资料来源:人工智能前沿讲习
表格资料来源:hoya012的Github
| Detector | VOC07 (mAP@IoU=0.5) | VOC12 (mAP@IoU=0.5) | COCO (mAP@IoU=0.5:0.95) | Published In |
|---|---|---|---|---|
| R-CNN | 58.5 | - | - | CVPR'14 |
| SPP-Net | 59.2 | - | - | ECCV'14 |
| MR-CNN | 78.2 (07+12) | 73.9 (07+12) | - | ICCV'15 |
| Fast R-CNN | 70.0 (07+12) | 68.4 (07++12) | 19.7 | ICCV'15 |
| Faster R-CNN | 73.2 (07+12) | 70.4 (07++12) | 21.9 | NIPS'15 |
| YOLO v1 | 66.4 (07+12) | 57.9 (07++12) | - | CVPR'16 |
| G-CNN | 66.8 | 66.4 (07+12) | - | CVPR'16 |
| AZNet | 70.4 | - | 22.3 | CVPR'16 |
| ION | 80.1 | 77.9 | 33.1 | CVPR'16 |
| HyperNet | 76.3 (07+12) | 71.4 (07++12) | - | CVPR'16 |
| OHEM | 78.9 (07+12) | 76.3 (07++12) | 22.4 | CVPR'16 |
| MPN | - | - | 33.2 | BMVC'16 |
| SSD | 76.8 (07+12) | 74.9 (07++12) | 31.2 | ECCV'16 |
| GBDNet | 77.2 (07+12) | - | 27.0 | ECCV'16 |
| CPF | 76.4 (07+12) | 72.6 (07++12) | - | ECCV'16 |
| R-FCN | 79.5 (07+12) | 77.6 (07++12) | 29.9 | NIPS'16 |
| DeepID-Net | 69.0 | - | - | PAMI'16 |
| NoC | 71.6 (07+12) | 68.8 (07+12) | 27.2 | TPAMI'16 |
| DSSD | 81.5 (07+12) | 80.0 (07++12) | 33.2 | arXiv'17 |
| TDM | - | - | 37.3 | CVPR'17 |
| FPN | - | - | 36.2 | CVPR'17 |
| YOLO v2 | 78.6 (07+12) | 73.4 (07++12) | - | CVPR'17 |
| RON | 77.6 (07+12) | 75.4 (07++12) | 27.4 | CVPR'17 |
| DeNet | 77.1 (07+12) | 73.9 (07++12) | 33.8 | ICCV'17 |
| CoupleNet | 82.7 (07+12) | 80.4 (07++12) | 34.4 | ICCV'17 |
| RetinaNet | - | - | 39.1 | ICCV'17 |
| DSOD | 77.7 (07+12) | 76.3 (07++12) | - | ICCV'17 |
| SMN | 70.0 | - | - | ICCV'17 |
| Light-Head R-CNN | - | - | 41.5 | arXiv'17 |
| YOLO v3 | - | - | 33.0 | arXiv'18 |
| SIN | 76.0 (07+12) | 73.1 (07++12) | 23.2 | CVPR'18 |
| STDN | 80.9 (07+12) | - | - | CVPR'18 |
| RefineDet | 83.8 (07+12) | 83.5 (07++12) | 41.8 | CVPR'18 |
| SNIP | - | - | 45.7 | CVPR'18 |
| Relation-Network | - | - | 32.5 | CVPR'18 |
| Cascade R-CNN | - | - | 42.8 | CVPR'18 |
| MLKP | 80.6 (07+12) | 77.2 (07++12) | 28.6 | CVPR'18 |
| Fitness-NMS | - | - | 41.8 | CVPR'18 |
| RFBNet | 82.2 (07+12) | - | - | ECCV'18 |
| CornerNet | - | - | 42.1 | ECCV'18 |
| PFPNet | 84.1 (07+12) | 83.7 (07++12) | 39.4 | ECCV'18 |
| Pelee | 70.9 (07+12) | - | - | NIPS'18 |
| HKRM | 78.8 (07+12) | - | 37.8 | NIPS'18 |
| M2Det | - | - | 44.2 | AAAI'19 |
| R-DAD | 81.2 (07++12) | 82.0 (07++12) | 43.1 | AAAI'19 |
一、One Stage 和 Two Stage
物体检测算法大致分为两类:一步法检测器和二步法检测器
一步法检测器:在原图上铺设一系列锚点框(anchor),利用一个全卷积网络,对这些锚点框进行一次分类和一次回归,得到检测结果。
二步法检测器:在原图上铺设一系列锚点框(anchor),利用一个网络,对这些锚点框进行两次分类和两次回归,得到检测结果。
相对于一步法检测器,二步法检测器多了一个步骤。如果这两类方法在相同的条件下(如相同的输入,相同的anchor设置,相同的机器等),一步法一般胜在高效率,因为它没有耗时的第二步,而二步法的精度要更高一些,现在各个检测库上排名靠前的算法,基本都是二步法。
比较出名的一步法检测器有YOLO、SSD、RetinaNet、CornerNet,其中SSD是一步法检测器的集大成者,后续大部分的一步法工作都是基于它的
比较出名的二步法检测器有Faster R-CNN、R-FCN、FPN、Cascade R-CNN、SNIP,其中Faster R-CNN是奠基性工作,基本所有的检测算法的,都是在它的基础上改进的,包括一步法SSD
Two Stage 的精度优势
二阶段的分类:二步法的第一步在分类时,正负样本是极不平衡的,导致分类器训练比较困难,这也是一步法效果不如二步法的原因之一,也是focal loss的motivation。而第二步在分类时,由于第一步滤掉了绝大部分的负样本,送给第二步分类的proposal中,正负样本比例已经比较平衡了,所以第二步分类中不存在正负样本极度不平衡的问题。即二步法可以在很大程度上,缓和正负样本极度不平衡的分类问题
二阶段的回归:二步法中,第一步会先对初始候选框进行校正,然后把校正过的候选框送给第二步,作为第二步校正的初始候选框,再让第二步进一步校正
二阶段的特征:在二步法中,第一步和第二步法,除了共享的特征外,他们都有自己独有的特征,专注于自身的任务。具体来说,这两个步骤独有的特征,分别处理着不同难度的任务,如第一步中的特征,专注于处理二分类任务(区分前景和背景)和粗略的回归问题;第二步的特征,专注于处理多分类任务和精确的回归问题
特征校准:在二步法中,有一个很重要的RoIPooling扣特征的操作,它把候选区域对应的特征抠出来,达到了特征校准的目的,而一步法中,特征是对不齐的
二、One Stage目标检测
1、One Stage目标检测Pipeline
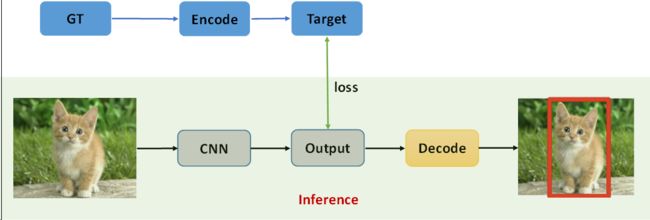
2、One Stage目标检测模型改进方向
网络设计(主干网络)
anchors设置方案
检测框回归方式
损失函数
PPT原文如下:

3、网络设计改进
作者使用SSD系列网络的发展展示了One Stage网络主干发展的脉络,DSSD和FSSD我在学校的组会上做过讲解,不过没有整理成文,这里不做过多讲解,以后再提
SSD
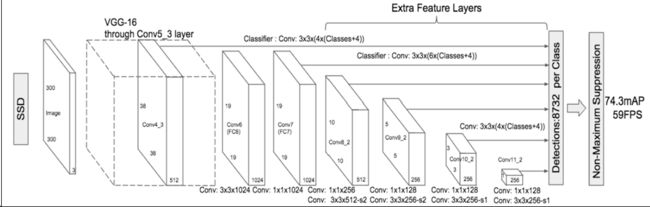
DSSD
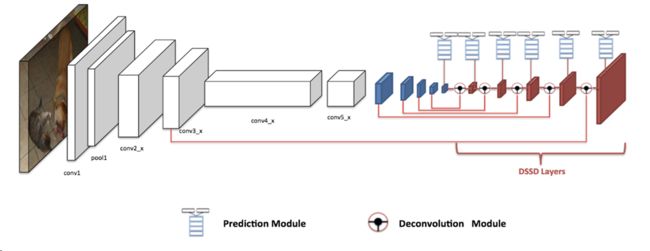
FSSD
4、anchors生成方案改进
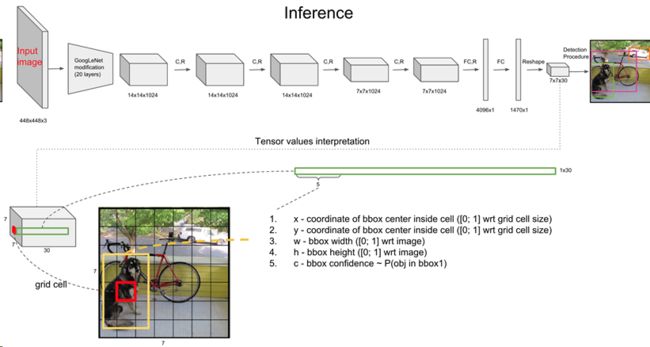
YOLOv1
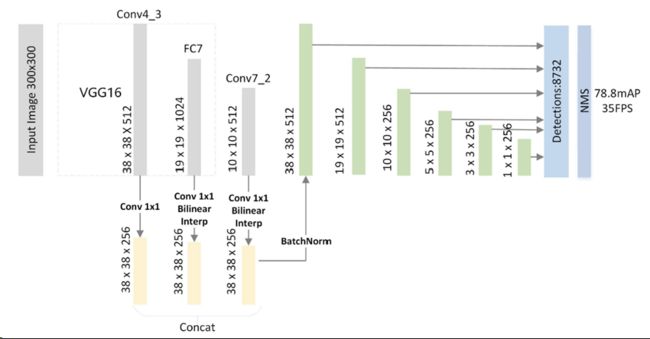
SSD
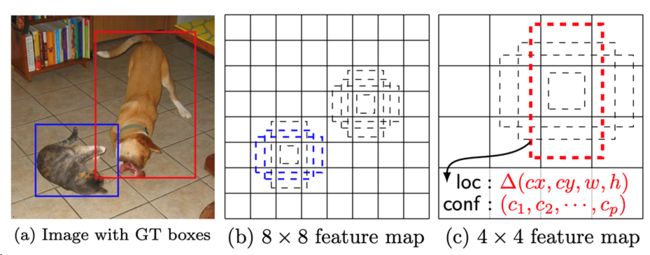
YOLOv2-v3
RefineDet
这个网络本文后面会介绍,这里不多赘述。
5、回归目标设计
YOLO
YOLO用不相重叠的网格划分区域,而选取的anchor为真实框中心点所在的网格作为回归的起始框,去匹配检测目标,即一个anchor对应一个target
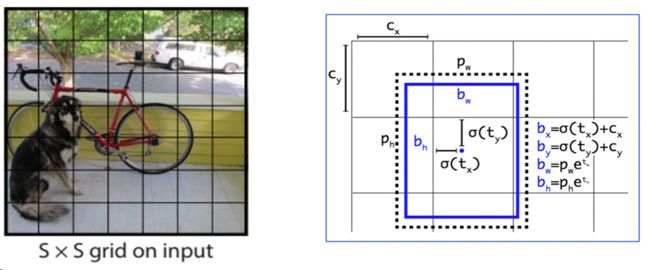
SSD
SSD的网格多且相互重叠,其匹配策略也略复杂:每一个anchor网格都有一个自己的class(都要去匹配一个真实框),在贡献loss的时候,真实框仅和IOU大于阈值的anchor相匹配。
参见 :
『TensorFlow』SSD源码学习_其二:基于VGG的SSD网络前向架构
『TensorFlow』SSD源码学习_其七:损失函数
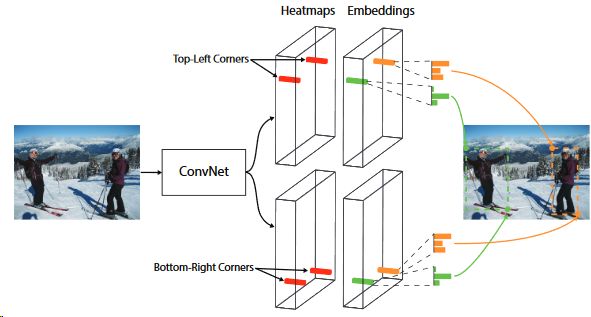
CornetNet
ECCV 2018的文章,不采用anchor修正的方法做物体检测,而是将ground-truth的左上和右下两个角点视为关键点,用热图来定位,实际设计很复杂,其损失函数设计也值得一看(特殊的网络一定会有特殊的损失函数相匹配)。除了原文外,推荐个博客辅助理解:
CornetNet算法理解
6、损失函数
OHEM
OHEM是Fast RCNN的改进,适合于batch size(images)较少,但每张image的examples很多的情况,针对困难object进行提取。
思想概括如下:
In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and a minibatch is constructed with the highest-loss examples.
实际应用流程:
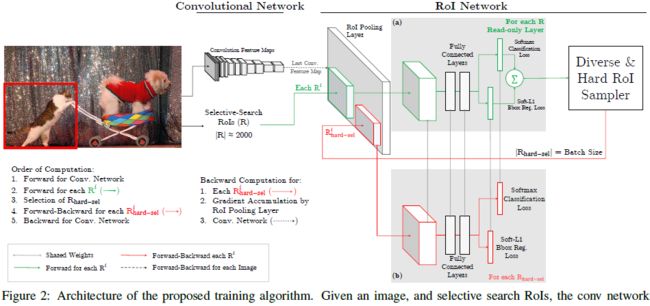
将Fast RCNN分成两个components:ConvNet和RoINet. ConvNet为共享的底层卷积层,RoINet为RoI Pooling后的层,包括全连接层;
2 对于每张输入图像,经前向传播,用ConvNet获得feature maps(这里为RoI Pooling层的输入);
3 将事先计算好的proposals,经RoI Pooling层投影到feature maps上,获取固定的特征输出作为全连接层的输入;
需要注意的是,论文说,为了减少显存以及后向传播的时间,这里的RoINet是有两个的,它们共享权重,
RoINet1是只读(只进行forward),RoINet2进行forward和backward:
a 将原图的所有props扔到RoINet1(上图a部分),计算它们的loss(这里有两个loss:cls和det);
b 根据loss从高到低排序,以及利用NMS,来选出前K个props(K由论文里的N和B参数决定)
为什么要用NMS? 显然对于那些高度overlap的props经RoI的投影后,
其在feature maps上的位置和大小是差不多一样的,容易导致loss double counting问题
c 将选出的K个props(可以理解成hard examples)扔到RoINet2(上图b部分),
这时的RoINet2和Fast RCNN的RoINet一样,计算K个props的loss,并回传梯度/残差给ConvNet,来更新整个网络
Focal loss
RetinaNet提出的致力于解决正负样本不均衡的新型损失函数
出发点:希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度
问题假设:作者认为one-stage detector的准确率不如two-stage detector的原因是样本的类别不均衡
相关工作:作者认为OHEM算法虽然增加了错分类样本的权重,但是完全忽略了容易分类的样本
focal loss:在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本
原交叉熵:
![]()
Focal loss改进:
gamma>0使得减少易分类样本的损失,使得更关注于困难的、错分的样本
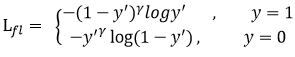
添加正负样本:
加入平衡因子alpha,用来平衡正负样本本身的比例不均
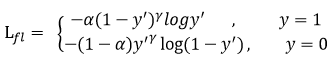
三、Two Stage目标检测
1、Two Stage目标检测Pipeline
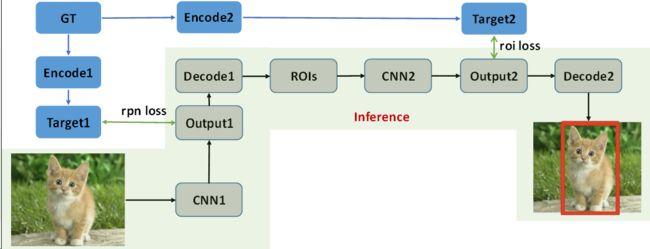
2、Two Stage目标检测模型改进方向
生成Proposals
ROI特征获取
ROI算法设计
加速检测
后处理回归框
PPT原文如下:
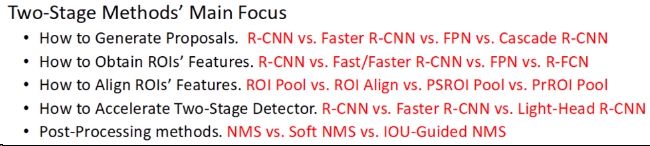
3、生成Proposals
R-CNN
使用某些算法生成推荐框,这些推荐区直接在原图上crop生成Proposals,然后非极大值抑制合并这些Proposals的分类、回归结果,作者使用“聚类”描述这个合并过程
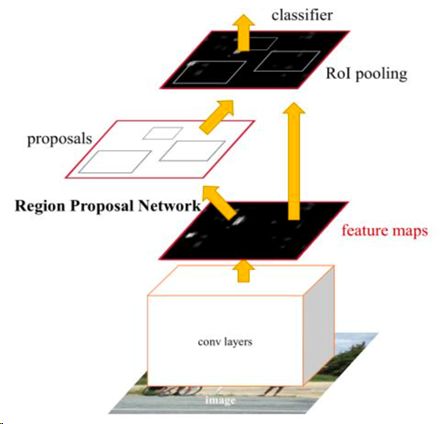
Faster R-CNN
这个讲滥了,直接用anchors经过第一次分类、回归得到的推荐框crop原图经过特征提取网生成的特征图,结果作为Proposals进行分类、回归
FPN
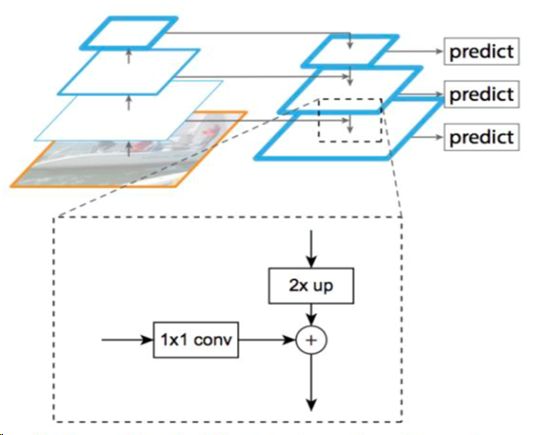
总体来看和Faster R-CNN类似,不过crop的目标不再是原图经过网络生成的一张特征图,而是在特征金字塔上寻找某一层作为crop目标
Cascade R-CNN
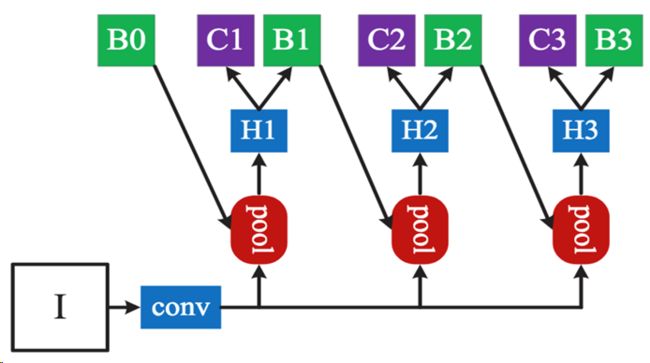
这篇是CVPR 2018的文章,核心是Cascade roi-wise subnet,用于更好的利用IOU进行回归结果的修正,简单解释一下下图,经过conv出来的特征要经过align pool才能进入subnet,这里采用了联级的方式操作,B0是二分类生成的框,选取一系列IOU阈值{0.5, 0.6, 0.7},B1是B0在conv输出特征上crop出来子区域经过H1回归的结果,B2则是B1在conv输出……,阈值逐渐严格回归效果更好
R-FCN
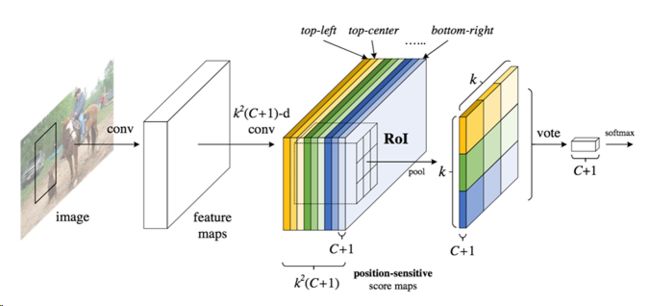
生成K*K*(C+1)张特征,K为ROI输出尺寸,在K*K组中每一组只取对应输出位置的Pool结果,重新排列整理得到我们想要的特征:『计算机视觉』R-FCN
4、设计ROI算法
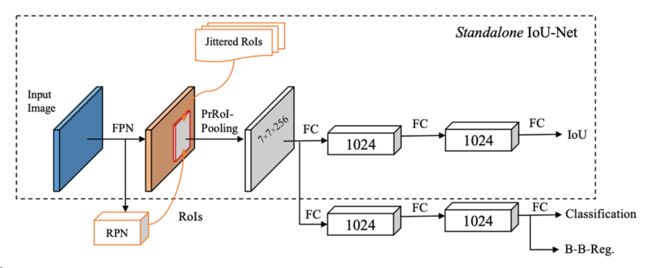
ROI Pooling 、ROI Align、PSROI Pool、PRROI Pool
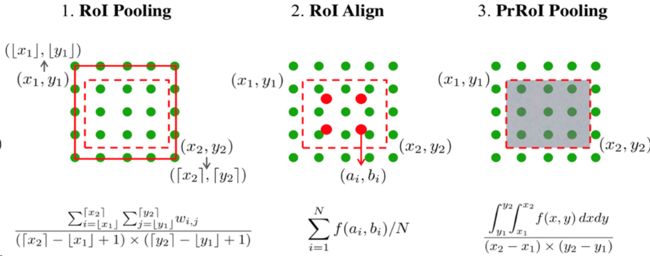
5、两步法准确率提升

6、模型后处理
NMS
非极大值抑制

Soft NMS
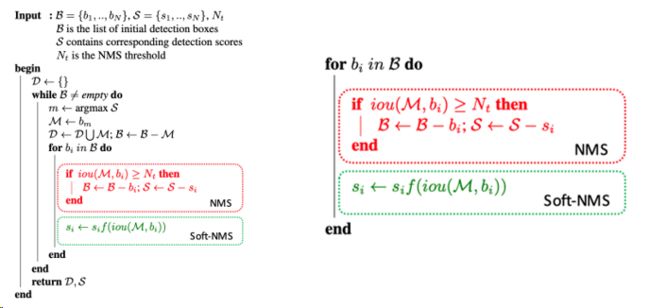
def cpu_soft_nms(np.ndarray[float, ndim=2] boxes, float sigma=0.5, float Nt=0.3, float threshold=0.001, unsigned int method=0):
cdef unsigned int N = boxes.shape[0]
cdef float iw, ih, box_area
cdef float ua
cdef int pos = 0
cdef float maxscore = 0
cdef int maxpos = 0
cdef float x1,x2,y1,y2,tx1,tx2,ty1,ty2,ts,area,weight,ov
for i in range(N):
maxscore = boxes[i, 4]
maxpos = i
tx1 = boxes[i,0]
ty1 = boxes[i,1]
tx2 = boxes[i,2]
ty2 = boxes[i,3]
ts = boxes[i,4]
pos = i + 1
# get max box
while pos < N:
if maxscore < boxes[pos, 4]:
maxscore = boxes[pos, 4]
maxpos = pos
pos = pos + 1
# add max box as a detection
boxes[i,0] = boxes[maxpos,0]
boxes[i,1] = boxes[maxpos,1]
boxes[i,2] = boxes[maxpos,2]
boxes[i,3] = boxes[maxpos,3]
boxes[i,4] = boxes[maxpos,4]
# swap ith box with position of max box
boxes[maxpos,0] = tx1
boxes[maxpos,1] = ty1
boxes[maxpos,2] = tx2
boxes[maxpos,3] = ty2
boxes[maxpos,4] = ts
tx1 = boxes[i,0]
ty1 = boxes[i,1]
tx2 = boxes[i,2]
ty2 = boxes[i,3]
ts = boxes[i,4]
pos = i + 1
# NMS iterations, note that N changes if detection boxes fall below threshold
while pos < N:
x1 = boxes[pos, 0]
y1 = boxes[pos, 1]
x2 = boxes[pos, 2]
y2 = boxes[pos, 3]
s = boxes[pos, 4]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
iw = (min(tx2, x2) - max(tx1, x1) + 1)
if iw > 0:
ih = (min(ty2, y2) - max(ty1, y1) + 1)
if ih > 0:
ua = float((tx2 - tx1 + 1) * (ty2 - ty1 + 1) + area - iw * ih)
ov = iw * ih / ua #iou between max box and detection box
if method == 1: # linear
if ov > Nt:
weight = 1 - ov
else:
weight = 1
elif method == 2: # gaussian
weight = np.exp(-(ov * ov)/sigma)
else: # original NMS
if ov > Nt:
weight = 0
else:
weight = 1
boxes[pos, 4] = weight*boxes[pos, 4]
# if box score falls below threshold, discard the box by swapping with last box
# update N
if boxes[pos, 4] < threshold:
boxes[pos,0] = boxes[N-1, 0]
boxes[pos,1] = boxes[N-1, 1]
boxes[pos,2] = boxes[N-1, 2]
boxes[pos,3] = boxes[N-1, 3]
boxes[pos,4] = boxes[N-1, 4]
N = N - 1
pos = pos - 1
pos = pos + 1
keep = [i for i in range(N)]
return keep
IOU-Guided NMS