命名实体识别(NER):BiLSTM-CRF原理介绍+Pytorch_Tutorial代码解析
本文较全面的介绍了命名实体识别(NER),包括NER定义、BiLSTM-CRF模型、Pytorch代码实现,未来将继续完善本文,以求涵盖NER众多方面。
文章目录
- 命名实体识别任务(NER)定义
- BiLSTM-CRF模型
-
- 模型输入
- LSTM
- CRF
-
- 真实路径得分
- 所有路径得分
- Pytorch Tutorial NER代码解析
- #TODO
- 参考
命名实体识别任务(NER)定义
命名实体识别属于自然语言处理中的序列标注任务,是指从文本中识别出特定命名指向的词,比如人名、地名和组织机构名等。具体而言,输入自然语言序列 ,给出对应标签序列 ,见下图。
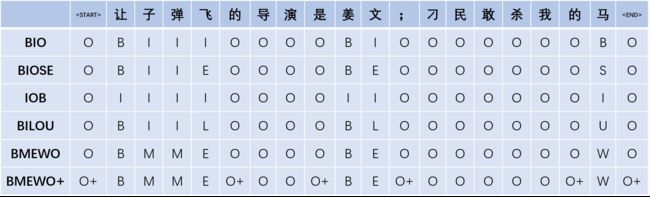
序列标注里标记法有很多,包括BIO、BIOSE、IOB、BILOU、BMEWO、BMEWO+等,最常见的是 BIO 与 BIOES 这两种。不同标注方法会对模型效果有些许影响,例如有些时候用BIOES会比BIO有些许优势。
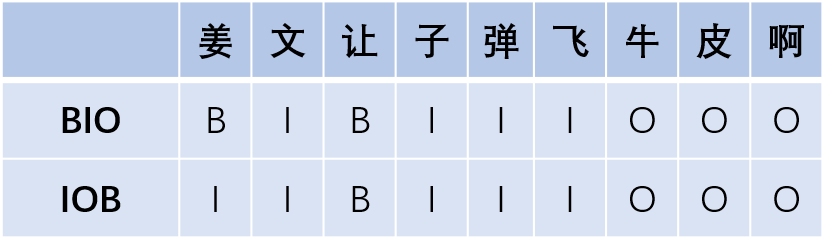
在BIO和BIOSE中,Beginning 表示某个实体词的开始,Inside表示某个实体词的中间,Outside表示非实体词,End表示某个实体词的结尾,Single表示这个实体词仅包含当前这一个字。IOB与BIO字母对应的含义相同,其不同点是IOB中,标签B仅用于两个连续的同类型命名实体的边界区分。BILOU 等价于 BIOES,Last等同于End,Unit等同于Single。BMEWO 等价于 BIOES,Middle等同于Inside,Whole等同于Single。BMEWO+是在命名实体边界外的标注,即‘O plus‘。
命名实体识别的常用方法是BiLSTM-CRF和BERT-CRF,可以完美的匹配该任务。
BiLSTM-CRF模型
下文,我们使用BIO标注进行解析,同时加入START和END来使转移矩阵更加健壮,其中,START表示句子的开始,END表示句子的结束。这样,标注标签共有5个:[B, I, O, START, END]。
BiLSTM-CRF模型主体由双向长短时记忆网络(Bi-LSTM)和条件随机场(CRF)组成,模型输入是字符特征,输出是每个字符对应的预测标签。

模型输入
对于输入的自然语言序列,可通过特征工程的方法定义序列字符特征,如词性特征、前后词等,将其输入模型。但现在多数情况下,可以直接选择句中每个字符的字嵌入或词嵌入向量,可以是事先训练好的或是随机初始化。对于中文,我个人倾向于将字符向量和其所属的词向量进行拼接,词嵌入使用预训练好的,字嵌入随机初始化。

LSTM
BiLSTM接收每个字符的embedding,并预测每个字符的对5个标注标签的概率。
LSTM是一种特殊的循环神经网络,可以解决RNN的长期依赖问题,其关键就是细胞状态,见下图中贯穿单元结构上方的水平线。细胞状态在整个链上运行,只有一些少量的线性交互,从而保存长距离的信息流。具体而言,LSTM一共有三个门来维持和调整细胞状态,包括遗忘门,输入门,输出门。
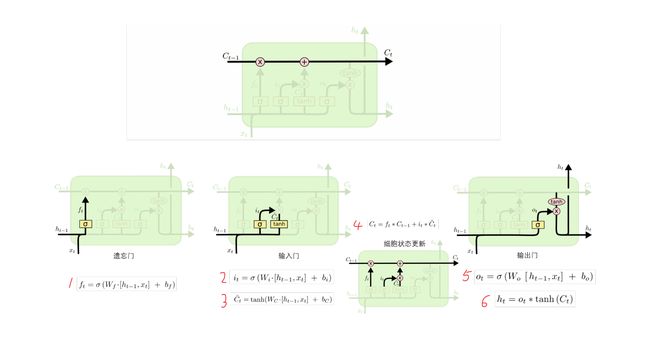
遗忘门接收 h t − 1 h_{t-1} ht−1和 x t x_t xt,通过公式1输出一个在 0 到 1 之间的数值 f t f_t ft,该数值会作用于上一个细胞状态 C t − 1 C_{t-1} Ct−1,1 表示“完全保留”,0 表示“完全忘记”;输入门接收 h t − 1 h_{t-1} ht−1和 x t x_t xt,通过公式2输出一个在 0 到 1 之间的数值,已控制当前候选状态 C t ^ \hat{C_t} Ct^有多少信息需要保留,至于候选状态 C t ^ \hat{C_t} Ct^,则通过公式3由tanh 层创建一个新的候选值向量,然后根据上一个细胞状态 C t − 1 C_{t-1} Ct−1和遗忘值 f t f_t ft、新的细胞状态 C t C_{t} Ct和输入值 i t i_t it,由公式4更新细胞状态;输出门接收 h t − 1 h_{t-1} ht−1和 x t x_t xt,通过公式5输出一个在 0 到 1 之间的数值 o t o_t ot,最后公式6决定了当前状态 C t C_t Ct有多少信息需要输出。
题外话:LSTM的理解
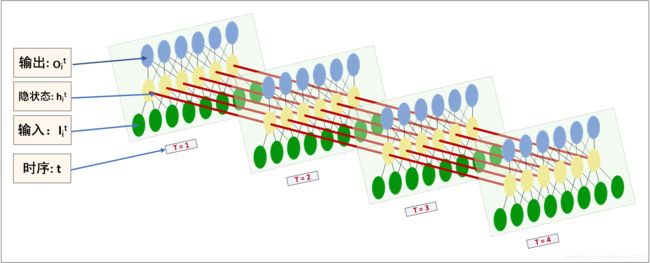
一般来说,循环神经网络是MLP增加了一个时间维度,那么该怎样理解这个时间维度呢?可以参考以下两张图可视化LSTM。
在
torch.nn.LSTM()中,有以下几个重要的参数:input_size,在这里就是每个字符嵌入的维度;hidden_size,经过一个LSTM单元后输入 h h h的维度;num_layers,即上图中depth的深度,若干个LSTMcell的堆叠;bidirectional,默认False,在实验中将其设为True。LSTM输入包括 i n p u t input input和 ( h 0 , c 0 ) (h_0, c_0) (h0,c0)两部分,其中 i n p u t input input大小为 (seq_len, batch, input_size), h 0 h_0 h0和 c 0 c_0 c0大小均为(num_layers * num_directions, batch, hidden_size)。输出包括 o u t p u t output output和 ( h n , c n ) (h_n, c_n) (hn,cn)两部分,其中 o u t p u t output output大小为(seq_len, batch, num_directions * hidden_size), h n h_n hn和 c n c_n cn大小均为(num_layers * num_directions, batch, hidden_size)。
我们知道,CNN在空间上共享参数,而RNN是在时间上共享参数。也就是在每一层depth中只有一个LSTMcell,即上面第二张图中每一层只有一个LSTM单元。
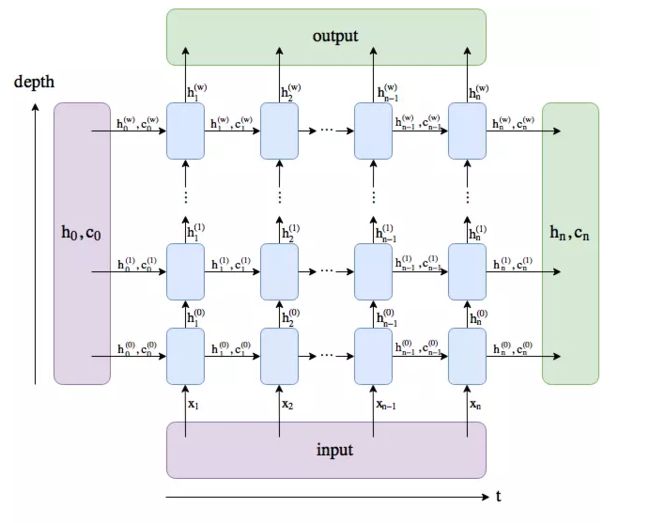
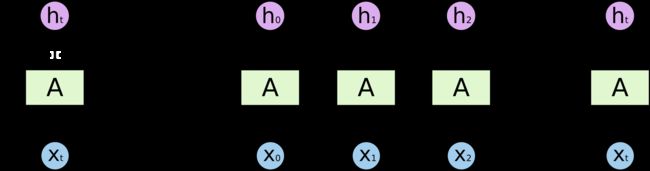
在BiLSTM-CRF中,一般使用一层的双向LSTM是足够的。因此,BiLSTM对输入embeddings的特征提取过程如下图。

本部分一开始就说过,BiLSTM接收每个字符的embedding,并预测每个字符的对5个标注标签的概率。但是,我们也知道上图得到的拼接向量维度大小为num_directions * hidden_size。为将输入表示为字符对应各个类别的分数,需要在BiLSTM层加入一个全连接层,通过softmax将向量映射为一个5维的分布概率。
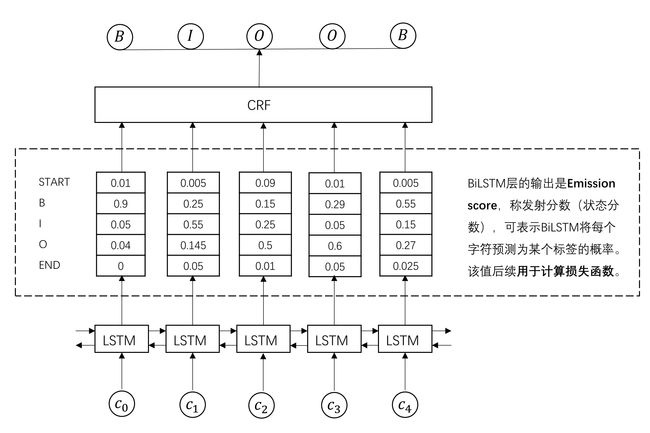
到了这一步,似乎我们通过BiLSTM已经找到每个单词对应的最大标签类别,但实际上,直接选择该步骤最大概率的标签类别得到的结果并不理想。原因在于,尽管LSTM能够通过双向的设置学习到观测序列之间的依赖,但softmax层的输出是相互独立的,输出相互之间并没有影响,只是在每一步挑选一个最大概率值的label输出,这样的模型无法学习到输出的标注之间的转移依赖关系(标签的概率转移矩阵)以及序列标注的约束条件,如句子的开头应该是“B”或“O”,而不是“I”等。为此,引入CRF层学习序列标注的约束条件,通过转移特征考虑输出label之间的顺序性,确保预测结果的有效性。
CRF
CRF层将BiLSTM的Emission_score作为输入,输出符合标注转移约束条件的、最大可能的预测标注序列。
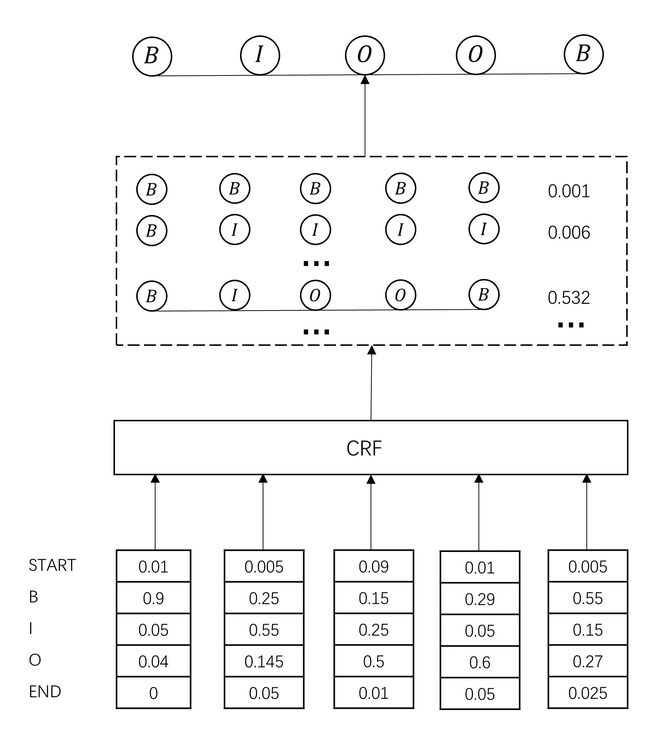
在开始之前,我们先了解一下线性链条件随机场。见李航老师的《统计学习方法》第11章。


赫然发现,NER问题就是条件随机场,即给定自然语言序列X,最大概率的标注序列Y用来表示NER标注结果。至于 P ( y ∣ x ) P(y|x) P(y∣x),由公式(11.10)和(11.11)求得。齐活!
上图中标出,公式(11.10)中有三个值得注意的部分: t k t_k tk, s l s_l sl和 Z ( x ) Z(x) Z(x),理解这三个部分是理解BiLSTM-CRF模型中CRF的关键,以下面这张图进行说明。
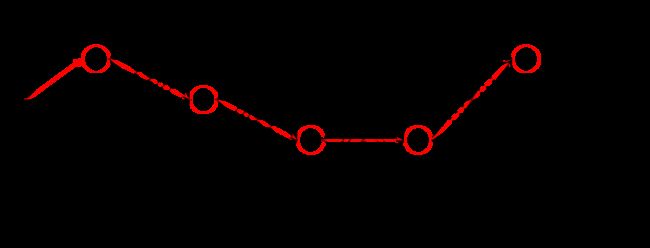
在我们的例子中,输入 x x x为 c 0 , c 1 , c 2 , c 3 , c 4 c_0,c_1,c_2,c_3,c_4 c0,c1,c2,c3,c4,理想输出 y y y 为 B , I , O , O , B B,I,O,O,B B,I,O,O,B,上图中红色线路。
- Z ( x ) Z(x) Z(x),称规范化因子或配分函数。在公式(11.10)中,“ Z ( x ) Z(x) Z(x)是规范化因子,求和是在所有可能的输出序列上进行的”。对应到我们的图中,其实就是图中所有可能的路径组合,由于输入序列长度为5,标注类型也为5,因此上图中共有 5 5 5^5 55条不同路径。每条路径根据 e x p ( ∗ ) exp(*) exp(∗)计算该路径的得分,加和得到 Z ( x ) Z(x) Z(x)。
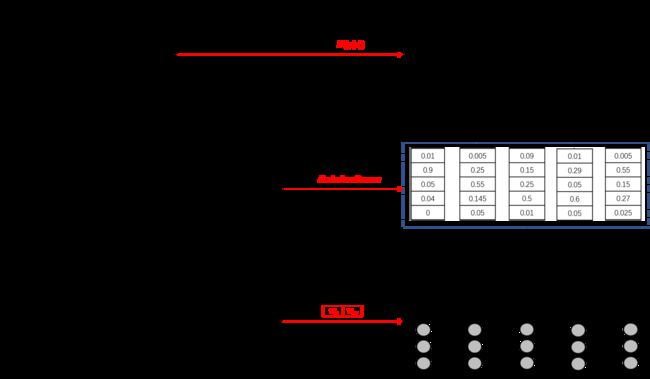
- s t s_t st是节点上的状态特征,取决于当前节点; t k t_k tk是边上的转移特征,取决于当前和前一个节点。根据它们的定义,可以很自然的将它们与BiLSTM-CRF中的Emission Score和Transition Score匹配:Emission Score是由BiLSTM生成的、对当前字符标注的概率分布;Transition Score是加入CRF约束条件的、字符标注之间的概率转移矩阵。从这个意义上讲,BiLSTM-CRF其实就是一个CRF模型,只不过用BiLSTM得到状态特征值 s t s_t st,用反向传播算法更新转移特征值 t k t_k tk。

在模型训练过程中,模型损失函数定义如下:
P ( y ˉ ∣ x ) = e x p ( score ( x , y ˉ ) ) ∑ y e x p ( score ( x , y ) ) P(\bar{y}|x)=\frac{exp(\operatorname{score}(x,\bar{y}))}{\sum_y{exp(\operatorname{score}(x,y))}} P(yˉ∣x)=∑yexp(score(x,y))exp(score(x,yˉ))
score ( x , y ) = ∑ i = 1 n P i , y i + ∑ i = 0 n A y i − 1 , y i \operatorname{score}(x,y)=\sum_{i=1}^{n} P_{i, y_{i}}+\sum_{i=0}^{n} A_{y_{i-1}, y_{i}} score(x,y)=i=1∑nPi,yi+i=0∑nAyi−1,yi
其中, P i , y i P_{i, y_{i}} Pi,yi和 A y i − 1 , y i A_{y_{i-1}, y_{i}} Ayi−1,yi分别表示标注序列 y y y中 y i y_i yi的Emission Score和Transition Score,通过查找上图中的”BiLSTM的Emission Score“和”序列标注转移矩阵“可以得到每个字符位置的得分,整个序列相加得到 score ( x , y ) \operatorname{score}(x,y) score(x,y)。
模型训练过程中最大化对数似然函数:
log P ( y ˉ ∣ x ) = score ( x , y ˉ ) − log ( ∑ y exp ( score ( x , y ) ) ) \log P\left(\bar{y}\mid x\right)=\operatorname{score}\left(x, \bar{y}\right)-\log \left(\sum_{y} \exp \left(\operatorname{score}\left(x, y\right)\right)\right) logP(yˉ∣x)=score(x,yˉ)−log(y∑exp(score(x,y)))
真实路径得分
在我们的例子中,真实路径 y ˉ = ( B , I , O , O , B ) \bar{y}=(B,I,O,O,B) yˉ=(B,I,O,O,B), score ( x , y ˉ ) = ∑ EmissionScores + ∑ TransitionScores \operatorname{score}(x,\bar{y})=\sum\operatorname{EmissionScores}+\sum\operatorname{TransitionScores} score(x,yˉ)=∑EmissionScores+∑TransitionScores,其中:
∑ EmissionScores = P 0 , S T A R T + P 1 , B + P 2 , I + P 3 , O + P 4 , O + P 5 , B + P 6 , E N D \sum\operatorname{EmissionScores}=P_{0,START}+P_{1, B}+P_{2, I}+P_{3,O}+P_{4, O}+P_{5,B}+P_{6,END} ∑EmissionScores=P0,START+P1,B+P2,I+P3,O+P4,O+P5,B+P6,END
∑ TransitionScores = A S T A R T , B + A B , I + A I , O + A O , O + A O , B + A B , E N D \sum\operatorname{TransitionScores}=A_{START,B}+A_{B,I}+A_{I,O}+A_{O,O}+A_{O,B}+A_{B,END} ∑TransitionScores=ASTART,B+AB,I+AI,O+AO,O+AO,B+AB,END
EmissionScores来自BiLSTM层的输出,至于 P 0 , S T A R T P_{0,START} P0,START和 P 6 , E N D P_{6,END} P6,END,则设为0;TransitionScores来自于CRF层;将真实路径中这两类分数加和,即可得到真实路径得分,上图中红色路线。
所有路径得分
对于所有路径的总分 ∑ y exp ( score ( x , y ) ) \sum_{y} \exp \left(\operatorname{score}\left(x, y\right)\right) ∑yexp(score(x,y)),一种直接的想法是列举出所有可能的路径,然后查找每条路径的Emission Score和Transition Score,计算出每条路径的得分,之后加和。
这种方法显然效率低下,在我们的例子中,仅有5个字符和5个标注序列,就已经有了约 5 5 5^5 55种路径组合,在实际工作中,我们显然会有更长的序列和更多的标注标签,提高计算效率是必要的。于是,我们以分数累积的方法计算所有路径得分,即先计算出到达 c 0 c_0 c0的所有路径的总得分,然后,计算 c 0 − > c 1 c_0{->}c_1 c0−>c1的所有路径的得分,依次类推,直到计算出 c 0 − > c 1 ⋯ − > c n c_0->c_1\dots->c_n c0−>c1⋯−>cn的所有路径的得分,这就是我们需要的结果。通过下图可以看出这两种计算方式的不同。
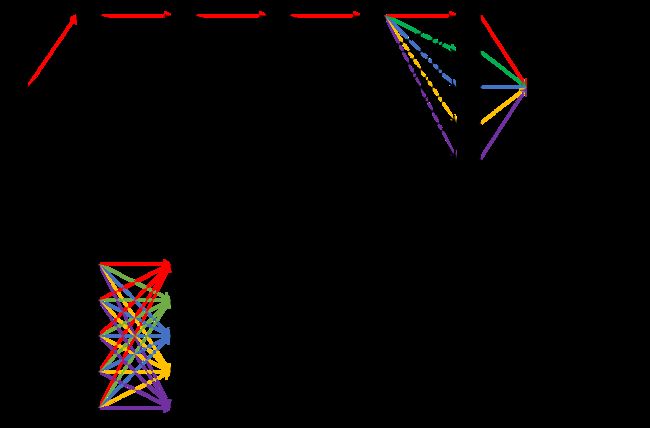
上面的图是直观的、计算所有路径得分加和的示意图,这种方法思想上是深度优先的;下面的图是改进的、分数累计求和的示意图,这种方法思想上是广度优先的。
在第一种方法中,图示以 [ ( S , S , S , S , S ) , ( S , S , S , S , B ) , ( S , S , S , S , I ) , ( S , S , S , S , O ) , ( S , S , S , S , E ) ] [(S,S,S,S,S),(S,S,S,S,B),(S,S,S,S,I),(S,S,S,S,O),(S,S,S,S,E)] [(S,S,S,S,S),(S,S,S,S,B),(S,S,S,S,I),(S,S,S,S,O),(S,S,S,S,E)]五条可能的标注路径为例,每一条路径得分由该路径上节点得分(EmissionScore)和边得分(TransitionScore)相加得到,可以发现,如果计算分别计算每一条路径的话,存在大量的冗余,如对于上述五条路径,前四个标注是相同的,理论上只需分别计算最后一项不同标注即可。
分数累积的方法更为激进。要知道,在计算 Z ( x ) Z(x) Z(x)时我们并不是要排列组合出所有可能路径,只是要一个All值,即图中所有边和节点的总值。因此,我们可以先计算出到达某一字符的路径得分之和 ( s S i , s B i , s I i , s O i , s E i ) (s_S^i,s_B^i,s_I^i,s_O^i,s_E^i) (sSi,sBi,sIi,sOi,sEi),然后依次计算下一字符的路径得分之和 ( s S i + 1 , s B i + 1 , s I i + 1 , s O i + 1 , s E i + 1 ) (s_S^{i+1},s_B^{i+1},s_I^{i+1},s_O^{i+1},s_E^{i+1}) (sSi+1,sBi+1,sIi+1,sOi+1,sEi+1),这类似于动态规划的思想。如在上图示例中,我们在得知到达 y 1 y_1 y1的路径得分之和 ( s S 1 , s B 1 , s I 1 , s O 1 , s E 1 ) (s_S^1,s_B^1,s_I^1,s_O^1,s_E^1) (sS1,sB1,sI1,sO1,sE1)后,根据 s t a g ′ 2 = ∑ t a g s s t a g 1 + t ( t a g , t a g ′ ) s_{tag'}^2=\sum_{tags}{s_{tag}^1+t_{(tag,tag')}} stag′2=∑tagsstag1+t(tag,tag′)可分别计算出 y 2 y_2 y2的路径得分之和 ( s S 2 , s B 2 , s I 2 , s O 2 , s E 2 ) (s_S^2,s_B^2,s_I^2,s_O^2,s_E^2) (sS2,sB2,sI2,sO2,sE2),图中红/绿/蓝/黄/紫分别根据 y 1 y_1 y1各标注的得分计算到达 y 2 y_2 y2的 ( S , B , I , O , E ) (S,B,I,O,E) (S,B,I,O,E)各标注的得分之和。依次类推,计算出整个图中所有路径得分之和。
在图中可以直观看到上述两种方法是等价的,其数学上的等价性见下:
log ( ∑ e log ( Σ e x ) + y ) = log ( ∑ ∑ e x + y ) \log \left(\sum e^{\log \left(\Sigma e^{x}\right)+y}\right)=\log \left(\sum \sum e^{x+y}\right) log(∑elog(Σex)+y)=log(∑∑ex+y)
证明过程:
log ( ∑ e log ( Σ e x ) + y ) = log ( ∑ e log ( Σ e x ) + log e y ) = log ( ∑ e log ( Σ e x ) ∗ e y ) = log ( ∑ e log ( Σ e x + y ) ) = log ( ∑ ∑ e x + y ) \begin{aligned} \log \left(\sum e^{\log \left(\Sigma e^{x}\right)+y}\right) &=\log (\sum e^{\log (\Sigma e^{x})+\log e^y}) \\ &=\log (\sum e^{\log (\Sigma e^{x})*e^y})\\ &=\log (\sum e^{\log (\Sigma e^{x+y})})\\ &=\log \left(\sum \sum e^{x+y}\right) \end{aligned} log(∑elog(Σex)+y)=log(∑elog(Σex)+logey)=log(∑elog(Σex)∗ey)=log(∑elog(Σex+y))=log(∑∑ex+y)
第二种方法有效减少了计算冗余。第一种方法的计算复杂度为 O ( n m n ) O(nm^n) O(nmn),其中, m m m为标注标签类别数,第二种方法的计算复杂度为 O ( n m 2 ) O(nm^2) O(nm2)。当然,第二种方法还可以以下图这种方式计算,下文Pytorch Tutorial中的实现_forward_alg()就是如此,但本质上就是一回事。

建议推荐参照Bi-LSTM-CRF算法详解-1中的推导过程进行理解或自行推导。
最终BiLSTM-CRF模型如下:
Pytorch Tutorial NER代码解析
网上多数Pytorch NER解析来自官方示例,见ADVANCED: MAKING DYNAMIC DECISIONS AND THE BI-LSTM CRF,以下代码添加有个人备注解析。以下几点需要注意:
- 前文提到,模型目标是最大化对数似然函数 log P ( y ˉ ∣ x ) = score ( x , y ˉ ) − log ( ∑ y exp ( score ( x , y ) ) ) \log P\left(\bar{y}\mid x\right)=\operatorname{score}\left(x, \bar{y}\right)-\log \left(\sum_{y} \exp \left(\operatorname{score}\left(x, y\right)\right)\right) logP(yˉ∣x)=score(x,yˉ)−log(∑yexp(score(x,y))),但在深度学习中,我们一般通过最小化损失函数优化模型参数。因此,取负得到损失函数 L o s s = log ( ∑ y exp ( score ( x , y ) ) ) − score ( x , y ˉ ) Loss=\log (\sum_{y} \exp (\operatorname{score}(x, y)))-\operatorname{score}(x, \bar{y}) Loss=log(∑yexp(score(x,y)))−score(x,yˉ)。
- 在NER问题中,训练过程与测试过程是不同的。在训练中,我们需要计算所有路径的得分以正确更新转移矩阵,但在测试过程中,我们以然得到合理的标签概率转移矩阵,因此只需要结合Emission Score选择一条概率最大的路径。该过程为解码过程,采用Vertibe算法,参见如何通俗地讲解 viterbi 算法?。
- Pytorch Tutorial仅提供最基本的代码帮助理解BiLSTM-CRF,具体的到实践,该代码还有很大的优化空间。如批次训练、GPU训练、维特比解码和配分函数计算优化等。
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(1)
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
def argmax(vec):
# 得到最大的值的索引
_, idx = torch.max(vec, 1)
return idx.item()
def log_sum_exp(vec):
max_score = vec[0, argmax(vec)] # max_score的维度为1
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1]) # 维度为1*5
return max_score + torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
#等同于torch.log(torch.sum(torch.exp(vec))),防止e的指数导致计算机上溢
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 转移矩阵,transitions[i][j]表示从label_j转移到label_i的概率,虽然是随机生成的但是后面会迭代更新
self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size))
self.transitions.data[tag_to_ix[START_TAG], :] = -10000 # 从任何标签转移到START_TAG不可能
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000 # 从STOP_TAG转移到任何标签不可能
self.hidden = self.init_hidden() # 随机初始化LSTM的输入(h_0, c_0)
def init_hidden(self):
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
def _forward_alg(self, feats):
'''
输入:发射矩阵(emission score),实际上就是LSTM的输出——sentence的每个word经BiLSTM后,对应于每个label的得分
输出:所有可能路径得分之和/归一化因子/配分函数/Z(x)
'''
init_alphas = torch.full((1, self.tagset_size), -10000.)
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# 包装到一个变量里面以便自动反向传播
forward_var = init_alphas
for feat in feats: # w_i
alphas_t = []
for next_tag in range(self.tagset_size): # tag_j
# t时刻tag_i emission score(1个)的广播。需要将其与t-1时刻的5个previous_tags转移到该tag_i的transition scors相加
emit_score = feat[next_tag].view(1, -1).expand(1, self.tagset_size) # 1*5
# t-1时刻的5个previous_tags到该tag_i的transition scors
trans_score = self.transitions[next_tag].view(1, -1) # 维度是1*5
next_tag_var = forward_var + trans_score + emit_score
# 求和,实现w_(t-1)到w_t的推进
alphas_t.append(log_sum_exp(next_tag_var).view(1))
forward_var = torch.cat(alphas_t).view(1, -1) # 1*5
# 最后将最后一个单词的forward var与转移 stop tag的概率相加
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
def _get_lstm_features(self, sentence):
'''
输入:id化的自然语言序列
输出:序列中每个字符的Emission Score
'''
self.hidden = self.init_hidden() # (h_0, c_0)
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out) # len(s)*5
return lstm_feats
def _score_sentence(self, feats, tags):
'''
输入:feats——emission scores;tags——真实序列标注,以此确定转移矩阵中选择哪条路径
输出:真实路径得分
'''
score = torch.zeros(1)
# 将START_TAG的标签3拼接到tag序列最前面
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags])
for i, feat in enumerate(feats):
score = score + \
self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
def _viterbi_decode(self, feats):
# 预测序列的得分,维特比解码,输出得分与路径值
backpointers = []
init_vvars = torch.full((1, self.tagset_size), -10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
forward_var = init_vvars
for feat in feats:
bptrs_t = []
viterbivars_t = []
for next_tag in range(self.tagset_size):
next_tag_var = forward_var + self.transitions[next_tag] # forward_var保存的是之前的最优路径的值
best_tag_id = argmax(next_tag_var) # 返回最大值对应的那个tag
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t) # bptrs_t有5个元素
# 其他标签到STOP_TAG的转移概率
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# 无需返回最开始的START位
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG]
best_path.reverse() # 把从后向前的路径正过来
return path_score, best_path
def neg_log_likelihood(self, sentence, tags): # 损失函数
feats = self._get_lstm_features(sentence) # len(s)*5
forward_score = self._forward_alg(feats) # 规范化因子/配分函数
gold_score = self._score_sentence(feats, tags) # 正确路径得分
return forward_score - gold_score # Loss(已取反)
def forward(self, sentence):
'''
解码过程,维特比解码选择最大概率的标注路径
'''
lstm_feats = self._get_lstm_features(sentence)
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
START_TAG = ""
STOP_TAG = ""
EMBEDDING_DIM = 5 # 由于标签一共有B\I\O\START\STOP 5个,所以embedding_dim为5
HIDDEN_DIM = 4 # 这其实是BiLSTM的隐藏层的特征数量,因为是双向所以是2倍,单向为2
training_data = [(
"the wall street journal reported today that apple corporation made money".split(),
"B I I I O O O B I O O".split()
), (
"georgia tech is a university in georgia".split(),
"B I O O O O B".split()
)]
word_to_ix = {
}
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
tag_to_ix = {
"B": 0, "I": 1, "O": 2, START_TAG: 3, STOP_TAG: 4}
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
for epoch in range(300):
for sentence, tags in training_data:
model.zero_grad()
# 输入
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# 获取loss
loss = model.neg_log_likelihood(sentence_in, targets)
# 反向传播
loss.backward()
optimizer.step()
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print(model(precheck_sent))
#TODO
- NER实战
- BERT-CRF
- …
参考
流水的NLP铁打的NER:命名实体识别实践与探索
序列标注方法BIO、BIOSE、IOB、BILOU、BMEWO、BMEWO+的异同
BiLSTM-CRF模型理解
Understanding LSTM Networks
pytorch中LSTM的细节分析理解
Bi-LSTM-CRF算法详解-1
ADVANCED: MAKING DYNAMIC DECISIONS AND THE BI-LSTM CRF
如何通俗地讲解 viterbi 算法?
《统计学习方法(第二版)》
转载请注明出处