【YOLOv4探讨 之三】mosaic数据增强
【YOLOv4探讨 之三】mosaic数据增强
- mosaic数据增强原理
- darknet框架下mosaic数据增强的代码解读
-
- 参数配置
- 处理过程
-
- 判断采用哪种数据增强模式
- 获取图像路径
- 设置初始平移量
- 图像偏移与truth值更新
- 常规数据增强
- 图像填充
- 绑定目标参数
- 步骤综合
- 总结
最近太忙,久未更新,对不住大家。进入正题,我们聊一聊YOLOv4中使用的mosaic数据增强。关于mosaic数据增强相关文章不少,三个月前这个方面的学习开了个头,那时候各路诸侯都是以TensorFlow框架为主,我这里依然坚持分析研究darknet框架下的数据增强。
mosaic数据增强原理
YOLOv4中在载入图片数据时同步进行mosaic数据增强。
mosaic数据增强基本原理就是在训练集中随机选择若干个(一般是4个)图像,经过裁剪拼接形成新的训练集元素,可以缓解训练集元素少或者增强识别能力,是cutmix数据增强的升级版,基本原理如下图。

darknet框架下mosaic数据增强的代码解读
参数配置
darknet框架下是否使用mosaic数据增强通过cfg文件进行配置,核心的参数包括
由于实际的yolo4.cfg中只有
#cutmix=1
mosaic=1
其他的配置参数我们通过parser.c文件中parse_net_options函数中的一些代码来看:
net->flip = option_find_int_quiet(options, "flip", 1);//翻转,默认为flip =1,
net->blur = option_find_int_quiet(options, "blur", 0);//糊化,默认不糊化
net->gaussian_noise = option_find_int_quiet(options, "gaussian_noise", 0);//高斯噪声,默认不加噪声
net->mixup = option_find_int_quiet(options, "mixup", 0);//使用数据增强,默认为0
int cutmix = option_find_int_quiet(options, "cutmix", 0); // cutmix增强,默认为0
int mosaic = option_find_int_quiet(options, "mosaic", 0); // mosaic增强,默认为0
//对使用不同类型的数据增强进行值定义
if (mosaic && cutmix) net->mixup = 4;
else if (cutmix) net->mixup = 2;
else if (mosaic) net->mixup = 3;
net->letter_box = option_find_int_quiet(options, "letter_box", 0);
net->mosaic_bound = option_find_int_quiet(options, "mosaic_bound", 0);
net->contrastive = option_find_int_quiet(options, "contrastive", 0);
net->contrastive_jit_flip = option_find_int_quiet(options, "contrastive_jit_flip", 0);
通过以上函数将关键参数传入net,再传给detector.c中的train_detector函数中的args ,再通过load_thread = load_data(args)进行数据载入和同时进行数据增强。
对模型进行训练时使用load_data_detection函数1:
data load_data_detection(int n, char **paths, int m, int w, int h, int c, int boxes, int truth_size, int classes, int use_flip, int use_gaussian_noise, int use_blur, int use_mixup, float jitter, float resize, float hue, float saturation, float exposure, int mini_batch, int track, int augment_speed, int letter_box, int mosaic_bound, int contrastive, int contrastive_jit_flip, int show_imgs)
这里对每个参数进行分析:
int n表示一个完整的批次处理的图片数量,在cfg文件中的n = batch*ngpus,在单GPU条件下,一个批次通常取64张图片
char **paths 表示训练数据集的路径的集合
int m 表示所使用的数据集的所有图片数量
int w,int h,int c 表示载入图片后归一化的用于模型处理的图片数据宽、高和通道数,是一个正方形图片数据,一般w = h
int boxes表示一张图片最多能够识别出来的目标数,即一个层中使用的最大目标识别框的个数,对应args.num_boxes = l.max_boxes = option_find_int_quiet(options, "max", 200),在yolov4.cfg文件中没有明确,表示一次最多支持200个目标识别框
int truth_size 表示真值包含的元素个数一般为5
int classes 表示可以分类的数量,YOLOv4标准型为80个
int use_flip 表示是否使用翻转,默认为1,表示使用翻转
int use_gaussian_noise 表示是否加噪声,默认不加
int use_blur 表示是使用糊化,默认不使用
int use_mixup 使用的混合数据增强的种类,包括cutmix,mixip,mosaic等
int jitter表示图像抖动范围,默认0.2,既然是抖动就可能往左往右都有
float resize 表示图像缩放的比例,默认不缩放
float hue 表示色调(色相),默认为0,表示色调(色相)没有偏移
float exposure 表示曝光度,通常曝光度设置为1
int mini_batch 表示最小批次,mini_batch = batch / subdivs,表示每次实际处理图像的批次
int track 在cfg文件中未定义track,则在进行数据增强时不采取序列路径,而是随机抽取图像进行组合
int augment_speed 表示增强速度,默认为2,当依序列获取增强数据路径时,每次跳过的图像索引个数
int letter_box 表示是否使用letter_box变换,一般默认为0,表示不使用。图像进入神经网络后被拉伸成长宽比为1的正方形,会造成图像失真,letter_box变换就是将图像还原成原始比例,放在正方形中,将剩余的图像填入灰色。在YOLOv3中使用test_detector函数进行探测时直接进行了这个操作,在YOLOv4中专门设置一个if(letter_box)的语句,可以进行选择使用。如果需要使用letter_box变换,后面在计算剪切后的图像时就要考虑进去。
int contrastive 表示是否使用对比,这个和序列抽取需要增强的数据图像时的起始索引有关,设置为1表示采用相邻索引,设置为0表示采用随机起始索引
int contrastive_jit_flip表示是否使用翻转对比
int show_imgs 表示是否需要显示组合的图像
处理过程
判断采用哪种数据增强模式
使用use_mixup参数配置数据循环及图像组合次数,当传入mosaic && cutmix ==1或者cutmix ==1,令use_mixup = 3,即统统转为使用mosaic数据增强。在YOLOv4默认的cfg文件中,令mosaic = 1。这里表示YOLOv4的模型主要支撑mosaic数据增强。需要注意的一点是cutmix的数据增强方法主要用于分类而非探测。
use_mixup = 3意味着后续的处理要循环四次,即把四张图片拼接在一起。
当use_mixup = 3时,设置(cut_x,cut_y)得位置,这个位置是随机的,示意图如下:
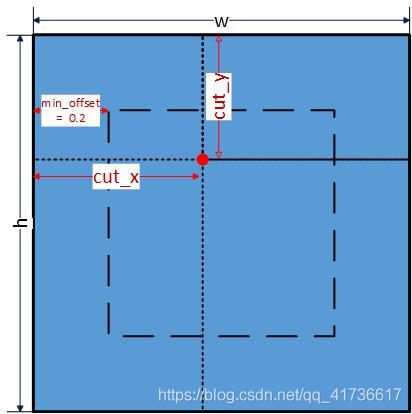
源码及注释如下:
//这里是针对所有含cutmix=1的情况
//cutmix=1只适用于分类,不支持Detector,所以在load_data_detection中如果有cutmix=1,将会提醒以下语句:
//"cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier)"
if (use_mixup == 2 || use_mixup == 4) {
printf("\n cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier) \n");
if (check_mistakes) getchar();
if(use_mixup == 2) use_mixup = 0;//循环次数use_mixup+1 = 1;
else use_mixup = 3;//同时使用mosaic和cutmix数据增强方法,循环次数use_mixup+1 = 4
}
//这里不支持letterbox变换和mosaic变换同时成立的情况。
if (use_mixup == 3 && letter_box) {
//printf("\n Combination: letter_box=1 & mosaic=1 - isn't supported, use only 1 of these parameters \n");
//if (check_mistakes) getchar();
//exit(0);
}
if (random_gen() % 2 == 0) use_mixup = 0;//当使用mosaicDA,平均有一半的use_mixup = 0,即不进行任何变换
int i;
//数据增强策略:mosaic条件平均有一半的use_mixup = 0,其他条件下所有use_mixup = 0
//use_mixup == 3的条件下,设置mosaic DA 初始cut值
int *cut_x = NULL, *cut_y = NULL;
if (use_mixup == 3) {
cut_x = (int*)calloc(n, sizeof(int));
cut_y = (int*)calloc(n, sizeof(int));
const float min_offset = 0.2; // 20%
//一个imgs中每个图片都设置一组cut_x,cut_y值,取值范围在举例边界20%距离的内圈
for (i = 0; i < n; ++i) {
cut_x[i] = rand_int(w*min_offset, w*(1 - min_offset));
cut_y[i] = rand_int(h*min_offset, h*(1 - min_offset));
}
}
设置数据增强相关初始参数:
data d = {
0};//设置data变量d,所有变换后的数据存储在这个变量中
d.shallow = 0;
d.X.rows = n;//d.X中存储一个batch的n个图片
d.X.vals = (float**)xcalloc(d.X.rows, sizeof(float*));
d.X.cols = h*w*c;//每个图片的尺寸,这里要考虑RGB通道
float r1 = 0, r2 = 0, r3 = 0, r4 = 0, r_scale = 0;//设置图像抖动最小随机平移量
float resize_r1 = 0, resize_r2 = 0;//用于当图像出现缩放的时候的最小随机平移量
float dhue = 0, dsat = 0, dexp = 0, flip = 0, blur = 0;//抖动、色调、曝光、翻转、糊化参数初始值
int augmentation_calculated = 0, gaussian_noise = 0;//增强计算标志位和是否使用高斯噪声
//d.y存储标签值,每一行为一幅图的标签,容量90*5个
d.y = make_matrix(n, truth_size*boxes);
利用循环进行数据增强图像拼接处理,mosaic数据增强循环分4次完成,每次获取一个batch的图像,获取完同时进行拼接,4次循环完毕,完成batch个拼接图像的处理。
数据增强拼接处理分几个步骤:
获取图像路径
分为两种方式:序列获取法和随机获取法,序列获取法适合图片集较少的情况,序列获取图片后,对图片进行糊化、高斯噪声、曝光、色调偏移、抖动位置重新设置等等操作;随机获取法适合图片集较多的情况,直接组合拼接图片也不担心出现组合图像重复的情况。如此设置可以保证满足数据增强需求的情况下不至于过度增加运算量。
每次获取一个batch的图片,使用函数的源码如下:
//抽取序列图像路径
char **get_sequential_paths(char **paths, int n, int m, int mini_batch, int augment_speed, int contrastive)
{
int speed = rand_int(1, augment_speed);//speed在(1, augment_speed)或(augment_speed,1)中间取值,程序中默认augment_speed =2所以speed一般为1.x
if (speed < 1) speed = 1;//如果speed小于1,则取1
char** sequentia_paths = (char**)xcalloc(n, sizeof(char*));
int i;
pthread_mutex_lock(&mutex);
//printf("n = %d, mini_batch = %d \n", n, mini_batch);
//start_time_indexes中存了一个mini_batch的开始时间序列
unsigned int *start_time_indexes = (unsigned int *)xcalloc(mini_batch, sizeof(unsigned int));
for (i = 0; i < mini_batch; ++i) {
//如果使用contrastive模式且i为奇数,start_time_indexes和上一个start_time_indexes相同
if (contrastive && (i % 2) == 1) start_time_indexes[i] = start_time_indexes[i - 1];
else start_time_indexes[i] = random_gen() % m;//否则,start_time_indexes为一个0-m之间的随机数,即在所有图片集中随机抽取
//这里是说,如果非contrastive模式,图片起始位置为随机选取
//如果contrastive模式,图片两个相邻起始位置相同,但也都是随机选取
//printf(" start_time_indexes[i] = %u, ", start_time_indexes[i]);
}
//按一个完整批次的图片进行循环
//这里是针对一个mimi_batch的图像循环取完,然后一起进行增强
for (i = 0; i < n; ++i) {
do {
int time_line_index = i % mini_batch;//循环设置time_line_index索引
//实际图片的索引为从start_time_indexes[0]开始的mimi_batch个顺序图像索引,对m取模是为了防止取到所有图片末尾后从头循环
unsigned int index = start_time_indexes[time_line_index] % m;
//start_time_indexes序列中的值在start_time_indexes[0]基础上按照speed顺序增加,如果mimi_batch为4,speed为1,mimi_batch为8,一般speed在1-2之间
start_time_indexes[time_line_index] += speed;
//int index = random_gen() % m;
sequentia_paths[i] = paths[index];//获取一个batch的图片序列
//printf(" index = %d, ", index);
//if(i == 0) printf("%s\n", paths[index]);
//printf(" index = %u - grp: %s \n", index, paths[index]);
//图片路径应大于4个字符
if (strlen(sequentia_paths[i]) <= 4) printf(" Very small path to the image: %s \n", sequentia_paths[i]);
} while (strlen(sequentia_paths[i]) == 0);
}
free(start_time_indexes);
pthread_mutex_unlock(&mutex);
return sequentia_paths;
}
//随机抽取序列比较简单,就是直接在所有的m个图像中随机选取
char **get_random_paths_custom(char **paths, int n, int m, int contrastive)
{
char** random_paths = (char**)xcalloc(n, sizeof(char*));
int i;
pthread_mutex_lock(&mutex);
int old_index = 0;
//printf("n = %d \n", n);
for(i = 0; i < n; ++i){
do {
int index = random_gen() % m;
if (contrastive && (i % 2 == 1)) index = old_index;
else old_index = index;
random_paths[i] = paths[index];
//if(i == 0) printf("%s\n", paths[index]);
//printf("grp: %s\n", paths[index]);
if (strlen(random_paths[i]) <= 4) printf(" Very small path to the image: %s \n", random_paths[i]);
} while (strlen(random_paths[i]) == 0);
}
pthread_mutex_unlock(&mutex);
return random_paths;
}
设置初始平移量
抖动一般是针对于序列获取路径的情况下设置的,第一个batch的图像不需要抖动,后面的三个batch的图像需要抖动。
抖动通过int pleft = rand_precalc_random(-dw, dw, r1);等函数完成,如果抖动r1使用r1 = random_float();等函数设置随机数,如果不抖动pleft = -dw,即-0.2*原始图像的宽度。
rand_precalc_random函数定义如下:
//如果random_part为0,则返回min
float rand_precalc_random(float min, float max, float random_part)
{
if (max < min) {
float swap = min;
min = max;
max = swap;
}
return (random_part * (max - min)) + min;
}
如果还存在缩放,则进一步进行修正:
以图像收缩为例,resize<1,则
pleft += rand_precalc_random(min_rdw, 0, resize_r1);
在非抖动的情况下,pleft = pleft + min_rdw
如果还存在letter_box变换,则pleft或者ptop的位置要切掉五十度灰的区域
图像偏移与truth值更新
对图像进行偏移处理后,将需要处理的图像在w×h的特征框中拉伸,并计算新的truth值。如果无抖动,裁剪图像裁剪位置就是图像的(0,0)坐标,如果有抖动,且抖动为正方向,就裁减掉pleft左边、ptop上边的部分图像,最后取得w和h尺寸的部分,如果尺寸不够,再使用resize_image函数进行拉伸处理,拉伸到w×h的尺寸。
然后,在使用fill_truth_detection函数修正图像中目标的位置标签等。
其中pleft和dx关系如下所示,计算新的truth值是一个线性变换,核心函数为中的correct_boxes函数,dx、dy为偏移量,sx、sy为拉伸比例
图像上下左右四个点坐标更新计算方法为:
l e f t n e w = l e f t _ o r i g i n ∗ s x – d x left_new = left\_origin * sx – dx leftnew=left_origin∗sx–dx
r i g h t n e w = r i g h t _ o r i g i n ∗ s x – d x right_new = right\_origin * sx – dx rightnew=right_origin∗sx–dx
t o p n e w = t o p _ o r i g i n ∗ s y – d y top_new = top\_origin * sy – dy topnew=top_origin∗sy–dy
b o t t o m n e w = b o t t o m _ o r i g i n ∗ s y – d y bottom_new = bottom\_origin * sy – dy bottomnew=bottom_origin∗sy–dy
具体目标的坐标及宽高参数为:
x = ( l e f t _ n e w + r i g h t _ n e w ) / 2 x = (left\_new + right\_new)/2 x=(left_new+right_new)/2
y = ( t o p _ n e w + b o t t o m _ n e w ) / 2 y = (top\_new + bottom\_new)/2 y=(top_new+bottom_new)/2
w = ( r i g h t _ n e w − l e f t _ n e w ) w = (right\_new - left\_new) w=(right_new−left_new)
h = ( b o t t o m _ n e w − t o p _ n e w ) h = (bottom\_new - top\_new) h=(bottom_new−top_new)
图像偏移拉伸示意图如下:

图像位置标签truth值修正函数代码如下:
//图像位置标签truth值修正函数
int fill_truth_detection(const char *path, int num_boxes, int truth_size, float *truth, int classes, int flip, float dx, float dy, float sx, float sy,
int net_w, int net_h)
{
char labelpath[4096];//初始化标签文件的路径
replace_image_to_label(path, labelpath);//使用一定的规则根据图像的路径算出label文件的路径
int count = 0;
int i;
box_label *boxes = read_boxes(labelpath, &count);
int min_w_h = 0;
float lowest_w = 1.F / net_w;//计算宽度的下限,1.F位浮点数1
float lowest_h = 1.F / net_h;
randomize_boxes(boxes, count);
correct_boxes(boxes, count, dx, dy, sx, sy, flip);//修正目标尺寸,平移加尺度伸缩,即线性变换
if (count > num_boxes) count = num_boxes;
float x, y, w, h;
int id;
int sub = 0;
//给坐标、尺寸和id赋值
for (i = 0; i < count; ++i) {
x = boxes[i].x;
y = boxes[i].y;
w = boxes[i].w;
h = boxes[i].h;
id = boxes[i].id;
int track_id = boxes[i].track_id;
// not detect small objects
//if ((w < 0.001F || h < 0.001F)) continue;
// if truth (box for object) is smaller than 1x1 pix
char buff[256];
if (id >= classes) {
printf("\n Wrong annotation: class_id = %d. But class_id should be [from 0 to %d], file: %s \n", id, (classes-1), labelpath);
sprintf(buff, "echo %s \"Wrong annotation: class_id = %d. But class_id should be [from 0 to %d]\" >> bad_label.list", labelpath, id, (classes-1));
system(buff);
if (check_mistakes) getchar();
++sub;
continue;
}
if ((w < lowest_w || h < lowest_h)) {
//sprintf(buff, "echo %s \"Very small object: w < lowest_w OR h < lowest_h\" >> bad_label.list", labelpath);
//system(buff);
++sub;
continue;
}
if (x == 999999 || y == 999999) {
printf("\n Wrong annotation: x = 0, y = 0, < 0 or > 1, file: %s \n", labelpath);
sprintf(buff, "echo %s \"Wrong annotation: x = 0 or y = 0\" >> bad_label.list", labelpath);
system(buff);
++sub;
if (check_mistakes) getchar();
continue;
}
if (x <= 0 || x > 1 || y <= 0 || y > 1) {
printf("\n Wrong annotation: x = %f, y = %f, file: %s \n", x, y, labelpath);
sprintf(buff, "echo %s \"Wrong annotation: x = %f, y = %f\" >> bad_label.list", labelpath, x, y);
system(buff);
++sub;
if (check_mistakes) getchar();
continue;
}
if (w > 1) {
printf("\n Wrong annotation: w = %f, file: %s \n", w, labelpath);
sprintf(buff, "echo %s \"Wrong annotation: w = %f\" >> bad_label.list", labelpath, w);
system(buff);
w = 1;
if (check_mistakes) getchar();
}
if (h > 1) {
printf("\n Wrong annotation: h = %f, file: %s \n", h, labelpath);
sprintf(buff, "echo %s \"Wrong annotation: h = %f\" >> bad_label.list", labelpath, h);
system(buff);
h = 1;
if (check_mistakes) getchar();
}
if (x == 0) x += lowest_w;
if (y == 0) y += lowest_h;
truth[(i-sub)*truth_size +0] = x;
truth[(i-sub)*truth_size +1] = y;
truth[(i-sub)*truth_size +2] = w;
truth[(i-sub)*truth_size +3] = h;
truth[(i-sub)*truth_size +4] = id;
truth[(i-sub)*truth_size +5] = track_id;
//float val = track_id;
//printf(" i = %d, sub = %d, truth_size = %d, track_id = %d, %f, %f\n", i, sub, truth_size, track_id, truth[(i - sub)*truth_size + 5], val);
if (min_w_h == 0) min_w_h = w*net_w;
if (min_w_h > w*net_w) min_w_h = w*net_w;
if (min_w_h > h*net_h) min_w_h = h*net_h;
}
free(boxes);
return min_w_h;
}
correct_boxes函数代码如下:
//偏移修正函数
void correct_boxes(box_label *boxes, int n, float dx, float dy, float sx, float sy, int flip)
{
int i;
//设置初始值
for(i = 0; i < n; ++i){
if(boxes[i].x == 0 && boxes[i].y == 0) {
boxes[i].x = 999999;
boxes[i].y = 999999;
boxes[i].w = 999999;
boxes[i].h = 999999;
continue;
}
if ((boxes[i].x + boxes[i].w / 2) < 0 || (boxes[i].y + boxes[i].h / 2) < 0 ||
(boxes[i].x - boxes[i].w / 2) > 1 || (boxes[i].y - boxes[i].h / 2) > 1)
{
boxes[i].x = 999999;
boxes[i].y = 999999;
boxes[i].w = 999999;
boxes[i].h = 999999;
continue;
}
boxes[i].left = boxes[i].left * sx - dx;//dx为偏移量,sx为拉伸比例
boxes[i].right = boxes[i].right * sx - dx;
boxes[i].top = boxes[i].top * sy - dy;//dy为偏移量,sy为拉伸比例
boxes[i].bottom = boxes[i].bottom* sy - dy;
//翻转修正
if(flip){
float swap = boxes[i].left;
boxes[i].left = 1. - boxes[i].right;
boxes[i].right = 1. - swap;
}
//若图像边界坐标在[0,1]之间,取区间值,否者取上下限
//这里的修正主要是针对当抖动中出现坐标超出图像边界的情况
boxes[i].left = constrain(0, 1, boxes[i].left);
boxes[i].right = constrain(0, 1, boxes[i].right);
boxes[i].top = constrain(0, 1, boxes[i].top);
boxes[i].bottom = constrain(0, 1, boxes[i].bottom);
boxes[i].x = (boxes[i].left+boxes[i].right)/2;//重新计算坐标位置
boxes[i].y = (boxes[i].top+boxes[i].bottom)/2;
boxes[i].w = (boxes[i].right - boxes[i].left);
boxes[i].h = (boxes[i].bottom - boxes[i].top);
boxes[i].w = constrain(0, 1, boxes[i].w);
boxes[i].h = constrain(0, 1, boxes[i].h);
}
}
常规数据增强
直接引用image_opencv.cpp中的数据增强函数image_data_augmentation,调整颜色、亮度、饱和度,还有翻转、拉伸、平移、噪声、模糊化等处理
具体处理方法这里不细讨论,详见image_opencv.cpp文档。
图像填充
利用如下代码计算平移量,注意,计算基本上是建立在默认翻转的基础之上的。这里代码的作用是保证平移之后,待切割的图像中有充足的像素点对平移量进一步进行修正。
const int left_shift = min_val_cmp(cut_x[i], max_val_cmp(0, (-pleft*w / ow)));
const int top_shift = min_val_cmp(cut_y[i], max_val_cmp(0, (-ptop*h / oh)));
const int right_shift = min_val_cmp((w - cut_x[i]), max_val_cmp(0, (-pright*w / ow)));
const int bot_shift = min_val_cmp(h - cut_y[i], max_val_cmp(0, (-pbot*h / oh)));
填充原理如下:

绑定目标参数
利用blend_truth_mosaic函数绑定目标参数,主要是针对前一步计算的目标参数进行平移,源代码如下:
//绑定目标参数x,y,w,h
void blend_truth_mosaic(float *new_truth, int boxes, int truth_size, float *old_truth, int w, int h, float cut_x, float cut_y, int i_mixup,
int left_shift, int right_shift, int top_shift, int bot_shift,
int net_w, int net_h, int mosaic_bound)
{
const float lowest_w = 1.F / net_w;
const float lowest_h = 1.F / net_h;
int count_new_truth = 0;
int t;
for (t = 0; t < boxes; ++t) {
float x = new_truth[t*truth_size];
if (!x) break;
count_new_truth++;
}
int new_t = count_new_truth;
for (t = count_new_truth; t < boxes; ++t) {
float *new_truth_ptr = new_truth + new_t*truth_size;
new_truth_ptr[0] = 0;
float *old_truth_ptr = old_truth + (t - count_new_truth)*truth_size;
float x = old_truth_ptr[0];
if (!x) break;
float xb = old_truth_ptr[0];
float yb = old_truth_ptr[1];
float wb = old_truth_ptr[2];
float hb = old_truth_ptr[3];
// shift 4 images
//主要是针对前一步计算的目标参数进行平移
if (i_mixup == 0) {
xb = xb - (float)(w - cut_x - right_shift) / w;
yb = yb - (float)(h - cut_y - bot_shift) / h;
}
if (i_mixup == 1) {
xb = xb + (float)(cut_x - left_shift) / w;
yb = yb - (float)(h - cut_y - bot_shift) / h;
}
if (i_mixup == 2) {
xb = xb - (float)(w - cut_x - right_shift) / w;
yb = yb + (float)(cut_y - top_shift) / h;
}
if (i_mixup == 3) {
xb = xb + (float)(cut_x - left_shift) / w;
yb = yb + (float)(cut_y - top_shift) / h;
}
int left = (xb - wb / 2)*w;
int right = (xb + wb / 2)*w;
int top = (yb - hb / 2)*h;
int bot = (yb + hb / 2)*h;
if(mosaic_bound)
{
// fix out of Mosaic-bound
float left_bound = 0, right_bound = 0, top_bound = 0, bot_bound = 0;
if (i_mixup == 0) {
left_bound = 0;
right_bound = cut_x;
top_bound = 0;
bot_bound = cut_y;
}
if (i_mixup == 1) {
left_bound = cut_x;
right_bound = w;
top_bound = 0;
bot_bound = cut_y;
}
if (i_mixup == 2) {
left_bound = 0;
right_bound = cut_x;
top_bound = cut_y;
bot_bound = h;
}
if (i_mixup == 3) {
left_bound = cut_x;
right_bound = w;
top_bound = cut_y;
bot_bound = h;
}
if (left < left_bound) {
//printf(" i_mixup = %d, left = %d, left_bound = %f \n", i_mixup, left, left_bound);
left = left_bound;
}
if (right > right_bound) {
//printf(" i_mixup = %d, right = %d, right_bound = %f \n", i_mixup, right, right_bound);
right = right_bound;
}
if (top < top_bound) top = top_bound;
if (bot > bot_bound) bot = bot_bound;
xb = ((float)(right + left) / 2) / w;
wb = ((float)(right - left)) / w;
yb = ((float)(bot + top) / 2) / h;
hb = ((float)(bot - top)) / h;
}
else
{
// fix out of bound
if (left < 0) {
float diff = (float)left / w;
xb = xb - diff / 2;
wb = wb + diff;
}
if (right > w) {
float diff = (float)(right - w) / w;
xb = xb - diff / 2;
wb = wb - diff;
}
if (top < 0) {
float diff = (float)top / h;
yb = yb - diff / 2;
hb = hb + diff;
}
if (bot > h) {
float diff = (float)(bot - h) / h;
yb = yb - diff / 2;
hb = hb - diff;
}
left = (xb - wb / 2)*w;
right = (xb + wb / 2)*w;
top = (yb - hb / 2)*h;
bot = (yb + hb / 2)*h;
}
// leave only within the image
if(left >= 0 && right <= w && top >= 0 && bot <= h &&
wb > 0 && wb < 1 && hb > 0 && hb < 1 &&
xb > 0 && xb < 1 && yb > 0 && yb < 1 &&
wb > lowest_w && hb > lowest_h)
{
new_truth_ptr[0] = xb;
new_truth_ptr[1] = yb;
new_truth_ptr[2] = wb;
new_truth_ptr[3] = hb;
new_truth_ptr[4] = old_truth_ptr[4];
new_t++;
}
}
//printf("\n was %d bboxes, now %d bboxes \n", count_new_truth, t);
}
步骤综合
对以上几个步骤进行综合,部分使用OpenCV代码模块的的load_data_detection函数源代码如下,不使用OpenCV代码模块的源代码大体思路一样,这里不再详解了。
//int n = imgs
//按照parser中的解释,同时使用mosaic和cutmix数据增强方法,use_mixup = 4;只使用cutmix,use_mixup = 2;只使用mosaic,use_mixup = 3;都不使用,use_mixup = 0
//但是在实际函数中,darknet依然保持他喜欢在代码中迷惑人的风范,use_mixup = 0是使用OpenCV中的调节亮度色彩饱和度、噪点等,use_mixup = 1为mixup
//use_mixup = 2的cutmix被mosaic DA所取代
//use_mixup 用于表征采用哪种增强方法,use_mixup == 4时,拼接4张图片,循环4次,采用mosaic,赋值use_mixup = 3
//use_mixup == 2,赋值use_mixup = 0,则图像拼接的循环执行1次,处理一张图片
//采用use_mixup = 0还是use_mixup = 3按50%的概率发生
data load_data_detection(int n, char **paths, int m, int w, int h, int c, int boxes, int truth_size, int classes, int use_flip, int use_gaussian_noise, int use_blur, int use_mixup,
float jitter, float resize, float hue, float saturation, float exposure, int mini_batch, int track, int augment_speed, int letter_box, int mosaic_bound, int contrastive, int contrastive_jit_flip, int show_imgs)
{
//!!!!!!!!!!!!!!!用于给混合的后的图像命名,这个要回头再确认
const int random_index = random_gen();
c = c ? c : 3;//保证图像为RGB三通道
//这里是针对所有含cutmix=1的情况
//cutmix=1只适用于分类,不支持Detector,所以在load_data_detection中如果有cutmix=1,将会提醒以下语句:
//"cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier)"
if (use_mixup == 2 || use_mixup == 4) {
printf("\n cutmix=1 - isn't supported for Detector (use cutmix=1 only for Classifier) \n");
if (check_mistakes) getchar();
if(use_mixup == 2) use_mixup = 0;//循环次数use_mixup+1 = 1;
else use_mixup = 3;//同时使用mosaic和cutmix数据增强方法,循环次数use_mixup+1 = 4
}
//这里不支持letterbox变换和mosaic变换同时成立的情况。
if (use_mixup == 3 && letter_box) {
//printf("\n Combination: letter_box=1 & mosaic=1 - isn't supported, use only 1 of these parameters \n");
//if (check_mistakes) getchar();
//exit(0);
}
if (random_gen() % 2 == 0) use_mixup = 0;//当使用mosaicDA,平均有一半的use_mixup = 0,即不进行任何变换
int i;
//数据增强策略:mosaic条件平均有一半的use_mixup = 0,其他条件下所有use_mixup = 0
//use_mixup == 3的条件下,设置mosaic DA 初始cut值
int *cut_x = NULL, *cut_y = NULL;
if (use_mixup == 3) {
cut_x = (int*)calloc(n, sizeof(int));
cut_y = (int*)calloc(n, sizeof(int));
const float min_offset = 0.2; // 20%
//一个imgs中每个图片都设置一组cut_x,cut_y值,取值范围在举例边界20%距离的内圈
for (i = 0; i < n; ++i) {
cut_x[i] = rand_int(w*min_offset, w*(1 - min_offset));
cut_y[i] = rand_int(h*min_offset, h*(1 - min_offset));
}
}
data d = {
0};//设置data变量d,所有变换后的数据存储在这个变量中
d.shallow = 0;
d.X.rows = n;//d.X中存储一个batch的n个图片
d.X.vals = (float**)xcalloc(d.X.rows, sizeof(float*));
d.X.cols = h*w*c;//每个图片的尺寸,这里要考虑RGB通道
float r1 = 0, r2 = 0, r3 = 0, r4 = 0, r_scale = 0;//设置图像抖动最小随机平移量
float resize_r1 = 0, resize_r2 = 0;//用于当图像出现缩放的时候的最小随机平移量
float dhue = 0, dsat = 0, dexp = 0, flip = 0, blur = 0;//抖动、色调、曝光、翻转、糊化参数初始值
int augmentation_calculated = 0, gaussian_noise = 0;//增强计算标志位和是否使用高斯噪声
//d.y存储标签值,每一行为一幅图的标签,容量90*5个
d.y = make_matrix(n, truth_size*boxes);
int i_mixup = 0;
//mosaic DA条件下一半情况下use_mixup = 3,要执行4次循环,处理4张图片,其他情况use_mixup = 0,循环只执行1次
for (i_mixup = 0; i_mixup <= use_mixup; i_mixup++) {
//如果是非首次循环,augmentation_calculated = 0
if (i_mixup) augmentation_calculated = 0; // recalculate augmentation for the 2nd sequence if(track==1)
//获取用于拼接的文件路径集合
//如果track == 1则执行get_sequential_paths,从所有m个训练图片集中获n个取序列路径,否则获取n个随机路径
//track实际上默认为0,表示纯随机选取图片进行数据增强
char **random_paths;
if (track) random_paths = get_sequential_paths(paths, n, m, mini_batch, augment_speed, contrastive);
else random_paths = get_random_paths_custom(paths, n, m, contrastive);
//这个循环是为了再随机图片序列中挨个取一个图,在图上进行截取(cut)
for (i = 0; i < n; ++i) {
float *truth = (float*)xcalloc(truth_size * boxes, sizeof(float));//真值初始化
const char *filename = random_paths[i];//获取文件名
int flag = (c >= 3);//通道数大于等于3,则flag=1
mat_cv *src;
src = load_image_mat_cv(filename, flag);//使用OpenCV读取图像信息
if (src == NULL) {
//如果读取为空,清空缓存,继续读取
printf("\n Error in load_data_detection() - OpenCV \n");
fflush(stdout);
if (check_mistakes) {
getchar();
}
continue;
}
//获取图片的原始高oh(origin height)和宽ow(origin width)
int oh = get_height_mat(src);
int ow = get_width_mat(src);
//确定素材图像抖动的初始位置
int dw = (ow*jitter);//jitter=0.2
int dh = (oh*jitter);
//此处为图像缩放处理
//resize比例初始值为1,配置文件没有写就默认为1
//min_rdw,min_rdh 一定 < 0,max_rdw,max_rdh 一定 > 0,相当于计算ow和oh的“缓冲带”的上下沿
float resize_down = resize, resize_up = resize;
if (resize_down > 1.0) resize_down = 1 / resize_down;
int min_rdw = ow*(1 - (1 / resize_down)) / 2; // < 0
int min_rdh = oh*(1 - (1 / resize_down)) / 2; // < 0
if (resize_up < 1.0) resize_up = 1 / resize_up;//切边?
int max_rdw = ow*(1 - (1 / resize_up)) / 2; // > 0
int max_rdh = oh*(1 - (1 / resize_up)) / 2; // > 0
//printf(" down = %f, up = %f \n", (1 - (1 / resize_down)) / 2, (1 - (1 / resize_up)) / 2);
//首次循环,处理第一张图片,如果track=0,则此处不运行;二次循环一定运行
//augmentation_calculated:数据增强参数设置,选取一个batch的图片,都按照相同的参数
//如果采取序列获取图片路径的方式,则重新计算图像拼接平移的量,同时使用糊化、高斯噪声、曝光、色调偏移等等数据增强方式
//因为如果图片较少的情况下,很可能总是相同的几个图像进行组合,因此要对组合的几个图像进行处理
//这也告诉我们,大训练集使用随机获取路径的方式,小训练集使用序列获取路径并进行局部处理方式,从而保证数据增强可控、有效
if (!augmentation_calculated || !track)
{
augmentation_calculated = 1;//每4次图像抽取更新一次随机处理的参数
resize_r1 = random_float();//0-1之间的随机浮点数
resize_r2 = random_float();
//存在对比、翻转或者第二次
if (!contrastive || contrastive_jit_flip || i % 2 == 0)
{
r1 = random_float();
r2 = random_float();
r3 = random_float();
r4 = random_float();
flip = use_flip ? random_gen() % 2 : 0;//use_flip初始值为1,flip为随机0或1
}
r_scale = random_float();
//cfg中,saturation = 1.5,exposure = 1.5中
dhue = rand_uniform_strong(-hue, hue);
dsat = rand_scale(saturation);//随机为1-1.5之间或者0.66-1之间
dexp = rand_scale(exposure);
if (use_blur) {
int tmp_blur = rand_int(0, 2); // 0 - disable, 1 - blur background, 2 - blur the whole image
if (tmp_blur == 0) blur = 0;
else if (tmp_blur == 1) blur = 1;
else blur = use_blur;
}
if (use_gaussian_noise && rand_int(0, 1) == 1) gaussian_noise = use_gaussian_noise;
else gaussian_noise = 0;
}
//设置初始平移量
int pleft = rand_precalc_random(-dw, dw, r1);
int pright = rand_precalc_random(-dw, dw, r2);
int ptop = rand_precalc_random(-dh, dh, r3);
int pbot = rand_precalc_random(-dh, dh, r4);
//如果存在缩放,则对平移量进行微调,注意,此时的数据针对计算都还是对原始图片,没有按正方形的待卷积的形状进行处理
//由于cfg文件中没有resize参数,所以在parser.c中,是将resize赋值为1,置入参数设置
if (resize < 1) {
// downsize only
pleft += rand_precalc_random(min_rdw, 0, resize_r1);
pright += rand_precalc_random(min_rdw, 0, resize_r2);
ptop += rand_precalc_random(min_rdh, 0, resize_r1);
pbot += rand_precalc_random(min_rdh, 0, resize_r2);
}
else {
pleft += rand_precalc_random(min_rdw, max_rdw, resize_r1);
pright += rand_precalc_random(min_rdw, max_rdw, resize_r2);
ptop += rand_precalc_random(min_rdh, max_rdh, resize_r1);
pbot += rand_precalc_random(min_rdh, max_rdh, resize_r2);
}
//printf("\n pleft = %d, pright = %d, ptop = %d, pbot = %d, ow = %d, oh = %d \n", pleft, pright, ptop, pbot, ow, oh);
//float scale = rand_precalc_random(.25, 2, r_scale); // unused currently
//printf(" letter_box = %d \n", letter_box);
//如果使用letter_box变换,在计算ptop及pbot时需要将填充的五十度灰色去掉,YOLOv4中默认不使用
if (letter_box)
{
float img_ar = (float)ow / (float)oh;
float net_ar = (float)w / (float)h;
float result_ar = img_ar / net_ar;
//printf(" ow = %d, oh = %d, w = %d, h = %d, img_ar = %f, net_ar = %f, result_ar = %f \n", ow, oh, w, h, img_ar, net_ar, result_ar);
if (result_ar > 1) // sheight - should be increased
{
float oh_tmp = ow / net_ar;
float delta_h = (oh_tmp - oh)/2;
ptop = ptop - delta_h;
pbot = pbot - delta_h;
//printf(" result_ar = %f, oh_tmp = %f, delta_h = %d, ptop = %f, pbot = %f \n", result_ar, oh_tmp, delta_h, ptop, pbot);
}
else // swidth - should be increased
{
float ow_tmp = oh * net_ar;
float delta_w = (ow_tmp - ow)/2;
pleft = pleft - delta_w;
pright = pright - delta_w;
//printf(" result_ar = %f, ow_tmp = %f, delta_w = %d, pleft = %f, pright = %f \n", result_ar, ow_tmp, delta_w, pleft, pright);
}
//printf("\n pleft = %d, pright = %d, ptop = %d, pbot = %d, ow = %d, oh = %d \n", pleft, pright, ptop, pbot, ow, oh);
}
// move each 2nd image to the corner - so that most of it was visible
// 将第二张图片移到角上,这样图片的大部分像素都可以看见,也可能这是最初的设计
// 但是在实际图像处理中,因为要对图片进行平移,flip条件下还要进行数据对换,这个一会给left赋0.一会给right赋0的伎俩并没有什么实际意义
// pleft += pright可以看成增强数据的随机性的一种方式,可以保证平移量出现较大的数据范围
if (use_mixup == 3 && random_gen() % 2 == 0) {
if (flip) {
if (i_mixup == 0) pleft += pright, pright = 0, pbot += ptop, ptop = 0;
if (i_mixup == 1) pright += pleft, pleft = 0, pbot += ptop, ptop = 0;
if (i_mixup == 2) pleft += pright, pright = 0, ptop += pbot, pbot = 0;
if (i_mixup == 3) pright += pleft, pleft = 0, ptop += pbot, pbot = 0;
}
else {
if (i_mixup == 0) pright += pleft, pleft = 0, pbot += ptop, ptop = 0;
if (i_mixup == 1) pleft += pright, pright = 0, pbot += ptop, ptop = 0;
if (i_mixup == 2) pright += pleft, pleft = 0, ptop += pbot, pbot = 0;
if (i_mixup == 3) pleft += pright, pright = 0, ptop += pbot, pbot = 0;
}
}
//无抖动条件下swidth = ow,sheight = oh
//有抖动条件下swidth与ow,sheight与oh存在偏差
int swidth = ow - pleft - pright;
int sheight = oh - ptop - pbot;
//计算偏移后图像与原始图像比例
float sx = (float)swidth / ow;
float sy = (float)sheight / oh;
//图像在拉伸情况下的偏移量
float dx = ((float)pleft / ow) / sx;
float dy = ((float)ptop / oh) / sy;
int min_w_h = fill_truth_detection(filename, boxes, truth_size, truth, classes, flip, dx, dy, 1. / sx, 1. / sy, w, h);
//for (int z = 0; z < boxes; ++z) if(truth[z*truth_size] > 0) printf(" track_id = %f \n", truth[z*truth_size + 5]);
//printf(" truth_size = %d \n", truth_size);
//计算糊化的参数
if ((min_w_h / 8) < blur && blur > 1) blur = min_w_h / 8; // disable blur if one of the objects is too small
//数据增强普通函数,在image_opencv.cpp中,在进行mosaic DA之前,前进行一轮普通增强
//直接引用image_opencv.cpp中的数据增强函数,调整颜色、亮度、饱和度,还有翻转、拉伸、平移、噪声、模糊化等处理
//这里输出的图像ai就已经是正方形的了,宽为w,长为h
image ai = image_data_augmentation(src, w, h, pleft, ptop, swidth, sheight, flip, dhue, dsat, dexp,
gaussian_noise, blur, boxes, truth_size, truth);
if (use_mixup == 0) {
d.X.vals[i] = ai.data;
memcpy(d.y.vals[i], truth, truth_size * boxes * sizeof(float));
}//use_mixup == 0,表示只进行opencv中的数据增强
// use_mixup == 1,使用mixup
else if (use_mixup == 1) {
if (i_mixup == 0) {
d.X.vals[i] = ai.data;
memcpy(d.y.vals[i], truth, truth_size * boxes * sizeof(float));
}
else if (i_mixup == 1) {
image old_img = make_empty_image(w, h, c);
old_img.data = d.X.vals[i];
//show_image(ai, "new");
//show_image(old_img, "old");
//wait_until_press_key_cv();
blend_images_cv(ai, 0.5, old_img, 0.5);
blend_truth(d.y.vals[i], boxes, truth_size, truth);
free_image(old_img);
d.X.vals[i] = ai.data;
}
}
else if (use_mixup == 3) {
if (i_mixup == 0) {
image tmp_img = make_image(w, h, c);//生成临时切割好的图像块
d.X.vals[i] = tmp_img.data;
}
if (flip) {
int tmp = pleft;
pleft = pright;
pright = tmp;
}
// 平移之后,待切割的图像中有充足的像素点
const int left_shift = min_val_cmp(cut_x[i], max_val_cmp(0, (-pleft*w / ow)));
const int top_shift = min_val_cmp(cut_y[i], max_val_cmp(0, (-ptop*h / oh)));
const int right_shift = min_val_cmp((w - cut_x[i]), max_val_cmp(0, (-pright*w / ow)));
const int bot_shift = min_val_cmp(h - cut_y[i], max_val_cmp(0, (-pbot*h / oh)));
// 每个i_mixup循环切割一块像素点,放入d.X中,构成一个个用于卷积的正方形图像数据
// 排列顺序是左上,右上,左下,右下
int k, x, y;
for (k = 0; k < c; ++k) {
for (y = 0; y < h; ++y) {
int j = y*w + k*w*h;
if (i_mixup == 0 && y < cut_y[i]) {
int j_src = (w - cut_x[i] - right_shift) + (y + h - cut_y[i] - bot_shift)*w + k*w*h;
memcpy(&d.X.vals[i][j + 0], &ai.data[j_src], cut_x[i] * sizeof(float));
}
if (i_mixup == 1 && y < cut_y[i]) {
int j_src = left_shift + (y + h - cut_y[i] - bot_shift)*w + k*w*h;
memcpy(&d.X.vals[i][j + cut_x[i]], &ai.data[j_src], (w-cut_x[i]) * sizeof(float));
}
if (i_mixup == 2 && y >= cut_y[i]) {
int j_src = (w - cut_x[i] - right_shift) + (top_shift + y - cut_y[i])*w + k*w*h;
memcpy(&d.X.vals[i][j + 0], &ai.data[j_src], cut_x[i] * sizeof(float));
}
if (i_mixup == 3 && y >= cut_y[i]) {
int j_src = left_shift + (top_shift + y - cut_y[i])*w + k*w*h;
memcpy(&d.X.vals[i][j + cut_x[i]], &ai.data[j_src], (w - cut_x[i]) * sizeof(float));
}
}
}
//mosaic DA的核心函数,绑定数据信息d.y
blend_truth_mosaic(d.y.vals[i], boxes, truth_size, truth, w, h, cut_x[i], cut_y[i], i_mixup, left_shift, right_shift, top_shift, bot_shift, w, h, mosaic_bound);
free_image(ai);
ai.data = d.X.vals[i];
}
if (show_imgs && i_mixup == use_mixup) // delete i_mixup
{
image tmp_ai = copy_image(ai);
char buff[1000];
//sprintf(buff, "aug_%d_%d_%s_%d", random_index, i, basecfg((char*)filename), random_gen());
sprintf(buff, "aug_%d_%d_%d", random_index, i, random_gen());
int t;
for (t = 0; t < boxes; ++t) {
box b = float_to_box_stride(d.y.vals[i] + t*truth_size, 1);
if (!b.x) break;
int left = (b.x - b.w / 2.)*ai.w;
int right = (b.x + b.w / 2.)*ai.w;
int top = (b.y - b.h / 2.)*ai.h;
int bot = (b.y + b.h / 2.)*ai.h;
draw_box_width(tmp_ai, left, top, right, bot, 1, 150, 100, 50); // 3 channels RGB
}
save_image(tmp_ai, buff);
if (show_imgs == 1) {
//char buff_src[1000];
//sprintf(buff_src, "src_%d_%d_%s_%d", random_index, i, basecfg((char*)filename), random_gen());
//show_image_mat(src, buff_src);
show_image(tmp_ai, buff);
wait_until_press_key_cv();
}
printf("\nYou use flag -show_imgs, so will be saved aug_...jpg images. Click on window and press ESC button \n");
free_image(tmp_ai);
}
release_mat(&src);
free(truth);
}
if (random_paths) free(random_paths);
}
return d;
}
总结
在darknet中之所以感觉mosaic数据增强这么“难”,应该还是图像平移翻转、图像表示计算等等功力不够。记得本人在学习微波工程的时候,教授讲过,学习这门课需要你首先有空间想象能力,要多琢磨。琢磨什么呢?琢磨电磁场在空间传播的形态,不同空间位置功率密度的状态(也就是方向图),琢磨各种极化方式、相位变化、电磁波干涉的结果、电磁波在介质中传播中损耗情况、电磁波碰到反射面后的反射情况等等。其实看起来比图像处理还要复杂是不是?
Mosaic数据增强的代码大体原理已经解释完毕,细节部分有需要进一步研究的同学可以花费更多时间进行研读,马上要过年了,就赶紧脱手了。
完结,撒花!