梯度下降(Gradient Descent)原理以及Python代码
给定一个函数 ,我们想知道当
,我们想知道当 是值是多少的时候使这个函数达到最小值。为了实现这个目标,我们可以使用梯度下降(Gradient Descent)进行近似求解。
是值是多少的时候使这个函数达到最小值。为了实现这个目标,我们可以使用梯度下降(Gradient Descent)进行近似求解。
梯度下降是一个迭代算法,具体地,下一次迭代令
![]()
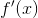 是梯度,其中
是梯度,其中 是学习率(learning rate),代表这一轮迭代使用多少负梯度进行更新。梯度下降非常简单有效,但是其中的原理是怎么样呢?
是学习率(learning rate),代表这一轮迭代使用多少负梯度进行更新。梯度下降非常简单有效,但是其中的原理是怎么样呢?
原理
为什么每次使用负梯度进行更新呢?这要从泰勒公式(Taylor's formula)说起:
![]()
泰勒公式的目的是使用![]() 的多项式去逼近函数,这里可以理解泰勒公式在
的多项式去逼近函数,这里可以理解泰勒公式在![]() 的展开是原函数的一个近似函数。
的展开是原函数的一个近似函数。
那泰勒公式跟梯度下降有什么关系呢?
我们的目标是使![]() ,我们对
,我们对![]() 在
在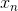 处进行一阶泰勒展开:
处进行一阶泰勒展开:
![]()
由此可知,我们只需令![]() ,就会使
,就会使![]()
所以迭代公式可以为![]()
案例
下面我们看具体例子,假设我们有以下函数
![]()
矩阵和 向量
向量 已知,我们想知道当取值为多少的时候,函数的值最小。
已知,我们想知道当取值为多少的时候,函数的值最小。
根据梯度下降法,我们只需计算出负梯度,然给定一个初始值 ,不断迭代就能找到一个近似解了。负梯度计算如下:
,不断迭代就能找到一个近似解了。负梯度计算如下:
![]()
接下来让我写一段代码解决这个问题
定义梯度下降函数
首先,定义cal_gradient函数用来计算梯度,然后使用gradient_decent进行迭代,其中learning_rate就是公式中的,这个值需要合理设置,过大的话会导致震荡,过下的话又会导致迭代时间过长。step代表迭代的次数,理想情况下找到满意的解就停止。
我们会在代码中调整这两个参数查看它们对求解过程的影响。
import numpy as np
import time
#calculate gradient
def cal_gradient(A, b, x):
left = np.dot(np.dot(A.T, A), x)
right = np.dot(A.T, b)
gradient = left - right
return gradient
# iteration
def gradient_decent(x, A, b, learning_rate, step):
start = time.time()
for i in range(step):
gradient = cal_gradient(A, b, x)
delta = learning_rate * gradient
x = x - delta
end = time.time()
time_cost = round(end - start, 4)
print('done! x = {a}, time cost = {b}s'.format(a=x, b=time_cost))求解过程
我们给了矩阵和向量的值以及标准答案 ![]() ,然后我们随机初始化一个,让学习率
,然后我们随机初始化一个,让学习率![]() ,迭代次数
,迭代次数![]()
A = np.array([[1.0, -2.0, 1.0], [0.0, 2.0, -8.0], [-4.0, 5.0, 9.0]])
b = np.array([0.0, 8.0, -9.0])
# Giveb A and b,the solution x is [29, 16, 3]
x0 = np.array([1.0, 1.0, 1.0])
learning_rate = 0.01
step = 1000000
gradient_decent(x0, A, b, learning_rate, step)结果
以下为结果,可以看出求得的近似解和标准答案 ![]() 还是非常接近的。
还是非常接近的。
done! x = [28.98272933 15.99042465 2.99763054], time cost = 4.6037s调整学习率
其他参数都一样,我们让学习率变小,运行相同的步数,从以下结果看到求得的近似解跟标准答案还有一定差距。这意味着小的过小学习率需要学习更久的时间。
learning_rate = 0.001
# result
# done! x = [15.8048349 8.68422815 1.18968306], time cost = 4.5997s
调整初始值
我们只调整初始值,学习相同的步数,发现求得的近似解尽管与标准答案相似,但是不如第一个方法求得解。这说明梯度下降方法也会受到初始值得影响。
x0 = np.array([1000, 1000, 1000])
# result
# done! x = [29.78036839 16.43265826 3.10706301], time cost = 4.5528s总结
梯度下降方法是一种非常有效的优化方法,它的效果会受到初始值、学习率、步数的影响。如果要说缺点的话,就是它容易找到局部最优解,有时候会发生震荡现象。
参考
https://sm1les.com/2019/03/01/gradient-descent-and-newton-method/