式是注册信号处理函数;由于信号是异步发生的,要解决数据的并发访问,可重入问题。signalfd可以将信号抽象为一个文件描述符,当有信号发生时可以对其read,这样可以将信号的监听放到select、poll、epoll等监听队列中。
-
timerfd:可以实现定时器的功能,将定时器抽象为文件描述符,当定时器到期时可以对其read,这样也可以放到监听队列的主循环中。
-
eventfd:实现了线程之间事件通知的方式,eventfd的缓冲区大小是sizeof(uint64_t);向其write可以递增这个计数器,read操作可以读取,并进行清零;eventfd也可以放到监听队列中,当计数器不是0时,有可读事件发生,可以进行读取。
三种新的fd都可以进行监听,当有事件触发时,有可读事件发生。
https://blog.csdn.net/gdutliuyun827/article/details/8460417
小结
编写多线程C++程序的原则如下:
- 线程时宝贵的,一个程序可以使用几个或几十个线程,但一台机器不应该同时运行几百个,几千个线程,会增加内核的负担。
- 线程的创建和销毁是有代价的,最好一开始就创建所有线程反复使用,如果必须那么做,最好降到一分钟一次。
- 每个线程都应该有明确的职责,例如IO线程或计算线程。
- 线程之间的交互应该尽量简单,理想情况下只用消息传递,如果必须使用锁,最好避免同一个线程拥有两把锁。
- 考虑清楚一个mutable shared 对象会暴露给哪些线程,每个线程是读还是写,是否并发。
第5章 高效的多线程日志
对于关键进程,日志通常要记录
- 收到的每条内部消息的id(还可以包括关键字段、长度、hash等);
- 收到的每条外部消息的全文;
- 发出的每条消息的全文,每条消息都有全局唯一的id;
- 关键内部状态的变更,等等。
完整的日志消息通常包含日志级别、时间戳、源文件位置、线程id等基本字段,以及程序输出的具体消息内容。
—个日志库大体可分为前端和后端两部分。
- 前端是供应用程序使用的接口,并生成日志消息;
- 后端负责把日志消息写到目的地。
在多线程程序中,每个线程有自己的前端,整个程序共用一个后端。但难点在于将日志数据从多个前端髙效地传输到后端。这是一个典型的多生产者-单消费者问题,对生产者而言,要尽量做到低延迟、低CPU开销、无阻塞;对消费者而言,要做到足够大的吞吐量,并占用较少资源。
5.1 功能需求
常规的通用日志库如log4j/logback通常会提供丰富的功能。但这些功能不一定全都是必需的,其提供的功能有:
- 日志消息有多种级别(level),如TRACE、DEBUG、INFO、 WARN、ERROR、FATAL等。
- 日志消息可能有多个目的地(appender),如文件、socket、 SMTP等。
- 日志消息的格式可配置(layout),例如org.apache.log4j.PatternLayout。
- 可以设置运行时过滤器(filter),控制不同组件的日志消息的 级别和目的地。
对于分布式系统中的服务进程而言,日志的目的地只有一个:本地文件。往网络写日志消息是不靠谱的。
以本地文件为日志的destination,那么日志文件的滚动(rolling)是必需的,这样可以简化日志归档(archive)的实现
rolling的条件通常有两个:
- 文件大小(例如每写满1GB就换下一个文件)
- 时间(例如每 天零点新建一个日志文件,不论前一个文件有没有写满)
一个典型的日志文件的文件名如下:
logfile_test.2012060-144022.hostname.3605.log
文件名由以下几部分组成:
- 第1部分logfile_test是进程的名字。通常是main()函数参数中argv[0] 的basename,这样容易区分究竟是哪个服务程序的日志。必要时还可以把程序版本加进去。
- 第2部分是文件的创建时间(GMT时区)。这样很容易通过文件名 来选择某一时间范围内的日志,例如用通配符
*.20120603-14*表示2012 年6月3日下午2点(GMT)左右的日志文件(s)。 - 第3部分是机器名称。这样即便把日志文件拷贝到别的机器上也能 追溯其来源。
- 第4部分是进程id。如果一个程序一秒之内反复重启,那么每次都会生成不同的日志文件(参考后面的“分布式系统中的进程标识”文章)。
- 第5部分是统一的后缀名.log。同样是为了便于周边配套脚本的编写。
往文件写日志的一个常见问题是,万一程序崩溃,那么最后若干条日志往往就丢失了,因为日志库不能每条消息都flush硬盘,性能开销太大。muduo日志库用两个办法来应对这一点,
- 其一是定期将缓冲区内的日志消息flush到硬盘;
- 其二是每条内存中的日志消息都带有cookie,其值为某个函数的地址,这样通过在core dump文件中查找cookie 就能找到尚未来得及写人磁盘的消息。
以下是muduo日志库的默认消息格式:

日志消息格式有几个要点:
- 尽量每条日志占一行。这样很容易用awk、sed、grep等命令行工具来快速联机分析日志。
- 时间戳精确到微秒。每条消息都通过gettimeofday获得当前时间,这么做不会有什么性能损失。因为在x86-64 Linux上, gettimeofday不是系统调用,不会陷入内核。
- 始终使用GMT时区(Z)。对于跨洲的分布式系统而言,可省去本地时区转换的麻烦(别忘了主要西方国家大多实行夏令时),更易于追查事件的顺序
- 打印线程id。便于分析多线程程序的时序,也可以检测死锁(例如某个繁忙的线程在某一时刻之后不再log任何消息,往往意味着发生了死锁或阻塞(僵死))。
- 打印日志级别。在线查错的时候先看看有无ERROR日志,通常可加速定位问题。
- 打印源文件名和行号。修复bug的时候不至于搞错对象。
5.2 性能需求
编写Linux服务端程序的时候,需要一个高效的日志库。
高效性体现在几方面:
- 每秒写几千上万条日志的时候没有明显的性能损失。
- 能应对一个进程产生大量日志数据的场景,例如1GB/min。
- 不阻塞正常的执行流程。
- 在多线程程序中,不造成争用(contention)。
5.3 多线程异步日志
多线程程序对日志库提出了新的需求:线程安全。
解决思路:
- 用一个全局锁保护IO,或者每个线程单独写一个日志文件。性能堪忧,前者造成所有线程抢占一个锁,后者会让业务线程阻塞在写磁盘操作上。
- 异步日志:每个进程只写一个日志文件,用一个背景线程负责收集日志消息,并写入日志文件,其他业务线程只需往这个日志线程中发送日志消息。
实现
我们需要一个“队列”来将日志前端的数据传送到后端(日志线程),但这个“队列”不必是现成的BlockingQueue,因为不用每次产生一条日志消息都通知(notify())接收方 。
muduo日志库采用的是双缓冲(double buffering)技术 :
- 准备两块buffer:A和B,前端负责往buffer A填数据(日志消息),后端负责将buffer B的数据写入文件;
- 当buffer A写满之后,交换A和B。让前端则往buffer B填入新的日志消息,后端将buffer A的数据写入文件。如此往复…;
用两个buffer的好处是:
- 在新建日志消息的时候不必等待磁盘文件操作,也避免每条新日志消息都触发(唤醒)后端日志线程。
- 换言之,前端不是将一条条日志消息分别传送给后端,而是将多条日志消息拼成一个大的buffer传送给后端,相当于批处理,减少了线程唤醒的频度,降低开销。
- 另外,为了及时将日志消息写入文件,即便buffer A未满,日志库也会每3秒执行一次上述交换写入操作。
muduo异步日志的性能开销大约是:前端每写一条日志消息耗时1.0μs ~1.6μs
关键代码
实际实现采用了四个缓冲区,这样可以进一步减少或避免日志前端的等待。
数据结构如下
typedef muduo::detail::FixedBuffer<muduo::detail::kLargeBuffer> Buffer;
typedef std::vector<std::unique_ptr<Buffer>> BufferVector;
typedef BufferVector::value_type BufferPtr;
muduo::MutexLock mutex_;
muduo::Condition cond_;
BufferPtr currentBuffer_; //当前缓冲
BufferPtr nextBuffer_; //预备缓冲
BufferVector buffers_; //待写入文件的已填满的缓冲
- Buffer类型是FixedBuffer class template的一份具体实现 (instantiation),其大小为4MB,可以存至少1000条日志消息
- BufferVector::value_type的类型为C++11中的std::unique_ptr,具备移动语义(move semantics),而且能自动管理对象生命期
- mutex_:用于保护后面的四个数据成员
- buffers_:存放的是供后端写入的buffer
发送方(前端)代码
void AsyncLogging::append(const char* logline, int len)
{
muduo::MutexLockGuard lock(mutex_);
//most common case: buffer is not full, copy data here
if (currentBuffer_->avail() > len) //1
{
currentBuffer_->append(logline, len); //2
}
//buffer is full, push it, and find next spare buffer
else
{
buffers_.push_back(std::move(currentBuffer_)); //3
if (nextBuffer_) //is there is one already, use it //4
{
currentBuffer_ = std::move(nextBuffer_); //移动,而非复制
}
else //allocate a new one //5
{
currentBuffer_.reset(new Buffer); // Rarely happens
}
currentBuffer_->append(logline, len); //6
cond_.notify(); //7
}
}
- 前端在生成一条日志消息的时候会调用AsyncLogging::append()。
- 函数解释:
- 如果当前缓冲currentBuffer_剩余的空间足够大 (代码段1处),则会直接把日志消息拷贝(追加)到当前缓冲中(代码段2处), 这是最常见的情况。这里拷贝一条日志消息并不会带来多大开销。前后端代码的其余部分都没有拷贝,而是简单的指针交换。
- 否则,说明当前缓冲已经写满,就把它送入/移入buffers_(代码段3处),并试图把预备好的另一块缓冲nextBuffer_移用 (move)为当前缓冲(代码段4处),然后追加日志消息并通知/唤醒后端开始写入日志数据(代码段6、7处。
- 以上两种情况在临界区之内都没有耗时的操作,运行时间为常数。
- 如果前端写入速度太快,一下子把两块缓冲都用完了,那么只好分配一块新的buffer,作为当前缓冲(代码段5处),这是极少发生的情况。
接收方(后端)代码
void AsyncLogging::threadFunc()
{
//...
BufferPtr newBuffer1(new Buffer); //8
BufferPtr newBuffer2(new Buffer); //9
//...
BufferVector buffersToWrite;
buffersToWrite.reserve(16);
while (running_)
{
//...
//swap out what need to be written, keep CS short
{
muduo::MutexLockGuard lock(mutex_);
if (buffers_.empty()) // unusual usage!
{
cond_.waitForSeconds(flushInterval_); //10
}
buffers_.push_back(std::move(currentBuffer_));//移动,而非复制 11
currentBuffer_ = std::move(newBuffer1); //移动,而非复制 12
buffersToWrite.swap(buffers_); //内部指针交换,而非复制 13
if (!nextBuffer_) //14
{
nextBuffer_ = std::move(newBuffer2); //移动,而非复制
}
}
//...
//output buffersToWrite to file 15
//re-fill newBuffer1 and newBuffer2 16
}
//flush output...
}
函数解释:
-
首先准备好两块空闲的buffer,以备在临界区内交换(代码段8、9处)。
-
在临界区内,等待条件触发(代码段10处)
-
这里的条件有两个:其一是超时,其二是前端写满了一个或多个buffer。
-
注意这里是非常规的condition variable用法,它没有使用while循环,而且等待时间有 上限。
-
-
当“条件”满足时,先将当前缓冲(currentBuffer_)移入 buffers_(代码段11处),并立刻将空闲的newBuffer1移为当前缓冲(代码段12处)。注意这整段代码位于临界区之内,因此不会有任何race condition。
-
接下来将buffers_与buffersToWrite交换(代码段13处),后面的代码可以在临界区之外安全地访问buffersToWrite,将其中的日志数据写入文件(代码段15处)。
-
临界区里最后干的一件事情是用newBuffer2替换nextBuffer_(代码段14处),这样前端始终有一个预备buffer可供调配。nextBuffer_可以减少前端临界区分配内存的概率,缩短前端临界区长度。
-
注意到后端临界区内也没有耗时的操作,运行时间为常数。
-
代码段16处会将buffersToWrite内的buffer重新填充newBuffer1和 newBuffer2,这样下一次执行的时候还有两个空闲buffer可用于替换前端的当前缓冲和预备缓冲。最后,这四个缓冲在程序启动的时候会全部填充为0,这样可以避免程序热身时page fault引发性能不稳定。
转自:https://blog.csdn.net/qq_41453285/article/details/105092114
如果日志消息堆积怎么办?
万一前端陷入死循环,拼命发送日志消息,超过后端的处理(输出)能力,会导致什么后果?
- 对于同步日志来说:这不是问题,因为阻塞IO自然就限制了前端的写入速度,起到了节流阀(throttling)的作用。
- 但是对于异步日志来说:这就是典型的生产速度高于消费速度问题,会造成数据在内存中堆积,严重时引发性能问题(可用内存不足) 或程序崩溃(分配内存失败)。
muduo日志库处理日志堆积的方法很简单:直接丢掉多余的日志buffer,以腾出内存,这样可以防止日志库本身引起程序故障。
5.4 其他方案
muduo现在的异步日志实现用了一个全局锁。尽管临界区很小,但是如果线程数目较多,锁争用也可能影响性能。一种解决办法是像Java的 ConcurrentHashMap那样用多个桶(bucket),前端写日志的时候再按线程id哈希到不同的bucket中,以减少contention。
第6章 muduo网络库简介(及并发网络服务程序设计方案)
muduo网络库介绍
- muduo 是基于 Reactor 模式的网络库,其核心是个事件循环 EventLoop,用于响应计时器和 IO 事件。
- muduo 采用基于对象(object- based)而非面向对象( objectoriented)的设计风格,其事件回调接口多以 function+ bind 表达,用户在使用 muduo 的时候不需要继承其中的 class。
- muduo 的线程模型:one loop per thread + thread pool 模型。
- muduo中的poller是PollPoller和EPollPoller的基类,采用电平触发。
muduo使用
muduo是静态链接的C++程序库(因为在分布式系统中正确安全地发布动态库的成本很高)。编译带有muduo代码的程序,g++规则与命令如下:
- 头文件:使用-I选项指出头文件路径
- 库文件:使用-L选项指出库文件路径
- 链接相应的静态库文件:-lmuduo_net、-lmuduo_base
g++ -o muduo_test muduo_test.c -I头文件路径 -L库文件路径 -lmuduo_net -lmuduo_base
公开接口
- 这里简单介绍各个class的作用,详细的介绍参见以后的文章。
- 公开接口有:
- Buffer仿Netty ChannelBuffer的buffer class,数据的读写通过buffer 进行。用户代码不需要调用read()/write(),只需要处理收到的数据和 准备好要发送的数据(详情参阅“muduo Buffer类的设计与使用”)。
- InetAddress封装IPv4地址(end point),注意,它不能解析域名, 只认IP地址。因为直接用gethostbyname()解析域名会阻塞IO线程。
- EventLoop事件循环(反应器Reactor),每个线程只能有一个 EventLoop实体,它负责IO和定时器事件的分派。它用eventfd()来异步唤醒,这有别于传统的用一对pipe()的办法。它用TimerQueue作为计时器管理,用Poller作为IO multiplexing。
- EventLoopThread启动一个线程,在其中运行EventLoop::loop()。
- TcpConnection整个网络库的核心,封装一次TCP连接,注意它不能发起连接。
- TcpClient用于编写网络客户端,能发起连接,并且有重试功能。
- TcpServer用于编写网络服务器,接受客户的连接。
- 在这些类中:
- TcpConnection的生命期依靠shared_ptr管理(即用户和库共同控制)。Buffer的生命期由TcpConnection控制。其余类的生命期由用户控制。
- Buffer和InetAddress具有值语义,可以拷贝;其他class 都是对象语义,不可以拷贝。
内部实现
- Channel是selectable IO channel,负责注册与响应IO事件,注意它 不拥有file descriptor。它是Acceptor、Connector、EventLoop、 TimerQueue、TcpConnection的成员,生命期由后者控制。
- Socket是一个RAIIhandle,封装一个filedescriptor,并在析构时关闭 fd。它是Acceptor、TcpConnection的成员,生命期由后者控制。 EventLoop、TimerQueue也拥有fd,但是不封装为Socket class。
- SocketsOps封装各种Sockets系统调用。
- Poller是PollPoller和EPollPoller的基类,采用“电平触发”的语意。 它是EventLoop的成员,生命期由后者控制。
- PollPoller和EPollPoller封装poll()和epoll()两种IO multiplexing后 端。poll的存在价值是便于调试,因为poll(2)调用是上下文无关的,用 strace(1)很容易知道库的行为是否正确。
- Connector用于发起TCP连接,它是TcpClient的成员,生命期由后者控制。
- Acceptor用于接受TCP连接,它是TcpServer的成员,生命期由后者控制。
- TimerQueue用timerfd实现定时,这有别于传统的设置 poll/epoll_wait的等待时长的办法。TimerQueue用std::map来管理Timer, 常用操作的复杂度是O(logN),N为定时器数目。它是EventLoop的成 员,生命期由后者控制。
- EventLoopThreadPool用于创建IO线程池,用于把TcpConnection分派到某个EventLoop线程上。它是TcpServer的成员,生命期由后者控制。
6.4 使用教程
6.4.1 TCP网络编程本质论
基于事件的非阻塞网络编程是编写高性能并发网络服务程序的主流模式。
TCP网络编程最本质的是处理三个半事件:
- 1.连接的建立,包括服务端接受(accept)新连接和客户端成功发起(connect)连接。TCP连接一旦建立,客户端和服务端是平等的,可以各自收发数据。
- 2.连接的断开,包括主动断开(close、shutdown)和被动断开 (read()返回0)。
- 3.消息到达,文件描述符可读。这是最为重要的一个事件,对它的处理方式决定了网络编程的风格(阻塞还是非阻塞,如何处理分包, 应用层的缓冲如何设计,等等)。
- 3.5消息发送完毕,这算半个。对于低流量的服务,可以不必关心这个事件;另外,这里的“发送完毕”是指将数据写入操作系统的缓冲区,将由TCP协议栈负责数据的发送与重传,不代表对方已经收到数据。
细节问题:
在非阻塞网络编程中,为什么要使用应用层发送缓冲区?假设应用程序需要发送40kB数据,但是操作系统的TCP发送缓冲区只有25kB剩余空间,那么剩下的15kB数据怎么办?如果等待OS缓冲区可用,会阻塞当前线程,因为不知道对方什么时候收到并读取数据。因此网络库应该把这15kB数据缓存起来,放到这个TCP链接的应用层发送缓冲区中,等socket变得可写的时候立刻发送数据,这样“发送”操作不会阻塞。如果应用程序随后又要发送50kB数据,而此时发送缓冲区中尚有未发送的数据(若干kB),那么网络库应该将这50kB数据追加到发送缓冲区的末尾,而不能立刻尝试write(),因为这样有可能打乱数据的顺序。
在非阻塞网络编程中,为什么要使用应用层接收缓冲区?
- 假如一次读到的数据不够一个完整的数据包,那么这些已经读到的数据是不是应该先暂存在某个地方,等剩余的数据收到之后再一并处理?见lighttpd关于\r\n\r\n分包的bug。
- 假如数据是一个字节一个字节地到达,间隔10ms,每个字节触发一次文件描述符可读(readable)事件,程序是否还能正常工作?lighttpd在这个问题上出过安全漏洞。
在非阻塞网络编程中,如何设计并使用缓冲区?
- 一方面我们希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区。
- 另一方面,我们希望减少内存占用。如果有10000个并发连接, 每个连接一建立就分配各50kB的读写缓冲区(s)的话,将占用1GB内存, 而大多数时候这些缓冲区的使用率很低。
- muduo用readv()结合栈上空间巧妙地解决了这个问题。
6.4.2 echo服务的实现
muduo的使用非常简单,不需要从指定的类派生,也不用覆写虚函数,只需要注册几个回调函数去处理前面提到的三个半事件就行了。
echo回显服务代码如下
-
定义EchoServer class。
// echo.h #ifndef MUDUO_EXAMPLES_SIMPLE_ECHO_ECHO_H #define MUDUO_EXAMPLES_SIMPLE_ECHO_ECHO_H #includeclass EchoServer { public: // 构造函数 EchoServer(muduo::net::EventLoop* loop, const muduo::net::InetAddress& listenAddr); // 启动服务 void start(); private: // 响应客户端连接 void onConnection(const muduo::net::TcpConnectionPtr& conn); // 响应客户端消息 void onMessage(const muduo::net::TcpConnectionPtr& conn, muduo::net::Buffer* buf, muduo::Timestamp time); // TcpServer对象 muduo::net::TcpServer server_; }; #endif // MUDUO_EXAMPLES_SIMPLE_ECHO_ECHO_H -
实现代码如下:
- onConnection()、onMessage():这两个函数体现了“基于事件编程”的典型做法,即程序主体是被动等待事件发生,事件发生之后网络库会调用(回调)事先注册的时间处理函数(event handler)
// echo.cc #include "echo.h" #include "muduo/base/Logging.h" using std::placeholders::_1; using std::placeholders::_2; using std::placeholders::_3; // using namespace muduo; // using namespace muduo::net; // 构造TcpServer对象,为TcpServer对象注册回调函数 EchoServer::EchoServer(muduo::net::EventLoop *loop, const muduo::net::InetAddress &listenAddr) : server_(loop, listenAddr, "EchoServer") { server_.setConnectionCallback( std::bind(&EchoServer::onConnection, this, _1)); server_.setMessageCallback( std::bind(&EchoServer::onMessage, this, _1, _2, _3)); } // 调用TcpServer对象的start()函数,启动服务 void EchoServer::start() { server_.start(); } // 接收客户端连接,并打印相关信息 void EchoServer::onConnection(const muduo::net::TcpConnectionPtr &conn) { // perrAddress(): 返回对方地址(以InetAddress对象表示IP和port) // localAddress(): 返回本地地址(以InetAddress对象表示IP和port) // connected():返回bool值, 表明目前连接是建立还是断开 LOG_INFO << "EchoServer - " << conn->peerAddress().toIpPort() << "->" << conn->localAddress().toIpPort() << " is " << (conn->connected() ? "UP" : "DOWN"); } // 接收客户端数据,并将数据原封不动的返回给客户端 // conn参数: 收到数据的那个TCP连接 // buf参数: 是已经收到的数据,buf的数据会累积,直到用户从中取走(retrieve) // 数据。注意buf是指针,表明用户代码可以修改(消费)buffer time参数: // 是收到数据的确切时间,即epoll_wait()返回的时间,注意这个时间通常比read()发生的时间略早,可以用于正确测量程序的消息处理延迟。另外,Timestamp对象采用pass-by-value,而不是pass-by-(const)reference, // 这是有意的,因为在x86-64上可以直接通过寄存器传参 void EchoServer::onMessage(const muduo::net::TcpConnectionPtr &conn, muduo::net::Buffer *buf, muduo::Timestamp time) { // 将接收到的数据封装为一个消息 muduo::string msg(buf->retrieveAllAsString()); LOG_INFO << conn->name() << " echo " << msg.size() << " bytes, " << "data received at " << time.toString(); // 将消息再回送回去, // 不必担心send(msg)是否完整地发送了数据,muduo网络库会帮我们管理发送缓冲区 conn->send(msg); } -
在main()函数用EventLoop让整个程序跑起来。
// main.cc #include "examples/simple/echo/echo.h" #include "muduo/base/Logging.h" #include "muduo/net/EventLoop.h" #include// using namespace muduo; // using namespace muduo::net; int main() { // 1.打印进程ID LOG_INFO << "pid = " << getpid(); // 2.初始化EventLoop、InetAddress对象, muduo::net::EventLoop loop; muduo::net::InetAddress listenAddr(2007); // 3.创建EchoServer, 启动服务 EchoServer server(&loop, listenAddr); server.start(); // 4.事件循环 loop.loop(); }
6.4.3 finger服务的实现
finger服务:显示有关运行 Finger 服务 的指定远程计算机(通常是运行 UNIX 的计算机)上用户的信息。
// finger07.cc
#include "muduo/net/EventLoop.h"
#include "muduo/net/TcpServer.h"
#include 转自:https://dongshao.blog.csdn.net/article/details/107015436
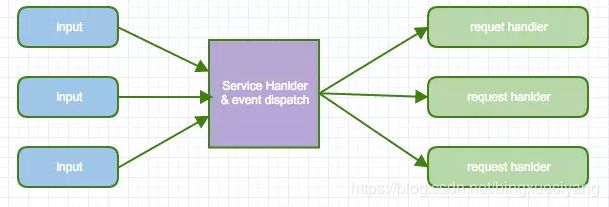
6.6.2 常见的并发服务器设计方案

其中“互通”指的是:多个客户连接之间是否能方便地交换数据(chat也是附录A中举的三大TCP网络编程案例之一)。
“顺序性”指的是:如果客户连接顺序发送多个请求,那么计算得到的多个响应是否按相同的顺序发还给客户(这里指的是在自然条件下,不含刻意同步)。
方案1 accept+fork
调用fork派生一个子进程来处理每个客户请求,每个进程一个客户。为每个客户现场fork一个子进程比较耗费CPU时间。
这种方案适合并发连接数不大的情况,至今仍有一些网络服务应用程序使用这种方式实现,比如PostgreSQL和Perforce的服务端。这种方案适合“计算响应的工作量远大于fork的开销”情况,如数据库服务器。这种方案适合长连接,不太适合短连接,因为fork开销大于求解Sudoku的用时。
from SocketServer import BaseRequestHandler, TCPServer
from SocketServer import ForkingTCPServer, ThreadingTCPServer
class EchoHandler(BaseRequestHandler):
def handle(self):
print "got connection from", self.client_address
while True:
data = self.request.recv(4096)
if data:
sent = self.request.send(data) # sendall?
else:
print "disconnect", self.client_address
self.request.close()
break
if __name__ == "__main__":
listen_address = ("0.0.0.0", 2007)
server = ForkingTCPServer(listen_address, EchoHandler)
server.serve_forever()
方案2 accept+thread
这种方案的初始化开销比方案1要小很多,但与求解Sudoku的用时差不多,仍然不适合短连接服务。这种方案的伸缩性受到线程数的限制,一两百个还行,几千个的话对操作系统的scheduler恐怕是个不小的负担。将方案1代码中的ForkingTCPServer改为ThreadingTCPServer即可。
方案3 prefork 是对方案1的优化。
方案4 prethreaded 是对方案2的优化。
方案3和方案 4这两个方案都是Apache httpd长期使用的方案。
以上几种方案都是阻塞式网络编程,无法直接同时处理多个输入输出,需要使用多个线程/进程,或者IO复用。
“IO复用”其实复用的不是IO连接,而是复用线程。使用select/poll几乎肯定要配合non-blocking IO,而使用non-blocking IO肯定要使用应用层buffer。这就不是一件轻松的事儿了,如果每个程序都去搞一套自己的IO multiplexing机制(本质是 event-driven事件驱动),这是一种很大的浪费。感谢Doug Schmidt为我们总结出了Reactor模式,让event-driven网络编程有章可循。继而出现了一些通用的Reactor 框架/库,比如libevent、muduo、Netty、twisted、POE等等。有了这些库,基本不用去编写阻塞式的网络程序了(特殊情况除外,比如proxy流量限制)。
Reactor的意义就在于将消息(IO事件)分发到用户提供的处理函数,并保持网络部分的通用代码不变,独立于用户的业务逻辑。
方案5 poll(reactor)
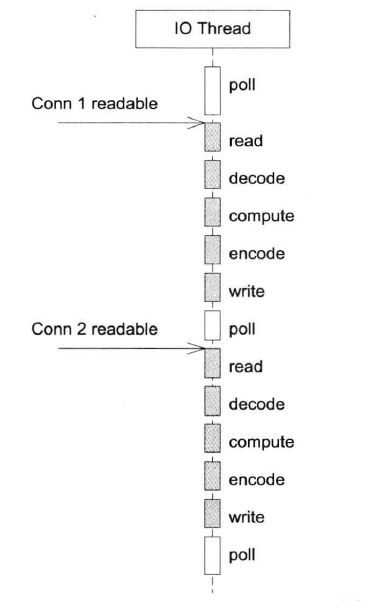
缺点是适合IO密集的应用,不太适合CPU密集的应用,因为较难发挥多核的威力;事件的优先级得不到保证。
在使用非阻塞IO + 事件驱动方式编程的时候,一定要注意避免在事件回调中执行耗时的操作,包括阻塞IO等,否则会影响程序的响应。
方案6 reactor + thread-per-task
这是一种过渡方案。这种方案中,收到Sudoku请求之后,不在Reactor线程计算,而是创建一个新线程去计算,以充分利用多核CPU。这是非常初级的多线程应用,因为它为每个请求(而不是每个连接)创建了一个新线程。这个开销可以用线程池来避免,即方案8。这个方案还有一个特点是out-of-order,即同时创建多个线程去计算同一个连接上收到的多个请求,那么算出结果的次序是不确定的。
方案7 reactor + worker thread
为了让返回结果的顺序确定,可以为每个连接创建一个计算线程,每个连接上的请求固定发给同一个线程去算,先到先得。这也是一个过渡方案,因为并发连接数受限于线程数目,这个方案或许还不如直接使用阻塞IO的 thread-per-connection 的方案2。
方案8 reactor + thread pool
为了弥补方案6中为每个请求创建线程的缺陷,使用固定大小线程池,程序结构如下图所示:
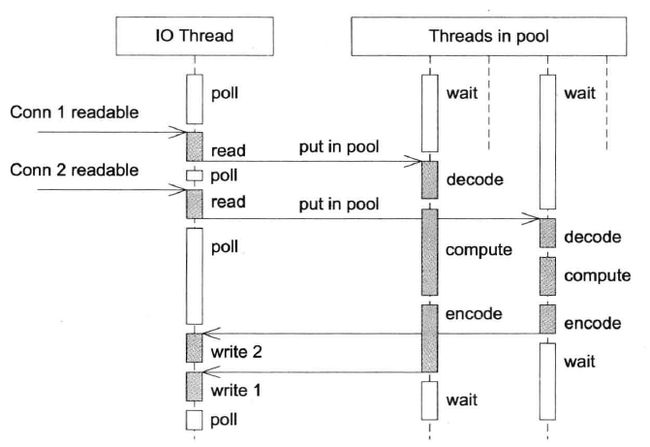
全部的IO工作都在一个Reactor线程完成,而计算任务交给thread pool。如果计算任务彼此独立,而且IO的压力不大,那么这种方案是非常适用的。Sudoku Solver 正好符合这种场景。
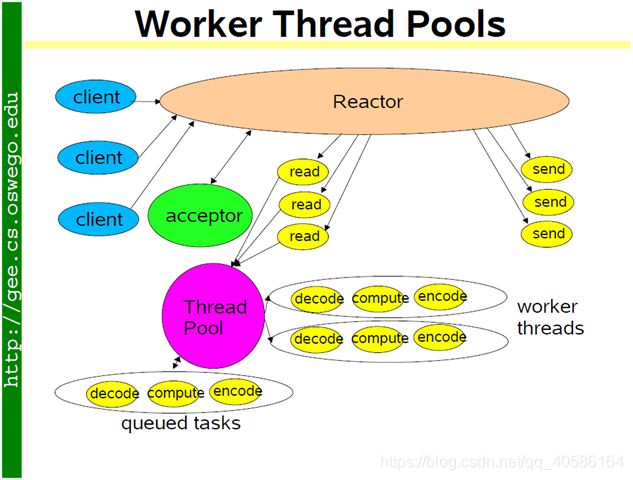
线程池的另一个作用是执行阻塞操作,比如有的数据库的客户端只提供同步访问,那么可以把数据库查询放到线程池中,可以避免阻塞IO线程,不会影响其他客户连接;也可以用线程池来调用一些阻塞的 IO函数,例如fsync(2)/fdatasync(2),这两个函数没有非阻塞的版本。
如果IO的压力比较大,一个Reactor处理不过来,可以试试方案9,它采用多个 Reactor来分担负载。
方案9 reactors in threads
这也是muduo内置的多线程方案,也是 Netty 内置的多线程方案 。
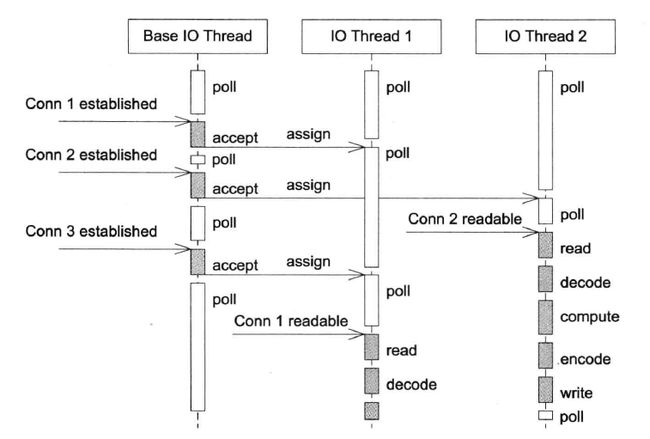
这种方案的特点是one loop per thread,有一个main Reactor负责accept(2)连接,然后把连接挂在某个sub Reactor中(muduo采用round-robin 轮询调度 的方式来选择sub Reactor),这样该连接的所有操作都在那个sub Reactor所处的线程中完成。多个连接可能被分派到多个线程中,以充分利用CPU。
muduo采用的是固定大小的Reactor pool,池子的大小通常根据CPU数目确定,也就是说线程数是固定的,这样程序的总体处理能力不会随连接数增加而下降。另外,由于一个连接完全由一个线程管理,那么请求的顺序性有保证,突发请求也不会占满全部8个核(如果需要优化突发请求,可以考虑方案11)。这种方案把IO分派给多个线程,防止出现一个Reactor的处理能力饱和。
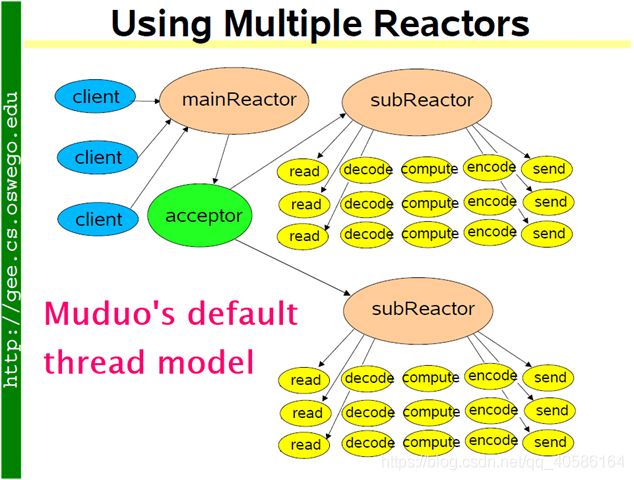
与方案8的线程池相比,方案9减少了进出thread pool的两次上下文切换,在把多个连接分散到多个Reactor线程之后,小规模计算可以在当前IO线程完成并发回结果,从而降低响应的延迟。
方案10 reactors in processes
这是Nginx的内置方案。如果连接之间无交互,这种方案也是很好的选择。工作进程之间相互独立,可以热升级。
方案11 reactors + thread pool
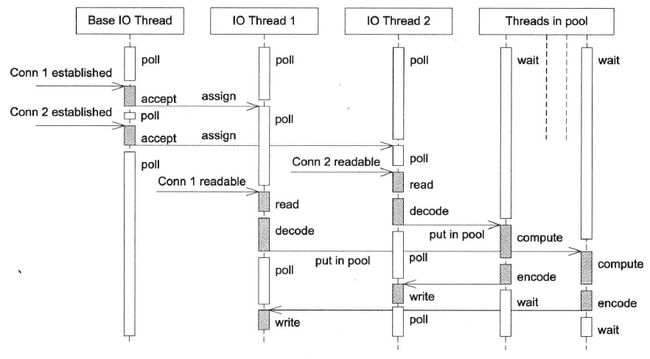
该方案把方案8和方案9混合,既使用多个Reactor来处理IO,又使用线程池来处理计算。这种方案适合既有突发IO(利用多线程处理多个连接上的IO),又有突发计算的应用(利用线程池把一个连接上的计算任务分配给多个线程去做),见下图 。
如何选择?
程序到底是使用一个event loop还是使用多个event loops?ZeroMQ的手册给出的建议是,按照每千兆比特每秒的吞吐量配一个event loop的比例来设置 eventloop 的数目。依据这条经验规则,在编写运行于千兆以太网上的网络程序时,用一个event loop就足以应付网络IO。
- 如果程序本身没有多少计算量,而主要瓶颈在网络带宽,那么可以按这条规则来办,只用一个eventloop。
- 另一方面,如果程序的IO带宽较小,计算量较大,而且对延迟不敏感,那么可以把计算放到thread pool中,也可以只用一个event loop。
另外,以上假定 TCP连接是同质的,没有优先级之分。在muduo中,属于同一个event loop的连接之间没有事件优先级的差别。如果TCP连接有优先级之分,那么单个event loop可能不适合,正确的做法是把高优先级的连接用单独的event loop来处理。
结语
归纳一下,实用的方案有5种,muduo直接支持后4种:

表6-2中的N表示并发连接数目,C1和C2是与连接数无关、与CPU数目有关的常数。
第7章 muduo编程示例
7.1 五个简单TCP示例
-
discard:丢弃所有收到的数据,简单的长连接TCP应用层协议。
void DiscardServer::onMessage(const TcpConnectionPtr& conn, Buffer* buf, Timestamp time) { string msg(buf->retrieveAllAsString()); LOG_INFO << conn->name() << " discards " << msg.size() << " bytes received at " << time.toString(); } -
daytime:短连接协议,在发送完当前时间后,由服务器主动断开连接。
void DaytimeServer::onConnection(const TcpConnectionPtr& conn) { LOG_INFO << "DaytimeServer - " << conn->peerAddress().toIpPort() << " -> " << conn->localAddress().toIpPort() << " is " << (conn->connected() ? "UP" : "DOWN"); if (conn->connected()) { conn->send(Timestamp::now().toFormattedString() + "\n"); conn->shutdown();//主动断开连接 } } -
time : 与daytime极其相似,只不过它返回的不是日期时间字符串,而是一个32bit的整数。
void TimeServer::onConnection(const muduo::net::TcpConnectionPtr& conn) { LOG_INFO << "TimeServer - " << conn->peerAddress().toIpPort() << " -> " << conn->localAddress().toIpPort() << " is " << (conn->connected() ? "UP" : "DOWN"); if (conn->connected()) { time_t now = ::time(NULL); int32_t be32 = sockets::hostToNetwork32(static_cast<int32_t>(now)); conn->send(&be32, sizeof be32); conn->shutdown(); } }time客户端:time服务端发送的是二进制数据,不易读取,因此客户端来解析。
void onMessage(const TcpConnectionPtr& conn, Buffer* buf, Timestamp receiveTime) { if (buf->readableBytes() >= sizeof(int32_t)) { const void* data = buf->peek(); int32_t be32 = *static_cast<const int32_t*>(data); buf->retrieve(sizeof(int32_t)); time_t time = sockets::networkToHost32(be32); Timestamp ts(time * Timestamp::kMicroSecondsPerSecond); LOG_INFO << "Server time = " << time << ", " << ts.toFormattedString(); } else { LOG_INFO << conn->name() << " no enough data " << buf->readableBytes() << " at " << receiveTime.toFormattedString(); } } }; -
echo:前面的都是一个单向接收和发送数据,这是第一个双向发送的协议,即将服务端发送的数据原封不动的发送回去。
void EchoServer::onMessage(const muduo::net::TcpConnectionPtr& conn, muduo::net::Buffer* buf, muduo::Timestamp time) { muduo::string msg(buf->retrieveAllAsString()); LOG_INFO << conn->name() << " echo " << msg.size() << " bytes, " << "data received at " << time.toString(); conn->send(msg); } -
chargen: 只发送数据,不接受数据,且发送数据的速度不能快过客户端接收的速度。
void ChargenServer::onConnection(const TcpConnectionPtr& conn) { LOG_INFO << "ChargenServer - " << conn->peerAddress().toIpPort() << " -> " << conn->localAddress().toIpPort() << " is " << (conn->connected() ? "UP" : "DOWN"); if (conn->connected()) { conn->setTcpNoDelay(true); conn->send(message_); } } void ChargenServer::onMessage(const TcpConnectionPtr& conn, Buffer* buf, Timestamp time) { string msg(buf->retrieveAllAsString()); LOG_INFO << conn->name() << " discards " << msg.size() << " bytes received at " << time.toString(); }
五合一
前面的五个程序都用到了Eventloop。其实是一个Reactor,用于注册和分发IO事件。五个服务端可以用同一个EventLoop跑起来。
int main()
{
LOG_INFO << "pid = " << getpid();
EventLoop loop; // one loop shared by multiple servers
ChargenServer chargenServer(&loop, InetAddress(2019));
chargenServer.start();
DaytimeServer daytimeServer(&loop, InetAddress(2013));
daytimeServer.start();
DiscardServer discardServer(&loop, InetAddress(2009));
discardServer.start();
EchoServer echoServer(&loop, InetAddress(2007));
echoServer.start();
TimeServer timeServer(&loop, InetAddress(2037));
timeServer.start();
loop.loop();
}
这就是Reactor模式复用线程的能力,让一个单线程程序同时具备多个网络服务功能 。
7.2 文件传输
send(const StringPiece&message)这个重载可以发送std::string和const char*,其中StringPiece是Google发明的专门用于传递字符串参数的class,这样程序里就不必为const char*和const std::string&提供两份重载了。其成员仅包含一个const char*以及表示大小的int,所以StringPiece只能用于读取,但所占内存很小。C++17引入的string_view实现了该功能! const char*可以构造string_view,且string可以隐式转换成string_view。
一次读入全部文件的话太浪费内存,利用onWriteComplete()回调函数可以实现分段传输,做到不必一次全部读入内存。
为什么TcpConnection::shutdown()没有直接关闭TCP连接?
- muduo TcpConnection没有提供close(),而只提供shutdown()半关闭,这么做是为了收发数据的完整性。
- TCP是个全双工协议,同一个文件描述符既可读也可写,shutdownWrite()关闭了“写”方向上连接,保留了读方向上的,这成为TCP的半关闭状态,如果直接close, 那么socket_fd就不能读了,导致还在路上的数据被漏收。
- 换句话说,muduo在TCP这一层面解决了“当你打算关闭网络连接的时候,如何得知对方是否发了一些数据而你还没有收到?"这一问题。当然,这个问题也可以在上面的协议层解决,双方商量好不再互发数据,就可以直接断开连接。】
- muduo把“主动关闭连接”这件事情分成两步来做,如果要主动关闭连接,它会先关本地“写”端,等对方关闭之后,再关本地“读”端。
- 有安全漏洞:如果对方故意不关闭连接,则一直消耗资源。
- 析构时才真正close socket。
7.3 Boost.Asio 的聊天服务器
在 TCP 这种字节流协议上做应用层分包是网络编程的基本需求。分包指的是在发送一个消息或一帧数据时,通过一定的处理,让接收方能从字节流中识别并还原出一个个消息。“粘包问题”是个伪问题。
对于短连接的 TCP 服务,分包不是问题,只要发送方主动关闭连接,就表示一条消息发送完毕,接收方 read 返回 0,从而知道消息的结尾。
对于长连接的 TCP 服务,分包有四种方法:
- 消息长度固定;
- 使用特殊的字符或字符串作为消息的边界,例如 HTTP 协议的 headers 以 “/r/n” 为字段的分隔符;
- 在每条消息的头部加一个长度字段,这是最常见的做法;
- 利用消息本身的格式来分包,例如 XML 格式的消息中
...
本节实现的聊天服务非常简单:客户端接受键盘输入,以回车为界,把消息发送给服务端;服务端接收到消息之后,依次发送给每个连接到它的客户端,包括发送此消息的客户端。
客户端和服务端交互的“消息”本身是一个字符串,每条消息的有一个 4 字节的头部,以网络序存放字符串的长度。消息之间没有间隙,字符串也不一定以 ‘/0’ 结尾。
因涉及到消息的编码和解码处理,每当 socket 可读,Muduo 的 TcpConnection 会读取数据并存入 Input Buffer,然后回调用户的函数。这个时候就需要一个间接层,让用户代码只关心“消息到达”而不是“数据到达”。下面的LengthHeaderCodec就是所谓的间接层:
class LengthHeaderCodec : muduo::noncopyable
{
public:
typedef std::function StringMessageCallback;
explicit LengthHeaderCodec(const StringMessageCallback& cb)
: messageCallback_(cb)
{
}
// 分包代码
void onMessage(const muduo::net::TcpConnectionPtr& conn,
muduo::net::Buffer* buf,
muduo::Timestamp receiveTime)
{
while (buf->readableBytes() >= kHeaderLen) // kHeaderLen == 4
{
// FIXME: use Buffer::peekInt32()
const void* data = buf->peek();
int32_t be32 = *static_cast(data); // SIGBUS
const int32_t len = muduo::net::sockets::networkToHost32(be32);
if (len > 65536 || len < 0)
{
LOG_ERROR << "Invalid length " << len;
conn->shutdown(); // FIXME: disable reading
break;
}
else if (buf->readableBytes() >= len + kHeaderLen)
{
buf->retrieve(kHeaderLen);
muduo::string message(buf->peek(), len);
messageCallback_(conn, message, receiveTime);
buf->retrieve(len);
}
else
{
break;
}
}
}
// 打包代码
void send(muduo::net::TcpConnection* conn,
const muduo::StringPiece& message)
{
muduo::net::Buffer buf;
buf.append(message.data(), message.size());
int32_t len = static_cast(message.size());
int32_t be32 = muduo::net::sockets::hostToNetwork32(len);
buf.prepend(&be32, sizeof be32);
conn->send(&buf);
}
private:
StringMessageCallback messageCallback_;
const static size_t kHeaderLen = sizeof(int32_t);
};
7.4 muduo Buffer类的设计与使用
在实际中,non-blocking 几乎总是和 IO-multiplexing 一起使用,原因有两点:
- 没有人真的会用轮询 (busy-pooling) 来检查某个 non-blocking IO 操作是否完成,这样太浪费 CPU cycles;
- IO-multiplex 一般不能和 blocking IO 用在一起,因为 blocking IO 中 read()/write()/accept()/connect() 都有可能阻塞当前线程,这样线程就没办法处理其他 socket 上的 IO 事件了。
non-blocking 网络编程中应用层 buffer 是必须的:
-
TcpConnection必须要有output buffer,原因:
- 比如TCP发送了100kb的数据,但是在write()调用中,操作系统只接受了80kb,因为不想原地等待(非阻塞),所以要尽快交出控制权,返回事件循环中。
- 对于应用程序而言,它只管生成数据,它不应该关心到底数据是一次发送还是分成几次发送。这些应该由网络库来操心。
- 网络库应该接管这剩余的20kB数据,把它保存在该TCP connection的output buffer里,然后注册POLLOUT事件,一旦socket变得可写就立刻发送数据。
- 综上,要让程序在write操作上不阻塞,网络库必须要给每个TCPconnection配置output buffer。
-
TcpConnection必须要有input buffer,原因:
- 网络库在处理“socket可读”事件的时候必须一次性把socket的数据一次性读完(从操作系统的buff搬运到应用层的buff上面),否则会反复触发POLLIN事件,造成busy-loop。
- 那么网络库必然要应对“数据不完整”的情况,收到的数据先放到input buffer里,等构成一条完整的消息再通知程序的业务逻辑。这通常是codec(编码解码器)的职责。
muduo EventLoop采用的是epoll(4) level trigger,而不是ET。原因:
- 一是为了与传统的poll(2)兼容,因为在文件描述符数目较少,活动文件描述符比例较高时,epoll不见得比poll更高效,必要时可以在进程启动时切换Poller。
- 二是level trigger编程更容易,以往select(2)/poll(2)的经验都可以继续用,不可能发生漏掉事件的bug。
- 三是读写的时候不必等候出现EAGAIN,可以节省系统调用次数,降低延迟。
7.4.3 Buffer的功能需求
Muduo Buffer 的设计要点:
- 对外表现为一块连续的内存(char* p, int len),以方便客户代码的编写;
- 其 size() 可以自动增长,以适应不同大小的消息。它不是一个 fixed size array;
- 内部以
std::vector来保存数据,并提供相应的访问函数;
在非阻塞网络编程中,如何设计并使用缓冲区? 一方面希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区。 另一方面希望减少内存占用。 两者相互矛盾。
muduo 用 readv 结合栈上空间巧妙地解决了这个问题。具体做法是,在栈上准备一个 65536 字节的 stackbuf,然后利用 readv() 来读取数据,iovec 有两块,第一块指向 muduo Buffer 中的 writable 字节,另一块指向栈上的 stackbuf。这样如果读入的数据不多,那么全部都读到 Buffer 中去了;如果长度超过 Buffer 的 writable 字节数,就会读到栈上的 stackbuf 里,然后程序再把 stackbuf 里的数据 append 到 Buffer 中。这么做利用了临时栈上空间,避免开巨大 Buffer 造成的内存浪费,也避免反复调用 read() 的系统开销。
线程安全?
muduo::net::Buffer 不是线程安全的,这么做是有意的,原因如下:
-
对于 input buffer,onMessage() 回调始终发生在该 TcpConnection 所属的那个 IO 线程,应用程序应该在 onMessage() 完成对 input buffer 的操作,并且不要把 input buffer 暴露给其他线程。这样所有对 input buffer 的操作都在同一个线程,Buffer class 不必是线程安全的。
-
对于 output buffer,应用程序不会直接操作它,而是调用 TcpConnection::send() 来发送数据,后者是线程安全的。
如果 TcpConnection::send() 调用发生在该 TcpConnection 所属的那个 IO 线程,那么它会转而调用 TcpConnection::sendInLoop(),sendInLoop() 会在当前线程(也就是 IO 线程)操作 output buffer;如果 TcpConnection::send() 调用发生在别的线程,它不会在当前线程调用 sendInLoop() ,而是通过 EventLoop::runInLoop() 把 sendInLoop() 函数调用转移到 IO 线程(听上去颇为神奇?),这样 sendInLoop() 还是会在 IO 线程操作 output buffer,不会有线程安全问题。当然,跨线程的函数转移调用涉及函数参数的跨线程传递,一种简单的做法是把数据拷一份,绝对安全。
7.4.4 Buffer的数据结构
Buffer 的内部是一个std::vector,它是一块连续的内存。此外,Buffer 有两个 data members,指向该 vector 中的元素。这两个 indices 的类型是 int,不是 char*,目的是应对迭代器失效。Muduo Buffer 的数据结构如下:

两个 indices 把 vector 的内容分为三块:prependable、readable、writable。

readable初始为0,写入数据后writeIndex后移。writable大小不够时,vector自动增长(重新分配内存)。读取数据后,readIndex后移,与最终writeIndex重叠,恢复初始状态。
Muduo 的设计目标是用于开发公司内部的分布式程序。换句话说,它是用来写专用的 Sudoku server 或者游戏服务器,不是用来写通用的 httpd 或 ftpd 或Web proxy。前者通常有业务逻辑,后者更强调高并发与高吞吐。
Muduo 的设计目标之一是吞吐量能让千兆以太网饱和,也就是每秒收发 120 兆字节的数据。这个很容易就达到,不用任何特别的努力。
千兆以太网,每秒传输1000Mbit数据,即125MB/s, 扣除以太网 header、IP header、TCP
header之后,应用层的吞吐率大约在 117 MB/s 上下。
7.5 —种自动反射消息类型的Protobuf网络传输方案
本节要解决的问题是:通信双方在编译时就共享proto文件的情况下,接收方在收到Protobuf二进制数据流之后,如何自动创建具体类型的Protobuf Message对象, 并用收到的数据填充该Message对象(即反序列化)。“自动”的意思是:当程序中新增一个Protobuf Message类型时,这部分代码不需要修改。
Protobuf是一款非常优秀的库,它定义了一种紧凑的可扩展二进制消息格式,特别适合网络数据传输。
在网络编程中使用Protobuf需要解决以下两个问题:
-
长度,Protobuf打包的数据没有自带长度信息或终结符,需要由应用程序在发送和接收时做正确的切分。通常的做法是在每个消息前面加个固定长度的length header;
-
类型,Protobuf打包的数据没有自带类型信息,需要由发送方把类型信息传给给接收方,接收方创建具体的Protobuf Message对象,再做反序列化。Protobuf对此有内建的支持。
Protobuf本身具有很强的反射功能,可以根据 type name 创建具体类型的Message对象。起关键作用的是Descriptor,每个具体Message type都对应一个Descriptor对象。 因此,我们发送protobuf data时要附带type name。
详细介绍:https://www.cnblogs.com/gqtcgq/p/10363202.html
7.6 在muduo中实现Protobuf编解码器与消息分发器
在使用TCP长连接,且在一个连接上传递不止一种消息的情况时,需要一个分发器dispatcher,把不同类型的消息分给各个消息处理函数。
7.6.1 什么是编解码器(codec)
编解码器(codec)是encoder和decoder的缩写,这是一个软硬件领域都在使用的术语。这里借指“把网络数据和业务消息互相转换”的代码。
在最简单的网络编程中,没有消息,只有字节流数据,这时是用不到codec的。
在non-blocking网络编程中,codec几乎是必不可少的。既然这个任务太常见,可以做一个utility class(工具类),避免服务端和客户端程序都要自己处理分包和解析。codec是一层间接性,它位于TcpConnection和业务服务之间,拦截处理收到的数据(Buffer*),在收到完整的消息之后,解出消息对象, 再调用业务服务对应的处理函数。
之前在ChatServer中使用的LengthHeaderCodec就是一种codec:

Protobuf codec与此非常类似,只不过消息类型从std::string变成了protobuf::Message。
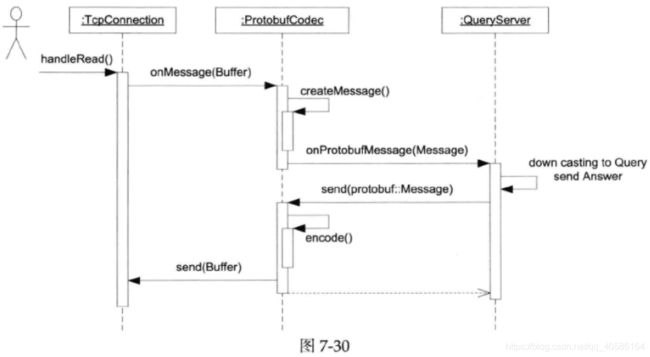
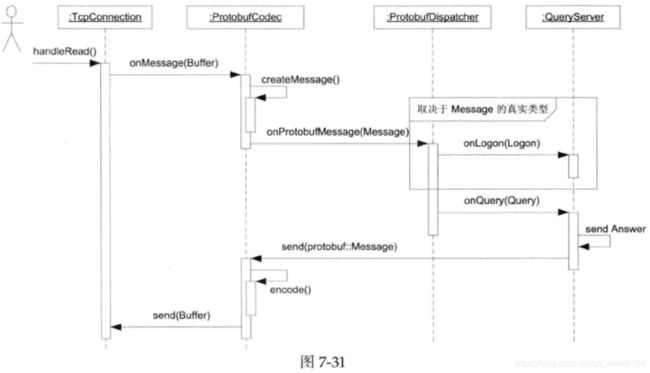
7.6.3 消息分发器(dispatcher)
前面提到,在使用TCP长连接,且在一个连接上传递不止一种Protobuf消息的情况下,客户代码需要对收到的消息按类型做分发。比方说,收到Logon消息就交给QueryServer::onLogon()处理,收到 Query 消息就交给 QueryServer::onQuery()处理。这个消息分派机制可以做得稍微有点通用性,让所有muduo+Protobuf程序受益,而且不增加复杂性。
换句话说,又是一层间接性,Protobufcodec拦截了TcpConnection的数据,把它转换为Message,ProtobufDispatcher拦截了Protobufcodec的callback,按消息具体类型把它分派给多个callbacks,如图所示。
7.7 限制服务器的最大并发连接数
这里的并发连接数是指同时支持的客户端的连接数,原因:
- 不希望程序超载;
- 因为fd是稀缺资源,如果fd耗尽则很棘手。
accept(2)返回EMFILE该如何应对?这意味着本进程的文件描述符已经达到上限,无法为新连接创建socket文件描述符。但是,既然没有socket文件描述符来表示这个连接,我们就无法close(2)它。但是,监听端口又会一直可读,有新连接待处理但又处理不了。陷入busy loop。
解决办法:
-
调高进程fd数量;
-
死等,鸵鸟算法;
-
改用ET。若漏掉一次accept,程序再也不会收到新连接。
-
准备一个空闲的文件描述符来占坑 。遇到这种情况,先关闭这个空闲文件,获得一个文件描述符的名额;再accept(2)拿到新socket连接的描述符;随后立刻close(2)它,这样就优雅地断开了客户端连接;最后重新打开一个空闲文件,把“坑”占住,以备再次出现这种情况时使用。不过多线程下会又竞态条件。
if (errno == EMFILE) { ::close(idleFd_); idleFd_ = ::accept(acceptSocket_.fd(), NULL, NULL); ::close(idleFd_); idleFd_ = ::open("/dev/null", O_RDONLY | O_CLOEXEC); } -
设置一个soft limit,超过该限制就主动关闭新连接,就可以避免触及“fd耗尽”的边界条件。
7.7.2 在muduo中限制并发连接数
记录连接数。然后,在EchoServer:onconnection()中判断当前活动连接数。如果超过最大允许数,则使用shutdown()踢掉连接。
7.8 定时器
在一般的服务端程序设计中,与时间有关的常见任务有:
- 获取当前时间,计算时间间隔。
- 时区转换与日期计算。
- 定时操作,比如在预定的时间执行任务,或者在一段延时之后执行任务。
7.8.2 Linux时间函数
Linux的计时函数,用于获得当前时间:
- time(2)/time_t(秒)
- ftime(3)/struct timeb(毫秒)
- gettimeofday(2)/struct timeval(微秒)
- clock_gettime(2)/struct timespec(纳秒)
定时函数,用于让程序等待一段时间或安排计划任务:
- sleep(3)
- alarm(2)
- usleep(3)
- nanosleep(2)
- clock_nanosleep(2)
- getitimer(2)/setitimer(2)
- timer_create(2)/timer_settime(2)/timer_gettime(2)/timer_delete(2)
- timerfd_create(2)/timerfd_gettime(2)/timerfd_settime(2)
多线程时间函数取舍:
- (计时)只使用
gettimeofday(2)来获取当前时间。 - (定时)只使用
timerfd_*系列函数来处理定时任务。
原因:
gettimeofday(2)精度为微秒,并且是在用户态实现的特殊系统调用,不需要陷入内核,开销低。timerfd_*不需要使用信号(多线程处理信号很麻烦),精度为纳秒,将定时器与fd结合,方便使用select/poll/epoll。此外,非阻塞网络中绝不能让线程挂起来定时,会失去响应。
必须要说明,在Linux这种非实时多任务操作系统中,在用户态实现完全精确可控的计时和定时是做不到的,因为当前任务可能会被随时切换出去,这在CPU负载大的时候尤为明显。但是,我们的程序可以尽量提高时间精度,必要的时候通过控制CPU负载来提高时间操作的可靠性。
7.8.3 muduo的定时器接口
muduo EventLoop有三个定时器函数:
- runAt在指定的时间调用TimerCallback;
- runAfter等一段时间调用TimerCallback;
- runEvery以固定的间隔反复调用TimerCallback;
- cancel取消timer。
muduo的TimerQueue采用了平衡二叉树来管理未到期的timers,因此这些操作的事件复杂度是O(logN)。
7.10 用timing wheel踢掉空闲连接
一个连接如果若干秒没有收到数据,就被认为是空闲连接。在严肃的网络程序中,应用层的心跳协议是必不可少的。 应该用心跳消息来判断对方进程是否能正常工作。
使用 timing wheel 能够有效处理连接超时。
其核心思想为:
-
处理连接超时可以用一个简单的数据结构:8 个桶组成的循环队列。
-
第一个桶放下一秒将要超时的连接,第二个放下 2 秒将要超时的连接。每个连接一收到数据就把自己放到第 8 个桶,然后在每秒钟的 callback 里把第一个桶里的连接断开,把这个空桶挪到队尾。这样大致可以做到 8 秒钟没有数据就超时断开连接。更重要的是,每次不用检查全部的 connection,只要检查第一个桶里的 connections,相当于把任务分散了。
7.10.1 Timing wheel 原理
Simple timing wheel 的基本结构是 一个循环队列 + 一个指向队尾的指针 (tail),这个指针每秒钟移动一格,就像钟表上的时针,timing wheel 由此得名。
以下是某一时刻 timing wheel 的状态,格子里的数字是倒计时(与通常的 timing wheel 相反),表示这个格子(桶子)中的连接的剩余寿命。一秒钟以后,tail 指针移动一格,新指向的格子被清空,其中的连接已被断开。

timing wheel 中的每个格子是个 hash set,可以容纳不止一个连接,同时去重。
7.10.2 代码实现与改进
在具体实现中,格子里放的不是连接,而是一个特制的 Entry struct,每个 Entry 包含 TcpConnection 的 weak_ptr。Entry 的析构函数会判断连接是否还存在(用 weak_ptr),如果还存在则断开连接。
struct Entry : public muduo::copyable
{
explicit Entry(const WeakTcpConnectionPtr& weakConn)
: weakConn_(weakConn)
{
}
~Entry()
{
muduo::net::TcpConnectionPtr conn = weakConn_.lock();
if (conn)
{
conn->shutdown();
}
}
WeakTcpConnectionPtr weakConn_;
};
typedef std::shared_ptr EntryPtr;
typedef std::weak_ptr WeakEntryPtr;
typedef std::unordered_set Bucket;
typedef boost::circular_buffer WeakConnectionList;
为了简单起见,我们不会真的把一个连接从一个格子移到另一个格子,而是采用引用计数的办法,用 shared_ptr 来管理 Entry。如果从连接收到数据,就把对应的 EntryPtr 放到这个格子里,这样它的引用计数就递增了。当 Entry 的引用计数递减到零,说明它没有在任何一个格子里出现,那么连接超时,Entry 的析构函数会断开连接。
在构造函数中,注册每秒钟的回调(EventLoop::runEvery() 注册 EchoServer::onTimer() ),然后把 timing wheel 设为适当的大小。
EchoServer::EchoServer(EventLoop* loop,
const InetAddress& listenAddr,
int idleSeconds)
: server_(loop, listenAddr, "EchoServer"),
connectionBuckets_(idleSeconds)
{
server_.setConnectionCallback(
std::bind(&EchoServer::onConnection, this, _1));
server_.setMessageCallback(
std::bind(&EchoServer::onMessage, this, _1, _2, _3));
loop->runEvery(1.0, std::bind(&EchoServer::onTimer, this));
connectionBuckets_.resize(idleSeconds);//根据超时秒数设置Bucket大小
}
其中 EchoServer::onTimer() 的实现只有一行(除了打印消息):往队尾添加一个空的 Bucket,这样 circular_buffer 会自动弹出队首的 Bucket,并析构之。
void EchoServer::onTimer()
{
connectionBuckets_.push_back(Bucket());
dumpConnectionBuckets();//打印消息
}
在连接建立时,以对应的TcpConnection对象conn来创建一个 Entry 对象entry,把它放到 timing wheel 的队尾。另外,我们还需要把 entry的弱引用保存到 conn的 context (boost::any类型,可以保存任何类型)里,因为在收到数据的时候还要用到 Entry,且弱引用不影响引用计数。
void EchoServer::onConnection(const TcpConnectionPtr& conn)
{
LOG_INFO << "EchoServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
EntryPtr entry(new Entry(conn));//连接到来的时候,创建entry对象来管理conn
connectionBuckets_.back().insert(entry);
dumpConnectionBuckets();
WeakEntryPtr weakEntry(entry);
conn->setContext(weakEntry);
}
else
{
assert(!conn->getContext().empty());
WeakEntryPtr weakEntry(boost::any_cast<WeakEntryPtr>(conn->getContext()));
LOG_DEBUG << "Entry use_count = " << weakEntry.use_count();
}
}
在收到消息时,从 TcpConnection 的 context 中取出 Entry 的弱引用,把它提升为强引用 EntryPtr,然后放到当前的 timing wheel 队尾。(提升为强引用的时候,引用计数+1)
void EchoServer::onMessage(const TcpConnectionPtr& conn,
Buffer* buf,
Timestamp time)
{
string msg(buf->retrieveAllAsString());
LOG_INFO << conn->name() << " echo " << msg.size()
<< " bytes at " << time.toString();
conn->send(msg);
assert(!conn->getContext().empty());
WeakEntryPtr weakEntry(boost::any_cast<WeakEntryPtr>(conn->getContext()));
EntryPtr entry(weakEntry.lock());
if (entry)
{
connectionBuckets_.back().insert(entry);
dumpConnectionBuckets();
}
}
总结:
每个TcpConnection有一个上下文Context变量保存Entry的WeakPtr。 有了上下文,服务器每当收到客户端的消息时(onMessage),可以拿到与该连接关联的Entry的弱引用,再把它提升到强引用,插入到circular_buffer,这样就相当于把更新了该连接在时间轮盘里面的位置了,相应的use_count会加1。
7.11 简单的消息广播服务
在分布式系统中,除了常用的 end-to-end 通信,还有一对多的广播通信。本节讨论的是基于 TCP 协议的应用层广播。
 上图中圆角矩形代表程序,"Hub"是一个服务程序,不是网络集线器,它起到类似集线器的作用,故而得名。Publisher 和 Subscriper 通过 TCP 协议与 Hub 程序通信。Publisher 把消息发到某个 topic 上,Subscribers 订阅该 topic,然后就能收到消息。即 publisher 借助 hub 把消息广播给了多个 subscribers。
上图中圆角矩形代表程序,"Hub"是一个服务程序,不是网络集线器,它起到类似集线器的作用,故而得名。Publisher 和 Subscriper 通过 TCP 协议与 Hub 程序通信。Publisher 把消息发到某个 topic 上,Subscribers 订阅该 topic,然后就能收到消息。即 publisher 借助 hub 把消息广播给了多个 subscribers。
这种 pub/sub 结构的好处在于可以增加多个 Subscriber 而不用修改 Publisher,从而一定程度上实现了“解耦”(也可以看成分布式的 observer pattern)。
详细介绍:https://blog.csdn.net/baidu_15952103/article/details/110790558
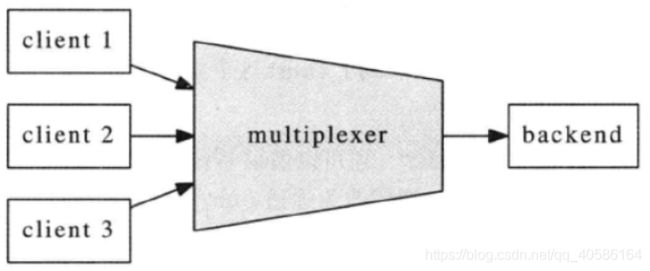
7.12 "串并转换"连接服务器
网游连接服务器的功能需求(不考虑安全性):
这个连接服务器把多个客户连接汇聚为一个内部TCP连接,起到“数据串并转换”的作用,让backend的逻辑服务器专心处理业务,而无须顾及多连接的并发性。系统的框图如图所示。
 实现
实现
multiplexer的功能需求不复杂,无非是在backend connection和client connections之间倒腾数据。对每个新client connection分配一个新的整数id,如果id用完了,则断开新连接(这样通过控制id的数目就能控制最大连接数)。另外,为了避免id过快地被复用(有可能造成backend串话),multiplexer采用queue来管理free id,每次从队列的头部取id,用完之后放回queue的尾部。
具体来说,主要是处理四种事件:
- 当client connection到达或断开时,向backend发出通知。代码见onClientConnection()。
- 当从client connection收到数据时,把数据连同connection id一同发给back end。代码见onclientMessage()。
- 当从backend connection收到数据时,辨别数据是发给哪个client connection,并执行相应的转发操作。代码见onBackendMessage()。
- 如果backend connection断开连接,则断开所有client connections(假设client会自动重试),代码见onBackendConnection()。
代码见 examples\multiplexer,multiplexer_simple.cc是一个单线程版的实现,多线程版的实现见multiplexer.cc。
7.13 proxy代理服务工具
7.14 muduo内置简陋HTTP服务器
7.15 与其他库集成
通过Channel class可以把其他一些现成的网络库融入muduo的event loop中。
Channel class是IO事件回调的分发器(dispatcher),它在handleEvent()中根据事件的具体类型分别回调Readcallback、writeCallback等。每个Channel对象服务于一个文件描述符,但并不拥有fd,在析构函数中也不会close(fd)。详见8.1.1节。
第8章 muduo 网络库设计与实现
参考:https://blog.csdn.net/freeelinux/category_6479321.html
8.0 什么都不做的EventLoop
one loop per thread 顾名思义每个线程都只能有一个EventLoop对象。故构造时会先检查当前线程是否已经创建EvenLoop(通过现场局部存储记录EvenLoop指针)。
创建了EventLoop对象的线程是I/O线程,其主要功能是运行事件循环EventLoop::loop(),监听事件并处理。
muduo的接口设计会明确哪些成员函数是线程安全的,可以跨线程调用;哪些成员函数只能在某个特定线程调用(主要是I/O线程),为了能在运行时检查这些pre-condition,EventLoop提供了isInLoopThread()和assertInLoopThread()等函数。
事件循环必须在I/O线程执行,因此EventLoop::loop()会进行这一检查。
https://blog.csdn.net/FreeeLinux/article/details/53510541
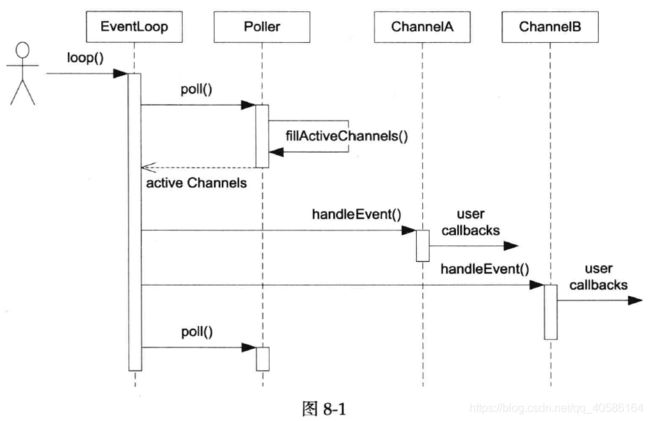
8.1 Reactor的关键结构
本节讲Reactor最核心的事件分发机制,即将I/O multiplexing拿到的I/O事件分发给各个文件描述符(fd)的事件处理函数。
8.1.1 Channel class
Channel类,即通道类,负责一个fd的事件。
- 它是muduo库负责注册读写事件的类,并保存了fd读写事件发生时调用的回调函数,如果poll/epoll有读写事件发生则将这些事件添加到对应的通道中。
- 一个通道对应唯一EventLoop,一个EventLoop可以有多个通道。
- Channel类不负责fd的生存期,fd的生存期是有socket决定的,断开连接关闭描述符。
- Channel会把不同的IO事件分发为不同的回调,例如ReadCallback、WriteCallback、ErrorCallback等。
- muduo用户一般不直接使用Channel,而会使用更上层的封装,如TcpConnection。
https://blog.csdn.net/FreeeLinux/article/details/53456945
8.1.2 Poller class
vector的定义时,可以使用前向声明的T类型。
muduo库中唯一使用面向对象的地方就在Poller,它有两个派生类,分别是PollPoller和EPollPoller。可以实现两种I/O多路复用机制。
-
Poller使用一个map来存放描述符fd和对应的Channel类型的指针,这样我们就可以通过fd很方便的得到Channel了。
-
Poller::poll调用poll或者epoll_wait,当有事件发生时,使用
fillActiveChannels()将有活动事件的fd对应的Channel填入activeChannels。 -
Poller并不拥有Channel,Channel在析构之前必须自己unregister(
EventLoop::removeChannel()),避免空悬指针。 -
Poller::updatechannel()的主要功能是负责维护和更新pollfds_数组。
https://blog.csdn.net/FreeeLinux/article/details/53457060
8.1.3 总结
以上几个class构成了Reactor模式的核心内容。
 示例:
示例:
用timerfd实现了一个单次触发的定时器。
#include 8.2 TimerQueue定时器
传统的Reactor通过控制select和poll的等待时间来实现定时,而现在在Linux中有了timerfd,我们可以用和处理I/O事件相同的方式来处理定时,代码的一致性更好。
muduo的定时器功能由三个class实现,TimerId、Timer、TimerQueue,用户只能看到第一个class,另外两个都是内部实现细节。
Timer类
Timer是对定时器的高层次抽象,封装了定时器的一些参数,例如超时回调函数、超时时间、超时时间间隔、定时器是否重复、定时器的序列号。其函数大都是设置这些参数,run()用来调用回调函数,restart()用来重启定时器(如果设置为重复)。
TimerId类
TimerId是被设计用来取消Timer的,它的结构很简单,只有一个Timer指针和其序列号。其中还声明了TimerQueue为其友元,可以操作其私有数据。
TimerQueue类
TimerQueue类是重点,它的内部有channel,和timerfd相关联。添加新的Timer后,在超时后,timerfd可读,会处理channel事件,之后调用Timer的回调函数;在timerfd的事件处理后,还要检查一遍超时定时器,如果其属性为重复还要再次添加到定时器集合中。
整个TimerQueue类只有一个timerfd,它在内部使用set保存了多个Timer对象,Timestamp为到期时间。timerfd的触发时间永远与保存的定时器中触发时间最近的那个相同。
图8-2是TimerQueue回调用户代码onTimer()的时序图。

TimerQueue的接口很简单,只有两个函数addTimer()和cancel()。addTimer()是供EventLoop使用的,EventLoop会把它封装为更好用的runAt()、runAfter()、runEvery()等函数。
TimerId EventLoop::runAt(Timestamp time, TimerCallback cb)
{
return timerQueue_->addTimer(std::move(cb), time, 0.0);
}
TimerId EventLoop::runAfter(double delay, TimerCallback cb)
{
Timestamp time(addTime(Timestamp::now(), delay));
return runAt(time, std::move(cb));
}
TimerId EventLoop::runEvery(double interval, TimerCallback cb)
{
Timestamp time(addTime(Timestamp::now(), interval));
return timerQueue_->addTimer(std::move(cb), time, interval);
}
注意这几个EventLoop成员函数应该允许跨线程使用,比方说我想在某个I/O线程中执行超时回调。这就带来线程安全性方面的问题,muduo的解决办法不是加锁,而是把对Timerqueue的操作转移到I/O线程来进行,这会用到S8.3介绍的EventLoop::runInLoop()函数。
8.3 EventLoop::runInLoop()函数
EventLoop有一个非常有用的功能:在它的IO线程内执行某个用户任务回调,即EventLoop::runInLoop(const Functor&cb),其中Functor是function。
如果用户在当前IO线程调用这个函数,回调会直接进行;如果用户在其他线程调用该函数,回调函数cb会被加入到数组,IO线程会被唤醒来调用这个Functor(EventLoop在每次循环末尾使用doPendingFunctors()处理回调函数数组)。
void EventLoop::runInLoop(const Functor& cb)
{
if (isInLoopThread())
{
cb();
}
else
{
queueInLoop(cb);
}
}
有了这个功能,我们就能够轻易地在线程间调配任务,比方说吧TimerQueue的成员函数调用移动到IO线程,这样可以==在不用锁的情况下保证线程安全性==。
唤醒IO监听阻塞
IO线程平时阻塞在事件循环EvenLoop::loop()的poll调用中,为了让IO线程立刻唤醒它,传统的方法是使用pipe(2),IO线程始终监视此管道的可读事件,需要唤醒的时候,其他线程往管道里写一个字节。现在的Linux有了eventfd(2),可以更加高效的唤醒,因为不必管理缓冲区。
eventfd自带sizeof(uint64_t)大小的缓冲区;向其write可以递增这个计数器,read操作可以读取,并进行清零;eventfd也可以放到监听队列中,当计数器不是0时,有可读事件发生,可以进行读取。
8.3.2 EventLoopThread class
- I/O线程不一定是主线程,一个进程可以有不止一个IO线程。
- 可以按照优先级将不同的Socket分给不同的IO线程,避免优先级反转。
- 为了方便使用,就直接定义了一个I/O线程的类,就是EventLoopThread类,该类实际上就是对I/O线程的封装。
- EventLoopThread会启动自己的线程,并在其中运行
EventLoop::loop()(定义在栈上)。 startLoop()函数用条件变量来等待线程的创建与运行,并返回EventLoop*。
- EventLoopThread会启动自己的线程,并在其中运行
https://blog.csdn.net/FreeeLinux/article/details/53521000
8.4 实现TCP网络库
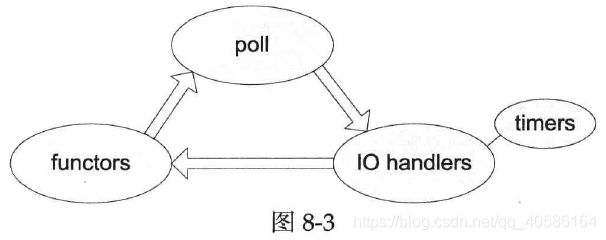
从本节开始我们用它逐步实现一个非阻塞TCP网络编程库。从poll返回到再次调用poll阻塞称为一次事件循环:
Acceptor class
Acceptor class,用于accept新TCP连接,并通过回调通知使用者。它是内部class,供TcpServer使用,生命期由后者控制。
Acceptor的数据成员包括Socket、Channel等。其中Socket是一个RAII handle,封装了listening socket文件描述符的生命期。 Channel用于观察此socket上的readable事件,并回调Acceptor::handleRead(),后者会调用accept来接受新连接,并回调用户callback,其形参为新连接connfd(可以优化为移动语意的Socket对象)以及客户端InetAddress。
private:
void handleRead(); //可读回调函数
EventLoop* loop_; //loop指针
Socket acceptSocket_; //监听套接字
Channel acceptChannel_; //和监听套接字绑定的通道
NewConnectionCallback newConnectionCallback_; //一旦有新连接发生执行的回调函数
bool listenning_; //acceptChannel所处的EventLoop是否处于监听状态
int idleFd_; //用来解决文件描述符过多引起电平触发不断触发的问题,后文会有解释
Acceptor的构造函数和Acceptor::listen()成员函数执行创建TCP服务端的传统步骤,即调用socket(2)、bind(2)、listen(2)等Sockets API,其中任何一个步骤出错都会造成程序终止。通常出错原因是端口被占用。这时让程序异常退出更好,因为能触发监控系统报警,而不是假装正常运行。
Acceptor::handleRead()的策略很简单,每次accept(2)一个socket。另外还有两种实现策略:
- 一是每次循环accept(2),直至没有新的连接到达;
- 二是每次尝试accept(2)N个新连接,N的值一般是10。
后面这两种做法适合短连接服务,而muduo是为长连接服务优化的,因此这里用了最简单的办法。(现在的Http默认使用长连接)
int sockets::accept(int sockfd, struct sockaddr_in6* addr)
{
socklen_t addrlen = static_cast(sizeof *addr);
#if VALGRIND || defined (NO_ACCEPT4)
int connfd = ::accept(sockfd, sockaddr_cast(addr), &addrlen);
setNonBlockAndCloseOnExec(connfd);
#else
int connfd = ::accept4(sockfd, sockaddr_cast(addr),
&addrlen, SOCK_NONBLOCK | SOCK_CLOEXEC);
#endif
if (connfd < 0)
{
int savedErrno = errno;
LOG_SYSERR << "Socket::accept";
switch (savedErrno)
{
case EAGAIN:
case ECONNABORTED:
case EINTR:
case EPROTO: // ???
case EPERM:
case EMFILE: // per-process lmit of open file desctiptor ???
// expected errors
errno = savedErrno;
break;
case EBADF:
case EFAULT:
case EINVAL:
case ENFILE:
case ENOBUFS:
case ENOMEM:
case ENOTSOCK:
case EOPNOTSUPP:
// unexpected errors
LOG_FATAL << "unexpected error of ::accept " << savedErrno;
break;
default:
LOG_FATAL << "unknown error of ::accept " << savedErrno;
break;
}
}
return connfd;
}
利用Linux新增的系统调用accept4可以直接accept一步得到非阻塞的socket。
这里区分致命错误和暂时错误,并区别对待。对于暂时错误,例如EAGAIN、EINTR、EMFILE,ECONNABORTED等等,处理办法是忽略这次错误。对于致命错误,例如ENFILE、ENOMEM等等,处理办法是终止程序,对于未知错误也照此办理。
测试用例:
#include
#include
#include
#include
#include
using namespace muduo;
using namespace muduo::net;
void newConnection(int sockfd, const InetAddress& peerAddr)
{
printf("newConnection() : accepted a new connection from %s\n",
peerAddr.toIpPort().c_str());
::write(sockfd, "How are you?\n", 13);
sockets::close(sockfd);
}
int main()
{
printf("main(): pid = %d\n", getpid());
InetAddress listenAddr(8888);
EventLoop loop;
Acceptor acceptor(&loop, listenAddr, true);
acceptor.setNewConnectionCallback(newConnection);
acceptor.listen();
loop.loop();
}
8.5 TcpServer接受新连接
TcpServer新建连接的相关函数调用顺序见图8-4(有的函数名是简写,省略了poll调用),其中Channel::handleEvent()的触发条件是listening socket可读,表明有新连接到达。TcpServer会为新连接创建对应的TcpConnection对象。

8.5.1 TcpServer class
-
它的功能是管理accept(2)获得的TcpConnection。Tcpserver是供用户直接使用的,生命周期由用户控制用户只需要设置好callback,调用start()即可。
-
TcpServer内部使用Acceptor来获得新连接的fd。它保存用户提供的Connectioncallback和Messagecallback,在新建Tcpconnection的时候会原样传给后者。TcpServer持有目前存活的TpConnection的shared_ptr(定义为TcpConnectionPtr)。
-
在新连接到达时,Acceptor会回调newConnection(),后者会创建TcpConnection对象conn,把它加入connectionMap,设置好callback,再调用
conn->connectEstablished(),其中会回调用户提供的Connectioncallback。
注意muduo尽量让依赖是单向的,TcpServer会用到Acceptor,但Acceptor并不知道TcpServer的存在。TcpServer会创建TcpConnection,但TcpConnection并不知道TcpServer的存在。
8.5.2 TcpConnection class
- TcpConnection class是muduo里面最复杂,最核心的class,也是Muduo唯一默认使用shared_ptr 来管理的class。
- TcpConnection使用Channel来获得socket上的IO事件,它会自己处理writable事件,而把readable事件通过MessageCallback传达给客户。
8.6 TcpConnection断开连接
muduo有两种关闭连接的方式:
- 被动关闭。即对方先关闭连接,本地read(2)返回0,触发关闭逻辑。
- 关闭连接,调用forceClose()成员函数即可,实际还是通过handleclose()函数。
函数调用的流程见图8-5,其中的“X"表示TcpConnection通常会在此时析构。
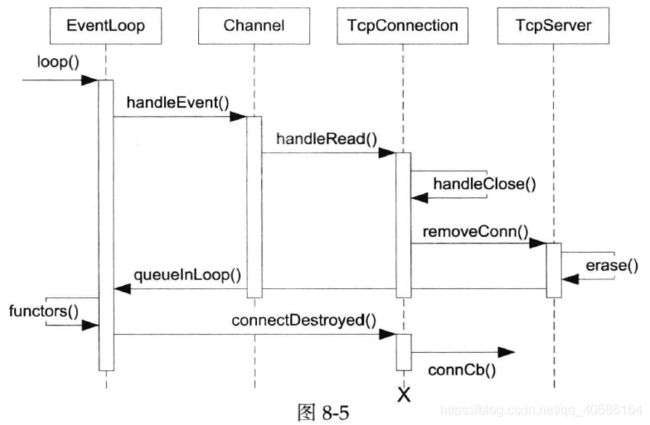
一般来讲数据的删除比新建要复杂,TCP连接也不例外,根本原因是对象生命期管理的需要。
Channel 的改动
Channel class新增了closeCallback事件回调,
if ((revents_ & POLLHUP) && !(revents_ & POLLIN))
{
if (logHup_)
{
LOG_WARN << "fd = " << fd_ << " Channel::handle_event() POLLHUP";
}
if (closeCallback_) closeCallback_();
}
其中,closeCallback_被绑定为TcpConnection::handleClose()。
TcpConnection改动
TcpConnection class也新增了CloseCalback事件回调,但是这个回调是给TcpServer和TcpClient用的,用于通知它们移除所持有的TcpConnectionPtr,这不是给普通用户用的。
TcpConnection::handleRead()会检查read(2)的返回值,根据返回值分别调用messageCallback_、handleclose()、handleError()。
void TcpConnection::handleRead(Timestamp receiveTime)
{
loop_->assertInLoopThread();
int savedErrno = 0;
ssize_t n = inputBuffer_.readFd(channel_->fd(), &savedErrno);
if (n > 0)
{
messageCallback_(shared_from_this(), &inputBuffer_, receiveTime);
}
else if (n == 0)
{
handleClose();
}
else
{
errno = savedErrno;
LOG_SYSERR << "TcpConnection::handleRead";
handleError();
}
}
TcpConnection::handleclose()的主要功能是调用closeCallback,这个回调被TcpServer::removeConnection()绑定。
void TcpConnection::handleClose()
{
loop_->assertInLoopThread();
LOG_TRACE << "TcpConnection::handleClose state = " << state_;
assert(state_ == kConnected);
// we don't close fd, leave it to dtor, so we can find leaks easily.
channel_->disableAll();
// must be the last line
closeCallback_(shared_from_this());
}
TcpConnection::connectDestroyed()是TcpConnection析构前最后调用的一个成员函数,它通知用户连接已断开。
void TcpConnection::connectDestroyed()
{
loop_->assertInLoopThread();
assert(state_ == kConnected);
setState(kDisconnected);
channel_->disableAll();
connectionCallback_(shared_from_this());
loop_->removeChannel(get_pointer(channel_));
}
TcpServer 的改动
建立连接时,TcpServer向TcpConnection注册CloseCallback,用于接收连接断开的消息。
conn->setCloseCallback(std::bind(&TcpServer::removeConnection, this, _1));
TcpServer::removeConnection()把conn从ConnectionMap中移除。注意这里用bind让TcpConnection的生命期长到调用connectDestroyed()的时刻,否则会在函数结束时直接析构!
void TcpServer::removeConnection(const TcpConnectionPtr& conn)
{
loop_->runInLoop(std::bind(&TcpServer::removeConnectionInLoop, this, conn));
}
void TcpServer::removeConnectionInLoop(const TcpConnectionPtr& conn)
{
loop_->assertInLoopThread();
LOG_INFO << "TcpServer::removeConnectionInLoop [" << name_
<< "] - connection " << conn->name();
size_t n = connections_.erase(conn->name());
(void)n;
assert(n == 1);
EventLoop* ioLoop = conn->getLoop();
ioLoop->queueInLoop(
std::bind(&TcpConnection::connectDestroyed, conn));
}
EventLoop和Poller的改动
EventLoop新增了removeChannel()成员函数,它会调用Poller::removeChannel()。
注意其中从数组pollfds_中删除元素是O(1)复杂度,办法是将待删除的元素与最后一个元素交换,再pollfds_.pop_back()。
8.7 Buffer读取数据
Buffer是非阻塞TCP网络编程必不可少的东西(Chapter 7.4),本节介绍用Buffer来处理数据输入,下一节介绍数据输出。Buffer是另一个具有值语义的对象。
8.7.1 TcpConnection使用Buffer作为输入缓冲
TcpConnection了添加inputBuffer_成员变量,使用Buffer来读取数据。
void TcpConnection::handleRead(Timestamp receiveTime)
{
loop_->assertInLoopThread();
int savedErrno = 0;
ssize_t n = inputBuffer_.readFd(channel_->fd(), &savedErrno);
...
8.7.2 Buffer::readFd()
Buffer读取数据时兼顾了内存使用量和效率,其实现如下。
ssize_t Buffer::readFd(int fd, int* savedErrno)
{
// saved an ioctl()/FIONREAD call to tell how much to read
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
vec[0].iov_base = begin()+writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
// when there is enough space in this buffer, don't read into extrabuf.
// when extrabuf is used, we read 128k-1 bytes at most.
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;
const ssize_t n = sockets::readv(fd, vec, iovcnt);
if (n < 0)
{
*savedErrno = errno;
}
else if (implicit_cast(n) <= writable)
{
writerIndex_ += n;
}
else
{
writerIndex_ = buffer_.size();
append(extrabuf, n - writable);
}
return n;
}
注意点:
-
一是使用了scatter/gather IO,并且一部分缓冲区取自stack,这样输入缓冲区足够大,又不必开辟很大的堆空间,通常一次readv(2)调用就能取完全部数据。
-
二是Buffer::readFd()只调用一次read(2),而没有反复调用read(2)直到其返回EAGAIN,首先,这么做是正确的,因为muduo采用level trigger,这么做不会丢失数据或消息。其次,对追求低延迟的程序来说,这么做是高效的,因为每次读数据只需要一次系统调用(ET至少要两次)。再次,这样做照顾了多个连接的公平性,不会因为某个连接上数据量过大而影响其他连接处理消息。
将来的一个改进措施是:如果n == writable + sizeof extrabuf,就再读一次。
8.8 TcpConnection发送数据
到目前为止,我们只用到了Channel 的ReadCallback:
- TimerQueue用它来读timerfd(2)。
- EventLoop用它来读eventfd(2)。
- TcpServer/Acceptor用它来读listening socket。
- TcpConnection用它来读普通TCP socket。
由于muduo采用level trigger,因此我们只在需要时才关注writable事件,否则就会造成busy loop。
class Channel{
void enableWriting() { events_ |= kWriteEvent; update(); }
void disableWriting() { events_ &= ~kWriteEvent; update(); }
bool isWriting() const { return events_ & kWriteEvent; }
TcpConnection的接口中增加了send()和shutdown()两个函数,这两个函数都可以跨线程调用。
TcpConnection的状态增加到了4个,和目前muduo的实现一致。
enum StateE { kDisconnected, kConnecting, kConnected, kDisconnecting };
TcpConnection的状态图如下:
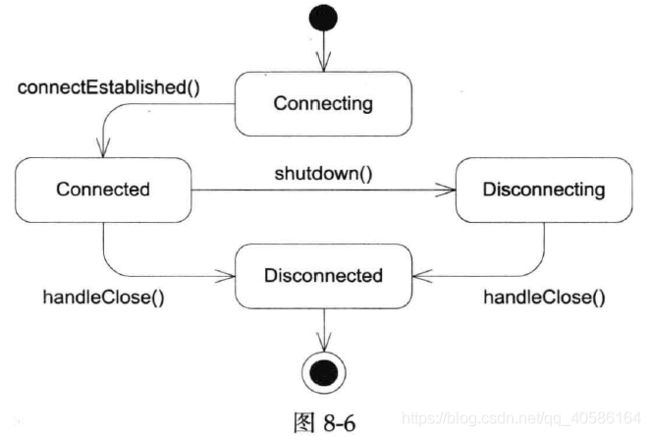
shutdown()是线程安全的:
void TcpConnection::shutdown()
{
// FIXME: use compare and swap
if (state_ == kConnected)
{
setState(kDisconnecting);
// FIXME: shared_from_this()?
loop_->runInLoop(std::bind(&TcpConnection::shutdownInLoop, this));
}
}
void TcpConnection::shutdownInLoop()
{
loop_->assertInLoopThread();
if (!channel_->isWriting())
{
// we are not writing
socket_->shutdownWrite();
}
}
没有写任务时,立即关闭,否则写完再调用shutdownInLoop(根据kDisconnecting状态)。
send()也是一样的,如果在非IO线程调用,它会把message复制(可以改进为移动)一份,传给IO线程中的sendInLoop()来发送。
sendInLoop()会先尝试直接发送数据,如果一次发送完毕就不会启用writeCallback;如果只发送了部分数据,则把剩余的数据放入outputBuffer_,并开始关注writable事件,以后在handlerwrite()中发送剩余的数据。
void TcpConnection::sendInLoop(const std::string& message)
{
loop_->assertInLoopThread();
ssize_t nwrote = 0;
// if no thing in output queue, try writing directly
if (!channel_->isWriting() && outputBuffer_.readableBytes() == 0) {
nwrote = ::write(channel_->fd(), message.data(), message.size());
if (nwrote >= 0) {
if (implicit_cast(nwrote) < message.size()) {
LOG_TRACE << "I am going to write more data";
}
} else {
nwrote = 0;
if (errno != EWOULDBLOCK) {
LOG_SYSERR << "TcpConnection::sendInLoop";
}
}
}
assert(nwrote >= 0);
if (implicit_cast(nwrote) < message.size()) {
outputBuffer_.append(message.data()+nwrote, message.size()-nwrote);
if (!channel_->isWriting()) {
channel_->enableWriting();
}
}
}
当socket变得可写时,Channel会调用TcpConnection::handlewrite(),这里我们继续发送outputBuffer_中的数据。一旦发送完毕,立刻停止观察writable事件,避免busy loop。另外如果这时连接正在关闭,则调用shutdownInLoop(),继续执行关闭过程。这里不需要处理错误,因为一旦发生错误,handleRead()会读到0字节,继而关闭连接。
void TcpConnection::handleWrite()
{
loop_->assertInLoopThread();
if (channel_->isWriting()) {
ssize_t n = ::write(channel_->fd(),
outputBuffer_.peek(),
outputBuffer_.readableBytes());
if (n > 0) {
outputBuffer_.retrieve(n);
if (outputBuffer_.readableBytes() == 0) {
channel_->disableWriting();
if (state_ == kDisconnecting) {
shutdownInLoop();
}
} else {
LOG_TRACE << "I am going to write more data";
}
} else {
LOG_SYSERR << "TcpConnection::handleWrite";
}
} else {
LOG_TRACE << "Connection is down, no more writing";
}
}
注意sendInLoop()和handlewrite()都只调用了一次write(2)而不会反复调用直至它返回EAGAIN,原因是如果第一次write(2)没有能够发送完全部数据的话,第二次调用write(2)几乎肯定会返回EAGAIN。
8.9 完善TcpConnection
本节补充几个小功能,让TcpConnection成为可以实用的单线程非阻塞TCP网络库。
8.9.1 SIGPIPE
SIGPIPE的默认行为是终止进程,在命令行程序中这是合理的,但是在网络编程中,这意味着如果对方断开连接而本地继续写入的话,会造成服务进程意外退出。
假如服务进程繁忙,没有及时处理对方断开连接的事件,就有可能出现在连接断开之后继续发送数据的情况。
解决办法很简单,在程序开始的时候就忽略SIGPIPE,可以用C++全局对象做到这一点。
#include
class IgnoreSigPipe
{
public:
IgnoreSigPipe()
{
::signal(SIGPIPE, SIG_IGN);
}
};
IgnoreSigPipe initObj;
8.9.2 TCP No Delay 和 TCP keepalive
TCP No Delay和TCP keepalive都是常用的TCP选项:
- 前者的作用是禁用Nagle算法,避免连续发包出现延迟,这对编写低延迟网络服务很重要。
- 后者的作用是定期探查TCP连接是否还存在。一般来说如果有应用层心跳的话,TCP keepalive不是必需的,但是一个通用的网络库应该暴露其接口。
8.9.3 WriteCompleteCallback和HighWaterMarkCallback
非阻塞网络编程的发送数据比读取数据要困难得多:
- 一方面是Chapter8.8提到的“什么时候关注writable事件”的问题,这只带来编码方面的难度;
- 另一方面是如果发送数据的速度高于对方接收数据的速度,会造成数据在本地内存中堆积,这带来设计及安全性方面的难度。
muduo对第二个问题的解决办法是提供两个回调,有的网络库把它们称为“高水位回调”和“低水位回调",muduo使用HighWaterMarkCallback和WriteCompleteCallback这两个名字。
writeCompleteCallback很容易理解,如果发送缓冲区被清空,就调用它。TcpConnection有两处可能触发此回调:TcpConnection::sendInLoop的write和TcpConnection::handleWrite的write后面。
另外一个有用的callback是HighWaterMarkCallback,如果输出缓冲的长度超过用户指定的大小,就会触发回调(只在上升沿触发一次)。
如果用非阻塞的方式写一个proxy,proxy有C和s两个连接(S713)。只考虑server发给client的数据流(反过来也是一样),为了防止server发过来的数据撑爆C的输出缓冲区,一种做法是在C的HighWaterMarkCallback中停止读取s的数据,而在C的WriteCompleteCallback中恢复读取S的数据。这就跟用粗水管往水桶里灌水,用细水管从水桶中取水一个道理,上下两个水龙头要轮流开合。
8.10 多线程程TcpServer
本节介绍多线程TcpServer,用到了EventLoopThreadPool class。
EventLoopThreadPool
用one loop per thread的思想实现多线程TcpServer的关键步骤是在新建TcpConnection时从event loop pool里挑选一个loop给TcpConnection用。也就是说多线程TcpServer自己的EventLoop只用来接受新连接,而新连接会用其他EventLoop来执行IO。(单线程TcpServer的EventLoop是与TcpConnection共享的)muduo的event loop pool由EventLoopThreadPool class表示,简略接口如下。
class EventLoopThreadPool : boost::noncopyable
{
public:
EventLoopThreadPool(EventLoop* baseLoop);
~EventLoopThreadPool();
void setThreadNum(int numThreads) { numThreads_ = numThreads; }
void start();
EventLoop* getNextLoop();
EventLoop* getLoopForHash(size_t hashCode);
private:
EventLoop* baseLoop_;
bool started_;
int numThreads_;
int next_; // always in loop thread
boost::ptr_vector threads_;
std::vector loops_;
};
TcpServer每次新建一个TcpConnection就会调用getNextLoop()(round-robin轮询调度算法来选取)来取得EventLoop。(还提供了了哈希getLoopForHash)
总而言之,TcpServer和TcpConnection的代码都只处理单线程的情况(甚至都没有mutex成员),而我们借助EventLoop::runInLoop()并引入EventLoopThreadPool让多线程TcpServer的实现易如反掌。
8.11 Connector
主动发起连接比被动接受连接要复杂一些,一方面是错误处理麻烦,另一方面是要考虑重试。在非阻塞网络编程中,发起连接的基本方式是调用connect(2),当socket变得可写时(同时没有错误)表明连接建立完毕。
非阻塞connect步骤(UNP 卷一 16.3节):
-
非阻塞socket进行connect,如果connect返回0,说明建立成功。
-
如果返回负数:
-
判断 errno 是否为 EINPROGRESS(正在连接),如果是,说明连接建立中。
-
监听该socket,等待出现可写。
可写出现的原因有两种:
- 一个TCP套接字上发生某个错误时,这个待处理错误总是导致该套接字变为既可读又可写。
- connect成功,套接字缓冲区可写。
-
因此,需要调用
getsockopt(sockfd, SOL_SOCKET, SO_ERROR, &error, &len):-
返回-1,说明TCP发生错误,连接失败。
-
返回0,说明没有错误发生,连接成功。
-
-
若connect失败,则该套接字不可再用,必须关闭,重新创建套接字,重复上面步骤以重连。
Connector只负责建立socket连接,不负责创建TcpConnection。connect失败会反复尝试直成功连接。
Connector实现难点:
-
socket是一次性的,一旦出错(比如对方拒绝连接)无法恢复,只能能关闭重来。但Connector是可以反复使用的,需要使用新的fd和新的Channel。
-
错误代码与accept(2)不同,EAGAIN是真的错误,表明本机ephemeral port暂时用完,要关闭socket再延期重试。EINPROGRESS表示正在连接,步骤见上。
-
重试的间隔时间应该逐渐延长,例如0.5s、1s、2s、4s,直至30s,即指数退避back-off。重试使用EventLoop::runAfter定时,为了防止Connector在定时器到时前析构,在Connector的析构函数中要注销定时器。
-
要处理自连接。
在发起连接的时候,TCP/IP协议栈会先选择source IP和source port,在没有显式调用bind(2)的情况下,source IP由路由表确定,source port由TCP/IP协议栈从local port range中选取尚未使用的port(即ephemeral port)。如果destination IP正好是本机,而destination port位于local port range,且没有服务程序监听的话,ephemeral port可能正好选中了destination port,这就出现(source IP,source port)=(destination IP,destination port)的情况,即发生了自连接。处理办法是断开连接再重试,否则原本侦听destination port的服务进程也无法启动了。
TimerQueue::cancel()
本节实现定时器的注销功能。
为了便于取消定时器,使用TimerId区分不同定时器,TimerId只包含Timer*是不够的,因为无法区分地址相同的先后两个Timer对象。因此每个Timer对象有一个全局递增的序列号int64_t sequence_(用原子计数器(AtomicInt64)生成)。
TimerQueue新增以下成员变量来实现取消。
typedef std::pair ActiveTimer;
typedef std::set ActiveTimerSet;
ActiveTimerSet activeTimers_;
bool callingExpiredTimers_; /* atomic */
ActiveTimerSet cancelingTimers_;
activeTimers_和timers_保存相同的数据,只不过timers_是按到期时间排序,方便查找超时的定时器;activeTimers_是按对象地址排序,以便取消定时器时查找删除。
void TimerQueue::cancel(TimerId timerId)
{
loop_->runInLoop(
std::bind(&TimerQueue::cancelInLoop, this, timerId));
}
void TimerQueue::cancelInLoop(TimerId timerId)
{
loop_->assertInLoopThread();
assert(timers_.size() == activeTimers_.size());
ActiveTimer timer(timerId.timer_, timerId.sequence_);
ActiveTimerSet::iterator it = activeTimers_.find(timer);
if (it != activeTimers_.end())
{
size_t n = timers_.erase(Entry(it->first->expiration(), it->first));
assert(n == 1); (void)n; //(void)n;用来防止编译器警告:变量未使用。
delete it->first; // FIXME: no delete please
activeTimers_.erase(it);
}
else if (callingExpiredTimers_)
{
cancelingTimers_.insert(timer);
}
assert(timers_.size() == activeTimers_.size());
}
其中callingExpiredTimers_和cancelingTimers_是为了应对“自注销”这种情况,即在定时器回调中注销当前定时器。当进入定时器回调时,定时器代表的Timer已经不在timers_和activeTimers_这两个容器中,而是位于expired数组中。
void TimerQueue::handleRead()
{
loop_->assertInLoopThread();
Timestamp now(Timestamp::now());
readTimerfd(timerfd_, now);
std::vector expired = getExpired(now);
callingExpiredTimers_ = true;
cancelingTimers_.clear();
// safe to callback outside critical section
for (const Entry& it : expired)
{
it.second->run();
}
callingExpiredTimers_ = false;
reset(expired, now);
}
因此,需要记录下来,在reset的时候删除定时器,并且不再把已cancel()的Timer添加回timers_和activeTimers_当中。
void TimerQueue::reset(const std::vector& expired, Timestamp now)
{
Timestamp nextExpire;
for (const Entry& it : expired)
{
ActiveTimer timer(it.second, it.second->sequence());
if (it.second->repeat()
&& cancelingTimers_.find(timer) == cancelingTimers_.end())
{
it.second->restart(now);
insert(it.second);
}
else
{
// FIXME move to a free list
delete it.second;
}
}
...
8.12 TcpClient
每个TcpClient只管理一个TcpConnection,内部包含一个Connector。要点如下:
-
TcpClient具备TcpConnection 断开重连 的功能,因此客户端和服务端的启动顺序无关紧要。可以先启动客户端,一旦服务端启动,半分钟之内即可恢复连接(由connector::kMaxRetrybelayMs常数控制);在客户端运行期间服务端可以重启,客户端也会自动重连。
实现方法:给TcpConnection注册CloseCallback:如果重连功能开启,并且非主动关闭,Connector重新连接。
-
连接断开后初次重连的延迟应该有随机性,比方说服务端崩溃,它所有的客户连接同时断开,然后0.5s之后同时再次发起连接,可能给服务端带来短期大负载,造成丢包。因此每个TcpClient应该等待一段随机的时间(0.5-2s),再重试,避免拥塞。
-
发起连接的时候如果发生TCP SYN丢包,那么系统默认的重试间隔是3s,这期间不会返回错误码,而且这个间隔似乎不容易修改。如果需要缩短间隔,可以再用一个定时器,在0.5s或1s之后发起另一次连接。如果有需求的话,这个功能可以做到Connector中。
8.13 epoll
epoll(4)是Linux独有的高效的IO多路复用机制,与poll的不同之处在于poll每次返回整个文件的描述符数组,用户代码需要遍历数组以找到哪些文件描述符上面有IO事件,而epoll_wait返回的是活动的fd的列表,需要遍历的数组通常会小很多。在并发连接数大而活动连接比例不高时候,epoll(4)比poll(2)更加高效。
EPoller的关键数据结构如下,其中events_是一次epoll_wait(2)调用返回的活动fd列表,它的大小是自适应的。
typedef std::vector EventList;
int epollfd_;
EventList events_;
struct epoll_event的定义如下,注意epoll_data是个union,muduo使用的是其ptr成员,用于存放Channel*,这样可以减少一步查找。
typedef union epoll_data
{
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event
{
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
}
为了减少转换,muduo Channel没有自己定义IO事件的常量,而是直接使用poll(2)的定义(POLLIN,POLLOUT等等),在Linux中它们和epoll(4)的常量相等。
EPoller::poll()的关键代码如下。events_resize表示如果当前活动fd的数目填满了events_,那么下次就尝试接收更多的活动fd。events_的初始长度是16(kInitEventListsize),其会根据程序的IO繁忙程度自动增长。
Timestamp EPollPoller::poll(int timeoutMs, ChannelList* activeChannels)
{
LOG_TRACE << "fd total count " << channels_.size();
int numEvents = ::epoll_wait(epollfd_,
&*events_.begin(),
static_cast(events_.size()),
timeoutMs);
int savedErrno = errno;
Timestamp now(Timestamp::now());
if (numEvents > 0)
{
LOG_TRACE << numEvents << " events happened";
fillActiveChannels(numEvents, activeChannels);
if (implicit_cast(numEvents) == events_.size())
{
events_.resize(events_.size()*2);
}
}
...
updateChannel()和removeChannel()的代码中Channel::index()和Channel::set_index()被挪用为标记此Channel是否位于epoll的关注列表之中。
本章Acceptor,Connector,Reactor等术语是Douglas Schmidt发明的,出自其论文。
第9章 分布式系统工程实践
9.2 分布式系统的可靠性浅说
9.2.1 分布式系统的软件不要求7x24可靠
高可用的关键不在于做到不停机;恰恰相反,要做到能随时重启任何一个进程或服务。通过容错策略让系统保持整体可用,关键是要设计合理的协议来避免对单机过高的可靠性要求。只要重启或故障转移(failover)的时间足够短(秒级),则可用性仍然相当高。
如果真要7×24连续运行,应该有明确的 t M T B F t_{MTBF} tMTBF指标。对于非性命攸关的系统,在星期天凌晨3点短暂不可用不会有多大影响。
对于分布式系统中的进程来说,考虑到平均一两个月就会有程序版本更新,那么进程能连续运行数星期就可算达标了,软件升级的时候反正还是要重启进程的。
9.2.2 “能随时重启进程”作为程序设计目标
不必区分进程的正常退出与异常终止,程序也不必做到能安全退出,只要能安全被杀即可。这大大简化了多线程服务端编程,我们只需关心正常的业务逻辑,不必为安全退出进程费心。
无论是程序主动调用exit(3)或是被管理员kill(1),进程都能立即重启。这就要求程序只使用操作系统能自动回收的IPC,不使用生命期大于进程的IPC,也不使用无法重建的IPC,具体说,只用TCP为进程间通信的唯一手段,进程一退出,连接与端口自动关闭。而且无论连接的哪一方断连,都可以重建TCP连接,恢复通信。
不要使用跨进程的mutex或semaphore,也不要使用共享内存,因为进程意外终止的话,无法清理资源,特别是无法解锁。另外也不要使用父子进程共享文件描述符的方式来通信(pipe(2)),父进程死了,子进程怎么办?pipe是无法重建的。
如何优雅地重启?对于计划中的重启,一般可以采取以下步骤。
- 先主动停止一个服务进程心跳:
- 对于短连接,关闭listen port,不会有新请求到达。
- 对于长连接,客户会主动failover到备用地址或其他活着的服务端。
- 等一段时间,直到该服务进程没有活动的请求。
- kill并重启进程(通常是新版本)。
- 检查新进程的服务正常与否。
- 依次重启服务端剩余进程,可避免中断服务。
另外一种升级软件的做法是“迁移”。先启动一个新版本的服务进程,然后让旧版本的服务进程停止接受新请求,把所有新请求都导向新进程。这样一段时间之后,旧版本的服务进程上已经没有活动请求,可以直接kill进程,完成迁移和升级。在此升级过程中服务不中断,每个用户不必在意自己是连接到新版本还是旧版本的服务。一些看似不能中断的服务可以采用这种方式升级,因为单个请求的时长总是有限的。
9.3 分布式系统中心跳协议的设计
为什么TCP keepalive不能替代应用层心跳?
心跳除了说明应用程序还活着(进程还在,网络通畅),更重要的是表明应用程序还能正常工作。而TCP keepalive由操作系统负责探查,即便进程死锁或阻塞,操作系统也会如常收发TCP keepalive消息,对方无法得知这一异常。
心跳协议的基本形式是:如果进程C依赖S,那么S应该按固定周期向C发送心跳,而C按固定的周期检查心跳。换言之,通常是服务端向客户端发送心跳。
心跳的检查也很简单,如果Receiver最后一次收到心跳消息的时间与当前时间之差超过某个timeout值,那么就判断对方心跳失效。
如何确定发送周期、检查周期、timeout这三个值?
-
通常Sender的发送周期和Receiver的检查周期相同,均为 T c T_{c} Tc。
-
timeout的选择要能容忍网络消息延时波动和定时器的波动,因此为了避免误报(false alarm),通常可取timeout=2 T c T_{c} Tc。
-
T c T_{c} Tc的选择要平衡两方面因素: T c T_{c} Tc越小,单位时间内的心跳消息越多,开销越大; T c T_{c} Tc越大,Receiver检测到故障的延迟也就越大。在故障延迟敏感的场合,可取Tc=1s,否则可取T= 10s。
总结一下心跳的判断规则:如果最近的心跳消息的接收时间早于now-2 T c T_{c} Tc,可判断心跳失效。
以上是Sender和Receiver直接通过TCP连接发送心跳的做法,如果Sender和Receiver之间有其他消息中转进程,那么还应该在心跳消息中加上Sender的发送时间,防止消息在传输过程中堆积而导致假心跳。相应的判断规则改为:如果最近的心跳消息的发送时间早于now-2 T c T_{c} Tc,心跳失效。使用这种方式时,两台机器的时间应该都通过NTP协议与时间服务器同步。
考虑到闰秒的影响, T c T_{c} Tc小于1秒是无意义的,因为闰秒会让两台机器的相对时差发生跳变,可能造成误报警。
心跳协议还有两个实现上的关键点:
- 要在工作线程发送,不要单独起一个“心跳线程"。
- 与业务消息用同一个连接,不要单独用“心跳连接”。
这么做的原因是为了防止伪心跳。
-
对于第1点,这是防止工作线程死锁或阻塞时还在继续发心跳。对于muduo单线程TcpServer,应该用EventLoop::runEvery()注册周期性定时器回调,在回调函数中发送心跳消息。对于多线程TcpServer也采取类似的办法,并且对多个EventLoop轮流调用runInLoop(),以防止某个业务线程死锁还继续发送心跳。
-
对于第2点,心跳消息的作用之一是验证网络畅通,如果它验证的不是收发业务数据的TCP连接畅通,那其意义就大为缩水了。特别要避免用TCP做业务连接,用UDP发送心跳消息,防止一旦TCP业务连接上出现消息堆积而影响正常业务处理时,程序还一如既往地发送UDP心跳,造成客户端误认为服务可用。
9.4 分布式系统中的进程标识
本文讨论的是,如何为一个程序每次运行的进程取一个唯一标识符gpid(global pid)?
9.4.1 错误做法
-
如果进程本身是无状态的,或者重启了也没有关系,那么用ip:port来标识一个“服务”是没问题的。但对于有状态的进程不行。
-
host:pid也不可以,因为pid会轮回。
9.4.2 正确做法
正确做法:以四元组ip:port:start time:pid作为分布式系统中进程的gpid,其中start time是64-bit整数,表示进程的启动时刻(UTC时区,从Unix Epoch到现在的微秒数)。
- 容易保证唯一性。如果程序短时间重启,那么两个进程的pid必定不重复;如果程序运行了相当长一段时间再重启,那么两次启动的starttime必定不重复。
- 产生这种gpid的成本很低(几次低成本系统调用)。
- gpid本身有意义,根据gpid立刻就能知道是什么进程(port),运行在哪台机器(IP),是什么时间启动的,在/proc目录中的位置(/proc/pid)等,进程的资源使用情况也可以通过运行在那台机器上的监控程序报告出来。
- gpid具有历史意义,便于将来追溯。
进一步,还可以把程序的名称和版本号作为gpid的一部分,这起到锦上添花的作用。
有了唯一的gpid,那么生成全局唯一的消息id字符串也十分简单,只要在进程内使用一个原子计数器,用计数器递增的值和gpid即可组成每个消息的全局唯一id。
9.5 构建易于维护的分布式程序
分布式系统中的每个长期运行的、会与其他机器打交道的进程都应该提供一个管理接口,对外提供一个维修探查通道,可以查看进程的全部状态。一种具体的做法是在程序里内置HTTP服务器,能查看基本的进程健康状态与当前负载,包括活动连接及其用途,能从root set开始查到每一个业务对象的状态。这种做法类似Java的JMX,又类似memcached的stats命令。
9.6 为系统演化做准备
9.6.1 可扩展的消息格式
错误做法
-
可扩展消息格式的第一条原则是避免协议的版本号,否则代码里会有一堆堆难以维护的switch-case。
-
另一种常见错误是通过TCP连接发送C struct或使用bit fields。
不是这样的,C struct和bit fields的缺点很多。
- 其一是不易升级。如果在C struct里新加了一些元素,通常要求客户端和服务端一起升级,否则就语言不通了。
- 其二是不跨语言。
解决办法
采用某种中间语言来描述消息格式(schema),然后生成不同语言的解析与打包代码。如果用文本格式,可以考虑JSON或XML;如果用二进制格式,可以考虑Google Protocol Buffers。
Google Protobuf是结构化的二进制消息格式,兼顾性能与可扩展性。
这种“中间语言”或者叫“数据描述语言”定义的消息格式可以有可选字段(optional fields),一举解决了服务端和客户端升级的难题。新版的服务端可以定义一些optional fields,根据请求中这些字段的存在与否来实施不同的行为,即可同时兼容旧版和新版的客户端。给每个field赋终生不变的id是保证兼容性的绝招,Google Protobuf的文档强调在升级proto文件时要注意:
- you must not change the tag numbers of any existing fields.
- you must not add or delete any required fields.
PNG文件给我们很好的启示。PNG是一种精心设计的二进制文件格式,文件由一系列数据块(chunks)组成,每个数据块的前4个字节表示该数据块的长度,接下来的4个字节代表该数据块的类型。PNG的解译程序会忽略那些自己不认识的数据块,因此PNG文件没有版本之说,不存在前后版本不兼容的问题。
9.7 分布式程序的自动化回归测试
自动化测试的作用是把程序已经实现的features 以test case的形式固化下来,将来任何代码改动如果破坏了现有的功能需求就会触发测试failure。
第10章 C++编译链接模型精要
C++语言的三大约束是:与C兼容、零开销(zero overhead)原则、值语义。
为了兼容C语言,C++付出了很大的代价。例如要兼容C语言的隐式类型转换规则(例如整数类型提升),这让C++的函数重载决议resolution)规则变得无比复杂。
10.1 C语言的编译模型及其成因
10.1.1 为什么C语言需要预处理
由于早期的计算机的内存空间很小,没办法在内存里完整地表示单个源文件的抽象语法树,更不能把整个程序(有多个源文件组成)放到内存中,以完成交叉引用。由于内存的限制,编译器必须要能分别编译多个源文件,生成多个目标文件,再设法将这些目标文件链接成一个可执行文件。
为了能在尽量减少内存使用的情况下实现分离编译,C语言采用了“隐式函数声明” 的做法。代码在使用前文未定义的函数时,编译器不需要也不检查函数的原型:既不检查参数个数,也不检查参数类型以及返回值类型 。编译器认为为声明的函数都返回int , 并且能接受任意个数的 int 型参数。实际上,C语言使用某个没有定义的函数,那么实际造成的是链接错误,而非编译错误。
那么为什么还需要头文件和预处理呢?
头文件和预处理的最大的好处是:将公共信息做成头文件,然后程序包含用到的头文件即可。可以减少无畏的错误,提高代码的可移植性。
10.1.2 C语言的编译模型
由于不能将整个源文件的语法树保存在内存中,C语言其实是按照“单遍编译” 来设计的。单遍编译指的是从头到尾扫描一遍源码,一边解析代码,一边即刻生成目标代码。在单遍编译时,编译器只能看到目前已经解析过的代码,看不到之后的代码。这意味着:
- C语言要求结构体必须先定义,才能访问其成员,否则编译器不知道结构体成员的类型和偏移量,就无法即刻生成目标代码。
- 局部变量也必须先定义再使用,因为如果定义放在后面,编译器再第一次看到一个局部变量时候,并不知道它的类型和在stack中的位置,也就无法立刻生成代码,只能报错退出。
- 为了方便编译器分配stack空间,C语言要求局部变量只能在语句块的开始处定义。
- 对于外部变量,编译器只需要知道它的类型和名字,不需要知道它的地址,因此需要先声明后使用。外部变量的地址是空白的,留给链接器去补起来。
- 当编译器看到一个函数调用时,按隐式函数声明规则,编译器可以立刻生成调用函数的汇编代码(函数参数入栈,调用,获取返回值),唯一不确定的是被调用函数的地址,编译器可以留下一个空白给链接器去填补。
10.2 C++的编译模型
由于要保持与C兼容,原本很多在C语言中顺理成章或者危害不大的东西继承到了C++里就成了大祸害。
C++也继承了单遍编译。在单遍编译时,编译器只能根据目前看到的代码做出决策,读到后面的代码也不会影响前面做出的决定。这特别影响了名字查找(name lookup)和函数重载决议。(C语言没有函数重载)
-
名字查找
C++中的名字包括类型名、函数名、变量名、typedef名、template名等等。
C++只能通过解析源码来了解名字的含义,不能像其他语言那样通过直接读取目标代码中的元数据来获得所需信息(函数原型、class类型定义等等)。
C++编译器的符号表至少要保存目前已看到的每个名字的含义,包括class 的成员定义、已声明的变量、已知的函数原型等,才能正确解析源代码。还没有考虑template,编译template 的难度超乎想象。
-
函数重载决议
当C++编译器读到一个函数调用语句时,它必须(也只能)从目前已看到的同名函数中选出最佳函数。哪怕后面的代码中出现了更合适的匹配,也不能影响当前的决定。
其实由于C++新增了不少语言特性,C++编译器并不能真正做到像C那样过眼即忘的单遍编译。但是C++必须兼容C的语意,因此编译器不得不装得好像是单遍编译(准确地说是单遍parse)一样,哪怕它内部是multiple pass的,比如前向声明。
10.2.2 前向声明
几乎每份C++编码规范都会建议尽量使用前向声明来减少编译期依赖。
对于class Foo,以下几种使用不需要看见其完整定义:
- 定义或声明Foox和Foo&,包括用于函数参数、返回类型、局部变量、类成员变量等等。这是因为C++的内存模型是flat的,Foo的定义无法改变Foo的指针或引用的含义。
- 声明一个以Foo为参数或返回类型的函数,如Foo bar()或void bar(Foo f),但是,如果代码里调用这个函数就需要知道Foo的定义,因为编译器要使用Foo的拷贝构造函数和析构函数,因此至少要看到它们的声明(虽然构造函数没有参数,但是有可能位于private区)。
[CCS]第30条规定不能重载&、||、,(逗号)这三个操作符,Google的C++编程规范补充规定不能重载一元operator&(取址操作符),因为一旦重载operator&,这个class的就不能用前向声明了。例如:
class Foo; //前向声明
void bar(Foo& foo) {
Foo* p = &foo; //这句话是取foo的地址,但是如果重载了&,意思就变了。
}
10.3 C++链接(Linking)
使用one pass链接器时要注意参数顺序(gcc/g++),被依赖的库放在后面,拓扑排序。这样保证每个未决符号都可以在后面出现的库中找到。比如A,B两个彼此独立的库同时依赖C库,那么链接的顺序是ABC或BAC。
原因
为什么这个规定不是反过来,先列出基础库,再列出应用库呢?原因是前一种做法的内存消耗要小得多。如果先处理基础库,链接器不知道库里哪些符号会被后面的代码用到,因此只能每一个都记住,链接器的内存消耗跟所有库的大小之和成正比。反过来,如果先处理应用库,那么只需要记住目前尚未查到定义的符号就行了。链接器的内存消耗跟程序中外部符号的多少成正比(而且一旦填上空白,就可以忘掉它)。
C++的链接模型与C相比主要增加了两项内容:
- 函数重载,需要类型安全的链接,即name mangling。
- vague linkage ,即同一个符号有多份互不冲突的定义。
name mangling的事情一般不需要程序员操心,只要掌握extern"C"的用法,能和C程序库交互就行。何况现在一般的C语言库的头文件都会适当使用extern"C",使之也能用于C++程序。
extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言(而不是C++)的方式进行编译。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般只包括函数名。
C语言通常一个符号在程序中只能有一处定义,否则就会造成重复定义。C++则不同,编译器在处理单个源文件的时候并不知道某些符号是否应该在本编译单元定义。为了保险起见,只能每个目标文件生成一份“弱定义”,而依赖链接器去选择一份作为最终的定义,这就是vague linkage。
10.3.1 函数重载
为了实现函数重载,C++ 编译器采用名字改编(name mangling),为每个重载函数生成独一无二的名字,这样在链接的时候就能找到正确的函数重载版本。注意,普通的非模板函数的name mangling 不包含返回类型,因为返回类型不参与函数重载。
c++filt命令可以输出改编过的名字的原名。
10.3.2 inline函数
外部链接:如果一个名称对编译单元来说不是局部的,而在链接的时候其他的编译单元可以访问它,也就是说它可以和别的编译单元交互。
内部链接:如果一个名称对编译单元来说是局部的,在链接的时候其他编译单元无法链接到它且不会与其他编译单元中的同样名称相冲突。
在C++中具有内部链接属性的有:static的全局变量,枚举类型的定义,类的定义,内联函数的定义,union的定义,名字空间中const定义。(注意:在函数体外定义:const char* p = “xx”; p是外部连接的,因为const没有修饰p)
现在的编译器聪明到可以判断一个函数是否适合inline,因此inline关键字在源文件中往往不是必需的。在头文件中还是需要inline 的,为了防止链接器报怨重复定义。
现在的C++ 编译器采用重复代码消除的办法来避免重复定义。也就是说,如果编译器无法inline 展开的话,每个编译单元都会生成inline 函数的目标代码,然后链接器会从多份实现中任选一份保留,其余的则丢弃( vague linkage)。如果编译器能够展开inline 函数,那么就不用单独为之生成目标代码(除非使用函数指针指向它)。
如何判断一个C++可执行文件是debug build还是release build?换言之,如何判断一个可执行文件是-00编译还是-02编译?我通常的做法是看class template的短成员函数有没有被inline展开。(使用nm命令查看符号表内是否有该函数)
注意,编译器为我们自动生成的class析构函数也是inline函数,有时候我们要故意out-of-line,防止代码膨胀或出现编译错误。
out-of-line是inline的反义词,指将类的成员函数实现放在源文件中,而不是直接在头文件的类中。
在现代的C++系统中,编译和链接的界限更加模糊了。传统C++教材告诉我们,要想编译器能够inline一个函数,那么这个函数体必须在当前编译单元可见。因此我们通常把公共inline函数放到头文件中。现在有了link time code generation,编译器不需要看到inline函数的定义,inline可以留给链接器去做。
link time code generation:
传统的编译模式(词法解析-〉代码生成-〉链接),决定了在生成代码时,编译器只能看到同一个obj文件的内容,因此,优化也只能在obj文件里进行。而LTCG的引入,则颠覆了这种模式,将链接器提前到代码生成之前,并由之来调用代码生成。这样,在生成代码的时候,编译器便不太容易受到obj文件边界的限制。此时,有些函数,虽然没有被标上inline,却被编译器自动inline了。 LTCG让优化更加彻底,一般编译器Release模式(-O2优化)自动开启LTCG。
编译单元:一个obj文件就是一个编译单元。
10.3.3 模板
template和inline函数会不会导致代码膨胀
假设有一个定长Buffer类,其内置buffer长度是在编译期确定的,我们可以把它实现为非类型类模板:
template
class Buffer
{
public:
Buffer() : index_(0) {}
void append(const char* buf, size_t len)
{
memcpy(data_ + index_, data_, len);
index_ += len;
}
//other members
private:
char data_[SIZE];
int index_;
};
当其以不同SIZE被分别具现两次时,编译器会为每一个用到的类模板成员函数具现化份实体。造成代码膨胀。
但是开启-O2编译时,编译器会把这些段函数全部inline展开,实际上并没有出现类。
限制模板的具现化 / 隐藏模板实现
一般的C++教材会告诉你,模板的定义要放到头文件中,否则会有编译错误。如果读者足够细心,会发现其实所谓的“编译错误”是链接错误。
知道模板会有哪些具现化类型,并事先显式(或隐式)具现化出来。就可以把模板的实现放到库里,头文件里只放声明。
由此,可以限制模板的具现化,比方说限制Buffer只能有64,256,1024,4096这几个长度;同时,将实现隐藏起来。
//buffer.h
template
class Buffer
{
public:
Buffer() : index_(0) {}
void append(const char* buf, size_t len);
private:
char data_[SIZE];
int index_;
};
//buffer.cpp
#include "buffer.h"
#include
template
void Buffer::append(const char* buf, size_t len)
{
int x = 10;
while (--x) {
memcpy(data_ + index_, data_, len);
index_ += len;
}
}
void f() {
Buffer<256>().append("1", 1);
}
//main.cpp
#include "buffer.h"
int main() {
Buffer<256> b1;
b1.append("1", 1);
return 1;
}
对于通用(universal)的模板库,这个办法是行不通的,因为你不可能事先知道客户会用哪些参数类型来具现化你的模板(比方说vector)
但是对于某些特殊情况,这可以减少代码膨胀,比方说把Buffer的构造函数从头文件移到某个源文件,并且只具现化几个固定的长度,这样防止客户代码任意具现化Buffer模板。
对于private成员函数模板,我们也不用在头文件中给出定义,因为用户代码不能调用它,也就无法随意具现化它,所以不会造成链接错误。
另外,C++11新增了extern template特性,可以阻止隐式模板具现化。g++的C++标准库就使用了这个办法,使得使用std::string和std::iostream的代码不受代码膨胀之苦。
《C++Primer》16.1.5
在大系统中,在多个文件中实例化相同模板的额外开销可能非常严重。在新标准中,我们可以通过显式实例化(explicit instantiation)来避免这种开销。一个显式实例化有如下形式:
extern template declaration; //实例化声明 template declaration; //实例化定义declaration是一个类或函数声明,其中所有模板参数已被替换为模板实参。例如,
extern template class Blob;//声明 template int compare(const int&, const int&);//定义 当编译器遇到extern模板声明时,它不会在本文件中生成实例化代码。将一个实例化声明为extern就表示承诺在程序其他位置有该实例化的一个非extern声明(定义)。对于一个给定的实例化版本,可能有多个extern声明,但必须只有一个定义。
10.3.4 虚函数
在现在的C++实现中,虚函数的动态调用(动态绑定、运行期决议)是通过虚函数表(vtable)进行的,每个多态class都应该有一份vtable。定义或继承了虚函数的对象中会有一个隐含成员:指向vtable的指针,即vptr。
如果一个类在头文件中定义并具有一个vtable(它具有虚函数或它派生自具有虚函数的基类),则该类中必须始终至少有一个out-of-line虚函数。否则,编译器会将vtable和RTTI复制到包含该头文件的每个.o文件中,造成代码膨胀,减慢编译时间。(转自https://llvm.org/docs/CodingStandards.html#ll_virtual_anch)
因为C++编译器有时无法判断是否应该在当前编译单元生成vtable定义,为了保险起见,只能每个编译单元都生成vtable,交给链接器去消除重复数据。
10.4 共程项目中头文件的使用规则
一旦为了使用某个struct 或者 某个库函数而包含一个头文件,那么这个头文件中定义的其他名字也被引入当前编译单元,可能会引起错误。
10.4.1 头文件的害处
头文件的害处主要体现在以下几方面:
- 传递性。头文件可以再包含其他头文件。
- 顺序性。一个源文件可以包含多个头文件,如果头文件内容组织不当,会造成程序的语义与头文件包含顺序有关,也与是否包含某一个头文件有关。通常的做法是把头文件分为几类(例如分为C语言系统头文件、C++标准库头文件、C++第三方库头文件、本公司的基础库头文件、本项目的头文件),然后分别按顺序包含这几类头文件(比如从一般到特殊),相同类的头文件按文件名的字母排序。这样一方面源代码比较整洁;另一方面如果两个人同时修改源码,各自想多包含一个头文件,那么造成冲突的可能性较小。一般应该避免每次在#include列表的末尾添加新的头文件,这样很快代码的依赖关系就无法管理了。
- 差异性。内容差异造成不同源文件看到的头文件不一致,时间差异造成头文件与库文件内容不一致。如果两个源文件编译时的宏定义选项不一致,可能造成二进制代码不兼容。这说明整个程序应该用统一的编译选项,如果程序用到了第三方静态库或者动态库,除了拿到头文件和库文件,我们还要拿到当时编译这个库的编译选项,才能安全无误地使用这个程序库。如果程序用到了两个库,但是它们的编译选项有冲突,那麻烦就大了。
反观现代的编程语言,它们比C++的历史包袱轻多了,模块化做得也比较好。模块化的做法主要有两种:
- 对于解释型语言,import的时候直接把对应模块的源文件解析(parse)一遍(不再是简单地把源文件包含进来)。
- 对于编译型语言,编译出来的目标文件(例如Java的.class文件)里直接包含了足够的元数据,import的时候只需要读目标文件的内容,不需要读源文件。
这两种做法都避免了声明与定义不一致的问题,因为在这些语言里声明与定义是一体的。同时这种import手法也不会引入不想要的名字,大大简化了名字查找的负担(无论是人脑还是编译器),也不用担心import的顺序不同造成代码功能变化。
10.4.2 头文件的使用规则
几乎每个C++编程规范都会涉及头文件的组织。归纳起来观点如下:
-
“将文件间的编译依赖降至最小。"
使用前置声明:使用指针和引用,定义尽量放在源文件;Pimpl惯用……
在类中定义引用变量, 必须要在初始化列表中初始化该成员变量(const 类型数据成员也必须在初始化列表中进行初始化)。
-
“将定义式之间的依赖关系降至最小。避免循环依赖。"
示例:
class Parent { Child* mychild; }; class Child { Parent* myParent; };两个类不再是独立的,而是相互依赖的。为了打破循环,可以使用“依赖倒置原理”:不要让高层模块依赖于底层模块;相反,应该让两者都依赖于抽象。如果能为parent或child定义独立的抽象类,那么就能够打破循环了。
-
“让class名字、头文件名字、源文件名字直接相关。”这样方便源代码的定位。
-
“令头文件自给自足。”
应该确保所编写的每个头文件都能够独自进行编译,为此需要包含其内容所依赖的所有头文件。如果一个文件包含某个头文件时,还要包含另一个头文件才能工作,就会增加交流障碍,给头文件的用户增添不必要的负担。
-
“总是在头文件内写内部#include guard(护套),不要在源文件写外部护套。”这是因为现在的预处理对这种通用做法有特别的优化,GNU cpp在第二次#include同一个头文件时甚至不会去读这个文件,而是直接跳过。
-
#include guard用的宏的名字应该包含文件的路径全名(从版本管理器的角度),必要的话还要加上项目名称(如果每个项目有自己的代码仓库)。
-
如果编写程序库,那么公开的头文件应该表达模块的接口,必要的时候可以把实现细节放到内部头文件中。
这里介绍一个查找头文件包含途径的小技巧。比方说有一个程序只包含了std::string,我想知道

10.5 程项目中库文件的组织原则
改动程序本身或它依赖的库之后应该重新测试,否则测试通过的版本和实际运行的版本根本就是两个东西。一旦出了问题,责任就难理清了。
C++标准库的版本跟C++编译器直接关联,我想一般不会有人去替换系统的libstdc++。C标准库的版本跟Linux操作系统的版本直接相关,一般也不会有人单独升级glibc,因为这基本上意味着需要重新编译用户态的所有代码。
一旦选定了生产环境中操作系统的版本,另外三样东西的版本(Kernel、gcc、glibc)就确定了。
一个C++库的发布方式有三种:动态库(.so)、静态库(.a)、源码库(.cc)。下表简单终结了一些基本特性。

无论哪种方式,我们都必须保证应用程序之间的独立性,也就是让动态库的多个大版本能够并存。
10.5.1 动态库的缺点
动态库适合热修复。
一旦替换了某个应用程序用到的动态库,先前运行正常的这个程序使用的将不再是当初build和测试时的代码。结果是程序的行为变得不可预期。
不可能在fix bug和增加feature的同时,还能保证不会损坏现有的应用程序。
因此,动态库更新之前需要做充分测试。比如,把动态库的更新先发布到QA环境,正常运行一段时间之后再发布到生产环境。
10.5.2 静态库的缺点
静态库相比动态库主要有几点好处:
- 依赖管理在编译期决定,不用担心日后它用的库会变。同理,调试core dump不会遇到库更新导致debug符号失效的情况。
- 运行速度可能更快,因为没有PLT(过程查找表),函数调用的开销更小。
- 发布方便,只要把单个可执行文件拷贝到模板机器上。
静态库的一个小缺点是链接比动态库慢,比动态库耗内存(不是很重要)。
使用静态库时会有一个编译的时间差:编译库文件比编译可执行文件要早,这就可能造成编译应用程序时看到的头文件与编译静态库时不一样。
比方说编译net 1.1时用的是boost 1.34,但是编译xyz这个应用程序的时候用的是boost 1.40,见图10-6,这种不一致有可能导致编译错误,或者更糟糕地导致不可预期的运行错误。

这说明应用程序在使用静态库的时候必须要采用完全相同的开发环境(更底层的库、编译器版本、编译器选项)。
10.5.3 源码编译最优
每个应用程序自己选择要用到的库,并自行编译为单个可执行文件。彻底避免头文件与库文件之间的时间差,确保整个项目的源文件采用相同的编译选项,也不用为库的版本搭配操心。这么做的缺点是编译时间很长,因为把各个库的编译任务从库文件的作者转嫁到了每个应用程序的作者。
另外,最好能和源码版本工具配合,让应用程序只需指定用哪个库,build工具能自动帮我们check out库的源码。这样库的作者只需要维护少数几个branch,发布库的时候不需要把头文件和库文件打包供人下载,只要push到特定的branch就行。而且这个build工具最好还能解析库的Makefile(或等价的build script),自动帮我们解决库的传递性依赖,就像Apache Ivy能做的那样。
在目前看到的开源build工具里,最接近这一点的是Chromium的gyp和腾讯的typhoon-blade,其他如SCons,CMake,Premake,Waf等等工具仍然是以库的思路来搭建项目。
第11章 反思C++面向对象与虚函数
在C++中进行面向对象编程会遇到其他语言中不存在的问题,其本质原因是C++ class是值语义,而非对象语义。
11.1 朴实的C++设计
应用程序的原则是,可以有特别简单的类,但不宜有特别复杂的类,更不能有“大怪兽”。一个类太大,我们就看看能不能把它拆成两个,把责任分开。两个类有共同的代码逻辑,我们会考虑提炼出一个工具类来用。
11.2 程序库的二进制兼容性
C/C++的二进制兼容性(binary compatibility)有多重含义,本文主要在“库文件单独升级,现有可执行文件是否受影响”这个意义下讨论,我称之为library(主要是shared library,即动态链接库)的ABI(application binary interface)。
11.2.1 什么是二进制兼容性
如果以动态库方式提供函数库,那么头文件和库文件不能轻易修改,否则容易破坏已有的二进制可执行文件,或者其他用到这个shared library 的library。
本章所指的“二进制兼容性”是在升级(也可能是bug fix)库文件的时候,不必重新编译使用了这个库的可执行文件或其他库文件,并且程序的功能不被破坏。
换句话说,新版本的库文件,兼容旧版本的用户可执行文件。
11.2.2 有哪些情况会破坏库的ABI
ABI: Application Binary Interface,ABI是二进制层面的接口,包含了应用程序在这个系统下运行时必须遵守的编程约定,比如符号修饰标准,变量内存布局,函数调用方式等等跟可执行代码二进制兼容性相关的内容。终极目标是程序能够在不经任何修改的情况下得到重用。
到底如何判断一个改动是不是二进制兼容呢?这跟C++的实现方式直接相关,虽然C++标准没有规定C++的ABI,但是几乎所有主流平台都有明文或事实上的ABI标准,比方说ARM有EABI。x86是个例外,它只有事实上的ABI,比如Windows就是Visual C++,Linux是G++(G++的ABI还有多个版本,目前最新的是G++ 8.1的版本),Intel的C++编译器也得按照Visual C++或G++的ABI来生成代码,否则就不能与系统的其他部件兼容。
C++编译器ABI的主要内容包括以下几个方面:
- 函数参数传递的方式,比如x86-64用寄存器来传函数的前4个整数参数;
- 虚函数的调用方式,通常是vptr/vtbl机制,然后用vtb[offset]来调用;
- struct和class的内存布局,通过偏移量来访问数据成员;
- name mangling;
- RTTI和异常处理的实现(以下本文不考虑异常处理)。
如何判断一个改动是不是二进制兼容,主要就是看头文件暴露的“使用方法”(主要是函数调用和对象布局)能否与新版本的动态库的实际使用方法兼容。因为新的库必然有新的头文件,但是现有的二进制可执行文件还是按旧的头文件中的“使用说明”来调用动态库。
源代码兼容但是二进制代码不兼容的例子:
- 给函数增加默认参数,现有的可执行文件无法传这个额外的参数。
- 增加虚函数,会造成vtbl里的排列变化。(不要考虑“只在末尾增加”这种取巧行为,因为你的class可能已被继承。)
- 增加默认模板类型参数,比方说
Foo改为Foo,这会改变name mangling。 - 改变enum的值,把enum color { Red =3 };改为Red =4。这会造成错位。当然,由于enum自动排列取值,添加enum项也是不安全的(在末尾添加除外)。
给class Bar增加数据成员,造成sizeof(Bar)变大,以及内部数据成员的offset变化,这是不是安全的?通常不是安全的,但也有例外。
-
如果客户代码里有new Bar,那么肯定不安全,因为new的字节数不够装下新Bar对象。相反,如果library通过factory返回Bar*(并通过factory来销毁对象)或者直接返回
shared_ptr,客户端不需要用到sizeof(Bar),那么可能是安全的。 -
如果客户代码里有
Bar* pBar; pBar->memberA =xx;,那么肯定不安全,因为memberA的新Bar的偏移可能会变。相反,如果只通过成员函数来访问对象的数据成员,客户端不需要用到data member的offsets,那么可能是安全的。 -
如果客户调用
pBar->setMemberA(xx);,而Bar::setMemberA()是个inline function,那么肯定不安全,因为偏移量已经被inline到客户的二进制代码里了。如果setMemberA()是outline function,其实现位于shared library中,会随着Bar的更新而更新,那么可能是安全的。
另外,Windows下,Visual C++编译的时候要选择Release或Debug模式,而且Debug模式编译出来的library通常不能在Release binary中使用(反之亦然),这也是因为两种模式下的CRT二进制不兼容(主要是内存分配方面,Debug有自己的簿记(bookkeeping)),Linux就没有这个麻烦,可以混用。
header-only库文件
Header Only Library把一个库的内容完全写在头文件中,不带任何cpp文件。
优点是:
- 用户不需要分离编译、打包、安装,只需要#include头文件即可。
- 编译器能做更深入的优化。
缺点是:
- 脆弱性,库中大部分改变都导致需要重新编译。
- 更长的编译时间。
- 代码膨胀(这一条有争议),主要是inline语句导致的。
11.2.5 解决办法
采用静态链接
这里的静态链接不是指使用静态库(.a),而是指完全从源码编译出可执行文件。
用pimpl惯用法,编译器防火墙
在头文件中只暴露non-virtual接口,并且class的大小固定为sizeof(Impl*) ,这样可以随意更新库文件而不影响可执行文件。具体做法见Chapter11.4。
11.3 避免使用虚函数作为库的接口
11.3.1 C++程序库的作者的生存环境
写一个 C++ library,那么通常要做以下几个决策:
- 以什么方式发布?动态库还是静态库?(源代码发布和静态库类似)
- 如果选用动态库,以什么方式暴露库的接口?可选的做法有:以全局(含 namespace 级别)函数为接口、以 class 的 non-virtual 成员函数为接口、以 virtual 函数为接口(interface)。
需要考虑:
- 代码会有 bug,库也不例外。将来可能会发布 bug fixes。
- 会有新的功能需求。
第一个决定很好做,如果需要 hot fix,那么只能用动态库;否则,在分布式系统中使用静态库更容易部署。(忽略内存优势)
第二个决定不是那么容易做,关键问题是,要选择一种可扩展的 (extensible) 接口风格,让库的升级变得更轻松。“升级”有两层意思:
- 对于 bug fix only 的升级,二进制库文件的替换应该兼容现有的二进制可执行文件。
- 对于新增功能的升级,应该对客户代码友好。升级库之后,客户端使用新功能的代价应该比较小。只需要包含新的头文件(这一步都可以省略,如果新功能已经加入原有的头文件中),然后编写新代码即可。
1.3.3 虚函数作为接口的弊端
如果不考虑升级,虚函数作为接口没问题。
但如果动态库升级,添加了新的虚函数,那么新版本的动态库可能不兼容旧版本可执行文件(非二进制兼容)。
其本质问题在于 C++ 以 vtable[offset] 方式实现虚函数调用,而 offset 又是根据虚函数声明的位置隐式确定的,这造成了脆弱性。新的虚函数可能会造成 vtable 的排列发生了变化。即便把新的虚函数放在末尾,也很危险,因为类如果被继承,派生类中的offset会受影响。
11.4 动态库接口的推荐做法
取决于动态库的使用范围,有两类做法。
- 如果动态库的使用范围比较窄,比如本团队内部的两三个程序在用,用户都是受控的,要发布新版本也比较容易协调,那么不用太费事,只要做好发布的版本管理就行了。再在可执行文件中使用 rpath 把库的完整路径确定下来。
- 如果库的使用范围很广,用户很多,那么推荐使用pimpl惯用法。并考虑多采用 non-member non-friend function in namespace作为接口。
演示:
-
暴露的接口里边不要有虚函数,而且 sizeof(Graphics) == sizeof(Graphics::Impl*)。
class Graphics { public: Graphics(); // outline ctor ~Graphics(); // outline dtor void drawLine(int x0, int y0, int x1, int y1); void drawLine(Point p0, Point p1); void drawRectangle(int x0, int y0, int x1, int y1); void drawRectangle(Point p0, Point p1); void drawArc(int x, int y, int r); void drawArc(Point p, int r); private: class Impl; unique_ptrimpl; }; -
在库的实现中把调用转发 (forward) 给实现 Graphics::Impl ,这部分代码位于 .so/.dll 中,随库的升级一起变化。
#includeclass Graphics::Impl { public: void drawLine(int x0, int y0, int x1, int y1); void drawLine(Point p0, Point p1); void drawRectangle(int x0, int y0, int x1, int y1); void drawRectangle(Point p0, Point p1); void drawArc(int x, int y, int r); void drawArc(Point p, int r); }; Graphics::Graphics() : impl(new Impl) { } Graphics::~Graphics() { } void Graphics::drawLine(int x0, int y0, int x1, int y1) { impl->drawLine(x0, y0, x1, y1); } void Graphics::drawLine(Point p0, Point p1) { impl->drawLine(p0, p1); } -
如果要加入新的功能,不必通过继承来扩展,可以原地修改,且保持二进制兼容性。先动头文件:
class Graphics { public: Graphics(); // outline ctor ~Graphics(); // outline dtor void drawLine(int x0, int y0, int x1, int y1); + void drawLine(double x0, double y0, double x1, double y1); void drawLine(Point p0, Point p1); void drawRectangle(int x0, int y0, int x1, int y1); + void drawRectangle(double x0, double y0, double x1, double y1); void drawRectangle(Point p0, Point p1); void drawArc(int x, int y, int r); + void drawArc(double x, double y, double r); void drawArc(Point p, int r); private: class Impl; unique_ptrimpl; }; 然后在实现文件里增加 forward,这么做不会破坏二进制兼容性,因为增加 non-virtual 函数不影响现有的可执行文件。
#includeclass Graphics::Impl { public: void drawLine(int x0, int y0, int x1, int y1); + void drawLine(double x0, double y0, double x1, double y1); void drawLine(Point p0, Point p1); void drawRectangle(int x0, int y0, int x1, int y1); + void drawRectangle(double x0, double y0, double x1, double y1); void drawRectangle(Point p0, Point p1); void drawArc(int x, int y, int r); + void drawArc(double x, double y, double r); void drawArc(Point p, int r); }; Graphics::Graphics() : impl(new Impl) { } Graphics::~Graphics() { } void Graphics::drawLine(int x0, int y0, int x1, int y1) { impl->drawLine(x0, y0, x1, y1); } +void Graphics::drawLine(double x0, double y0, double x1, double y1) +{ + impl->drawLine(x0, y0, x1, y1); +} + void Graphics::drawLine(Point p0, Point p1) { impl->drawLine(p0, p1); }
采用 pimpl 多了一道 forward 的手续,带来的好处是可扩展性与二进制兼容性,通常是划算的。pimpl 扮演了编译防火墙的作用。
为什么 non-virtual 函数比 virtual 函数更健壮?因为 virtual function 是 bind-by-vtable-offset,而 non-virtual function 是 bind-by-name。加载器 (loader) 会在程序启动时做决议(resolution),通过 mangled name 把可执行文件和动态库链接到一起。就像使用 Internet 域名比使用 IP 地址更能适应变化一样。
本文只谈了使用 class 为接口,其实用 free function 有时候更好。
11.5 std::function和std::bind VS 虚函数
继承多态的缺点:
- 如果有一棵类型继承树(class hierarchy),人们在一开始设计时就得考虑各个class在树上的位置。随着时间的推衍,原来正确的决定有可能变成错误的。但是更正这个错误的代价可能很高,牵一发而动全身。继承的耦合性太强。
- 由于C++的动态绑定只能通过指针和引用实现。在C++这种非GC语言中,使用虚函数作为事件回调接口有其本质困难,即如何管理派生类对象的生命期。
std::function和std::bind/lambda 一般可以代替虚函数,缺点客户使用比较繁琐。
12.7 再探std::string
std::string有多种实现方式,归纳起来有三类,而每类又有多种变化。
- 无特殊处理(eager copy),采用类似std::vector的数据结构。现在很少有实现采用这种方式。
- Copy-on-Write (COW),写时复制。
- 短字符串优化(SSO),利用string对象本身的空间来存储短字符串。g++、Visual C++用的是这种实现方式。
12.7.1 直接拷贝(eager copy)
最朴素的做法:
class string {
public:
const_pointer data() const { return start; }
iterator begin() { return start; }
iterator end() { return start + size_; }
size_type size() const { return size_; }
size_type capacity() const { return capacity_; }
private:
char* start;
size_t size_;
size_t capacity_;
};
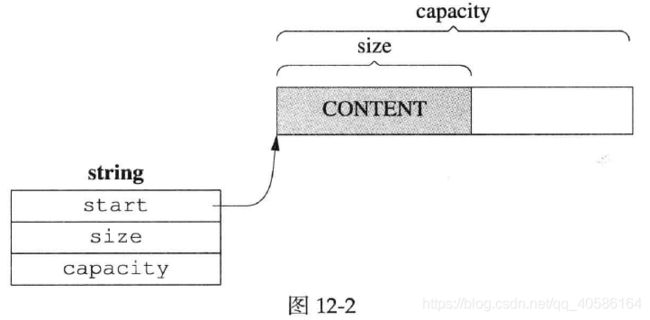
12.7.2 写时复制(copy-on-write)
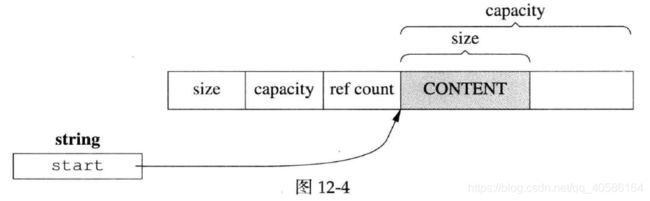
数据结构与eager copy类似,只不过拷贝是O(1)时间,但是拷贝之后的第一次operatort[]有可能是O(N)时间。利用了写时复制。
12.7.3 短字符串优化(SSO)
string对象比前面两个都大,因为有本地缓冲区(local buffer)。
class sso_string {
char* start;
size_t size;
static const int kLocalSize = 15;
union {
char buffer[kLocalSize + 1];
size_t capacity;
} data;
};
内存布局如图12-5(左图)所示。如果字符串比较短(通常的阈值是15字节),那么直接存放在对象的buffer里,如图12-5(右图)所示。start指向data.buffer。

如果字符串超过15字节,那么就变成eager copy 结构,start指向堆上分配的空间。
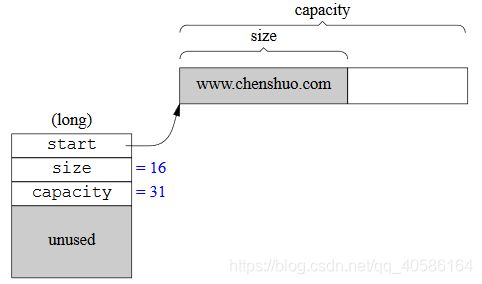
SSO string在64-bit中有一个小小的优化空间:如果允许字符串max-size()不大于4GiB的话,我们可以用32-bit整数来表示长度和容量。local buffer可以增大至19字节。

Q:有一台机器,它有一个 IP,上面运行了一个 TCP 服务程序,程序只侦听一个端口,问:从理论上讲(只考虑 TCP/IP 这一层面,不考虑IPv6)这个服务程序可以支持多少并发 TCP 连接?
A:一个 TCP 连接有两个 end points,每个 end point 是 {ip, port},题目说其中一个 end point 已经固定,那么留下一个 end point 的自由度,即 248。客户端 IP 的上限是 232 个,每个客户端IP发起连接的上限是 216,乘到一起得理论上限。
实际的限制是操作系统全局文件描述符的数量,以及内存大小。
boost库安装:
apt-cache search boost
搜到所有的boost库
然后:
sudo apt-get install libboost-all-dev
安装相应的库
参考:
《Linux多线程服务端编程:使用muduoC++网络库》
https://blog.csdn.net/freeelinux/category_6479321.htmlhttps://blog.csdn.net/freeelinux/category_6479321.html