深度学习和神经网络_深度学习概论——吴恩达DeepLearning.ai深度学习笔记之神经网络和深度学习(一)...
公众号关注 “DL_NLP”
设为 “星标”,重磅干货,第一时间送达!

◎ 原创 | 深度学习算法与自然语言处理
◎ 作者 | Dedsecr
1. 什么是神经网络?
1.1 房价预测
已知房屋的面积、价格,想要拟合一个根据房屋面积预测房价的函数。
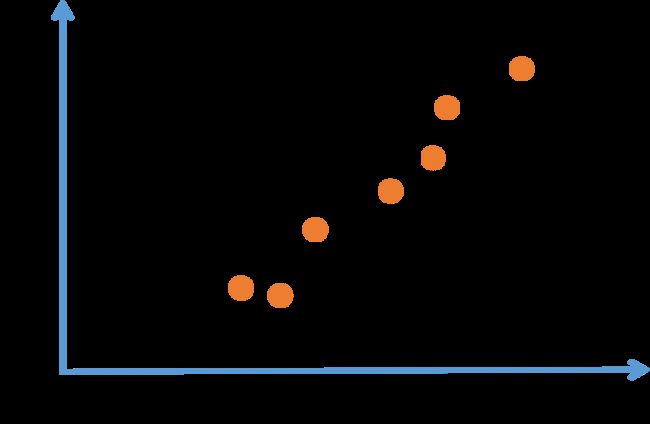
按照传统的方法,我们使用线性回归来解决这个问题,我们可以拟合出一条直线。并且我们知道价格永远不会是负数的。因此,为了替代一条可能会让价格为负的直线,我们把直线弯曲一点,让它最终在零结束。这条黑色曲线就是我们需要的函数,用于根据房屋面积预测价格。有部分是零,而直线的部分拟合的很好。

这几乎可能是最简单的神经网络。
我们把房屋的面积作为神经网络的输入 ,通过一个节点(一个小圆圈),最终输出了价格 。小圆圈就是一个单独的神经元。这样,我们的网络实现了上图拟合出来的函数功能:输入面积,完成线性计算,取不小于零的值,完成房价估算。

像这样从趋近于零开始,然后变成一条直线的函数被称作ReLU激活函数,它的全称是Rectified Linear Unit。rectify(修正)可以理解成 ,这也是你得到一个这种形状的函数的原因。
现在我们知道上述的神经网络是简单的,小规模的。那么大型神经网络就是把很多像这样的单个神经元堆叠起来形成的。可以把这些神经元想象成一个个单独的乐高积木。构建大型神经网络就和搭积木一样。
1.2 更复杂的房价预测
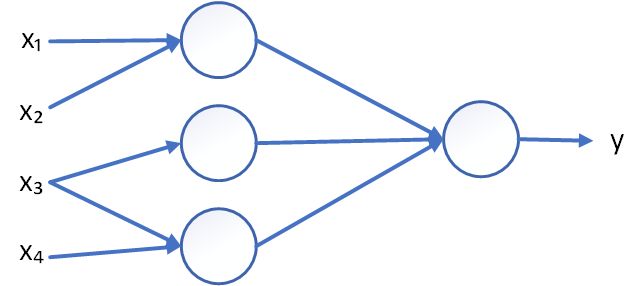
现在我们不仅知道房子的面积,还知道房子的其他信息,比如卧室的数量。有时房子能居中的人口数量也会影响房价,人们关心房子是否能满足自己家庭的人数需求。还知道房子对应的邮编,比如邮编可以反映一些步行化程度。还有比如周围人群的富裕程度,周围学校的质量。我们可以粗略画出如下图片:

在图上每一个画的小圆圈都可以是ReLU的一部分。基于房屋面积和卧室数量,我们可以估算家庭人口,基于邮编,可以估测步行化程度或者学校的质量。这些决定人们乐意花费多少钱。
在这个更复杂的例子中,最左侧的 个项是输入的内容,称为 ,右侧最终的结果 就是房价。将里面的神经元堆叠起来,就形成了现在稍微大一些的神经网络。神经网络的其中一个神奇之处在于:当你实现了神经网络,你只需要输入 ,就可以得到结果 ,不管训练集有多大。所有的中间过程它都会自己完成。
那么实际上我们只需要做的工作是:已知左边的 个输入特征,神经网络进行工作得出右侧的结果。
同时我们注意到下图左边 个圆圈,被称之为“隐藏单元”,它们每个都从输入的 个特征获得自身输入。在神经网络中,你决定在这个结点中想要得到什么,然后用所有的 个输入来计算想要得到的。
值得注意的是,神经网络给予了足够多的关于 和 的数据,给予了足够的训练样本有关 和 。神经网络非常擅长计算从 到 的精准映射函数。
这就是一个基本的神经网络,你会发现自己的神经网络在监督学习的环境下是如此有效和强大。只需要输入 ,我们就能得到 ,就好像我们在刚才房价预测的例子中看到的效果。
2. 用神经网络进行监督学习
关于神经网络也有很多的种类,考虑到它们的使用效果,有些使用起来恰到好处,但事实表明,到目前几乎所有由神经网络创造的经济价值,本质上都离不开一种叫做监督学习的机器学习类别。
2.1 用例子来解释监督学习
在监督学习中你有一些输入 ,你想学习到一个函数来映射到一些输出 ,比如我们之前提到的房价预测的例子,你只要输入有关房屋的一些特征 ,试着去输出或者估计价格 。我们举一些其它的例子,来说明神经网络已经被高效应用到其它地方。
| 输入(x) | 输出(y) | 应用场景 | 对应神经网络 |
|---|---|---|---|
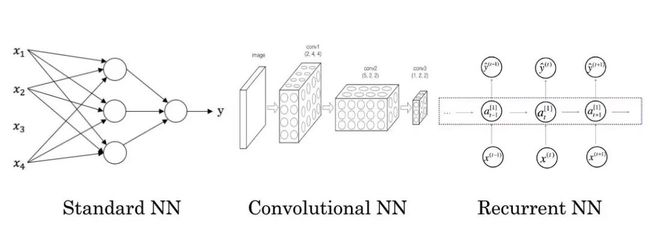
| 房子特征 | 房价 | 房地产 | 标准神经网络(Standard NN) |
| 广告,用户信息 | 是否点击广告 | 在线广告 | 标准神经网络(Standard NN) |
| 图片 | 对象(图片是不是猫) | 照片识别 | 卷积神经网络(Convolutional NN) |
| 语音 | 文字 | 语音识别 | 循环神经网络(Recurrent NNs) |
| 英语 | 汉语 | 机器翻译 | 循环神经网络(Recurrent NNs) |
| 图像、雷达信息 | 车辆位置 | 自动驾驶 | 卷积神经网络(Convolutional NN) |
- 在线广告:向用户展示最有可能点开的广告。
- 计算机视觉:输入图片,来识别图像包含的信息。
- 语音识别:输入音频片段,输出文本记录。
- 机器翻译:输入英语句子,输出一个中文句子。
- 自动驾驶:输入一幅图像,就好像一个信息雷达展示汽车前方有什么,来告诉汽车在马路上面具体的位置。
各种神经网络的应用:
- CNN:图像数据。
- RNN:序列数据,例如音频,语言。
3. 机器学习对于结构化数据和非结构化数据的应用
3.1 结构化数据
结构化的数据指的是数据库里的数据,比如预测房价你有个数据库,记录每个房子的基本信息和房价。
| 面积 | 卧室数量 | 其他一些信息 | 房价 |
|---|---|---|---|
| 100 | 3 | 500 万 | |
| 70 | 2 | 350 万 | |
| 40 | 1 | 250 万 |
结构化的数据的特点就是每个属性值都有明确的定义。
3.2 非结构化数据
非结构化数据,比如:音频,图像,或者文字内容。
计算机理解非结构化数据更难。但是人类很擅长处理非结构化数据。神经网络的兴起,使得计算机处理非结构化的数据不断变强。这样就提供了很多创造丰富应用的机会。
4. 为什么深度学习会兴起?
如果在深度学习和神经网络的背后技术概念已经有好几十年了,为什么现在才突然流行起来?
在本节中我们来看一些让深度学习流行起来的主要因素。这会帮助你在实际工作中发现好机会来用这些东西。为什么机器学习现阶段突然变得那么厉害,我们可以先看如下图:
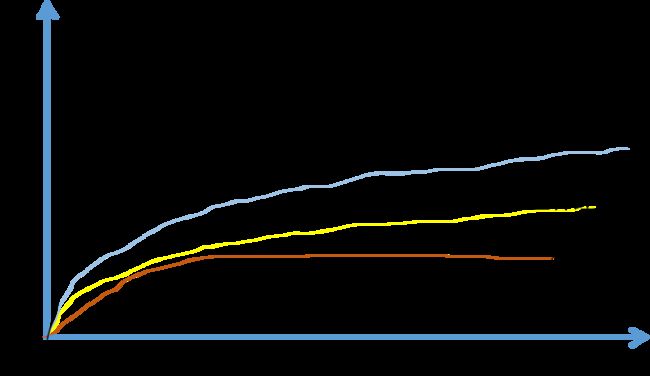
假设横坐标代表通过机器学习来完成某一项任务所需要的数据量,纵坐标代表这个机器学习算法完成任务的准确度。比如通过一大堆图片的学习来判断图片里面是否有猫。根据这个图像可以发现,把传统机器学习算法的表现,比如说支持向量机,或者逻辑回归,作为数据量的一个函数,你得到的曲线就是这样。一开始随着数据量增加,它的性能会大幅上升,但一段时间后它的性能进入平台期。那是因为这样的模型无法处理海量数据。
而过去 20 年,在社会中我们遇到的很多问题早期只有相对较少的数据量。多亏了数据化社会,现在获取海量数据相当容易。人类花了很多时间在数字王国中,在电脑,网络,移动设备上。如何数字设备上的活动都能创造数据。还有小巧的摄像机安装在手机上,还有各类传感器,我们收集了越来越多的数据。在过去的 20 年中,我们获取到的数据远超过传统的学习算法能发挥作用的规模。
如果使用神经网络模型的话,训练一个小型神经网络,性能会像黄线所示那样。如果是一个中型规模的神经网络,那么性能会更好。如果是大型的,性能会越来越好。
需要注意两点:
- 需要训练一个规模足够大的神经网络,以发挥数据规模量巨大的优点。
- 要达到横坐标的位置,需要大量数据。
因此我们常说:规模一直在推动深度学习的进步。规模不只是神经网络的规模,还有数据的规模。要在神经网络上获得更好的表现,在今天最可靠的手段就是要么训练一个更大的神经网络,要么投入更多的数据。这只能在一定程度上起作用,因为最终会耗尽数据,或者神经网络规模太大,训练的时间太久。但是提示规模已经让我们在深度学习中获得大量进展。
为了使这个图在技术上更准确一些,在 x 轴上我们标出数据量。从技术上说,这是“带标签的数据”量。带标签的数据,在训练样本时,我们有输入 x 和标签 y。
图中还有很多细节。如下图:

在训练集数量不大的情况下,各种算法性能的相对排名不是很确定,效果取决于人手工设计的组件。很可能比如有人训练出一个支持向量机(SVM),很可能因为设计的非常好,在数据量不大的情况下 SVM 表现的更好。因此在图中左侧区域,各类算法的性能排名不是很明确。只有在大数据领域,在图中右边,数据量庞大的情况下,我们才能见到神经网络稳定的领先于其他算法。
4.1 规模驱使着深度学习的发展
在深度学习崛起的初期,是数据和计算能力规模的进展,训练一个特别大的神经网络的能力,无论是在 CPU 还是 GPU 上,是这些发展使我们获得巨大的进步。但是渐渐地,尤其在近几年,我们也见证了算法上面的极大创新,有趣的是,许多算法上的创新都是为了让神经网络运行的更快。举个例子:神经网络方面一个巨大的突破是从 sigmoid 函数转换到这样的 ReLU 函数。

使用 sigmoid 函数,机器学习问题是在两侧区域,sigmoid 函数的斜率接近于 ,所以学习会变得非常缓慢,因为用梯度下降法,梯度接近于 时参数会变化的很慢,学习也会变得很慢。而通过改变激活函数,梯度不会趋于 。而右侧函数的斜率在左侧是 ,但是右侧不是。因此我们只需将 sigmoid 函数转换成 ReLU 函数,就能使梯度下降法运行得更快。这就是一个有点简单的算法创新例子。但是最终算法创新带来的影响是增加计算速度。这也使得我们可以训练规模更大的神经网络。或者在合理的时间内完成计算,即便在数据量很大,神经网络很大的情况下。
快速计算很重要的另一个原因是训练神经网络的过程很多时候是凭直觉的。你有了新的关于神经网络架构的想法,然后写代码实现,然后运行一下进行试验,可以告诉你你的神经网络效果有多好。知道结果后在回去改神经网络中的一些细节。你不断重复这个循环。当你的神经网络需要很长时间去训练,就需要很长时间走一圈循环。在实现神经网络时,迭代速度对你的效率影响非常大。
如果你有一个想法直接去试,10 分钟后就可以看到结果,或者花费 1 天。如果训练神经网络花了 1 个月的时间(有时确实需要这么长时间),如果你能快速得到结果,你就可以尝试更多的想法。你就可以发现适合你的应用的神经网络。
所以计算速度的提升有助于提高迭代速度,让你快速得到结果。也同时帮助了神经网络的从业人员和有关项目研究人员在深度学习过程中迭代更快。所有这些都极大的推动了整个深度学习社区的研究,快到让人难以置信。
人们一直在发明新的算法,取得不断进步,这些力量支持了深度学习的崛起。好消息是这些力量还在不断发挥作用,让深度学习更进一步。在数据上,我们的社会还在不断产生数字化数据。在计算上,GPU 这类硬件设备还在发展。网络速度更快,硬件速度更快,我们有信心实现超级大规模神经网络。
