深度强化学习系列之(13): 深度强化学习实验中应该使用多少个随机种子?
How Many Random Seeds Should I Use? Statistical Power Analysis in (Deep) Reinforcement Learning Experiments
前言
不断检查实验结果的统计意义是解决深度强化学习中所谓“再现性危机”的强制性方法步骤之一。本论文将解释随机种子数与统计错误概率之间的关系。对于t检验和bootstrap置信区间检验,作者回顾了确定随机种子数的理论准则,用以提供两种算法性能的统计显著性比较。最后讨论了由统计检验所作假设的偏差影响。结果表明,它们会导致对统计误差的不准确评估,并为应对这些负面影响提供指导。
机器学习和深度强化的可复现性是近年来学习成为一个严重的问题。复现RL论文可能会比你想象的要复杂得多,代码库并不总是被发布,而科学论文通常会省略部分实现技巧,。最近Henderson等人对导致这种复现性危机的各种参数进行了彻底的调查Henderson等,2017.他们使用了流行的深度RL算法,如DDPG,ACKTR,TRPO和PPO,以及OpenAI Gym流行的基准测试,如Half-Cheetah,Hopper和Swimmer研究代码库的影响,网络的大小,激活函数,奖励缩放或随机种子。在结果中,他们表明,使用相同的超参数集的相同算法的不同实现导致了截然不同的结果。
也许最令人惊讶的事情是:使用10个不同的随机种子在相同的超参数下运行10次相同的算法,并在5个种子的两次拆分中取平均性能,可能导致学习曲线似乎来自不同的统计分布。 值得注意的是,Henderson等人(包括他们在内)评论的所有深度RL论文都使用了5颗或更少的种子。 更糟糕的是,一些论文实际上报告了最佳运行的平均值。 如(Henderson等人,2017)所论证的,这些方法论可能导致两种算法的性能在不同时表现出不同。 解决此问题的方法是使用更多的随机种子来平均更多不同的试验,以便获得算法性能的更可靠度量。 但是,如何确定应使用多少个随机种子呢? 我们应该使用(Mania,2018)中的5、10或100吗?
这项工作假设有人想测试两种算法之间的性能差异。 第2节给出了定义并描述了差异测试的统计问题,而第3节则提出了两种统计测试来回答该问题。 在第4节介绍了选择样本量的标准准则,以满足两种类型的统计误差的要求。 最后挑战上一节中的假设,并在第5节中提出经验估计错误率的准则。
1、统计问题的定义
同一算法的两次运行通常会产生不同的性能指标。 这可能是由于各种因素造成的,例如随机生成器的种子(称为随机种子或此后的种子),代理的初始状态,环境的随机性等。算法的性能可以被建模为随机变量 X X X ,并且在环境中运行该算法的实现 x x x , 重复该过程 N N N 次,将得到一个统计学样本 x = ( x 1 , ⋯ , x N ) x = (x^{1},\cdots,x^{N}) x=(x1,⋯,xN) , 随机变量通常以其平均值 μ \mu μ 和标准偏差为特征,记为 σ \sigma σ 。当然,你不知道 μ \mu μ 和 σ \sigma σ 的值是多少。 你唯一能做的就是计算他们的估计 x ˉ \bar{x} xˉ 和s:
x ˉ = ^ ∑ i = 1 n x i \bar{x} \hat{=} \sum_{i=1}^{n}x^{i} xˉ=^i=1∑nxi
s = ^ ∑ i + 1 N ( x i − x ˉ ) 2 N − 1 s \hat{=} \sqrt{\frac{\sum_{i+1}^{N}(x^{i}-\bar{x})^{2}}{N-1}} s=^N−1∑i+1N(xi−xˉ)2
其中 x ˉ \bar{x} xˉ 表示经验平均, s s s 表示经验标准分布, 样本量 N N N 越大,则估计的置信越准确。
在这我们比较两种性能为 X 1 X_{1} X1 和 X 2 X_{2} X2 的算法,如果 X 1 X_{1} X1 和 X 2 X_{2} X2 遵循正态分布,描述其差异的随机变量 X d i f f = X 1 − X 2 X_{diff} = X_{1}-X_{2} Xdiff=X1−X2 也遵循带参数的正态分布 σ d i f f = ( σ 1 2 + σ 2 2 ) 1 2 \sigma_{diff} = (\sigma_{1}^{2}+\sigma_{2}^{2})^{\frac{1}{2}} σdiff=(σ12+σ22)21 和 μ d i f f = ( μ 1 − μ 2 ) \mu_{diff} = (\mu_{1}- \mu_{2}) μdiff=(μ1−μ2) ,在这种情况下,估计 X d i f f X_{diff} Xdiff 的平均值是 x ˉ d i f f = x 1 ˉ − x 2 ˉ \bar{x}_{diff} =\bar{x_{1}}-\bar{x_{2}} xˉdiff=x1ˉ−x2ˉ 和估计 σ d i f f \sigma_{diff} σdiff 的平均 s d i f f = s 1 2 + s 2 2 s_{diff} = \sqrt{s_{1}^{2}+s_{2}^{2}} sdiff=s12+s22,效果差异 ϵ \epsilon ϵ 可以定义为两种算法的平均性能之间的差异: ϵ = μ 1 − μ 2 \epsilon = \mu_{1}-\mu_{2} ϵ=μ1−μ2
测试两种算法的性能( μ 1 \mu_{1} μ1 和 μ 2 \mu_{2} μ2 )差异在数学上等同于测试他们之间的分布 μ d i f f \mu_{diff} μdiff 和0的差异,从现在开始我们考虑第二种观点,我们从 X d i f f X_{diff} Xdiff 中抽取样本 x d i f f x_{diff} xdiff ,减去从 X 1 X_{1} X1 和 X 2 X_{2} X2 得到的两个样品 x 1 x_{1} x1 和 x 2 x_{2} x2 。
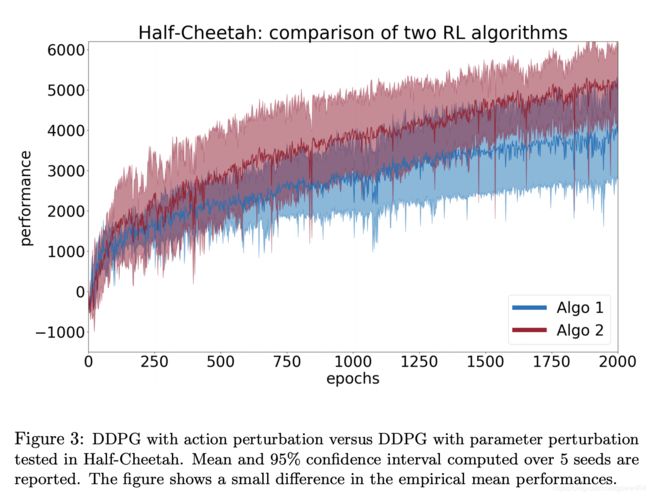
为了说明差异测试,我们使用两种算法(Algo1和Algo2),并在OpenAI Gym框架中对Half-Cheetah环境进行比较(Brockman等,2016)。 实现的算法在这里并不那么重要,稍后会公布。 首先,我们进行一项研究,每个种子有N = 5个随机种子。 图1显示了95%置信区间的平均学习曲线。 学习曲线的每个点是10个评估剧集的平均累积奖励。 Algo i的性能度量Xi是过去10个点的平均表现(即最后100个评估集)。 从图1中可以看出,Algo1的表现优于Algo2。 此外,置信区间似乎并不重叠。 但是,我们需要在得出任何结论之前进行统计测试。请看这实验结果图:

图1中的Algo1与Algo2是两种著名的Deep RL算法,此处在Half-Cheetah基准测试中进行了测试。 报告了5粒种子的平均和置信区间。 我们可以认为Algo1优于Algo2,因为在95%的置信区间之间没有太多的重叠。 但是是否有充分的证据表明Algo1确实表现更好? 下面,我们表明这些算法的性能实际上是相同的,并说明应该使用哪些方法来更可靠地证明两种算法之间的(非)差异。
2、将性能与差异测试进行比较
在差异测试中,统计学家定义零假设 H 0 H_{0} H0 和替代假设 H a H_{a} Ha , H 0 H_{0} H0 假定没有差异,而 H a H_{a} Ha 假设一个:
- H 0 H_{0} H0 : μ d i f f = 0 \mu_{diff}=0 μdiff=0
- H a H_{a} Ha: μ d i f f ≠ 0 \mu_{diff} \neq 0 μdiff=0
这些假设指的是双尾案例。 当一个算法表现最佳的先验可用时(比如Algo1),可以使用单尾版本:
- H 0 H_{0} H0 : μ d i f f ≤ 0 \mu_{diff} \leq 0 μdiff≤0
- H a H_{a} Ha: μ d i f f > 0 \mu_{diff} > 0 μdiff>0
首先,统计检验总是假设零假设。 一旦从 $X_{diff} 收集样本 x d i f f x_{diff} xdiff ,就可以在零假设假设下估计观察数据的概率 p p p(称为p值)为极值。 极端地,一个意味着远离零假设( x d i f f x_{diff} xdiff 远离0)。 p值回答了以下问题:考虑到两种算法的性能没有真正差异,观察这个样本或更极端的样本是多么可能? 在数学上,我们可以用这种方式为单尾情况编写:
p − v a l u e = P ( X d i f f ≥ x ˉ d i f f ∣ H 0 ) p-value = P(X_{diff} \geq \bar{x}_{diff}|H_{0}) p−value=P(Xdiff≥xˉdiff∣H0)
这种双尾情况可以表示为:
p − v a l u e = { P ( X d i f f ≥ x ˉ d i f f ∣ H 0 ) , i f x ˉ d i f f = 0 P ( X d i f f ≤ x ˉ d i f f ∣ H 0 ) , i f x ˉ d i f f ≤ 0 p-value= \begin{cases} P(X_{diff} \geq \bar{x}_{diff}|H_{0}),& if \quad \bar{x}_{diff}=0 \\ P(X_{diff} \leq \bar{x}_{diff}|H_{0}),& if \quad \bar{x}_{diff} \leq 0 \end{cases} p−value={ P(Xdiff≥xˉdiff∣H0),P(Xdiff≤xˉdiff∣H0),ifxˉdiff=0ifxˉdiff≤0
当此概率真的很低时,这意味着极有可能无法用两种没有性能差异的算法来生成收集的样本 x d i f f x_{\mathrm{diff}} xdiff。当单尾情况下p值小于 α \alpha α 时,在显著性level α \alpha α 的差异称为显着性。在双尾情况下低于 α / 2 \alpha / 2 α/2(以解释双面测试2)
2.3、统计误差
在假设检验中,统计检验可以得出 H 0 H_{0} H0 或 H a H_{a} Ha,而每一个都可以是真或假。有四种情况:

这会导致两种类型的错误:
- 当 H 0 H_{0} H0 为真时,type-I 错误会拒绝它,也称为假阳性。
这相当于在没有真正差异的情况下声称一个算法优于另一个算法。请注意,我们称之为显著水平和Type-I错误的 α \alpha α 概率,因为它们都指同一概念。在统计检验的假设下,选择一个显著性水平会强制执行type-I型错误的概率。 - 当 H 0 H_{0} H0 为假时,type-II型错误无法拒绝它,也称为假阴性。
这相当于错过了发表一篇文章的机会,而实际上却有一些东西可以找到。

3 选择适当的统计检验
在统计学中,差异不能百分之百地被证实。为了显示差异的证据,我们使用统计测试。所有的统计检验都作出假设,使它们能够评估p值或第2节所述的一个置信区间。两种误差类型的概率必须受到约束,这样统计检验才能得出可靠的结论。在这一节中,我们将介绍两个用于差异测试的统计测试。如Henderson等人的建议。(2017),两样本t检验和bootstrap置信区间检验可用于此。
3.2 T-test and Welch’s t-test
我们要检验两个总体平均数相等的假设(零假设h0)。假设两个总体(两种算法)的方差相等时,可以使用2样本T-test检验。然而,当比较两种不同的算法(如ddpg与trpo)时,这种假设很少成立。在这种情况下,应使用称为 Welch’s t-test检验的两样本检验对不等方差的适应性。当标准偏差相等时,这两种试验是严格等价的。t检验有几个假设:
- 数据测量的尺度必须连续且有序(可以排序)。这是RL的情况。
- 数据是通过从人群中收集代表性样本获得的。这在RL看来是合理的。
- 测量是相互独立的。这在RL看来是合理的。
- 数据是正态分布的,或者至少是钟形的。正态律是一个涉及到单位的数学概念,任何事物都不是完全正态分布的。此外,算法性能的测量可能遵循多模态分布。在第5节中,我们研究了偏离正态性的程度。
在这些假设下,可以计算由Welch-Satterthwaite equation方程估计的Welch-t检验的t统计量t和自由度 ν \nu ν ,例如:
t = x d i f f s 1 2 N 1 + s 2 2 N 2 , ν ≈ ( s 1 2 N 1 + s 2 2 N 2 ) 2 s 1 4 N 1 2 ( N 1 − 1 ) + s 2 4 N 2 2 ( N 2 − 1 ) t=\frac{x_{\mathrm{diff}}}{\sqrt{\frac{s_{1}^{2}}{N_{1}}+\frac{s_{2}^{2}}{N_{2}}}}, \quad \nu \approx \frac{\left(\frac{s_{1}^{2}}{N_{1}}+\frac{s_{2}^{2}}{N_{2}}\right)^{2}}{\frac{s_{1}^{4}}{N_{1}^{2}\left(N_{1}-1\right)}+\frac{s_{2}^{4}}{N_{2}^{2}\left(N_{2}-1\right)}} t=N1s12+N2s22xdiff,ν≈N12(N1−1)s14+N22(N2−1)s24(N1s12+N2s22)2
图2帮助理解这些概念。它表示与 X d i f f X_{diff} Xdiff 对应的t统计量在 H 0 H_{0} H0 (左分布)和 H a H_{a} Ha (右分布)下的分布。
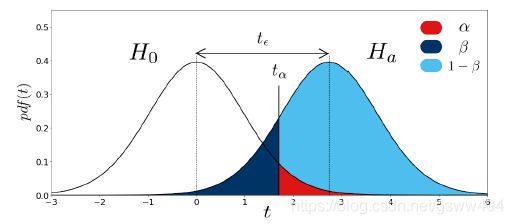
图2是T-test检验假设下 H 0 H_{0} H0 和 H a H_{a} Ha 的表示。红色、深蓝和浅蓝色分布下的区域分别对应于type-I型误差 α \alpha α 、type-II型误差 β \beta β 和统计功率 1 − β 1-\beta 1−β 的概率。
H 0 H_{0} H0 假设 μ d i f f = 0 \mu_{diff}=0 μdiff=0 ,因此,分布以0为中心。
H a H_{a} Ha 假设了一个(positive)差异 μ d i f f = ϵ \mu_{\mathrm{diff}}=\epsilon μdiff=ϵ, 因此,分布被对应于 ϵ , t ϵ \epsilon, t_{\epsilon} ϵ,tϵ 的t值移动
t分布由其概率密度函数 T d i s t r i b ν ( τ ) T_{d i s t r i b}^{\nu}(\tau) Tdistribν(τ) (图2中的左曲线)进行密度化,该函数由 ν \nu ν 参数化。累积分布函数 C D F H 0 ( t ) C D F_{H_{0}}(t) CDFH0(t) 是评价 T d i s t r i b ν ( t ) T_{distrib}^{\nu}(t) Tdistribν(t) 下 τ = − ∞ \tau=-\infty τ=−∞ to τ = t \tau=t τ=t 面积的函数。写为:
p -value = 1 − C D F H 0 ( t ) = 1 − ∫ − ∞ t T d i s t r i b ν ( τ ) ⋅ d τ p \text { -value }=1-C D F_{H_{0}}(t)=1-\int_{-\infty}^{t} T_{d i s t r i b}^{\nu}(\tau) \cdot d \tau p -value =1−CDFH0(t)=1−∫−∞tTdistribν(τ)⋅dτ

3.2 自举(Bootstrapped)置信区间
自举(Bootstrapped)置信区间是一种不假设 X d i f f X_{diff} Xdiff 分布的方法。它估计di的置信区间ci1,给定一个样本xdi,其特征是其经验平均xdi。它是通过在xdi中重新采样并计算每个新生成的样本的平均值来完成的。测试根据xdi的置信区间是否包含0来决定。它不计算p值。在不假设数据分布的情况下,无法计算分析置信区间。这里,xdi遵循未知分布f。可以使用bootstrap原理计算置信区间ci1的估计。假设我们有一个xdi示例,它由n个性能差异度量组成。通过在x di内部进行替换采样,得到了大小为n的经验bootstrap样本xdi。Bootstrap原理然后说,对于在原始样本上计算的任何统计量U和在引导样本上计算的U,U中的变化很好地近似于U5的变化。因此,经验平均值的变化,如其范围,可以通过引导样本的变化来近似。bootstrap-con dence间隔测试假设样本大小足够大,能够正确地表示底层分布,尽管这在实践中可能难以实现。与此的偏差
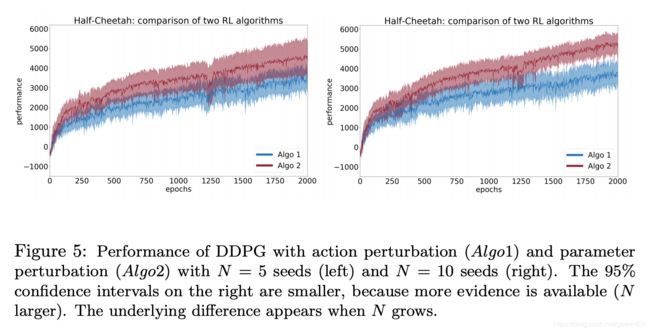
4.3 理论上:power分析用于选择样本大小
-
step 1 - 进行试点研究
-
step 2 - 选择样本量

- step 3 - 运行统计测试
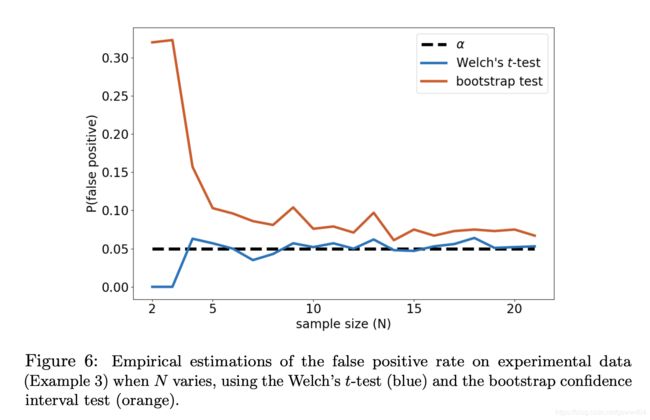
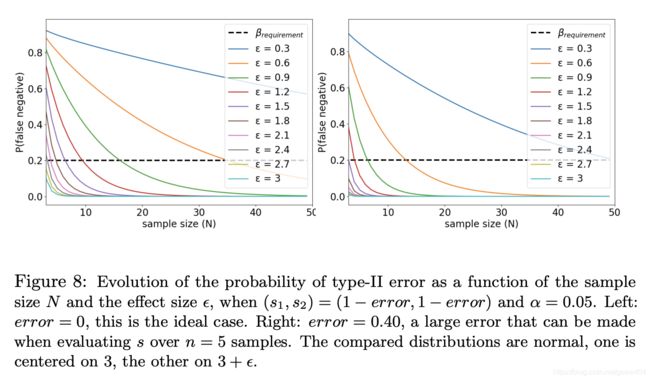
4.4 在实践中:偏离假设的影响
-
type-I型误差的经验估计
-
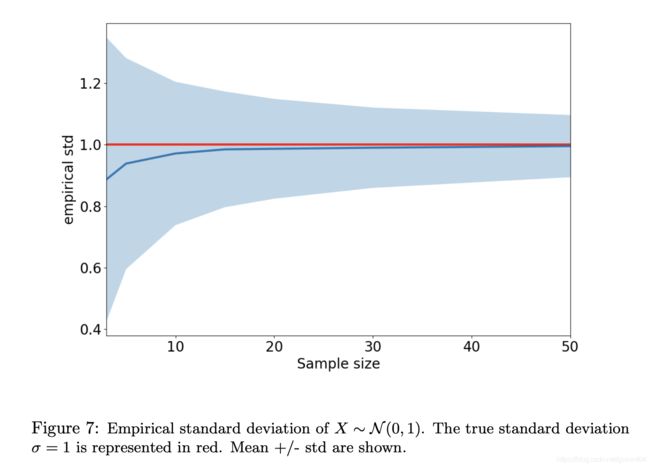
经验标准差的影响
参考文献:
[1]. https://arxiv.org/pdf/1806.08295.pdf