redis缓存过期淘汰策略
1.如何查看redis的最大占用内存?

打开redis配置文件,设置maxmemory参数,maxmemory单位是bytes字节类型,注意单位转换
如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3G内存
2.生产上配置多少?
一般推荐redis设置内存为最大物理内存的3/4
3.怎么配置redis的最大内存?
- 通过修改redis.conf
 示例配置最大内存100MB
示例配置最大内存100MB
- 通过命令修改

4.怎么查看redis内存使用情况?
![]()
5.如果redis内存使用超出了设置的最大值会怎样?
会报OOM异常
6.redis三种不同的删除策略
⑴定时删除: redis遍历所有设置了过期时间的key,来检测数据是否已经达到过期时间,然后对它进行删除.这种方式会对CPU产生额外压力,造成大量性能消耗,还会影响数据的读取操作. 对CPU不友好,用处理器性能换取存储空间(拿时间换空间)
⑵惰性删除: 数据到达过期时间,不作处理,等下次访问改数据时,如果数据未过期,返回数据;如果过期,删除,返回不存在.这种方式会导致大量无用数据占用内存,造成内存浪费. 对内存不友好,用存储空间换取处理器性能(拿空间换时间)
⑶定期删除: 定期删除是定时删除和惰性删除的折中.定期删除策略每隔一段时间执行一次删除过期键的操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU的影响. 周期性轮询redis中的数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度.定期删除策略的难点是确定删除操作执行的时长和频率.这种方式也会过期的key堆积在内存中,造成内存资源浪费.
7.redis内存淘汰策略
①noeviction:不会驱逐任何key(默认)
②allkeys-lru:对所有key使用lru算法进行删除
③volatile-lru:对所有设置了过期时间的key使用lru算法进行删除
④allkeys-random:对所有key随机删除
⑤volatile-random:对所有设置了过期时间的key随机删除
⑥volatile-ttl:删除马上要过期的key
⑦allkeys-lfu:对所有key使用lfu算法进行删除
⑧volatile-lfu:对所有设置了过期时间的key使用lfu算法进行删除
一般使用的是allkeys-lru:对所有key使用lru算法进行删除
8.如何配置redis内存淘汰策略?
 或者使用命令配置
或者使用命令配置
9.LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的数据进行淘汰
LRU算法核心是哈希链表,即HashMap+DoubleLinkedList,时间复杂度是O(1),哈希表+双向链表的结合体. 查询用哈希, 增删用链表
10.手写LRU算法
- LinkedHashMap 利用现成的数据结构来实现
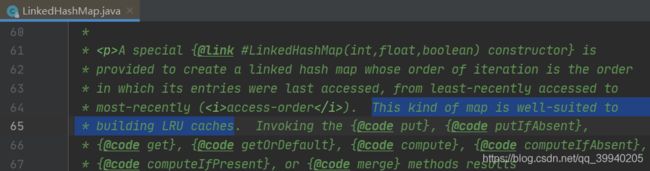
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCacheDemo extends LinkedHashMap {
private int capacity; // 容量
public LRUCacheDemo(int capacity) {
// 初始容量、加载因子、排序模式(true:access-order访问顺序 false:insertion-order插入顺序)
super(capacity, .75F, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
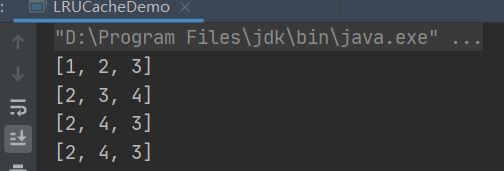
LRUCacheDemo lruCacheDemo = new LRUCacheDemo<>(3);
lruCacheDemo.put("1","a");
lruCacheDemo.put("2","b");
lruCacheDemo.put("3","c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put("4","d");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put("3","c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put("3","c");
System.out.println(lruCacheDemo.keySet());
}
} 
- 不使用LinkedHashMap
public class LRUCache {
// 定义一个双向链表
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {
}
public DLinkedNode(int key, int value) {
this.key = key;
this.value = value;
}
}
// 用来快速定位节点和记录节点数量
private Map cache;
private int capacity;
// 虚拟头节点,虚拟尾节点
private DLinkedNode head, tail;
/**
* 初始化方法
* @param capacity 指定缓存的容量
*/
public LRUCache(int capacity) {
this.capacity = capacity;
cache = new HashMap<>(capacity);
head = new DLinkedNode();
tail = new DLinkedNode();
// 建立虚拟头和虚拟尾节点的关系
head.next = tail;
tail.prev = head;
}
/**
* 从缓存中获取数据
* @param key 缓存的键
* @return 缓存的值
*/
public int get(int key) {
// 如果map中没有这个key,证明没有命中缓存,直接返回-1即可
if (!cache.containsKey(key)) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
DLinkedNode node = cache.get(key);
moveToHead(node);
return node.value;
}
/**
* 向缓存中写入数据
* @param key 写入的键
* @param value 写入的值
*/
public void put(int key, int value) {
if (!cache.containsKey(key)) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 新节点添加至双向链表的头部(虚拟头节点后面)
addToHead(newNode);
if (cache.size() > capacity) {
// 如果超出容量,删除双向链表的尾部节点(虚拟尾节点前面)
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
}
} else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
DLinkedNode node = cache.get(key);
node.value = value;
moveToHead(node);
}
}
// 插入头节点
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 删除节点
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
// 移动到头部
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
// 删除尾节点
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
} 11.LFU算法
LFU,全称是:Least Frequently Used,最不经常使用策略,在一段时间内,数据被使用频次最少的,优先被淘汰。最少使用(LFU)是一种用于管理计算机内存的缓存算法。主要是记录和追踪内存块的使用次数,当缓存已满并且需要更多空间时,系统将以最低内存块使用频率清除内存.采用LFU算法的最简单方法是为每个加载到缓存的块分配一个计数器。每次引用该块时,计数器将增加一。当缓存达到容量并有一个新的内存块等待插入时,系统将搜索计数器最低的块并将其从缓存中删除