Bi-LSTM-CRF命名实体识别实战
一、数据集介绍
本项目的数据集来自于天池——基于糖尿病临床指南和研究论文的实体标注构建(瑞金医院MMC人工智能辅助构建知识图谱大赛第一赛季)。即提供与糖尿病相关的学术论文以及糖尿病临床指南,要求在学术论文和临床指南的基础上,做实体的标注。实体类别共十五类。
类别名称和定义
疾病相关:
1、疾病名称 (Disease),如I型糖尿病。
2、病因(Reason),疾病的成因、危险因素及机制。比如“糖尿病是由于胰岛素抵抗导致”,胰岛素抵抗是属于病因。
3、临床表现 (Symptom),包括症状、体征,病人直接表现出来的和需要医生进行查体得出来的判断。如"头晕" "便血" 等。
4、检查方法(Test),包括实验室检查方法,影像学检查方法,辅助试验,对于疾病有诊断及鉴别意义的项目等,如甘油三酯。
5、检查指标值(Test_Value),指标的具体数值,阴性阳性,有无,增减,高低等,如”>11.3 mmol/L”。
治疗相关:
6、药品名称(Drug),包括常规用药及化疗用药,比如胰岛素。
7、用药频率(Frequency),包括用药的频率和症状的频率,比如一天两次。
8、用药剂量(Amount),比如500mg/d。
9、用药方法(Method):比如早晚,餐前餐后,口服,静脉注射,吸入等。
10、非药治疗(Treatment),在医院环境下进行的非药物性治疗,包括放疗,中医治疗方法等,比如推拿、按摩、针灸、理疗,不包括饮食、运动、营养等。
11、手术(Operation),包括手术名称,如代谢手术等。
12、不良反应(SideEff),用药后的不良反应。
常规实体:
13、部位(Anatomy),包括解剖部位和生物组织,比如人体各个部位和器官,胰岛细胞。
14、程度(level),包括病情严重程度,治疗后缓解程度等。
15、持续时间(Duration),包括症状持续时间,用药持续时间,如“头晕一周”的“一周”。
链接:https://tianchi.aliyun.com/competition/entrance/231687/information
二、Bi-LSTM-CRF模型介绍
(一)Bi-LSTM
RNN为循环神经网络(Recurrent Neural Network),与全连接网络的不同之处是其隐藏层之间是有连接的,即每一时刻的输出都跟当前时刻的输入和上一时刻的输出有关,由于其具有记忆特性,可以处理前后输入有关系的序列数据。
LSTM为长短期记忆网络(Long-Short Term Memory),作为一种改进之后的RNN,LSTM的cell代替了普通RNN的隐单元,通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息。相比普通的RNN,LSTM能够在更长的序列中有更好的表现,解决RNN在长序列训练过程中的梯度消失和梯度爆炸问题。
Bi-LSTM为双向长短时记忆网络(Bi-directional Long-Short Term Memory)。LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。实际应用中,网络输出可能依赖于整个输入序列。Bi-LSTM是由前向LSTM与后向LSTM组合而成,通过Bi-LSTM可以更好的捕捉双向的语义依赖。
(二)CRF
CRF为条件随机场(Conditional Random Field),属于判别式概率图模型。CRF能够在已知观测变量序列的条件下,标记序列发生的概率。在该项任务中,观测序列为单词序列,标记序列为对应的词性序列,标记序列具有线性的序列结构。
Bi-LSTM的优点是能够通过双向的设置学习到观测序列(输入的字)之间的依赖,在训练过程中,LSTM能够根据目标(比如识别实体)自动提取观测序列的特征,但是缺点是无法学习到标记序列(输出的标注)之间的关系。在命名实体识别任务中,标注之间是有一定的关系的,比如B类标注(表示某实体的开头)后面不会再接一个B类标注,所以LSTM在解决NER这类序列标注任务时,虽然可以省去很繁杂的特征工程,但是也存在无法学习到标注上下文的缺点。
相反,CRF的优点就是能对标记序列建模,学习标记序列的特点,但它的缺点是需要手动提取观测序列特征。所以一般的做法是,在LSTM后面再加一层CRF,以获得两者的优点。
三、实战
(一)环境
Python 3.7.3
Tensorflow 2.1.0
(二)代码
1.数据处理
数据有两种文件*.txt和*.ann,*.txt文件为原始文档,*.ann文件为标注信息,标注实体以T开头,后接实体序号,实体类别,起始位置和实体对应的文档中的词。
*.txt文件的内容为:
...
糖控制水平的公认指标,但应该控制的理想水平即目
标值究竟是多少还存在争议。糖尿病控制与并发症试
验(DCCT,1993)、熊本(Kumamoto,1995)、英国前瞻性
糖尿病研究(UKPDS,1998)等高质量临床研究已经证
实,对新诊断的糖尿病患者或病情较轻的患者进行严
...
*.ann的内容为:
T1 Disease 1845 1850 1型糖尿病
T2 Disease 1983 1988 1型糖尿病
....
文字处理:
(1)讲*.txt文件中段落,按"。"句号切割,一共得到26869个句子,并划分训练集和测试集。
(2)讲数字按照"0"处理,增加识别新知识的能力。
(3)形成汉字对应序号的字典,字典中,
(4)将每个句子分别做分字处理,用字向量表示,字向量为字在字典中的序号构成的列表。处理后形成train_char列表。
(4)将每个句子用jieba分词工具做分词处理,用词向量表示,词向量为0、1、2、3构成的向量,0表示单字,1表示词的起始字,3表示词的终止字,2表示词的中间字。处理后形成train_seg列表。
标注处理:
BIOES标注含义,B,即Begin,表示开始;I,即Intermediate,表示中间;E,即End,表示结尾;S,即Single,表示单个字符;O,即Other,表示其他,用于标记无关字符。
(1)形成十五类标注对应的缩写的字典:
'Level': 'LEV',
'Test_Value': 'TSV',
'Test': 'TES',
...
(2)形成BIOES标注对应数字序号的字典和数字序号对应BIOES标注的字典,共有58种不同的标注方式:
0:O
1:I-TES
2:I-DIS
...
O:0
I-TES:1
I-DIS:2
...
(3)将每个句子的BIOES标注通过字典映射为序号构成的列表。处理后形成train_seg数组。
2.数据截断、补全
train_char_ = tf.keras.preprocessing.sequence.pad_sequences(train_char, maxlen=maxlen,
padding='pre',truncating='pre',value=0.0)
train_seg_ = tf.keras.preprocessing.sequence.pad_sequences(train_seg, maxlen=maxlen,
padding='pre',truncating='pre',value=0.0)
train_target_ = tf.keras.preprocessing.sequence.pad_sequences(train_target, maxlen=maxlen,
padding='pre',truncating='pre',value=0.0)
test_char_ = tf.keras.preprocessing.sequence.pad_sequences(test_char, maxlen=maxlen,
padding='pre',truncating='pre',value=0.0)
test_seg_ = tf.keras.preprocessing.sequence.pad_sequences(test_seg, maxlen=maxlen,
padding='pre',truncating='pre',value=0.0)
test_target_ = tf.keras.preprocessing.sequence.pad_sequences(test_target, maxlen=maxlen,
padding='pre',truncating='pre',value=0.0)3.模型构建
(1)输入层
设置两个输入层,输入层1为字向量信息,[batch_size, maxlen] -> [batch_size, maxlen],输入层2为词向量信息,[batch_size, maxlen] -> [batch_size, maxlen],每个句子固定maxlen个词,上述取1000。
(2)Embedding层(Embedding)
对应两个输入层,设置两个Embedding层,其中字向量对应的字嵌入层为[batch_size, maxlen] -> [batch_size, maxlen, char_embedding_dims],将字进行char_embedding_dims长度的编码,char_embedding_dims上述取100;词向量对应的词嵌入层为[batch_size, maxlen] -> [batch_size, maxlen, seg_embedding_dims],将词进行char_embedding_dims长度的编码,char_embedding_dims上述取20。
(3)拼接(Concatenate)
取字嵌入层和词嵌入层最后一维拼接起来,得到输出维度为[batch_size, maxlen, 120]。
(4)Bi-LSTM层(Bidirectional-LSTM)
叠加两层双向LSTM层,激活函数分别为tanh和softmax,得到输出维度为[batch_size, maxlen, 58],即58种不同的标注方式的预测分值。
(5)CRF层(CRF)
CRF层中的损失函数包括两种类型的分数,一是Emission Score,发射分数(状态分数),这些状态分数来自Bi-LSTM层的输出,即每个位置是各个标签的预测分值,是一个maxlen×58的矩阵;二是Transition Score,转移分数,即标签间的转移分数,是一个58*58的矩阵。
某个序列的分数si=Emission Score + Transition Score,
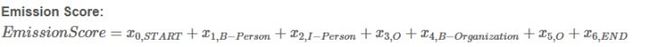

我们的训练目标通常是最小化损失函数,定义对数损失函数:

Bi-LSTM之上的CRF与普通CRF的区别:普通CRF的样本概率受特征函数和相关权值的影响,而Bi-LSTM上的CRF则没有特征函数,也没有权值,结果受Bi-LSTM层输出的各个位置标签概率,以及标签间的状态转移矩阵影响。对于Bi-LSTM+CRF的CRF层来说,要学习的就只有标签间状态转移矩阵而已。
根据tensorflow中的CRF.py,crf_log_likelihood函数输出的transition_params,就是要求解的状态转移矩阵。viterbi_decode(score, transition_params),就是通过Bi-LSTM的输出score和求解的状态转移矩阵transition_params来解码最终结果。
viterbi(维特比)算法是动态规划算法,每个子部分只存储最优子路径。其在计算过程中,有两类变量:obs 和 previous。previous存储的是上一个步骤的最终结果,即上一个单词对应各类别的最佳路径得分,obs代表当前单词包含的信息(发射分数)。有两个变量来储存历史信息,alpha0 和 alpha1,alpha0 是历史最佳的分数 ,alpha1 是最佳分数所对应的类别索引。最后一步,根据alpha0和alpha1存储的信息用来找到最佳路径。
得到输出维度为[batch_size, maxlen]
import tensorflow as tf
import tensorflow_addons as tfa
import numpy as np
import tqdm
from tensorflow.keras.models import Sequential
from tensorflow.keras.callbacks import TensorBoard
from CRF import CRF
# from CRF import CRF
class MyBiLSTMCRF:
def __init__(self, vocabSize, maxlen, tagIndexDict, tagSum, sequence_lengths=None):
self.vocabSize = vocabSize
self.maxlen = maxlen
self.tagSum = tagSum
self.sequence_lengths = sequence_lengths
self.tagIndexDict = tagIndexDict
self.vecSize = 100
self.segSize = 20
self.buildBiLSTMCRF()
def getTransParam(self, y, tagIndexDict):
self.trainY = np.argmax(y, axis=-1)
yList = self.trainY.tolist()
transParam = np.zeros([len(list(tagIndexDict.keys())), len(list(tagIndexDict.keys()))])
for rowI in range(len(yList)):
for colI in range(len(yList[rowI]) - 1):
transParam[yList[rowI][colI]][yList[rowI][colI + 1]] += 1
for rowI in range(transParam.shape[0]):
transParam[rowI] = transParam[rowI] / np.sum(transParam[rowI])
return transParam
def buildBiLSTMCRF(self):
input_1 = tf.keras.layers.Input(shape=(self.maxlen,), name='char')
input_2 = tf.keras.layers.Input(shape=(self.maxlen,), name='seg')
eb_1 = tf.keras.layers.Embedding(self.vocabSize, self.vecSize)(input_1)
eb_2 = tf.keras.layers.Embedding(4, self.segSize)(input_2)
concat = tf.keras.layers.Concatenate()([eb_1, eb_2])
x = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(
self.tagSum, return_sequences=True, activation="tanh"), merge_mode='sum')(concat)
x = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(
self.tagSum, return_sequences=True, activation="softmax"), merge_mode='sum')(x)
crf = CRF(self.tagSum, name='crf_layer')
output = crf(x)
myModel = tf.keras.models.Model([input_1, input_2], output)
myModel.compile('adam', loss={'crf_layer': crf.get_loss})
self.myBiLSTMCRF = myModel
def fit(self,X, y, epochs=100, transParam=None):
if len(y.shape) == 3:
y = np.argmax(y, axis=-1)
if self.sequence_lengths is None:
self.sequence_lengths = [row.shape[0] for row in y]
log_dir = "logs"
tensorboard_callback = TensorBoard(log_dir=log_dir, histogram_freq=1)
history = self.myBiLSTMCRF.fit(X, y, epochs=epochs, callbacks=[tensorboard_callback])
return history
def predict(self, X):
preYArr = self.myBiLSTMCRF.predict(X)
return preYArr