Kali Linux 安装 jdk 和搭建 hadoop 平台 (干货,超详细!!适合纯小白)
Kali Linux 如何搭建 Hadoop平台,Hadoop 伪分布安装与使用
大三的第一学期,用1~6周时间简单的学习了解组成原理和计网,虽然结课的很匆忙,但是却在第7周正式迎来了期待已久的 大数据专业课程,跟随企业老师学习hadoop和spark,非常的有趣。
课本是用Ubuntu讲解的,但我个人并不喜欢Ubuntu,因为Ubuntu缺少不少东西,得重新安装或者配置,可能是更适合初学者学习和使用吧。而我选择的是 Kali Linux,一方面是因为这是我使用次数最多和最熟练的一款Linux了,另一方面是因为信仰,一种对信息安全的信仰,也算最开始最纯粹的初心吧(笑哭)。
好了,废话不多说了,我们直奔主题!
如下为我的搭建环境:kali的VMware虚拟机,版本:2020.3。
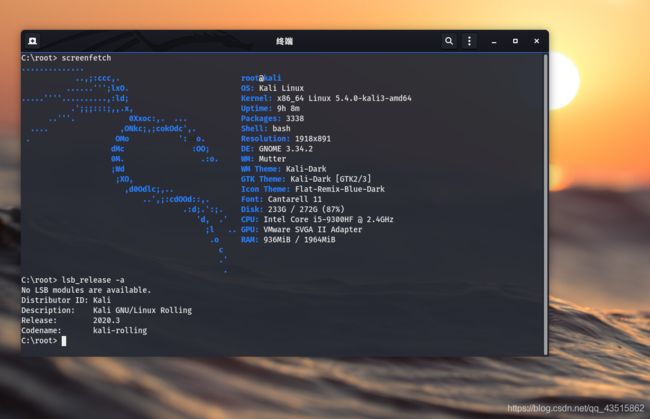
首先,我们必须明确任务点:
●拥有完善的java环境
●ssh服务能够正常运行
●正式搭建Hadoop平台
一、Kali Linux安装Java JDK :
● 判断是否安装JDK:
kali默认是自带了java的,如果不确定是否安装了jdk,可以采用如下任意一条命令来检测是否安装java:
1.java -verson
2.whereis java(比which搜索范围大一些,因为除查看PATH下可执行文件外,还会查找源文件和man文件。适用于查找安装好的命令。)
推荐前两条命令,如何这两条没有出现java的结果,就已经说名没有安装jdk了。
3.$echo java (等同于which java命令,因为which也只是查找可直接执行的命令,可以查找别名,查找的就编写在系统PATH下的可执行文件,which命令适用于查找安装好的命令。)
当然也可以使用find和locate命令来查询,不过这些都不是本文的重点,仅作简单介绍。
如果你的kali已经安装了java,并且添加到了环境变量中,那么可以直接跳转到第二大步骤了。
● Kali 安装Java JDK:
kali 安装java的方法是和Ubuntu一样的,有三种安装方式,如果不懂朋友可以移步博主另一篇文章,有详细的教程:Ubuntu Linux 安装 java 的方法
此处只为没安装的朋友提供解压安装的简单教程:jdk-8u91-linux-x64百度网盘(提取码:nqtg )
(如果纯小白不晓得如何把下载好的文件移动到你的kali虚拟机内,我推荐三种方法:)
1.可以用kali自带的火狐浏览器下载到你的kali;
2.了解如何使用vmwaretools,通过共享文件夹来实现windows和Linux间的直接文件传输;
3.百度kali如何使用Xftp 传输文件。
点到为止,不做过多赘述。
xftp 6 百度网盘下载链接 提取码:7ig0
下载好jdk-8u91-linux-x64后,解压和配置环境变量:
① 解压:
tar zxvf jdk-8u91-linux-x64.tar.gz -C /opt
(opt是一个第三方软件习惯安装目录,你也可以换其他的路径解压安装,比如我习惯把第三方安装在/home下)
tar -zxvf zxvf jdk-8u91-linux-x64.tar.gz -C /usr/lib/jvm
建议解压在jvm目录下,一般kali默认自带的jdk也是在/usr/lib/jvm这个路径的下。
② 配置环境变量:
1)执行vim /root/.bashrc,并添加以下内容:
# install JAVA JDK
export JAVA_HOME=/被解压文件所在路径/jdk1.8.0_91
#例如,我的就是:
#export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_91
export CLASSPATH=.:${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
2)执行 source ~/.bashrc使环境变量生效。
③ 安装并注册:
update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_91
update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.8.0_91
update-alternatives --set java /usr/lib/jvm/jdk1.8.0_91
update-alternatives --set javac /usr/lib/jvm/jdk1.8.0_91
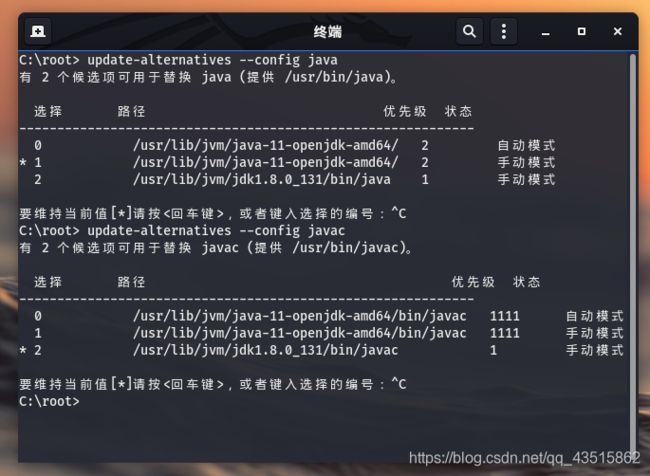
④ 检测:
update-alternatives --config java
update-alternatives --config javac
java -version
#output
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
JDK成功无误!
当然,也可用根据我们课本这样去安装,或者是博主的另一篇更详细的博文安装:Debian系列Linux安装JDK的三种方式。


二、开启SSH服务
ssh类似于远程登陆,可从一台Linux主机登陆到另一台Linux主机,并且运行命令,SSH的在hadoop中的具体应用,读者可以百度查阅集群免密登陆进一步学习了解,此处仅做简要提示。
在安装hadoop之前需要配置ssh,因为集群和单节点模式都需要用到SSH登录。Linux一般是默认自带ssh的客户端服务的,缺少的是服务端SSH server。如果不安装SSH Server,已经、配置好的单节点SSH服务器和客户端授权登录,则无法启动将要安装的伪分布hadoop。
sudo apt-get install -y openssh-server #网络在线安装
● 判断是否安装SSH服务:
执行如下命令启动ssh服务
sudo service ssh start
如果不能成功启动,则说明未安装ssh服务。
kali安装ssh服务
# apt-get install ssh -y
启用和开始使用 SSH
为了确保安全 shell 能够使用,在重启系统后使用systemctl命令来启用它:
# reboot
# systemctl enable ssh
在当前对话执行中使用 SSH:
# service ssh start
● 安装SSH Server服务器:
# apt-get install openssh-server
配置SSH服务开机启动
# update-rc.d -f ssh remove
# update-rc.d -f ssh defaults
# update-rc.d -f ssh enable 2 3 4 5
更改默认的SSH密钥
# cd /etc/ssh
# mkdir ssh_key_backup
# mv ssh_host_* ssh_key_backup
创建新密钥:
# dpkg-reconfigure openssh-server
允许 SSH Root 访问
默认情况下 SSH 不允许以 root 用户登录,因此将会出现下面的错误提示信息:
Permission denied, please try again.
为了通过 SSH 进入你的 Kali Linux 系统,你可以有两个不同的选择。第一个选择是创建一个新的非特权用户然后使用它的身份来登录。第二个选择,你可以以 root 用户访问 SSH 。为了实现这件事,需要在SSH 配置文件 /etc/ssh/sshd_config 中插入下面这些行内容或对其进行编辑:
将
#PermitRootLogin prohibit-password
改为:
PermitRootLogin yes
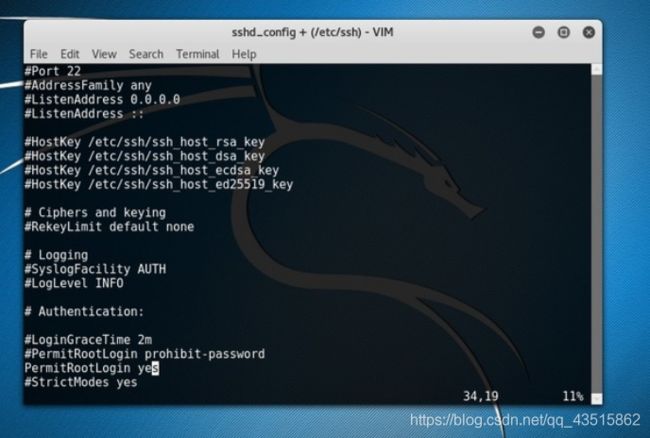
对 /etc/ssh/sshd_config 进行更改以后,需在以 root 用户登录 SSH 前重启 SSH 服务:
# service ssh restart
查看是否安装成功:
# ssh -V
出现如下类似信息,表示你很顺利的安装成功了!

SSH服务安装开启成功!
● ssh登陆本机:
ssh localhost
首次登陆SSH会提示,输入"yes",按提示输入密码就登陆本机了。
如果此时报这种错:
root@localhost's password:localhost:permission denied,please try again
就更改密码后再次登陆:
# sudo passwd root # 注意此处的root为当前登录本机所在的用户名,不一定是root
# 更改成功后重启服务:
# sudo service ssh restart
# ssh localhost
此时能够正常登陆了!
ssh安装无误后,有兴趣的朋友可以尝试一下登陆其他电脑玩玩,比如我用kali登陆另一台虚拟机或者是我的Win10尝试登陆kali虚拟机:
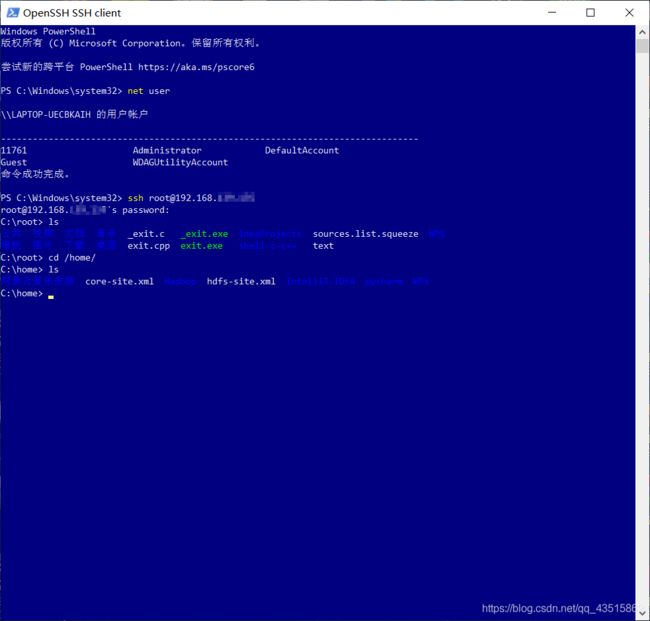
ssh远程登陆:
ssh 用户名@ip地址
从上图可以看到,Linux在登录成功之后,会有一些问候信息 balabala。这些文字信息是可以自定义的:
# vim /etc/motd
写入你想要的问候文字。
重启SSH:
# service ssh restart
● 无密登陆设置:
但是这样每次登入均要输入密码,设成无密登陆更方便。
具体操作如下:
# exit # 先退出刚才的ssh localhost
# cd ~/.ssh/ # 若无该目录,先执行一次ssh localhost创建
# ssh-keygen -t rsa # 全部回车即可
# cat ~/.ssh/id_rsa.pub >> ./authorized_keys # 加入授权
命令 “ssh-keygen -t rsa” 会生成 公钥和私钥,默认在该目录(~/.ssh/)生成id_rsa(私钥)和id_rsa.pub(公钥)俩文件。 而 "cat ~/.ssh/id_rsa.pub >> ./authorized_keys" 命令则是将公钥密码导入认证文件 authorized_keys 中。
最后,SSH授权完成,再次ssh localhost 则不再需要密码了,也不再影响伪分布hadoop启动。
三、正式搭建hadoop ,伪分布安装
① 安装Hadoop:
hadoop有着三种安装模式,分别是:
(1)单机模式;
(2)伪分布模式;
(3)分布模式。
由于,博主时间紧张,这里就只给读者介绍伪分布的安装,也是本文的全篇侧重点。
首先,下载Hadoop
(1)官网下载地址:Hadoop官方下载 可能下载速度会很慢
(2) 不过博主在这给读者提供了自己的网盘下载:hadoop2.7和hadoop3.3百度网盘
下载完成后便是安装和配置了。
● Hadoop安装文件并解压:
因为,我是实现在win10下载好后,移动到vmtools指定的共享文件夹开始操作的,所以,博主的初始化目录便是在/mnt/hgfs目录下,当然你也可以用前文中提到的xftp或kali自带火狐。
注意博主是在root账号下开始搭建的!
你可以创建一个新的用户,或者跟着博主在root下安装
先创建一个空的文件夹,用来解压hadoop,你可以创建在/opt路径下,或者像博主一样放在自己喜欢的路径下。
# mkdir /home/Hadoop
解压,-C 指定解压路径到创建的文件夹路径
# tar zxvf hadoop-3.3.0.tar.gz -C /home/Hadoop/
授权,具有读写文件的权利,否则直接影响其他相关操作,必须要执行!!
# chown -R root /home/Hadoop/hadoop-3.3.0/
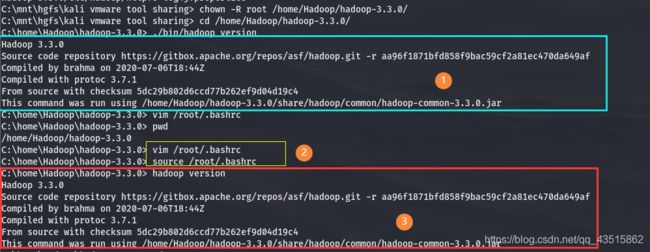
检测Hadoop是否解压安装正确:
# cd /home/Hadoop/hadoop-3.3.0/
# ./bin/hadoop version
如出现如下则 恭喜你安装无误!!
Hadoop 3.3.0
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af
Compiled by brahma on 2020-07-06T18:44Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
否则,采用 rm -rf /home/Hadoop 命令删除掉,回到上一步,耐心的重来。
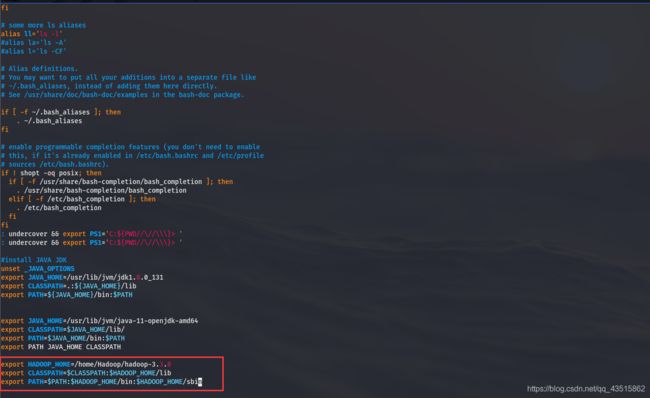
② 配置Hadoop环境变量:
与java环境变量的配置类似,用编辑器打开.bashrc文件保存修改后,执行source ~/.bashrc命令使其生效:
export HADOOP_HOME=/home/Hadoop/hadoop-3.3.0 # 注意,这里是你的hadoop解压安装路径
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并生效后,便可在任何路径下使用hadoop命令了
执行生效命令:
# source /root/.bashrc
出现此前执行./bin/hadoop version命令时所出现的信息,则证明环境变量修改无误
# hadoop version
一定要确定写对后再执行生效,避免不必要的麻烦,如果有朋友操作不当,导致命令几乎失效的话,请执行该命令恢复:
export PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
整个如上执行过程,请参考下图:
③ 伪分布模式配置:
首先,得清楚概念,什么是hadoop的伪分布运行?
Hadoop的伪分布运行是指,同一个节点既是名称节点(Name Node),也是数据节点(Data Node),读取分布式文件系统HDFS的文件。安装不同模式Hadoop,就是修改其配置文件符合模式要求。
Hadoop有俩配置文件,一个是core-site.xml文件,另一个是hdfs-site.xml,其相对路径是在 hadoop-3.3.0/etc/hadoop/ 下。
首先,修改core-site.xml配置文件
# vim /home/Hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml
修改添加的内容:
hadoop.tmp.dir
file:/home/Hadoop/hadoop-3.3.0/tmp
# 注意,这里的/home/Hadoop/hadoop-3.3.0是指你的hadoop安装路径
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
dfs.permissions
false
详解:
参数fs.defaultFS为默认文件系统名称,其值为Hadoop的Name Node地址和端口号,如hdfs://localhost:9000,即表示Name Node是本机,端口9000是HDFS的RPC端口,是HDFS的默认端口。
参数hadoop.tmp.dir用于确定Hadoop文件系统的原信息与数据保存在哪个目录下,是Hadoop文件系统依赖的基础配置,很多路径都依赖,如果hdfs-site.xml文件中不配置Name Node和Data Node的存放位置,默认放在此路径中。
参数dfs.permissions的值如果是true则检查权限,否则不检查权限(每个人都可以存取文件),该参数NameNode上设定。
如图: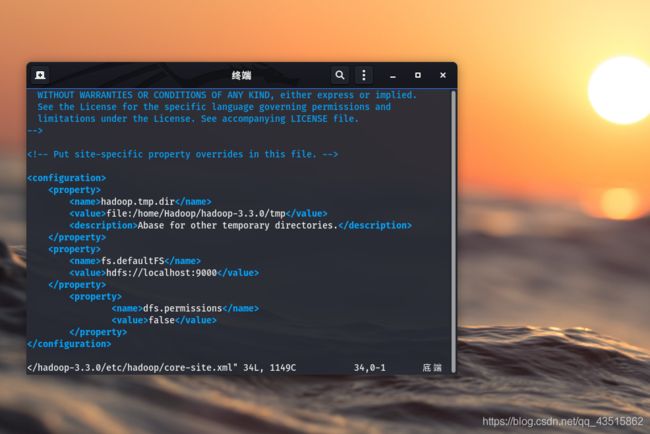
其次,修改hdfs-site.xml配置文件
# vim /home/Hadoop/hadoop-3.3.0/etc/hadoop/hdfs-site.xml
修改添加的内容:
dfs.replication
1
dfs.namenode.name.dir
file:/home/Hadoop/hadoop-3.3.0/tmp/dfs/name
# 注意,这里的/home/Hadoop/hadoop-3.3.0是指你的hadoop安装路径
dfs.datanode.data.dir
file:/home/Hadoop/hadoop-3.3.0/tmp/dfs/data
# 注意,这里的/home/Hadoop/hadoop-3.3.0仍然是指你的hadoop安装路径
详解:
参数dfs.replication指明设置hdfs副本数,因为是伪分布模式,所以设置为“1”,默认备份3个副本。
参数dfs.namenode.name.dir 对应的value是存放名称节点的路径,参数dfs.datanode.data.dir 对应的value是存放数据节点的路径。这俩路径也可自行设置,但最好与临时文件路径一致,在初期实验时,遇到问题可以一并处理。
Hadoop的运行方式是由配置文件决定的,因为运行Hadoop时会读取配置文件,如果需要切换模式,只需要重新增加,删除或者修改core-site.xml和hdfs-site.xml文件中的配置项。
④ Name Node的格式化:
配置完成,执行Name Node的格式化:
# hdfs namenode -format # 由于,hadoop生效了环境变量,所以在任何路径下均可执行。
一定要注意,在前面的工作完成无误之后再执行格式化,格式化只能一次,多次执行或许会出错。
出现"successfully formatted"和"Exiting with status 0"的字样,则证明格式化成功!!祝贺你!
否则,出现"Exiting with status 1"那么非常不幸!格式化出错了,建议执行"rm -rf /home/Hadoop/hadoop3.3"命令删掉hadoop,重新解压安装和配置吧!!
除此之外,需要特别强调的一点是首次格式化不必删除dfs及其子文件,此处引入我们课本:
以及Java没有配置正确后出现的报错,也在上述图中了。
⑤ 启动和关闭Hadoop
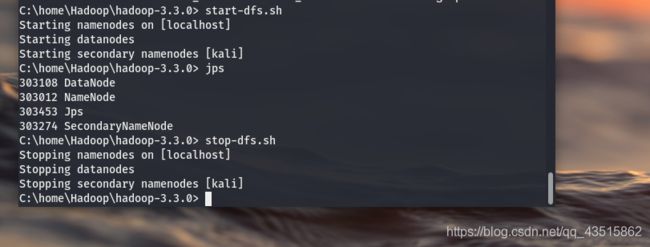
1)start-dfs.sh
start-dfs.sh只启动Name Node和Data Node,启动命令如下:
# start-dfs.sh
第一次启动Hadoop会出现SSH提示:“Are you sure you want to continue connecting(yes/no)?”,输入"yes"回车!
成功开启后会有如下信息:
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [kali]
启动Hadoop成功后,可以通过jps查看进程:
C:\home\Hadoop\hadoop-3.3.0> jps
303108 DataNode
303012 NameNode
303453 Jps
303274 SecondaryNameNode
关闭Hadoop的命令:
# stop-dfs.sh
成功开启后会有如下信息:
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [kali]
如上是正确的执行过程显示!如果 没有"SecondaryNameNode" ,需先运行stop-dfs.sh,再尝试启动。
如果没有Name Node或Data Node,就是配置不成功!
请仔细检查之前的操作,或者查看启动日志排除来原因,或者删掉hadoop重新解压安装和配置,的确是靠耐心,仔细认真的操作!
如果到这里你执行的相当顺利,那么博主对你表示祝贺 !!
从开启到关闭的执行过程图:
当然也有像博主一样,历经坎坷的朋友(笑哭),遇到问题就想办法解决吧,害,在瞎折腾中变秃也变强(手动滑稽 ing~,哈哈哈)
或许有朋友会在开启hadoop的时候就遇到如下报错:
C:\home\Hadoop\hadoop-3.3.0> start-dfs.sh
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [kali]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
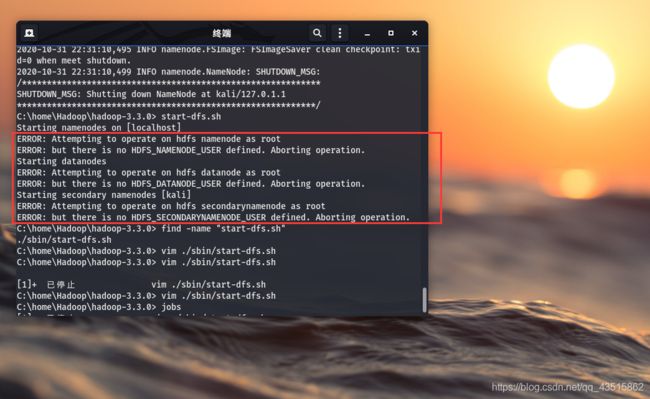
解决方法如下:
对hadoop的sbin下start-dfs.sh和stop-dfs.sh文件均进行修改:
# vim /home/Hadoop/hadoop-3.3.0/sbin/start-dfs.sh
# vim /home/Hadoop/hadoop-3.3.0/sbin/stop-dfs.sh
俩文件增添内容全部如下:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
注意添加位置是这两行之后:
# See the License for the specific language governing permissions and
# limitations under the License.
保存并退出vim,再次执行重启:
# start-dfs.sh
理论是不会有什么错了,如果修改这俩文件后,你又遇到和博主一样新的报错,博主也提供了新的解决方法:
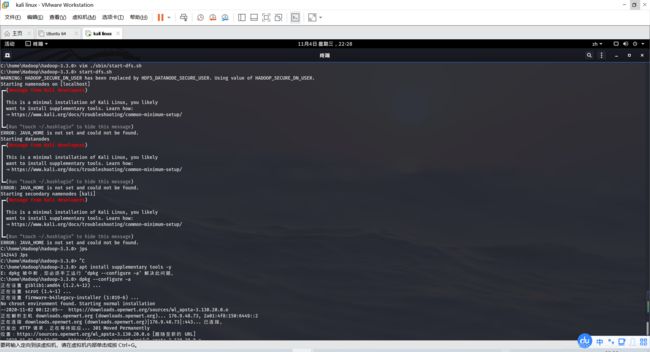
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [localhost]
ERROR: JAVA_HOME is not set and could not be found.
Starting datanodes
ERROR: JAVA_HOME is not set and could not be found.
Starting secondary namenodes [kali]
ERROR: JAVA_HOME is not set and could not be found.
仍然是修改start-dfs.sh和stop-dfs.sh文件这两文件,将之前的修改内容全部更改成:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
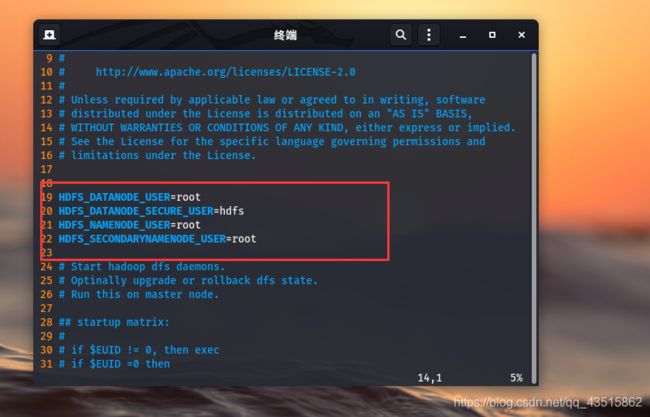
而面对另外一个报错,你可能会很懵逼,我明明是在之前添加了Java的环境变量啊,为什么还会报错说:“java没有设置并且也找不到”呢?
JAVA_HOME is not set and could not be found
起初,我郁闷了会,而且又回过去查看了环境变量配置,琢磨过来又细想过去,环境变量是没有问题的。后来晓得是得修改hadoop-env.sh来解决。
# vim /home/Hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
在这个文件中你会发现JAVA_HOME的确是没有被添加的!
解决方法:手动添加一个环境变量中的Java JDK 路径,保存并退出即可解决。
如图:
此处报错全图展览:
再次尝试启动和关闭Hadoop和jps进程查看,查看是否正常:
C:\home\Hadoop\hadoop-3.3.0> start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [kali]
C:\home\Hadoop\hadoop-3.3.0> jps
147891 NameNode
148192 SecondaryNameNode
147985 DataNode
148287 Jps
C:\home\Hadoop\hadoop-3.3.0> stop-dfs.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [kali]
恭喜你,基本完成了Hadoop的伪分布搭建 !
如果你还和博主一样悲催,仍然残留着小问题:
━(Message from Kali developers)
┃
┃ This is a minimal installation of Kali Linux, you likely
┃ want to install supplementary tools. Learn how:
┃ ⇒ https://www.kali.org/docs/troubleshooting/common-minimum-setup/
┃
┗━(Run “touch ~/.hushlogin” to hide this message)
别着急,博主也为你写了解决方案:
报错意思是说缺少了辅助工具,我们安装即可:
# apt install supplementary tools -y # 记得更换国内源和保证kali linux网络的正常运营
如果中途又报错提示:
E: dpkg 被中断,您必须手工运行 ‘dpkg --configure -a’ 解决此问题。
那么就根据报错的提示执行:
# dpkg --configure -a
等运行结束后,再执行该命令,隐藏提示即可:
# touch ~/.hushlogin
2)start-all.sh
start-all.sh不仅启动Name Node和Data Node,还启动YARN的ResourceManager和NodeManger。启动命令如下:
# start-all.sh
# jps # 查看全启动的Hadoop进程
关闭命令如下:
# stop-all.sh
注意,养成好习惯,开启不用时就关闭退出,避免其他错误的发生。
当然,在这里博主又遇到了报错,好悲催,不过热心的博主也为你解决了,哈哈(笑哭):
报错代码如下:
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
Stopping resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
我们只需要根据报错在start-yarn.sh和stop-yarn.sh文件的第二行中添加信息即可:
# vim /home/Hadoop/hadoop-3.3/sbin/start-yarn.sh
# vim /home/Hadoop/hadoop-3.3/sbin/stop-yarn.sh
添加内容如下:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
如下图:
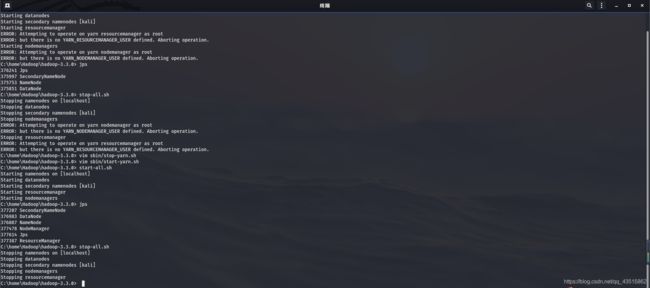
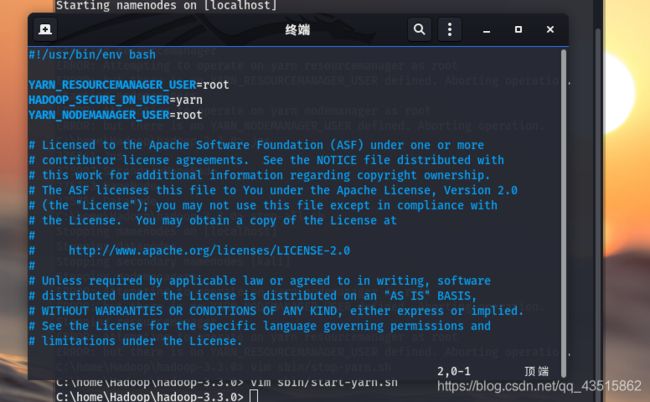
最后,重启关闭Hdoop和jps进程查看来检验:
C:\home\Hadoop\hadoop-3.3.0> start-all.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [kali]
Starting resourcemanager
Starting nodemanagers
C:\home\Hadoop\hadoop-3.3.0> jps
377207 SecondaryNameNode
376983 DataNode
376887 NameNode
377478 NodeManager
377614 Jps
377387 ResourceManager
C:\home\Hadoop\hadoop-3.3.0> stop-all.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [kali]
Stopping nodemanagers
Stopping resourcemanager
C:\home\Hadoop\hadoop-3.3.0>