中国大学排名定向爬虫以及淘宝商品爬虫参考嵩天老师Python爬虫课程遇到的问题及解决
首先附上课程中程序,无法正常运行
把2016年的url更改为今年的url:http://www.shanghairanking.cn/rankings/bcur/2020
代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
输出结果:
报错
AttributeError: ‘NoneType’ object has no attribute ‘children’
寻找问题原因
先输出网站内容,代码如下:
from bs4 import BeautifulSoup
import requests
r = requests.get('https://www.shanghairanking.cn/rankings/bcur/2020')
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
部分输出结果:
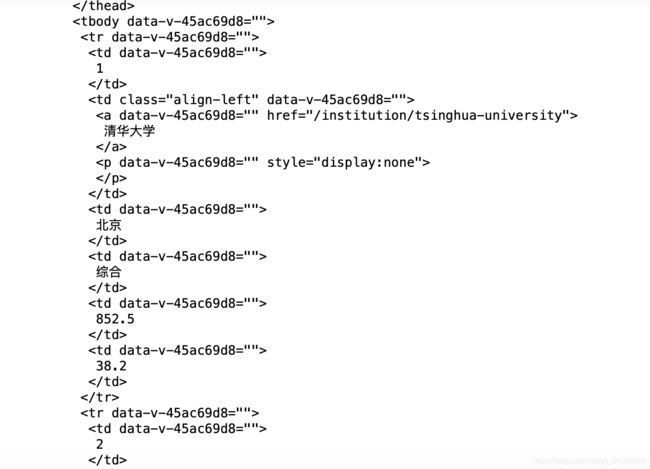
输出结果中可以看到 tbody 标签包含所有大学的信息,tr 标签包含一个大学的全部信息,td 标签下包含单个大学的每个信息。 但是与嵩天老师的课件中不同的是包含大学名称的标签是 td 下的 a 标签。
所以问题应该是出在获取大学名称部分。
将打印 ulist 的内容打印出来。
代码如下:
将语句:
ulist.append([tds[0].string, tds[1].string, tds[4].string])
改为 :
ulist.append([tds[0].string, tds[1], tds[4].string])
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1], tds[4].string])
print(ulist)
输出结果:

可以看到我们想要的内容被打印出来了,但是还有一下我们不想要的内容。
可以看到我们想要的内容在 a 标签下,可以用 .find() 方法检索出我们想要的内容。
代码如下:
for a in tr.find('a'):
print('a')
输出结果为:

这正是我们想要的内容,并把它赋给 tds。
代码如下:
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# ulist.append([tds[0].string, tds[1], tds[4].string])
for a in tr.find('a'):
# print(a)
ulist.append([tds[0].string, a, tds[4].string])
输出结果为:

内容正是我们想要的,但是排版不够整齐。原因是 ulist 的内容里面含有换行符。
把ulist里面的换行符用 .replace() 方法替换掉,就不会有换行的问题了。
代码如下:
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0].replace('\n',''), u[1].replace('\n',''), u[2].replace('\n','')))
输出结果:
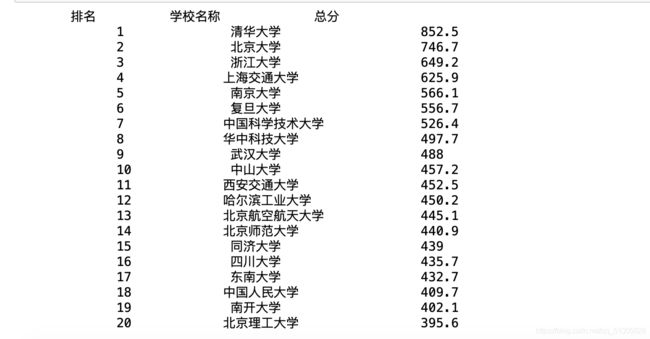
这正是我们想要的排版和内容,修改一下print() 打印出来的格式就能得到比较整齐的排版了。
程序整体代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# ulist.append([tds[0].string, tds[1], tds[4].string])
for a in tr.find('a'):
# print(a)
ulist.append([tds[0].string, a, tds[4].string])
def printUnivList(ulist, num):
print(" {:^10}\t{:^6}\t {:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0].replace('\n',''), u[1].replace('\n',''), u[2].replace('\n','')))
def main():
uinfo = []
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
输出结果为:
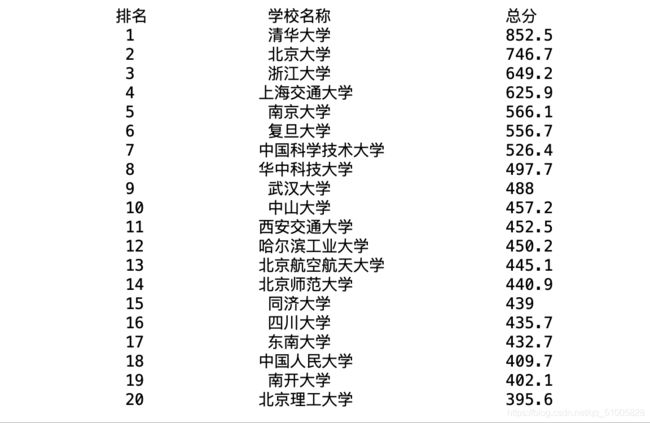
这个排名的网站又更新了,上面的程序用不了了,下面是更新之后的程序:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLtext(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
#detect the type of the tr, filte out tr that type is not bs4.element.Tag
if isinstance(tr, bs4.element.Tag):
#creating a list containing the tag:'td'
tds = tr('td')
for a in tr.find('a'):
continue
for b in tr.find('td'):
ulist.append([b, a])
def printUnivList(ulist, num):
print(" {:^10}\t {:^6}\t".format("uni_ranking", "uni_name"))
for i in range(0,num,2):
u = ulist[i]
print("{:^10}\t{:^16}".format(u[0].replace('\n',''), u[1].replace('\n','')))
def main():
uinfo = []
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLtext(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()
输出结果:

以下是淘宝商品爬虫代码:
因为淘宝网的反爬虫机制,所以需要伪装一下爬虫
import requests
import re
def getHTMLText(url):
try:
header = {
'authority': 's.taobao.com',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.61',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': 'https://www.taobao.com/',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cookie': 't=45617de446470fd44aee6d085f2d9e18; cna=SwSKFeQJLyYCATsqJmaw9KmK; miid=488275361906276349; tg=0; _m_h5_tk=7e994d481264fc9b7909a2fda08a7f77_1604587354537; _m_h5_tk_enc=dd8e40d0dd3512737c7a628d7ca28d87; v=0; _tb_token_=e3e5e7fbb0551; enc=d6kXYOkMlGO4Vpc3fpc0k15%2BptSme%2Fhs4qGftdmvi0gB595cZ8lCtM4ODRPLW8NsrIFzT1l8rh%2Fw974tqE3%2BKA%3D%3D; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; cookie2=14809c047547fa2b6897acb65a316e0f; hng=CN%7Czh-CN%7CCNY%7C156; xlly_s=1; thw=cn; _samesite_flag_=true; JSESSIONID=EA7B34945DCBBAC8990AED7A7D51BFFC; isg=BAsLXFa90HFmcQ6XrwKaebexmq_1oB8iJCKJQn0IP8oUnCn-BXX8cpZ9c5xy6Xca; l=eBj929xIqLsfyQIdBO5aourza77tzIRbzmFzaNbMiInca1uhtn6hnNQVmWH9SdtxgtCecetyM85CqdnprdadNxDDBexrCyCurxvO.; tfstk=cDaPBQx4raQrbrgCX4geVdyLTxiRaQ435ghKqkJ3LEs2KgqsQs4kpj4DB8eeH-nl.',
}
r=requests.get(url,timeout=30,headers=header)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
print("")
def parsePage(ilt,html):
try:
plt=re.findall(r'"view_price":"[\d.]*"',html)
tlt=re.findall(r'"raw_title":".*?"',html) #最小匹配
for i in range(len(plt)):
price=eval(plt[i].split(':')[1]) #eval去除引号
title=eval(tlt[i].split(':')[1])
ilt.append([price,title])#输出由多个列表组成的列表
# print(ilt)
except:
print("")
def printGoodsList(ilt):
tplt="{:4}\t{:8}\t{:10}"
print(tplt.format('序号','价格','商品名称'))
count=0
for g in ilt:
count+=1
print(tplt.format(count,g[0],g[1]))
print("")
def main():
goods='jetson'
depth=2
start_url='https://s.taobao.com/search?q='+goods
infoList=[]
for i in range(depth):
try:
url=start_url+'&s='+str(44*i)
html=getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()