知识图谱 概念与技术 第三章
知识图谱 概念与技术
肖仰华等编著 中国工信出版集团 电子工业出版社
第三章 词汇挖掘与实体识别
知识图谱中的实体识别基本思路: 当一个词汇在某个上下文表达的是某个预定义概念时,则是一个实体。 例如“刘德华是中国香港男歌手” 中“刘德华”属于“人物”
等价关系、等级关系、相关关系
等价关系:简写等
等级关系:子类,细分等
相关关系:上下位关系、索引关系等 (例如“复旦大学 ”和“985院校“为上下位关系
短语抽取
短语:描述一个完整、不可分割的语义单元
短语质量评估:频率、一致性、信息量、完整性
无监督短语抽取:
语料-> 候选短语生成(n gram, 卡阈值过滤)-> 统计特征计算(例如 tfidf、PMI、左邻字熵和右邻字熵等)-> 质量评分(特征值融合,家全球和等)-> 排序输出
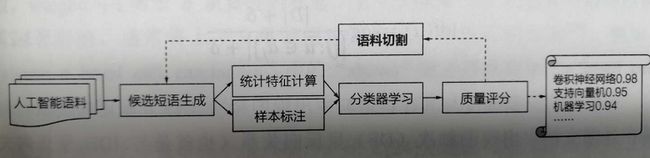
有监督短语抽取:
语料-> 候选短语生成 -> 统计特征计算+样本标注( 人工标注/ 百度百科、维基百科等)-> 分类器学习(决策树、随机森林、svm) -> 质量评分 -> 排序输出
质量评分而非直接采用词频统计原因: ”支持向量机“出险次数低于”向量机‘和“支持向量” =>添加语料切割, 通过分类器得到高质量短语,对语料切割, 重新统计词频,迭代
统计指标特征
- TFIDF、C-value(子短语频次减去负短语频次)、NC-value、PMI 点互信息、 左邻字熵和右邻字熵
- TFIDF: 挖掘能够有效代表某篇文档特征的短语
- C-value:考虑了短语与其父短语的关系来挖掘高质量短语
- NC-value:在C-value基础上进一步考虑了上下文来挖掘高质量短语
- PMI:挖掘组成部分一致性较高(经常一起搭配)的短语
- 左右邻字熵:挖掘左右邻丰富的短语
同义词挖掘
意义相同或相近的词
① 不同国家语言, “玩具”、“toy”
②相同含义的词:’教室“ ”课堂“
③ 人名、号、雅称等:”周杰伦“ ”周董; “宋太祖”、“赵匡胤”
④别称、俗称: “番茄”、“西红柿”; “小儿麻痹症” “骨髓灰质炎”
⑤简称 “江西省” “赣'"
挖掘方法:
- 同义词资源(字典、网络字典、百科词条)、
- 模式匹配 (XX又称Y) P97
- 自举法 通过同义词扩展模板 迭代
- 其他方法:序列标注模型 彼岸花(ENT)-也(S_B)-叫 (S_I) - 曼珠沙华(ENT),原产于(O)-中国(ENT)-长江流域(ENT);基于图模型
搜索引擎
缩略词
应用:实体链接、情感分析、事件抽取等
方法:一 缩略词检测及抽取; 二 规则或机器学习预测缩略词
一 缩略词检测及抽取: 主要是模式匹配, 噪声太多,需要统计信息和机器学习方法过滤(词频、卡方、互信息、最大熵、二元分类机器学习模型:SVM\LR)
机器学习二元分类特征:1. 统计指标 2. 文本特征:字符匹配程度(缩略词中是否包含全称以外的词、缩略词与全称的编辑距离、缩略词和全称长度差异、缩略词中的字在全称中的位置)词性特征
枚举和剪枝: 枚举所有可能缩略形式,排除文本中未出现,判断缩略词和原词出现语境(共现词越多越相近)
二 规则或机器学习预测缩略词:
规则:词性、位置、词之间相互关联
CRF: 字、词、位置、词性、词的关联特征
深度学习:LSTM
实体识别
命名实体是一个词或短语,命名实体识别:在文本中定位命名实体的边界并分类到预定义类型集合的过程。
实体是一个认知概念,实体在文本中不同表示形式或提及方式被称为实体指代
NER抽取, 输入:句子对应的单词序列: s=
例如:”姚明 出生 于 上海“ , <1,1, 人物> <4,4,地点,>
粗粒度命名实体识别:一个命名实体只分配一种类型; 细粒度命名实体识别:一个命名实体分配多种类别
传统NER方法:
<1> 基于规则、词典、在线知识库的方法 (Hownet,挂到已有知识库相类似的节点下,上下位词)
<2>监督学习:序列标注 HMM、CRF。 典型特征:但此级别特征(词法,词性标签)、列表查找特征(例如维基百科地名录、DBpedia地名词典)、文档和语料特征(语法、共现)

<3>半监督学习
基于深度学习的NER
BiLSTM-CRF
1 输入的分布式表示(词向量、字向量、混合表示)
2 上下文编码器:①CNN,② RNN( BiLSTM、GRU)
3 标签解码器:①全连接层+softmax, 如果多标签 将softmax改为sigmoid; 或 ② CRF, CRF可以对标签之间的关系进行建模,提高NER的准确性 ③ 循环神经网络RNN, 实体类型数量很大时,比其他解码器训练速度更快
新的方法:
- attention
- 迁移学习, 具有相同标签集