目标检测 SSD 算法结构解析以及基于 pytorch 代码复现(基于 VOC 数据集训练测试)
SSD 作为目标检测单阶段方法中最经典的算法之一,是大多数人入门的第一选择,网上参考资料也很多,本文旨在记录自己的学习过程,希望对其他的初学者能够有所帮助。
一、SSD 基础知识
目标检测单阶段方法一般先对图像进行特征提取,然后再根据提取的特征进行分类与边框回归。SSD 也是如此,比较独特的是,它在 VGG16 基础上通过添加额外的不同尺度特征提取层实现检测性能的提升。具体结构如下图:

共提取出 6 个不同尺度的特征图,分别为(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),从而实现检测。(这样设计的目的是不同尺度的特征图包含的信息不同,一般浅层感受野较小,包含的位置信息较好,并且有利于小目标的检测,高层一般感受野较大,包含更多的全局信息)不过 SSD 只是简单的利用了不同尺度信息,后面也有人融合了特征金字塔思想,提出了 FSSD ,提升了检测性能。
第二个比较核心的点是 SSD 采用卷积操作实现最后的检测而不是使用全连接层,采用 3*3 卷积核,产生类别的分数或产生相对于默认框坐标的形状偏移。通过卷积操作,减少了参数,从而达到了比 YOLO 更快的速度。
最后一点是 SSD 预先设置了先验框,每一个目标设置四个先验框,如下图所示。其中包含中心点坐标以及长、宽(w,h)四个参数。可以看到大尺度特征图更适合检测小目标,小尺度特征图适合检测大一些的目标。
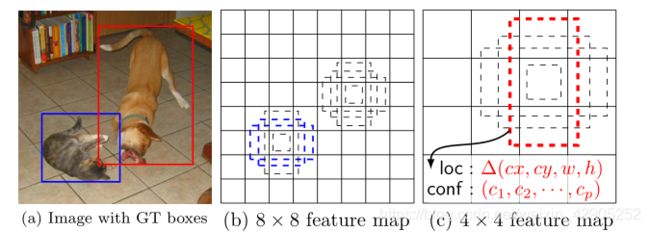
以上是 SSD 的核心设计思路以及整体结构。采用的损失函数思想是局部化损失(例如平滑 L1)和置信损失(例如 Softmax)之间的加权和。
二、pytorch 代码复现
在有了以上知识的基础上,下面介绍基于 pytorch 的代码复现。原论文基于 VOC 以及 COCO 数据集均做了实验,由于 COCO 数据集太大,本文仅基于 VOC 数据集进行训练及验证。
- pytorch代码链接:https://github.com/amdegroot/ssd.pytorch
- 一个较好的教程:https://www.jianshu.com/p/04ea90ebfd95,主要根据这个教程对代码做一些更改,以兼容高版本pytorch
(1)代码复现过程
下面是一些补充知识以及遇到的问题如何解决:
基本配置为 python+pytorch1.2.0,首先下载 VOC 数据集,可通过网盘链接自行下载:
- 链接:https://pan.baidu.com/s/1ZOcEwE5cbDgb_1R5FocAWg
提取码:mwh4
下载好以后可以在代码工程 data\scripts 文件夹下创建名为 VOC2007 的文件夹,并把训练集 VOC2007 下的文件拷贝过来,并在代码中更改数据集路径 (参考上面的教程,Linux系统采用源代码指令即可)
根据教程改一些代码,然后根据自己电脑修改初始参数(RTX1660Ti 最高批次尺寸可设为25,推荐使用16,若使用源代码中32,损失函数会变为无穷大;RTX2080Ti 可设为64)。然后运行 train.py,代码每迭代5000次会保存一次权重,可根据实际情况停止,官方训练迭代了40K次。
![]()
注意:1. 如果上面这句报错,可去掉.double()
2. 损失函数无穷大,可考虑调低学习率
训练完成后,可更改 eval.py 中权重名称,并运行,验证结果。官方 demo 给了视频检测,这里贴一个图像检测的 demo 程序
from __future__ import print_function
import torch
from torch.autograd import Variable
from matplotlib import pyplot as plt
import cv2
import time
import argparse
import sys
from os import path
sys.path.append(path.dirname(path.dirname(path.abspath(__file__))))
from data import BaseTransform, VOC_CLASSES as labelmap
from ssd import build_ssd
weight_path = 'D:\workspace\pytorch\project\ssd.pytorch\ssd.pytorch\weights\ssd300_VOC07_50000.pth'
parser = argparse.ArgumentParser(description='Single Shot MultiBox Detection')
parser.add_argument('--weights', default=weight_path,
type=str, help='Trained state_dict file path')
parser.add_argument('--cuda', default=False, type=bool,
help='Use cuda in live demo')
args = parser.parse_args()
COLORS = [(255, 0, 0), (0, 255, 0), (0, 0, 255)]
FONT = cv2.FONT_HERSHEY_SIMPLEX
def cv2_demo(net, transform):
def predict(frame):
height, width = frame.shape[:2]
x = torch.from_numpy(transform(frame)[0]).permute(2, 0, 1)
x = Variable(x.unsqueeze(0))
y = net(x) # forward pass
detections = y.data
# scale each detection back up to the image
scale = torch.Tensor([width, height, width, height])
for i in range(detections.size(1)):
j = 0
while detections[0, i, j, 0] >= 0.6:
score = float(detections[0, i, j, 0])
pt = (detections[0, i, j, 1:] * scale).cpu().numpy()
cv2.rectangle(frame,
(int(pt[0]), int(pt[1])),
(int(pt[2]), int(pt[3])),
COLORS[i % 3], 2)
cv2.putText(frame, labelmap[i - 1] + '_' + str(score)[:4], (int(pt[0]), int(pt[1])),
FONT, 1, (255, 0, 255), 2, cv2.LINE_AA)
j += 1
return frame
#for i in range()
frame = cv2.imread("car.jpg")
frame = predict(frame)
IMAGE_SIZE = (12, 8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(frame)
plt.show()
if __name__ == '__main__':
net = build_ssd('test', 300, 21) # initialize SSD
net.load_state_dict(torch.load(args.weights))
transform = BaseTransform(net.size, (104 / 256.0, 117 / 256.0, 123 / 256.0))
cv2_demo(net.eval(), transform)
frame = cv2.imread(“car.jpg”) #这句读自己要测试的图片
while detections[0, i, j, 0] >= 0.6 #这句可更改阈值,若无检测结果,可降低阈值重新检测。
(2)代码复现结果



有其他问题欢迎留言交流。