使用 VisualDL 助力遥感影像地块分割 (PaddleSeg 篇)
-
本项目利用 PaddleX 以及 PaddleSeg 两个套件分别实现遥感影像地块分割;
-
更重要的是想给大家展示一下如何利用
VisualDL这个强大的可视化工具来辅助训练及调参;
这个工具非常好用,在模型训练中给了我很大的帮助,也希望看完本文之后这个工具能给你带来帮助,也希望大家能去GitHub给点一点star,让官方把这个工具做的越来越好
![]()
-
最近百度与CCF合作举办了遥感影像地块分割的比赛,希望该项目可以帮助大家提高成绩;
-
PaddleX 篇的目的在于重点介绍VisualDL的Scalar、Image功能,以及如何利用它们来辅助我们的训练,其次会简单介绍一下VisualDL的其他功能; -
PaddleSeg 篇的目的在于重点介绍VisualDL的Graph、Histogram功能,以及如何利用它们来帮助我们进行网络模型结构的设计; -
两篇都是通过遥感影像地块分割为应用背景,在实战中体验如何应用
VisualDL
背景及工具介绍
- 遥感影像地块分割 旨在对遥感影像进行像素级内容解析,对遥感影像中感兴趣的类别进行提取和分类。也就是利用图像分割提取出图像中的房屋,水域,农田等用地类型,在城乡规划、防汛救灾等领域具有很高的实用价值
- PaddleSeg是基于PaddlePaddle开发的端到端图像分割开发套件,覆盖了DeepLabv3+, U-Net, ICNet, PSPNet, HRNet, Fast-SCNN等主流分割网络。通过模块化的设计,以配置化方式驱动模型组合,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。关于PaddleSeg 的更多信息大家可以去 PaddleSeg GitHub 查看
- VisualDL 是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。支持标量、图结构、数据样本可视化、直方图、PR曲线及高维数据降维呈现等诸多功能,同时VisualDL提供可视化结果保存服务。具体细节大家可以自行去 VisualDL Github 主页查看;
安装PaddleSeg
-
可以到PaddleSeg GitHub 页面手动下载,也可以使用命令自动下载,但这两种方式可能由于网络原因都会比较慢;我已经将官方下好的压缩包打包好了,这里是地址;
-
需要注意的是,在该项目中我们想要查看数据增强的过程,但 PaddleSeg 并没有提供对应的接口,所以我对 PaddleSeg 做了一些源码上的改动,保证可以达到我们的目的;改动后的版本也打包好了,我已经将其放在了项目中,是基于 PaddleSeg-v0.7.0 修改的;改动的更多细节就不在这里讲了;执行下面的代码即可完成解压安装;如果你不小心将文件删掉了,可以去这个地址下载;
!unzip work/PaddleSeg.zip -d work/
- 前面的部分我们依旧跟 PaddleX 篇 一致,介绍如何利用 VisualDL-Image 帮助我们选择数据增强策略,利用 VisualDL-Scalar 帮助我们进行训练时超参的调整;
对于这两个功能,该篇主要是介绍如何在 PaddleSeg 套件中使用,更多策略细节请参考 PaddleX 篇;
- 随后该篇的重点是利用 VisualDL-Graph,Visual-Histogram 来帮助我们进行网络模型结构的设计;
设置工作目录
先切换到工作目录,使用PaddleSeg时我们一般就设置工作目录为 PaddleSeg/,脚本默认都是在该目录下执行的;
%cd work/PaddleSeg/
获取数据集
-
我们依旧使用 PaddleX 篇中用到的数据集,原始数据集经过处理之后是可以直接拿来在 PaddleSeg 中用的;关于数据集的更多信息可以去 PaddleX 篇看一下,这里就不介绍了;
-
关于PaddleSeg数据集的具体要求,大家可以去查看一下官方文档;
-
我也将整理好并且经过脚本校验的数据集公开了,这里是数据集的地址;你可以将该数据集直接添加到项目中来,在项目页面点击右上角的修改,在点开的页面中依次点击
下一步->添加数据集,然后在搜索公开数据集的搜索框中搜索:冰河PaddleSeg篇数据集,点击添加后刷新该页面即可
# 注意这里的地址换成你实际数据集地址,点击左侧 数据集 标签,然后点数据集名称右边的 复制按钮,即可复制这里的路径
!unzip /home/aistudio/data/data61269/land_classify.zip -d dataset/
数据集校验
-
我强烈建议做好数据集后使用官方的校验脚本
pdseg/check.py来确认一下我们的数据集是没有问题的,关于这个脚本的使用方法,可以参考这里; -
你如果对这个校验脚本感兴趣的话,可以执行下面的命令再校验一下;但在数据集校验之前你首先需要设置配置文件,PaddleSeg 的脚本基本都是从配置文件中获取信息的;
-
我们的配置文件一般放在 PaddleSeg/configs 目录下,我创建了一个配置文件 land_classify.yaml ,已经放在了该目录下;关于配置文件的具体细节参考官方文档;
!python pdseg/check.py --cfg configs/land_classify.yaml
下载预训练模型
-
PaddleSeg 提供了丰富的分割预训练模型,在这些模型的基础上使用我们自己的数据集进行微调,一般会使我们的训练更加稳定;
-
我们在配置文件中设置了预训练模型为:unet_bn_coco
-
执行下面的脚本即可下载我们需要的预训练模型,关于更多预训练模型的介绍,可以参考这里
!python pretrained_model/download_model.py unet_bn_coco
利用 VisualDL-Image 选择数据增强策略
-
在训练开始前,选择一个合适的数据增强策略是至关重要的。数据增强策略选择的好,可以让模型提升很大的效果;
-
我在知道 VisualDL 之前选择数据增强策略时,完全是跟着感觉走,根本不知道经过增强操作之后的数据长什么样,在其他比赛中,我利用 VisualDL-Image 选择了合适的增强策略,让模型效果提升很多;
-
如何在PaddleSeg中设置增强策略呢?又如何利用VisualDL来帮助我们进行增强策略的选择呢?您接着往下看
-
PaddleSeg中内置了丰富的数据增强策略,完全不需要我们再手动实现一遍,我们只需要在配置文件中进行修改就可以了;
-
我们的配置文件中选择了下面的增强策略,关于更多的数据增强选择,可以查看这里;
-
偷偷告诉你,
MIRROR这个增强你在比赛中一定要用,很关键!
AUG:
# 图像resize的方式有三种:
# unpadding(固定尺寸),stepscaling(按比例resize),rangescaling(长边对齐)
AUG_METHOD: 'unpadding'
# 图像resize的固定尺寸(宽,高),非负
FIX_RESIZE_SIZE: (500, 500)
# 图像镜像左右翻转
MIRROR: True
# 图像上下翻转开关,True/False
FLIP: True
# 图像启动上下翻转的概率,0-1
FLIP_RATIO: 0.5
RICH_CROP:
# RichCrop数据增广开关,用于提升模型鲁棒性
ENABLE: True
# 图像旋转最大角度,0-90
MAX_ROTATION: 15
# 裁取图像与原始图像面积比,0-1
MIN_AREA_RATIO: 0.5
# 裁取图像宽高比范围,非负
ASPECT_RATIO: 0.33
# 亮度调节范围,0-1
BRIGHTNESS_JITTER_RATIO: 0.1
# 饱和度调节范围,0-1
SATURATION_JITTER_RATIO: 0.1
# 对比度调节范围,0-1
CONTRAST_JITTER_RATIO: 0.1
-
执行脚本 pdseg/visualize_seg_transforms.py 即可载入数据并进行增强操作,同时将增强后的结果记录下来;
-
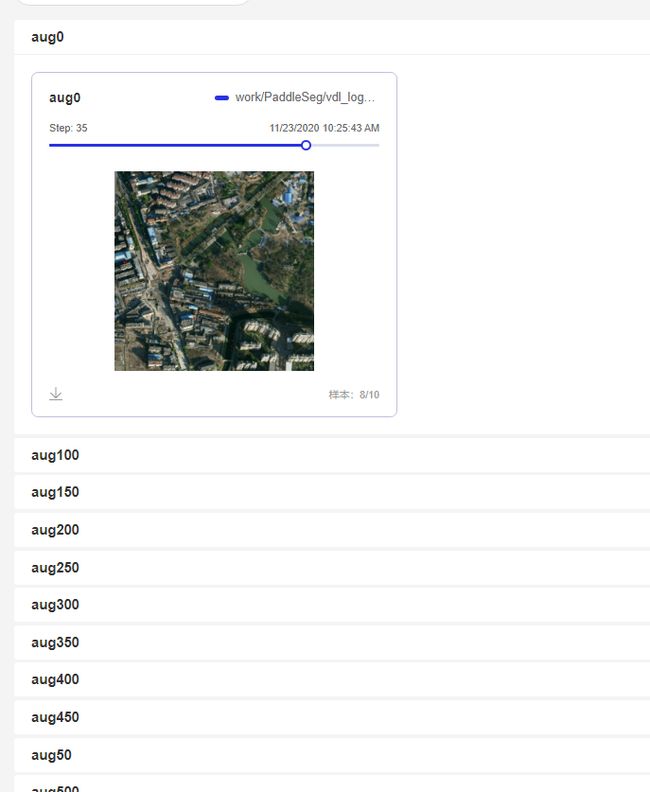
我们每五张记录一次图片,每十张记录在一个窗口中;日志文件保存在 vdl_log_aug ;
-
请不要尝试在 reader 未加载完所有数据就直接 return,这样有时候会报错,虽然并不影响 VisualDL-Image 保存图片;
!python pdseg/visualize_seg_transforms.py --cfg configs/land_classify.yaml --use_gpu
-
之后我们设置 vdl_log_aug 为 logdir, 启动 VisualDL 服务,在 样本数据-样本数据图像 中就可以看到增强后的图片了,每个窗口记录了十张图片,你可以通过点击滑动条的不同部位来查看这十张图片;
-
你可以根据可视化后的结果,选择最合适的数据增强策略;如果你的训练数据集够大,你可以适当留一些质量不怎么高的图片在数据集中,这样一定程度上可以防止模型过拟合,提升模型的鲁棒性;
-
注意我在配置文件中选择的增强策略可能是有点问题的,在这一步一定要利用VisualDL-Image调整几次找到最合适的策略;
-
同样的,我已经利用VisualDL-Service 将这里的日志文件上传了,你可以通过以下链接查看这些图像,关于 VisualDL-Service 的使用,可以参考PaddleX篇最后的部分或者官网,使用起来方便快捷;
-
数据增强日志文件: https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=84717e4e8e435b33bb779f1521eb71b7
这里只点开了一张图,每个窗口中我们都存了十张图,同时你还可以看到下面还有很多窗口,都可以一一点开来看;
利用 VisualDL-Scalar 辅助训练过程
-
其实 PaddleSeg 的某些地方也集成了 VisualDL 的
Scalar、Image功能, 要想在训练时使用这两个功能, -
只需要我们在启动训练时指定参数
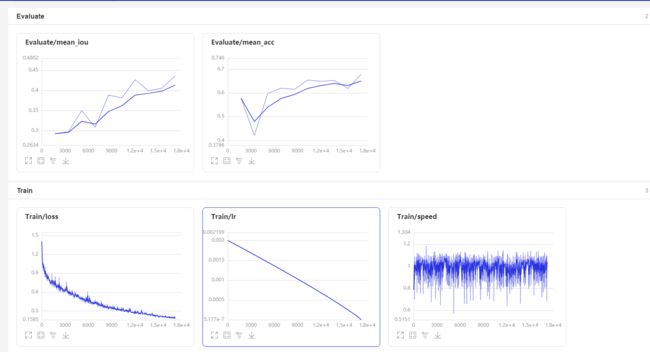
--use_vdl开启功能,并且设置参数vdl_log_dir设置记录文件保存的目录,就可以使用Scalar功能了,你可以查看到loss曲线,lr 曲线,以及speed曲线 -
如果在以上的基础上,你还指定了参数
--do_eval在保存检查点时进行一次evaluate,那么你还会在 eval 之后看到miou 曲线以及macc 曲线 -
如果在以上的基础上,你还在配置文件中设置了
DATASET:VIS_FILE_LIST,就会在每次做完 evaluate 之后对你这个文件中图像做一次预测结果的可视化, 你可以在 样本数据-样本数据图像 标签中,查看到原图,预测图,标签(如果有标签的话),我不建议你在该文件中指定太多的图片,只需要挑几张具有代表性的图片就可以了,否则会拖慢你的训练速度;我们从val_list.txt 中挑出几行写到 test_list.txt 中; -
该篇如何选择合适的学习率就不细讲了,可以参考 PaddleX 篇;值得一提的是,你可以选择在训练的过程中不断调整学习率,而不必使用初始学习率一直到训练结束,具体怎么调整大家可以参考一下其他资料,当然利用VisualDL进行可视化的调整才是最靠谱的,不能只凭他人经验来调整;
我们指定上述的所有参数来使用内置好的所有功能,关于更多训练参数的指定,参考这里
!python pdseg/train.py --use_gpu --do_eval --use_vdl --vdl_log_dir 'vdl_log' --cfg configs/land_classify.yaml
-
时间原因我这里只训练了 200epoch,可以看到 UNet 与 Deeplabv3p 的差距还是有的,不过通过曲线可以看出,再训练多一点轮次应该还是有提升的;因为train_loss 还是在不断下降,验证集的准确度也在不断上升的,所以可以尝试再多训练一些轮次看看效果;
-
训练之后我也利用
VisualDL-Service将训练时的日志上传了,可以参考一下以下链接:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=ace33d308b4706b45aa25aca5a59531a
利用VisualDL-Graph查看网络结构
-
前面选用的是 UNet, UNet结构虽然比较简单,但在数据集样本较少的时候往往也能发挥出很好的效果,是一个非常经典的网络;
-
我们查看一下训练好的模型结构,点击左侧标签可视化->选择模型文件,选择 saved_model/best_model/model.pdmodel 注意这里要选择到文件,不是文件夹;启动VisualDL 服务后,点击网络结构标签,就可以查看到网络结构了,你可以使用鼠标滑轮随意缩放,查看网络的整体结构或者感兴趣的区域,你还可以在右上角的搜索框中搜索想要查看的节点;点击图中的某个节点后,在右侧即可查看该节点的详细属性,op_callstack 中我们可以看到该操作的调用顺序,也很容易找到这个节点对应的代码在哪;
-
UNet 的突出特点就是做了信息融合,也即图中concat 的部分,你可以从图中清晰的看到通过concat节点将浅层的信息与深层的信息进行了融合;
-
网络结构也通过 VisualDL-Service 上传了,参考链接:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=b893ad69c8bcd3996d343b99898ca491
在修改网络结构之前,一定要清楚修改前的网络结构分别对应哪些部分,你在看的时候要将代码与图对应起来,这样比较容易理解,代码下面就有图哦。
- 首先看pdseg/models/modeling/unet.py 中的 70行做上采样的部分;代码中75行的
encode()
def encode(data):
# 编码器设置
short_cuts = []
with scope("encode"):
with scope("block1"):
data = double_conv(data, 64)
short_cuts.append(data)
with scope("block2"):
data = down(data, 128)
short_cuts.append(data)
with scope("block3"):
data = down(data, 256)
short_cuts.append(data)
with scope("block4"):
data = down(data, 512)
short_cuts.append(data)
with scope("block5"):
data = down(data, 512)
return data, short_cuts
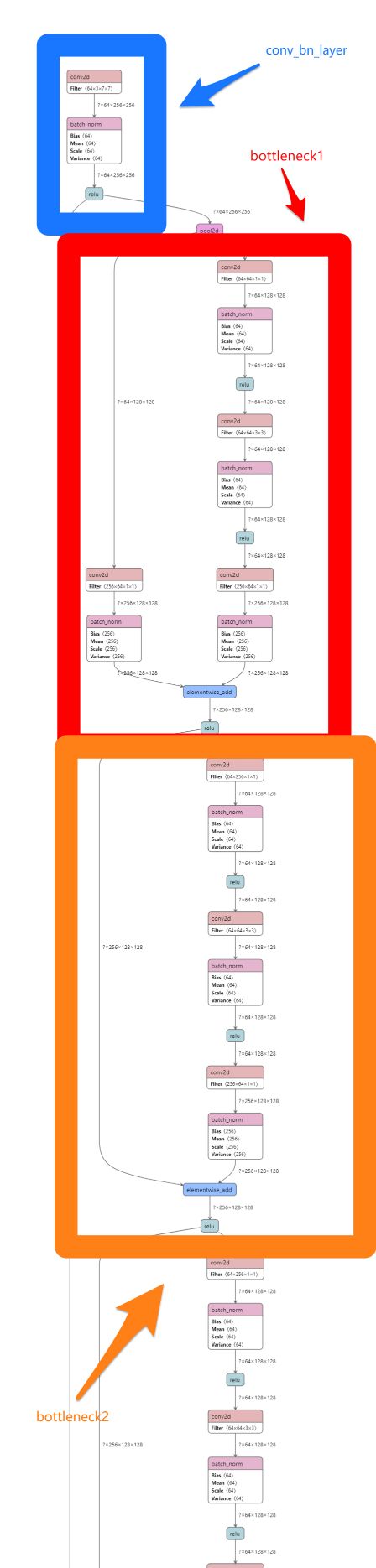
上来先做了一个 double_conv, double_conv 的代码就在最开始的部分,也即 conv+bn+relu 做了两次,这是网络最开始的部分,那么我们看图中的网络结构,找最开的部分,非常清楚的可以看到有这么一个结构,我在图上用红色标了出来;
def double_conv(data, out_ch):
param_attr = fluid.ParamAttr(
name='weights',
regularizer=fluid.regularizer.L2DecayRegularizer(
regularization_coeff=0.0),
initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.33))
with scope("conv0"):
data = bn_relu(
conv(data, out_ch, 3, stride=1, padding=1, param_attr=param_attr))
with scope("conv1"):
data = bn_relu(
conv(data, out_ch, 3, stride=1, padding=1, param_attr=param_attr))
return data
接着看代码,代码随后将处理后的数据进行了保存,这是为了之后做融合用的,先不管它;
再往后只剩下了重复的四次下采样操作 down(), down的代码就在 double_conv 下面,从43行开始,其中的操作也即 max_pool + double_conv ,在图中我们顺着刚才的地方沿着短线向下看,长线是去做融合的,先不看;
下面确实是重复的 pool2d + double_conv 的结构, 我在图中标出了第一个结构,剩下的结构你可以沿着往下看,很轻松的可以看到;
与代码中对应,一共出现了四次这样的结构,直到你看到了一个节点:bilinear_interp
def down(data, out_ch):
# 下采样:max_pool + 2个卷积
with scope("down"):
data = max_pool(data, 2, 2, 0)
data = double_conv(data, out_ch)
return data
- 这之后就进入了
decode的部分了,我们接着看decode部分的代码,就在 encode 的下面,从96行开始,
def decode(data, short_cuts):
# 解码器设置,与编码器对称
with scope("decode"):
with scope("decode1"):
data = up(data, short_cuts[3], 256)
with scope("decode2"):
data = up(data, short_cuts[2], 128)
with scope("decode3"):
data = up(data, short_cuts[1], 64)
with scope("decode4"):
data = up(data, short_cuts[0], 64)
return data
我们看到代码中做了四次上采样操作up() ,up()的代码从51行开始,这里先有一个上采样操作的选择,resize_bilinear 或者 deconv,从图中我们可以看到,选择了 resize_bilinear;
再往后有一个concat操作,这里就是UNet做信息融合的部分了, 紧接着又是一个double_conv,
总结一下 up() 里的操作就是 resize_bilinear + concat + double_conv, 而decode中做了四次 up(),从图中我们也可以很清楚的看到出现了四次 concat,
每一个concat 有两个输入,一个就是短线,是经过 resize_bilinear 后的数据;另一个就是长线,是之前保存的浅层信息;我在图中画出了第一个 up 结构;
def up(data, short_cut, out_ch):
# 上采样:data上采样(resize或deconv), 并与short_cut concat
param_attr = fluid.ParamAttr(
name='weights',
regularizer=fluid.regularizer.L2DecayRegularizer(
regularization_coeff=0.0),
initializer=fluid.initializer.XavierInitializer(),
)
with scope("up"):
if cfg.MODEL.UNET.UPSAMPLE_MODE == 'bilinear':
data = fluid.layers.resize_bilinear(data, short_cut.shape[2:])
else:
data = deconv(
data,
out_ch // 2,
filter_size=2,
stride=2,
padding=0,
param_attr=param_attr)
data = fluid.layers.concat([data, short_cut], axis=1)
data = double_conv(data, out_ch)
return data
- 接下来就剩一个操作了,看代码 decode() 完了之后做了一个
get_logit(),此函数的代码 从110行开始,其中只有一个卷积操作,也就对应图上第四个 up() 之后的节点 conv2d
def get_logit(data, num_classes):
# 根据类别数设置最后一个卷积层输出
param_attr = fluid.ParamAttr(
name='weights',
regularizer=fluid.regularizer.L2DecayRegularizer(
regularization_coeff=0.0),
initializer=fluid.initializer.TruncatedNormal(loc=0.0, scale=0.01))
with scope("logit"):
data = conv(
data, num_classes, 3, stride=1, padding=1, param_attr=param_attr)
return data
代码结束了,但图中还有一部分内容,下面这些节点分为两部分,一部分是 tanspose2 + arg_max + unsqueeze2 这里是生成分割后的结果pred;
另一部分就是剩下的所有节点了,都是用来计算 loss 的,有兴趣的话可以去loss.py 中对照着查看一下,也比较清晰;

利用VisualDL-Graph修改网络结构
-
怎么样,通过 VisualDL 的可视化功能是不是让你对模型结构有了更深的认识呢?代码配上VisualDL-Graph 也变得更加容易理解了;
-
通过上面的训练我们可以看到,相较于PaddleX 篇的 Deeplabv3p,UNet的表现有一点差;关于 UNet 的改进已经有了各种各样的尝试,在AIStudio上也有很多优秀的项目,我们主要参考 Zhou_Lu 大佬的项目:被玩坏的U-Net结构 来进行一些修改,利用VisualDL-Graph 帮助我们理解代码逻辑,并验证模型结构是否正确;利用ResNet做替换,主要就是替换掉 encode 的部分,利用到 ResNet 的特征提取能力以及缓解梯度消失与梯度爆炸的优点;
-
利用 ResNet 作为 UNet 的 backbone, 在 pdseg/models/backbone 我们新建了一个 resnet_for_unet.py 来作为backbone,但是刚才我们也看了 unet.py 中并没有调整 backbone 的代码,所以我们需要修改 unet.py;我们直接参照大佬项目中的 PaddleSeg_base/pdseg/models/modeling/unet.py 来修改,我们这里只使用 resnet,修改好的结构我放在了 pdseg/models/modeling/unet_resnet.py 中。
-
新的配置文件为 unet_resnet.yaml,我们先修改训练轮次为 1 ;查看一下网络结构;我已经将网络结构通过 VisualDL 上传了,
你可以通过链接来查看网络结构:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=a2469150d68a0cfefabd0921aa2911fa
-
注意这部分也要结合图来看哦,代码下面就是图
-
我们是将 UNet 的
encode部分替换成了ResNet,decode 后面的部分并没有改变,打开上面的连接后,我们点击网络结构,
直接拖到最下面,我们从下向上查看网络结构,先是很熟悉的计算 loss 的部分,这里有一点点不一样,多了一个 resize_bilinear,查看节点信息定位到代码 unet_resnet.py 139 行,这里是大佬自己加上的一个操作;
-
接着往上看图,我们可以看到
get_logit那个卷积操作,接着是四个up()操作,再往上就是我们替换的 ResNet 的部分了,我们结合代码看一下: -
从 resnet_for_unet.py 中第51 行开始定义操作,首先是一个 conv_bn_layer,这是在 98 行定义的,也就是说这里
conv_bn_layer = conv + bn + relu
def conv_bn_layer(self,
input,
num_filters,
filter_size,
stride=1,
groups=1,
act=None,
name=None,
data_format='NCHW'):
conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_weights"),
bias_attr=False,
name=name + '.conv2d.output.1',
data_format=data_format)
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
return fluid.layers.batch_norm(
input=conv,
act=act,
name=bn_name + '.output.1',
param_attr=ParamAttr(name=bn_name + '_scale'),
bias_attr=ParamAttr(bn_name + '_offset'),
moving_mean_name=bn_name + '_mean',
moving_variance_name=bn_name + '_variance',
data_layout=data_format)
-
随后紧跟着一个 append 操作,这里保存节点的操作我想你应该知道是用来干嘛的了,没错,就是融合;反映在图上也一定有一条长线连接到后面的某个 concat 操作去,你可以自己验证一下;
-
紧接着是一个
pool2d操作,我们选择了 layers=50, 到循环里是就是在重复做bottleneck_block操作,并且保存了每次操作之后的节点;循环次数也很好算 3+4+6+3 = 16;
我们查看 145行的 bottleneck_block, 包含 conv0 + conv1 + conv2 + short_cut + elementwise_add + relu,
其中
conv0 = conv1 = conv + bn + relu;
conv2 = conv + bn ;
short_cut = conv2 or 不做改动
def bottleneck_block(self, input, num_filters, stride, name, data_format):
conv0 = self.conv_bn_layer(
input=input,
num_filters=num_filters,
filter_size=1,
act='relu',
name=name + "_branch2a",
data_format=data_format)
conv1 = self.conv_bn_layer(
input=conv0,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu',
name=name + "_branch2b",
data_format=data_format)
conv2 = self.conv_bn_layer(
input=conv1,
num_filters=num_filters * 4,
filter_size=1,
act=None,
name=name + "_branch2c",
data_format=data_format)
short = self.shortcut(
input,
num_filters * 4,
stride,
is_first=False,
name=name + "_branch1",
data_format=data_format)
return fluid.layers.elementwise_add(
x=short, y=conv2, act='relu', name=name + ".add.output.5")
我们在图上很容易找到这么一个部分,我已经在图上画出了第一个部分,bottleneck1 中的shortcut 为conv2 , bottleneck2 中的 shortcut 不做改动,因为图比较长,只放了最上面的部分,你可以点击链接查看完整的网络结构;
按我们的计算,应该可以找到连续 16个这样的结构, 并且在第3,3+4, 3+4+6, 3+4+6+3 个结构之后分别都会有一条长线连接到后面的concat操作
你可以自己验证一下,这样整个网络我们就看完了,是不是觉得很清晰呢?如果你想用ResNet的其他版本来替换UNet,可以参考大佬项目中代码,按照这种方式更快更清晰的理解代码;
- 理论上 ResNet 的各种变种都可以用来替换 UNet 的 encode,按照这里的代码思路把该保存的浅层信息保存下来就可以了,主要都是这个 bottleneck 部分;
利用VisualDL-Scalar 辅助新模型的训练
-
下面所有参数与之前保持一致,指定新的配置文件
unet_resnet.yaml开始新的训练;注意:因为之前的预训练模型是基于UNet的,所以在加载权重的时候会跳过很多,我们替换后网络并没有这些权重; -
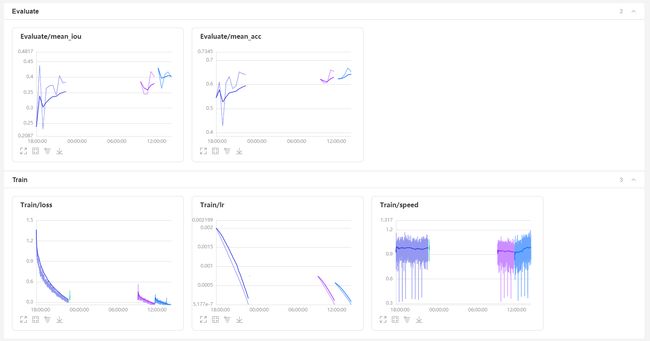
因为更改网络之后 收敛速度变慢了,在训练200epoch后 loss还没有降到UNet 同期水平,我多训练了 100个epoch还是没有降下来,再训练了100epoch 还是没降下来,收敛速度有点堪忧,但整体还是在下降的;
-
我在重复训练的过程中并没有指定新的 vdl_log_dir 这样在启动 VisualDL 时只会读取最新时间戳的那个 log,我写了个脚本 pdseg/classify_log.py 可以将该文件夹下的log文件放到不同的文件夹下,有需要的话参考下面行代码进行调整:
!python pdseg/classify_log.py --vdl_log_dir vdl_log_unet_resnet/
请注意不要在训练的过程中使用这个脚本,因为训练过程会不断记录log,在你移动log文件后,又会自动产生新的 log;
- 分开 log 之后,我通过
VisualDL-Service上传了这几次训练的log,大家可以参考一下,点击右侧的Wall time就可以清晰的对比了:
https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=f5ad6fd804e5bb5273f449106348f5d3
!python pdseg/train.py --use_gpu --do_eval --use_vdl --vdl_log_dir 'vdl_log_unet_resnet' --cfg configs/unet_resnet.yaml
这里是训练时完整的大图,可以看到每张图都有三种颜色的线,就对应我们的三次训练, loss 在不断下降,macc 跟 miou 在不断上升
- 鉴于以上模型 train_loss 下降慢的情况,可能的原因有:
-
训练数据中存在脏数据:回头再通过我分享的链接查看一下增强后的图片,好像确实质量有点低,可能存在一定的影响,心急吃不了热豆腐,开始训练前一定要利用 VisualDL-Image 保证数据是高质量的;
-
可能训练轮次不够:观察loss曲线,确实还有下降的趋势,在保证数据质量之后或许可以增大轮次试一下效果;
-
可能存在梯度消失的情况,也就是说可能我们自己的网络设计的不合理:下面我们就通过
VisualDL-Histogram查看一下是否真的有不合理的地方
利用VisualDL-Histogram 查看参数直方图
-
不同于标量 Scalar,Tensor 通常是多维度的,也就无法直接用曲线图的形式展现出来;
-
我们可以通过 VisualDL-Histogram 功能查看 Tensor 的直方图数据在训练过程中的变化趋势,来深入了解模型各层效果,从而可以精准的调优模型;
-
我写好了一个脚本 pdseg/visualize_seg_params.py, 我们可以通过上面网络结构查看一些 Tensor 的详细信息,取出
输入/Filter/name在脚本中替换 vis_var_names 进行查看
!python pdseg/visualize_seg_params.py
这里很多结构的输入张量的 weights 来展示,具体选了哪些大家可以去脚本中查看一下;
如果你选取了别的参数,并且打开VisualDL没有看到直方图的标签,那么很有可能是你的参数名称写错了;
直方图是一个个切片叠加起来的,其中的颜色有深浅,颜色越深表示时间越早,也就是最初的几个epoch;
针对一个切片,横轴表示其值,纵轴表示数量,如下图,鼠标悬停的点表示以 以0.001为中心的bin中有333个元素
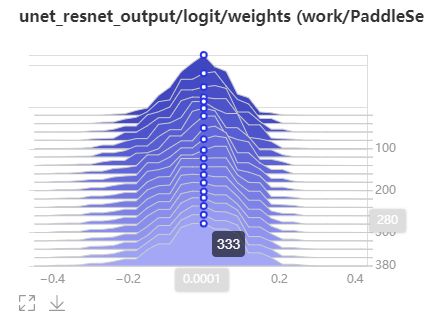
一般权重正常的话直方图就比较类似这种形状,如果某些权重出现了非常平或者非常集中,也就是说形状类似一条竖线或者一条横线,就表明网络可能出问题了;有时候某些权重多轮之后没有太大改变,也是异常的情况;
我们通过 VisualDL-Histogram 就能准确定位出现问题的地方,从而快速的进行调整;
下面是部分截图,完整的直方图参考链接:
https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=8298d39fcaa79f0e1aaba4a32e56fe28
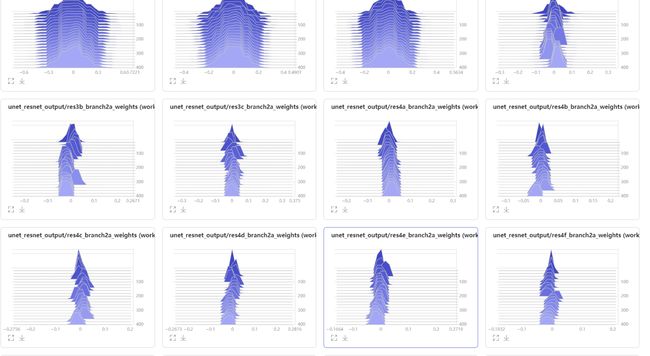
通过上图我们可以看到,我们的网络结构应该是正常的,如果你想看看不正常的直方图长什么样,可以设计一个非常深的网络,应该就可以看出差距了;
总结一下,
本篇首先我们修改了 PaddleSeg 的一部分代码,使其能够使用 VisualDL-Image 来查看数据增强效果;
接着我们使用了 VisualDL-Scalar 来辅助我们的UNet训练;
随后我们通过 VisualDL-Graph 结合代码加深了我们对网络结构的理解,并在此基础上借助可视化,我们很方便的使用 ResNet 替换了 UNet 的 backbone,并再次利用VisualDL-Scalar辅助了这个新网络的训练;
最后我们通过 VisualDL-Histogram 查看了网络设计是否存在异常;
同时贯穿全篇的是我们使用了 VisualDL-Service 进行了可视化结果的分享;
相信在整个过程中你也能感受到 VisualDL 的可视化功能给我们带来的便利,同时也知道了如何在 PaddleSeg 这个套件中使用 VisualDL,赶快在你以后的项目中利用起来吧。
结束语
怎么样?VisualDL是不是很不错呢?快去Github上点点Star吧!
什么?你觉得不太行?点完Star, 去issue里吐槽一下吧,会彳亍起来的!
想深入了解 PaddleX 如何应用VisualDL? 来我的 PaddleX 篇看看吧!
觉得写得不错的话,互相点个关注吧,如果你觉得写的有问题,也欢迎在评论区指正!