word2vec模型评估_干货 | NLP中的十个预训练模型

Word2vec, Fasttext, Glove, Elmo, Bert, Flair pre-train Word Embedding源码+数据Github网址:https://github.com/zlsdu/Word-Embedding
- Word2vec
- Fasttext
- ULMFit
- Glove
- Cove
- ELMO
- GPT1.0
- GPT2.0
- BERT
- Flair Embedding
一、Word2vec1、word2vec种语言模型
word2vec属于预测式词向量模型,两种Skipgram和CBOW
(1) skipgram通过中间词预测周围词构建网络模型
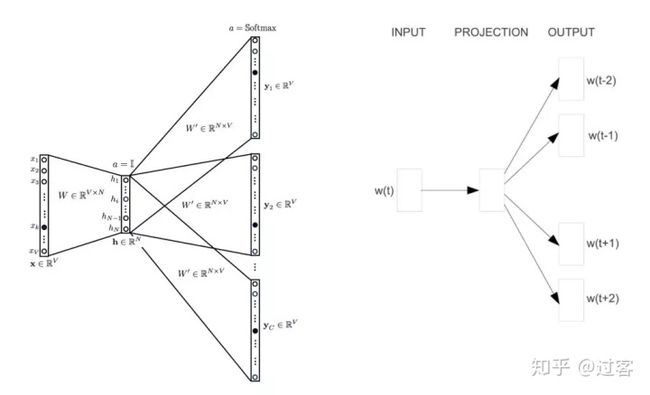
(2) cbow通过周围词预测中间词构建网络模型

2、word2vec中Tricks:
(1) Hierarchicalsoftmax
分层softmax最主要的改进既是:不需要对网络W个单词的输出计算概率分布,只需要评估个节点即可
(2) Negativesampling
详细介绍一下负采样,word2vec中训练技巧:负采样
通过模型的一次训练来解释负采样的过程,以skip_gram模型训练为例进行讲解
训练样本输入词是:love,输出词是me,如果词典中有10000个词,设定训练出的词向量大小为300,则开始love和me都是通过one-hot编码的,在输出位置上me对应的是1,其他位置都是0,我们认为这些0位置对应的词即是负样本,1位置对应的是正样本,在不采用负采样情况下隐层到输出层的参数为300*10000,负采样的意思即是我们只在9999个负样本中选择很少一部分对应的参数进行更新(包括正样本的也更新),其他没有挑中的负样本参数保持不变,例如我们选择5个negative words进行参数更新,加上一个正样本总共是6个,因此参数是300*6,大大提高每次训练的计算效率,论文中指出对于小规模数据集我们选择5-20个negative words较好,在数据集情况下选择2-5个负样本较好
(3) Subsamplingof Frequent words
频繁词的二次采样,根据论文描述在大的语料库中,频繁词如容易出现很多次的theina提供的信息量远没有罕见词提供的信息量多,因此在后续的训练中频繁词无法提供更多的信息甚至会将网络带偏,因此提出了频繁词二次采样方式:即在每次训练时按照如下公式对训练集的单词wi进行丢弃:

CBOW模型的优化函数(skipgram模型类似):

(4) word2vec是静态词向量预训练模型,词向量是固定的,不能解决多义词问题,无法考虑预料全局信息
二、Fasttext
fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点:
(1) fastText在保持高精度的情况下加快了训练速度和测试速度
(2) fastText不需要预训练好的词向量,fastText会自己训练词向量
因此fasttext在预训练上的体现便是我们可以通过fasttext训练自己预料的词向量1、fasttext模型架构
fastText模型架构和word2vec中的CBOW很相似, 不同之处是fastText预测类别标签而CBOW预测的是中间词,即模型架构类似但是模型的任务不同,下面是fasttext的结构图

2、fasttext中tricks
fasttext和word2vec类似还体现在优化tricks上,fasttext的tricks有:
(1) Hierarchical softmax:减少计算量
(2) n-gram特征:n-gram好处有可以考虑到语序信息同时也可避免OOV问题
fasttext接下来在文本分类专题中会详细介绍,这里需明白fasttext能够快速训练词向量提供nlp任务的预训练Embedding,且实验证明fasttext是预训练中的佼佼者
三、ULMFiT1、ULMFiT模型结构
UniversalLanguage Model Fine-tuning通用语言模型微调,主要做文本分类任务
如下图所示主要是三个模型:
(1) General-domainLM pretraining:在一般的大规模语料库上进行预训练语言模型
(2) Targettask LM fine-tuning:在目标数据集上微调语言模型
(3) Targettask classifier fine-tuning:在特定分类任务上微调语言模型

2、ULMFit中Tricks
在Target task LM fine-tuning阶段:
(1) Two-stagefine-tuning:在特征数据集和分类两阶段fine-tuning
(2) Discriminativefine-tuning:为网络的每一层都设置了学习率,因为网络不同层捕获不同信息,因此进行不同程度的微调

(3) Slantedtriangular learning rates:倾斜三角学习率,意思是为了使参数更快的适应任务的特征,在模型开始训练时快速收敛到参数空间,再细化参数


在Target task classifier fine-tuning阶段tricks:
(1) concatpooling:将最后隐层状态按max-pooled或mean-pooled拼接起来
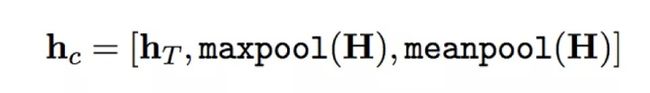
(2) guadualunfreezing: 过度微调会导致语音模型捕获的信息遗忘,而过于谨慎的微调会导致收敛缓慢,采用的是逐步微调方法,逐层微调
(3) BPTTfor text classification:时间反向传播,实现大输入序列的梯度传播
(4) Bidirectional language model:双向语言模型
四、Glove1、Glove矩阵分解模型
Glove是一种矩阵分解式词向量预训练模型,如果我们要得到目标词w的预训练Embedding目标词w的Embedding表示取决于同语境中的词c的共现关系,因此引入矩阵分解的共现矩阵M,下面先给出共现矩阵M定义:
|Vw|行,每行对应Vw中出现的词w
|Vc|列,每列对应Vc中出现的词c
Mij表示wi和cj之间的某种关联程度,最简单的联系是w和c共同出现的次数


重点来了,Glove中定义w和c的关联度为:

Glove共现矩阵分解方式:
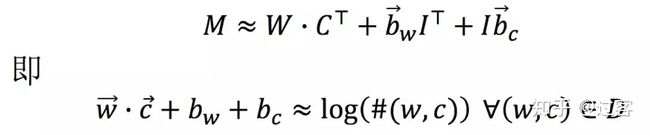
Glove分解误差及优化目标定义:
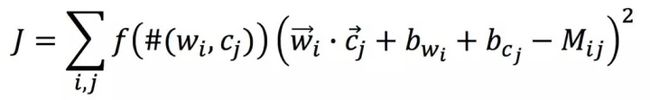

2、Glove中的优缺点
(1) 优点:glove矩阵分解是基于全局预料的,而word2vec是基于部分预料训练的
(2) 缺点:glove和word2vec、fasttext一样词向量都是静态的,无法解决多义词问题,另外通过glove损失函数,还会发现glove有一个致命问题,看下解释:

看上面的公式,glove损失函数显示,在glove得出的词向量上加上任意一个常数向量后,仍旧是损失函数的解,这问题就较大,如我们加上一个特别的常数,词向量就是十分接近了,这样就失去了词向量的表示含义,因此用glove训练出词向量后要进行check
五、Cove1、Cove模型结构
模型首先在一个Encoder-Decoder机器翻译的训练任务上进行预训练,预训练模型训练好之后只取Embedding层和Encoder层,然后在新的任务上设置task-specific model,用预训练好的Embedding层和Encodeer层作为输入,最后在新的任务场景下进行训练

预训练模型Encoder部分使用的是Bi-LSTM,并在下游任务中结合了glove向量作为表示

在效果上要优于glove的多种任务,但缺点是大多还是利用下游任务的模型表现
六、ELMO1、ELMO模型结构
ELMO首先根据名字Embedding from language model便可以ELMO是一个基于语言模型的词向量预训练模型,其次ELMO区别于word2vec、fasttext、glove静态词向量无法表示多义词,ELMO是动态词向量,不仅解决了多义词问题而且保证了在词性上相同
ELMO模型使用语言模型Language Model进行训练,ELMO预训练后每个单词对应三个Embedding向量:
(1) 底层对应的是Word Embedding,提取word的信息
(2) 第一层双向LSTM对应是Syntactic Embedding,提取高于word的句法信息
(3) 第二层双向LSTM对应的是Semantic Embedding,提取高于句法的语法信息
ELMO在下游任务中是将每个单词对应的三个Embedding按照各自权重进行累加整合成一个作为新特征给下游任务使用,如下图所示:
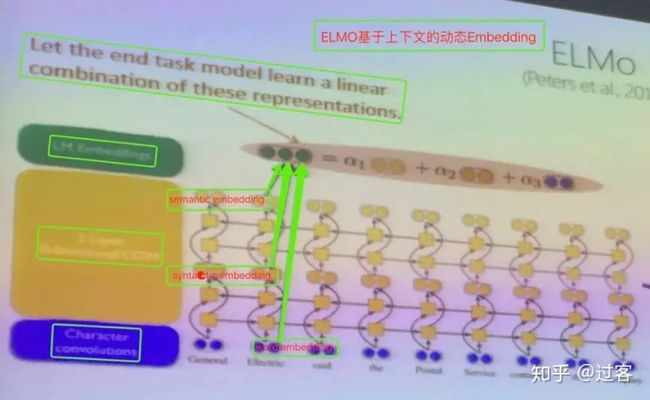
在Bert论文中也给出了ELMO的模型图,比上图更简洁易于理解:

下面通过公式来再深入理解一下ELMO的双向LSTM语言模型,有一个前向和后向的语言模型构成,目标函数是取这两个方向语言模型的最大似然
给定N个tokens,前向LSTM结构为:

后向LSTM结构为:
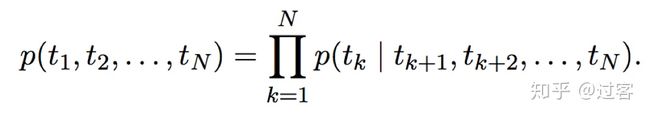
Bi-LSTM的目标函数既是最大化前向和后向的对数似然和:

2、ELMO的优缺点
ELMO的优点便是使用了双层Bi-LSTM,并且最终模型学到的是Word Embedding + Syntactic Embedding + Semantic Embedding的线性组合
ELMO相较于Bert模型来说,有以下缺点:
(1) ELMO在特征抽取器选择方面使用的是LSTM,而不是更好用Transformer,Bert中使用的便是Transformer,Transformer是个叠加的自注意力机制构成的深度网络,是目前NLP里最强的特征提取器
(2) ELMO采用双向拼接融合特征,相对于Bert一体化融合特征方式可能较弱
七、GPT1.01、GPT1.0模型结构
GPT1.0使用语言模型进行预训练,通过Fine-tuning的模式解决下有任务
GPT1.0和ELMO相比最大的两点不同
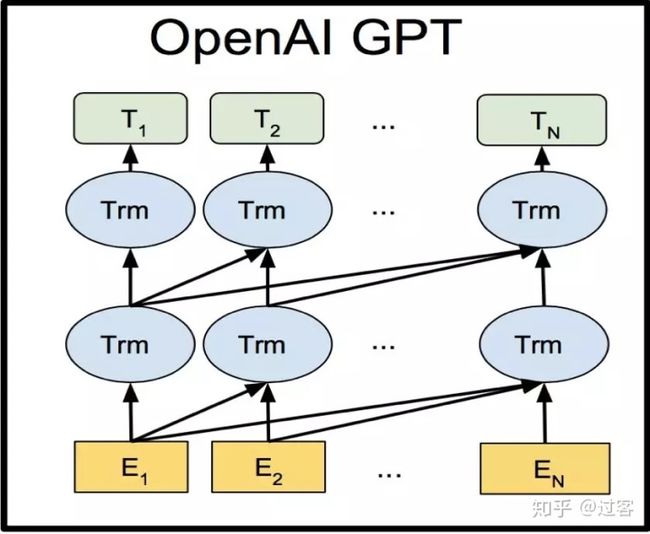
(1) 特征抽取器使用的是Transformer而不是RNN
(2) GPT预训练仍旧采用的是以语言模型作为目标任务,但是采用的是单向的语言模型,而不是ELMO和Bert中的双向语言模型,这也是GPT1.0甚至是GPT2.0与Bert模型相比最大的区别
Bert论文中给出了GPT模型的简要结构,可以看出输入是Word Embedding,然后是两层单向的语言模型,特征提取器使用的是Transformer
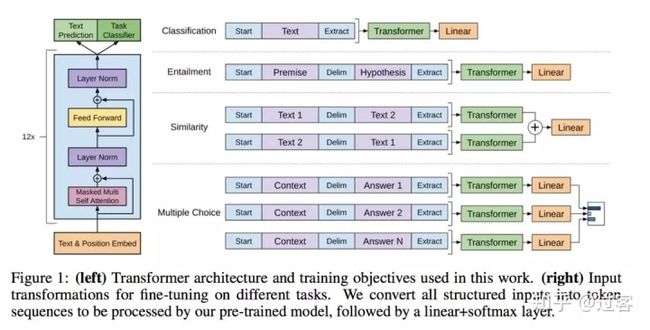
根据论文GPT1.0训练模型使用的任务包含以下三个:
(1) Textual entailment: For entailment tasks, we concatenate the premisep and hypothesis h token sequences, with a delimiter token ($) in between
(2) Similarity句子相似度
(3) Question Answer and Commonsense Reasoning
2、GPT中Tricks
(1) 特征提取器使用了Transformer替代RNN
(2) Discriminative fine tuning:意思是对于特定的任务有区别的进行下游任务的微调,即模型会感知输入的数据对于进行转化,最小程度修改模型结构
八、GPT2.01、GPT2.0模型结构
GPT2.0模型结构和GPT1.0大致相同,仍旧是采用单向语言模型预训练,特征提取使用的是Transformer,GPT2.0相对于GPT1.0主要是做了以下三点大的改进
(1) transformer模型由原来24层叠加的block变成了48层,参数15亿
(2) 更大网络自然需要更多数据,因此数据采用质量更高数量更大的涵盖范围更广的数据WebText
(3) 使用无监督进行下游任务而不是fine-tuning
当然还有一些小的改变如对transformer结构进行了微调,主要还是增大了网络层次2、对GPT2.0的应用理解
虽然大多数感觉GPT不如Bert,因为它和Bert特征提取器都使用的是Transformer,但是它使用的是单向语言模型,不似Bert的双向语言模型效果那么好,但是GPT在一个方面还是完胜Bert的,那就是序列生成任务上,如摘要生成,自动生成自然语言的句子和段落,这归因于GPT的预训练任务
九、BERT1、Bert模型结构
Bert相信NLPer都相当熟悉了,Bert模型主要两个特点
(1) 特征提取器使用的是transformer
(2) 预训练使用的是双向语言模型
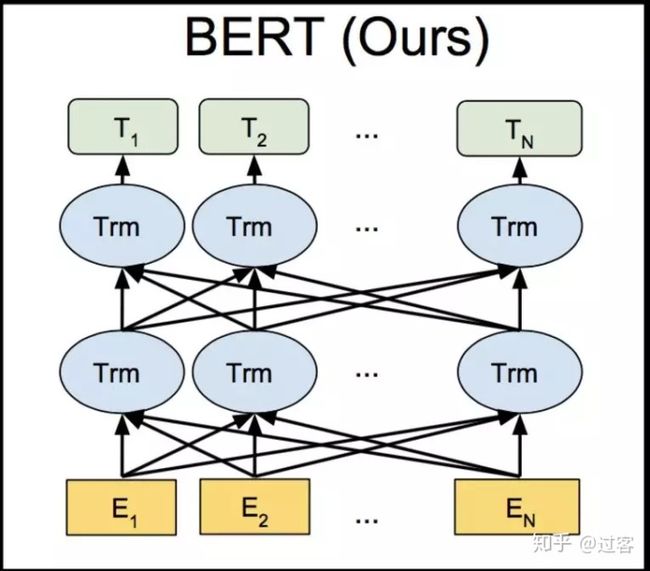
Bert还有突出的地方在于它的预训练任务上,Bert采用了两个预训练任务:Masked语言模型(本质上是CBOW)、NextSentence Prediction
(1) Masked语言模型:随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词,但15%词中只有80%会被替换成mask,10%被替换成另一个词,10%的词不发生改变
(2) Next SentencePrediction:指语言模型训练的时候,分两种情况选择句子,一种是正确拼接两个顺序句子,一种是从语料库中随机选择一个句子拼接到句子后面,做mask任务时顺带做句子关系预测,因此BERT的预训练是一个多任务过程在
因为Bert预训练预料丰富模型庞大,Bert的可适用的下游任务也很多,Bert可以对于上述四大任务改造下游任务,应用广泛:
(1) 序列标注:分词、POS Tag、NER、语义标注
(2) 分类任务:文本分类、情感计算
(3) 句子关系判断:Entailment、QA、自然语言推断
(4) 生成式任务:机器翻译、文本摘要等
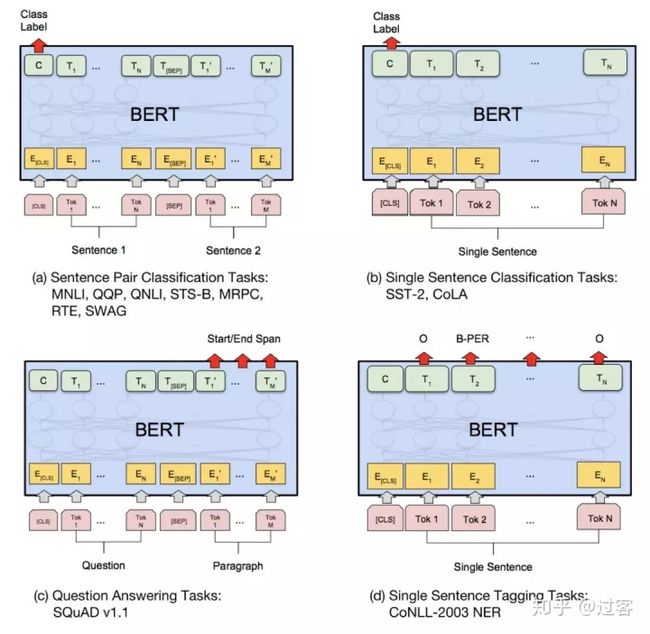
2、Bert中的细节理解
看下图,Bert在训练和使用过程中注意的一些小细节:
(1) Bert训练的词向量不是完整的,而是WordPiece Embedding,因此要通过Bert模型得到英文Word Embedding要将WrodPiece Embeddings转化为Word Embedding
(2) Bert预训练模型的输入向量是Token Embeddings + Segment Embeddings + Position Embeddings
(3) 在对Bert模型微调进行下游任务时,需要知道Bert模型输出什么传入下游任务模型,即是开头[CLS]出的向量Special Classification Embeddings

3、特征提取器插播
说到NLP中的特征提取器这里说一下,目前NLP常用的特征提取方式有CNN、RNN和Transformer,下面简要比较:
(1) CNN的最大优点是易于做并行计算,所以速度快,但是在捕获NLP的序列关系尤其是长距离特征方面天然有缺陷
(2) RNN一直受困于其并行计算能力,这是因为它本身结构的序列性依赖导致的
(3) Transformer同时具备并行性好,又适合捕获长距离特征
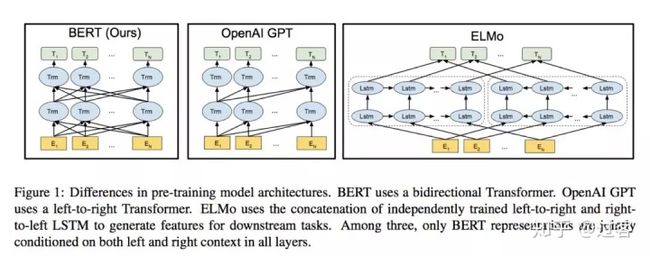
这里顺便放上ELMO、GPT、BERT的对比图,其中ELMO特征提取器使用的是RNN,GPT和Bert使用的是Transformer,GPT使用的是单向语言模型,ELMO和BERT使用的是双向语言模型
4、Attention机制插播
为了更好理解Transformer这里希望可以通俗简短的介绍一下Attention机制
(1) 从机器翻译(Encoder-Decoder)角度看一下Attention机制(下面图片引自网络)


先看上面第一张图,是传统的机器翻译,Y1由[X1, X2, X3, X4]编码得到,可以看出[X1, X2, X3, X4]对翻译得到词Y1贡献度没有区别
再看第二张图是Attention+ 机器翻译,每个输出的词Y受输入X1, X2, X3, X4影响的权重不同,这个权重便是由Attention计算,因此可以把Attention机制看成注意力分配系数,计算输入每一项对输出权重影响大小
(2) 从一个机器翻译实例理解Attention机制,了解一下Attention如何对权重进行计算(下面图片引自网络)
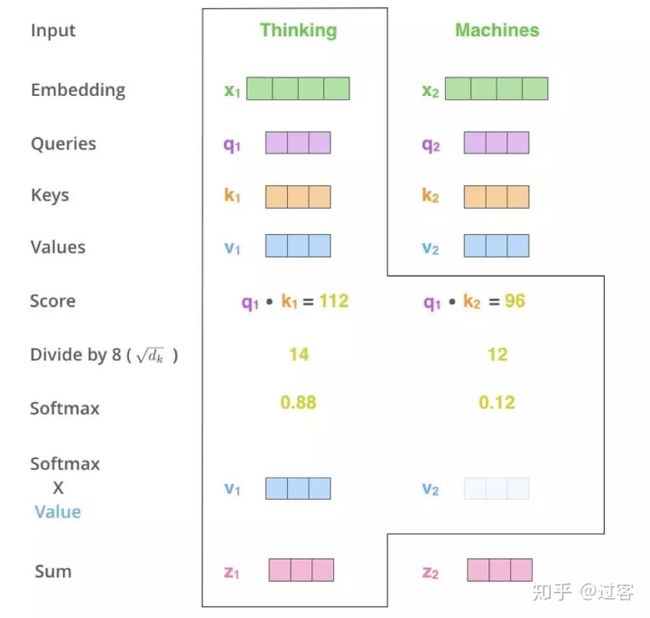
首先由原始数据经过矩阵变化得到Q、K、V向量,如下图(下图引自网络)

以单词Thinking为例,先用Thinking的q向量和所有词的k向量相乘,使用下面公式:
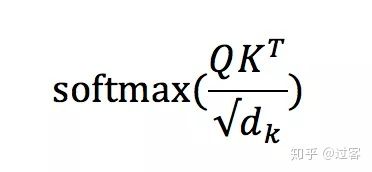
这种得到每个单词对单词Thinking的贡献权重,然后再用得到的权重和每个单词的向量v相乘,得到最终Thinking向量的输出
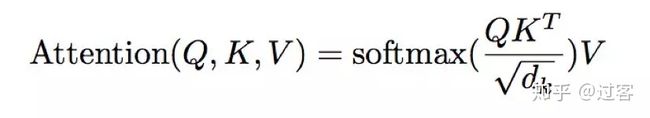
还有Self-attention和Multi-head attention都是在Attention上进行一些改动,这样不详细介绍
十、Flair Embedding
Flair Embedding预训练目前听到的还不太多,当时有论文证明在NER任务上目前比BERT效果还要好,其他任务还不确定,下面是在NER任务上的对比

这里结合论文简要介绍一下FlairEmbedding的预训练模型,并给出Flair Embedding源码github地址,上面详细介绍了Flair Embedding的使用1、Flair Embedding预训练模型
A trained characterlanguage model to produce a novel type of word embeddin as contextual stringembeddings
(1) pre-train on largeunlabeled corpora,
(2) capture word meaningin context and therefore produce different embeddings for polysemous wordsdepending on their usage
(3) model words andcontext fundamentally as sequences of characters, to both better handle rareand misspelled words as well as model subword structures such as prefixes andendings.
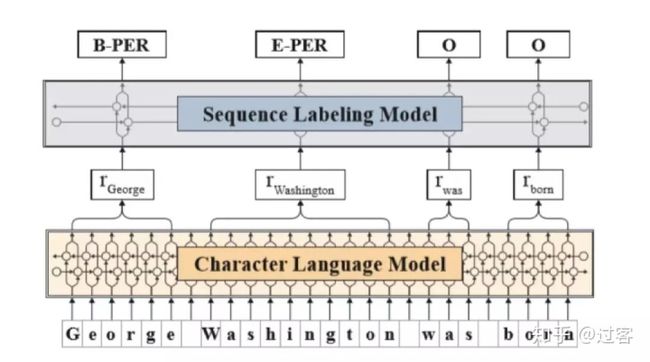
Character languagemodel: 2048 * 1 layer
1 Billion word corpus in1 week for 1 GPU
Sequence tagging model:150 epochs
256 * 1Layer
Classic word embedding:
GloVe , characterfeature: 25 * 1 layer2、Flair Embedding使用
flairEmbedding使用地址: https://github.com/zalandoresearch/flair,里面详细接受了Flair Embedding的介绍,并且集成了ElMO和BERT的使用

本文完结,后续持续出NLP相关文章,坚持用心写文章,感兴趣欢迎关注
