翻译Deep Learning and the Game of Go(5)第4章:使用树搜索来玩游戏(上)极小极大、深度剪枝、alpha-beta算法在围棋上的应用
第二部分 机器学习和游戏AI
在第二部分中,您将学习经典游戏AI和现代游戏AI的组件。您将从各种树搜索算法开始,这些算法是做游戏AI和优化各种问题必不可少的工具。接下来,您将了解深度学习和神经网络,从数学基础开始,并进行许多实际的设计考虑。最后,你会得到一个关于强化学习框架的介绍,这是让你的游戏AI能够通过练习提升的框架。
当然,这些技术不只是用在游戏上,一旦你掌握了这些组件,你将有机会将它们用到任何领域
第 4 章 使用树搜索来玩游戏
这一章包括:
- 使用极小极大算法去找到最好的落子点,实现极大极小井子棋AI
-
修剪极小极大树搜索以加快速度,实现两种AI:深度剪枝AI、alpha-beta剪枝AI
-
应用蒙特卡洛树搜索到游戏中:实现mcts AI
- 你有一系列的决定要做。在国际象棋中,你的决定是关于要移动哪个棋子。在仓库里,你的决定是关于下一步要拿起哪一件物品。
- 早期的决定都会影响我们未来的决定。在国际象棋中,提前移动一个棋子可能会让你的皇后在许多回合之后被攻击。在仓库里,如果你先去找17号货架上的一个小部件,你可能需要用各种方式回溯到99号货架之后。
- 在一系列步骤结束后,你可以评估一下有没有实现了目标。在国际象棋中,当你对局结束后,你就会知道谁赢了。在仓库里,你可以收集所有物品所花的时间。
- 可能序列的数量是很巨大的。下棋大概有
 种方法。在仓库里,如果你有20件东西要捡,就有20亿条可能的序列可供选择。
种方法。在仓库里,如果你有20件东西要捡,就有20亿条可能的序列可供选择。
当然,它们的类似仅此而已。例如,在国际象棋中,你会与一个积极地试图识破你意图的对手周旋,而这在任何仓库里都不会发生。
在计算机科学中,树搜索算法是一种在许多可能决策序列中寻找可以导向最优结果的一个序列的算法。在这一章中,我们涵盖了树搜索算法,许多原则可以扩展到其他优化问题。我们从极小极大搜索算法开始,在该算法中,每个回合中两个互相对立的玩家之间会轮流切换,这种算法可以找到完美的落子序列,但它的速度太慢,因此无法应用到复杂的游戏。接下来,我们将研究两种技术,只搜索树的一小部分去获得有用的结果。其中之一就是剪枝:可以加快对搜索树部分的评估。为了进行有效地修剪,您需要在代码中引入关于问题的真实世界知识,当这个无法做到时,你可以应用蒙特卡洛树搜索(MCTS)。它是一种随机搜索算法,可以在没有任何领域特定代码的情况下找到一个好结果。
当您的工具包中使用了这些技术,您就可以开始构建可以下各种棋和各种纸牌游戏的AI了
4.1 将游戏进行分类
- 确定性与非确定性-在确定性游戏中,游戏的过程只取决于玩家的决定。在非确定性博弈中,会涉及一个随机性元素,如打骰子或洗牌。
- 完全的信息与隐藏的信息——在完美的信息游戏中,两个玩家都可以随时看到完整的游戏状态;整个棋盘都是可见的,或者每个人出的的牌都在桌子上。在隐藏信息游戏中,每个玩家只能看到游戏状态的一部分,隐藏信息在纸牌游戏中很常见,每个玩家都会被处理几张牌,而不能选择其他球员持有的东西。隐藏信息游戏的部分吸引力在于根据其他玩家的游戏决定猜测他们的牌
在本章中,我们主要关注确定性的,有完全信息的游戏。在这种游戏的每一个回合中,理论上必有一个落子是最好的。没有运气和秘密成分;在你选择之前你就应该知道,你的对手可能会选择什么落子作为回应,以及在那之后你要下在哪里等等,直到比赛结束。从理论上讲,你应该把整盘对局在第一步的时候就计划好,而极大极小算法正是这样做的,从而能够有完美的发挥。
在现实中,国际象棋和围棋等经受了时间考验的游戏都有着大量的可能性。对人类来说,每个游戏似乎都有自己的生命,即使是计算机也不能一直计算到最后。
本章中的所有示例都包含了很少的游戏特定逻辑,因此您可以将它们适应于任何确定性的、有完全信息的游戏。要做到这一点,您可以遵循我们的goboard模块的模式在类中实现新的游戏逻辑,如Player、Move和GameState。Game State的基本功能是apply_move、legal_move、is_over和winner。我们已经实现了井字棋。
4.2 使用极大极小搜索法去预测你的对手
你如何去编写一个AI去决定在游戏中的下一步应该下在哪里?首先,你可以考虑人类是如何做出相同的决定。让我们从最简单的具有确定性和完全信息的游戏--井字棋开始。我们将要采用的技术名称是极小极大。这个术语是极小化和极大化的浓缩:你尽力想最大化你的局面评分,同时你的对手正尝试最小化你的局面评分时。你可以用一句话来总结算法:假设你的对手和你一样聪明。
让我们看看极小极大在实践中是如何使用的。看图4.1,想想下一步X应该下在哪里?
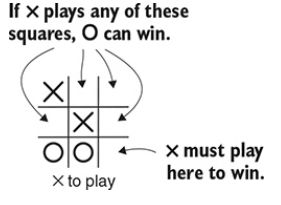
这里没有任何把戏,X下在右下角就可以赢得对局。你可以把这个变成一个一般的规则:去下任何能够立即赢得对局的落子。这个规则永远不可能出错。你可以参照下面代码去实现这种规则
# 寻找必胜下法
def find_winning_move(game_state, next_player):
for candidate_move in game_state.is_valid(next_player):
next_state = game_state.apply_move(candidate_move)
# 如果下到这里棋局结束且赢家就是你,就选择下在这里
if next_state.is_over() and next_state.winner == next_player:
return candidate_move
return None
我们往回倒一步,你是怎么得到这个局面的?也许前面一步的局面看起来像图4.3。O天真地希望在底部连成三个棋子,但那只有在X配合你的时候才会成立,这就导出了一个推论:不要选择任何让你的对手可以获胜的落子点。

实现大致如下:
# 去除会让对方一步获胜的落子点
def eliminate_losing_moves(game_state, next_player):
opponent = next_player.other()
possible_moves = [] #所有不会让对方一步获胜的合法落子点
for candidate_move in game_state.legal_moves(next_player):
# 计算你如果下了这个点后棋盘盘面会怎么样
next_state = game_state.apply_move(candidate_move)
# 看看会不会给你的对手带来胜利,如果不行就就加入到数组中
opponent_winning_move = find_winning_move(next_state, opponent)
if opponent_winning_move is None:
possible_moves.append(candidate_move)
return possible_moves现在,你知道你必须阻止你的对手进入一个胜利的局面。因此,你应该假设你的对手也会这样对你。考虑到这一点,你要怎么才能赢呢?看看图4.4中的棋盘。

如果你在下在中间,你就有两种方法可以连成三子:1和2,对手根本无法阻挡你获胜。于是我们可以这样描述这个一般原则:寻找一个对手无法阻止你取胜的落子点。这听起来很复杂,但是在已经编写的函数之上构建这个逻辑很容易。
# 寻找可以两步获胜的落子点,即对手无法阻止你获胜
def find_two_step_win(game_state, next_player):
opponent = next_player.other()
for candidate_move in game_state.legal_moves(next_player):
# 假定下了这步棋,去看看对手有无好的方法去阻止你获胜
next_state = game_state.apply_move(candidate_move)
good_responses = eliminate_losing_moves(next_state, opponent)
if not good_responses:
return candidate_move
return None你的对手会预料到你会这样做,并试图阻止这样的下法。现在你可以看到一个总的战略:
1 看看你下一步能不能赢。如果能赢,那就去下。
2 如果不能赢,就去看看你的对手下一步是否能赢。如果能的话,就去阻止它
3.如果也不能的话,看看你能不能在两步后取得胜利。如果能的话,那就去下吧。
4.如果还没有,那就看看你的对手能不能两步取胜。
请注意,所有三个函数都具有类似的结构。每个函数循环遍历所有有效的落子,并评估假定落子后的棋盘局面。此外,每个函数都建立在前一个函数的基础上,以模拟对手的反应。如果你归纳好这些函数,你就会得到一个总能确定最好的落子的算法。
4.3 一个极大极小算法的例子:解决井字棋
在上一节中,你研究了如何预测对手的一到两个动作落子。在这一节中,我们展示了如何去归纳这一策略,从而选择出好的举措。这个核心思想是完全相同的,但您需要灵活性,从而在未来看到任意数量的落子。
首先,让我们定义一个枚举类型,它代表一个游戏的三个可能的结果:输、赢或平局。这些可能性是相对于一个特定的玩家来定义的:一个玩家数,那另一个就是赢了。
import enum
# 游戏的三种状态
class GameResult(enum.Enum):
loss = 1
draw = 2
win = 3想象一下,你有一个函数best_result,它告诉你可以在该棋盘状态下获得的最佳结果。如果能保证一位棋手以任何顺序取胜,那么就不会太复杂,结果将会返回GameResult.Win。如果最佳结果是平局,该函数将返回GameResult.Draw。否则,它将返回Game Result.loss。如果您假设函数已经存在,那就很容易编写一个函数来选择一个落子:您可以循环所有可能的落子,然后调用best_result函数,并选择能导致您的结果最佳的落子。有可能不同的落子会导向相同的结果,在这种情况下,您可以从它们中随机选择一个落子去下。下面显示了如何实现这一点。
先在之前GameState类里加上获取所有合法点的方法
# 获取所有合法落子点
def legal_moves(self):
moves = []
for row in range(1, self.board.num_rows + 1):
for col in range(1, self.board.num_cols + 1):
move = Move.play(Point(row, col))
if self.is_valid_move(move):
moves.append(move)
return moves然后设计一个使用极小极大算法的AI,对每一个合法的落子点,去判断对手在该点落子后的最好结果,根据结果放入到相应的集合里,若有必胜招法,就随机选一种,否则去看有无平局招法,有就随机一种,若都无就是随机的必输招法,其实这时就可以投降了,算法如下:
# 使用极小极大算法的AI
class MiniMaxAgent(Agent):
def select_move(self,game_state):
winning_moves = [] # 赢棋落子点集合
drawing_moves = [] # 平局落子点
losing_moves = [] # 输棋落子点
for possible_move in game_state.legal_moves():
next_state = game_state.apply_move(possible_move)
opponent_best_result = best_result(next_state) # 查看对手在我落子后的最好结果
if opponent_best_result == GameResult.loss: # 对手必输
winning_moves.append(possible_move)
elif opponent_best_result == GameResult.draw: # 对手最好是平局
drawing_moves.append(possible_move)
else:
losing_moves.append(possible_move)
# 有必胜招法,就随机选一种去下
if winning_moves:
return random.choice(winning_moves)
elif drawing_moves:
return random.choice(drawing_moves)
else:
return random.choice(losing_moves)现在的主要问题是如何实现best_result这个方法,可以像之前章节一样,先从游戏结束开始判断
# 得到游戏的最佳结果
def best_result(game_state):
if game_state.is_over():
if game_state.current_player == game_state.winner():
return GameResult.win
elif game_state.winner() is None:
return GameResult.draw
else:
return GameResult.loss如果你在中盘阶段,你需要往下搜索。到现在,所有模式就比较熟悉了。您首先要循环遍历所有可能的落子和计算下一个游戏状态,然后你必须假设你的对手会尽力反击你。要做到这一点,您可以调用best_result去获得这个新局面下你的对手的最佳结果,从而知道你的结果。在你所考虑的所有落子中,你去选择一个能为你带来最好结果的落子。下图展示了这个过程:

你可以在上面best_result里加上以下代码
best_result_so_far = GameResult.loss
for candidate_move in game_state.legal_moves():
next_state = game_state.apply_move(candidate_move) # 获得如果落了这个子后的局面
opponent_best_result = best_result(next_state) # 对方的最好结果
our_result = reverse_game_result(opponent_best_result) # 我的最好结果
if our_result > best_result_so_far: # 我当前的最好结果比默认好,所以更新最好结果
best_result_so_far = our_result
return best_result_so_far如果你把这个算法应用到一个简单的游戏中,比如井字棋,那么你会得到一个无法被击败的对手。.理论上,这种算法也适用于国际象棋、围棋或任何其他确定性的、具有完全信息地博弈。但实际上,这种算法对于任何一种游戏来说都太慢了
注:有关使用极大极小算法实现井字棋AI实现的所有代码我都放在这个网盘链接里https://pan.baidu.com/s/1l0C18DAOqXDGg3E_zP7q5Q
4.4用剪枝减少搜索空间
在我们的井字棋游戏中,您计算了每一个可能的情况,从而找到完美的策略。井字棋只有不到30万个可能的情况,一台现代电脑的很快能算出来,那能不能把同样的技术应用于更有趣的游戏吗?举个例子,西洋跳棋大约有50000亿亿可能的棋盘局面。从技术上来一台现代计算机需要几年的时间才能搜索完。在国际象棋和围棋中,棋盘局面的种类比宇宙中的原子还多,因此遍历所有的局面是不可能的。
要使用树搜索来玩一个复杂的游戏,你需要一个策略来消除树的部分。跳过部分树的过程,我们称为剪枝。
游戏树是二维的:它们有宽度和深度。宽度是从给定棋盘盘面所找到的可能落子数目。深度是指从棋盘当前状态到结束的回合数。在一个游戏中,这两个量都是不同的。
一般来说,你会根据典型的宽度和特定游戏的深度去评估树的尺寸。游戏树中棋盘局面的个数公式可以粗略表示成![]() ,其中W为平均宽度,d为平均深度。图4.6和4.7展示了一棵井字棋树的宽度和深度。例如,在国际象棋中,一个棋手通常每步大约有30种选择,一局大约有要走80步;树的大小大约是
,其中W为平均宽度,d为平均深度。图4.6和4.7展示了一棵井字棋树的宽度和深度。例如,在国际象棋中,一个棋手通常每步大约有30种选择,一局大约有要走80步;树的大小大约是![]() 。围棋通常每回合约有250个合法动作,一局可能会持续150个回合,因此游戏树的大小约为
。围棋通常每回合约有250个合法动作,一局可能会持续150个回合,因此游戏树的大小约为![]() 。
。

4.6 一开始有9个选择,但是接下来选择会越来越少,因此平均宽度约为4-5个
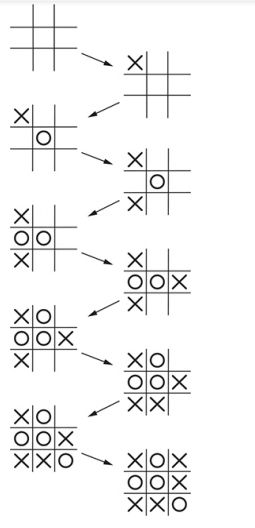
3.7深度最大是9,因此局面总数不到30万个
这个公式,![]() 是指数增长的一个例子:当你增加搜索深度时,要考虑的棋盘盘面数目就会迅速增长。想象一下,一个平均宽度和深度约为10的游戏.,其完整的游戏树将包含100亿的棋盘局面。
是指数增长的一个例子:当你增加搜索深度时,要考虑的棋盘盘面数目就会迅速增长。想象一下,一个平均宽度和深度约为10的游戏.,其完整的游戏树将包含100亿的棋盘局面。
现在假设你想出了一些适度的修剪方案。首先,你想出如何在一个回合上快速评估两个落子,将有效宽度减少到8。第二,你决定只看9个而不是10个落子就能算出比赛结果,这样你只需要计算![]() 个局面,大约是1.3亿。与完整的搜索相比,您已经消除了98%以上的计算!关键的一点是,即使稍微减少搜索的宽度或深度,也可以大幅度地降低选择落子所需的时间。图4.8说明了剪枝对小树的影响。
个局面,大约是1.3亿。与完整的搜索相比,您已经消除了98%以上的计算!关键的一点是,即使稍微减少搜索的宽度或深度,也可以大幅度地降低选择落子所需的时间。图4.8说明了剪枝对小树的影响。

在本节中,我们将涵盖两种剪枝技术:用于减少搜索深度的局面评估函数和用于减少搜索宽度的α-β剪枝。这两种技术结合在一起形成经典游戏AI的支柱。
4.4.1 使用局面评估来减少搜索深度
如果你沿着一棵游戏树直到游戏结束,你可以计算出对局的获胜者。那在对局的早期呢?人类棋手通常有一种谁在中盘领先的感觉。即使是初学者,也会本能地感觉到他们是否在主导他们的对手。如果你能让计算机程序拥有这种感觉,你就可以减少你需要搜索的深度。一个模仿这种感觉及计算领先多少的函数,就是一个局面评估函数。
对于许多游戏,局面评估功能可以通过使用游戏知识进行人工制定。举个例子:
- 跳棋——棋盘上的每一个棋子都算一分,国王再加上两分。用你的棋子的值,减去你对手的值。
- 国际象棋——每个棋子算一分,每个马或象算三分,每个车算五分,皇后就是九分。取你的棋子的值,减去你对手的值。
这些评估功能是高度简化的;顶级跳棋和国际象棋引擎会使用更复杂的方法。但在这两种情况下,人工智能将会尽力吃对手的棋子并保护自己的棋子。此外,它将愿意牺牲掉自己分值低的棋子,去吃对方一个分值高的棋子。
在围棋中,类似的方法是把你吃掉的棋子加起来,然后减去你对手吃到的棋子数量。下面的代码就实现了这种启发式算法,但这不是一个十分有效的评估方法。因为在围棋中,吃棋的威胁比实际吃它们要重要得多。对于一局对弈来说,100回合内没有任何棋子被吃是很平常的。我们要写一个局面评估函数,去准确地捕捉游戏状态的细微差别,但结果证明是非常困难的。
也就是说,您可以使用这种过于简单的方法来实现修剪技术,虽然这样的AI不会太强大,但它总比完全随机选择落子要好。在第11章和第12章中,我们将讨论如何使用深度学习去生成更好的评估函数。
在您选择了一个评估函数之后,您就可以实现深度修剪。搜索不是一直到对局结束去看谁会赢,你只需要搜索一个固定数量的局面,并使用评估函数来估计谁更有可能赢。
注:我把下面代码放在了agent下的新文件depthpruneAgent.py里作为深度剪枝的功能函数
from dlgp import gotypes
# 用棋盘上黑白棋子数目来评估棋盘---最简单的评估
def capture_diff(game_state):
black_num = 0
white_num = 0
# 遍历棋盘获得黑白棋子个数
for r in range(1, game_state.board.num_rows+1):
for c in range(1, game_state.board.num_cols+1):
point = gotypes.Point(row=r,col=c)
color = game_state.board.get(point)
if color == gotypes.Player.black:
black_num += 1
elif color == gotypes.Player.white:
white_num += 1
# 根据当前的落子方得出局面相应的评估
diff = black_num - white_num
if game_state.current_play == gotypes.Player.black:
return diff
else:
return -1*diff下面显示一个部分使用深度修剪的搜索树。(为了节省空间,我们已经将大部分分支排除在图之外,但算法也会检查这些分支。

图4.9 一棵特定的搜索树。现在你要往前算两步,你将通过吃子数量来评估棋盘。如果黑色选择最右边的分支,白棋可以吃掉一个黑棋,从而对黑棋产生-1的评价。如果黑棋选择中间的分支,黑棋暂时是安全的。所以黑棋会选择中间这个分支
在这棵树中,您正在向前2个局面的深度,并使用吃掉的棋子数作为棋盘的评估函数。原来的局面显示黑棋只有一个棋子且只有一口气,那黑棋应该做什么?如果黑棋一直往下走,如中间的分支所示,棋子是安全的(目前)。如果黑棋下在其他地方,白人就能抓住石头-左边分支显示了许多可能发生的方式之一。在向前看两步之后,您将您的评估函数应用到该位置。在这种情况下,白棋就可以吃掉黑棋----左边的分支就是这种事情发生的一种情况。
在搜索了两步以后,你会应用这种评估函数到棋盘上。这个情况下,凡是两个回合下白棋吃掉一个黑棋的情况白棋分数都会+1,而黑棋都会-1。而其他分支分数都是0。因此,黑色会选择唯一的落子去保护自己的棋子
下面就展示了如何实现深度修剪。该代码看起来类似于与上面的完整极小极大代码:如果比较这两个代码会对你有帮助。需要注意它们的不同之处:
- 下面的函数不是返回赢、输、平局,而是返回一个数字,来指示当前局面评估的值。我们的惯例是,得分是从棋手的角度来看他的下一回合:分数高意味着下一步棋手有希望获胜。当你从对手的角度来评估棋盘时,你要把分数乘以-1。
- max_depth控制要向前搜索的落子次数。在每一个回合中,你要把这个值中减去1。
- 当max_depth减到到0时,你就停止搜索,然后调用你的评估函数
# 根据评估函数获得当前局面的最佳结果
def best_result(game_state, max_depth, eval_fn):
# 由于暂时未实现判断输赢,先不看结果
'''if game_state.is_over():
if game_state.winner() == game_state.black:
return Max_Score
elif game_state.winner() == game_state.white:
return Min_Score'''
# 当搜索完了就返回评估结果
if max_depth == 0:
return eval_fn(game_state)
# 主要
best_result_so_far = Min_Score
for candidate_move in game_state.legal_moves():
next_state = game_state.apply_move(candidate_move)
# 对方的最好结果
opponent_best_result = best_result(next_state, max_depth-1, eval_fn)
our_result = -1*opponent_best_result
if our_result>best_result_so_far:
best_result_so_far = our_result
return best_result_so_far因此,相应的剪枝AI定义如下:
# 深度剪枝
class DepthPruneAgent(Agent):
def __init__(self,max_depth,eval_fn):
Agent.__init__(self)
self.max_depth = max_depth
self.eval_fn = eval_fn
def select_move(self, game_state):
# 最好的下法集合
best_moves = []
best_score = 0
# 遍历所有的合法落子
for possible_move in game_state.legal_moves():
# 得出落子后的局面
next_state = game_state.apply_move(possible_move)
# 得出对手的最佳结果
opponent_best_outcome = best_result(next_state,self.max_depth,self.eval_fn)
# 我们的最佳结果
our_best_outcome = -1 * opponent_best_outcome
if not best_moves or our_best_outcome>best_score:
best_moves = [possible_move]
best_score = our_best_outcome
elif our_best_outcome == best_score:
best_moves.append(possible_move)
return random.choice(best_moves)最后与深度剪枝AI进行5*5的对局
'''
人与使用深度剪枝的极小极大AI对弈,默认人拿黑棋
考虑到变化还是太多,所以棋盘设为5*5
'''
from dlgo.gotypes import Player,Point
from dlgo.utils import print_move,print_board,get_from_input
from dlgo.agent.DepthPruneAgent.depthpruneAgent import DepthPruneAgent
from dlgo import goboard
from six.moves import input
import time
# 用棋盘上黑白棋子数目来评估棋盘---最简单的评估
def capture_diff(game_state):
black_num = 0
white_num = 0
# 遍历棋盘获得黑白棋子个数
for r in range(1, game_state.board.num_rows):
for c in range(1, game_state.board.num_cols):
point = Point(row=r,col=c)
color = game_state.board.get(point)
if color == Player.black:
black_num += 1
elif color == Player.white:
white_num += 1
# 根据当前的落子方得出局面相应的评估
diff = black_num - white_num
if game_state.current_player == Player.black:
return diff
else:
return -1*diff
def main():
# 建一个5*5的棋盘
game = goboard.GameState.new_game(5)
bot = DepthPruneAgent(2,capture_diff)
while not game.is_over():
print_board(game.board)
if game.current_player == Player.black:
human_input = input('-- ')
point = get_from_input(human_input)
move = goboard.Move.play(point)
else:
# 计算一下AI的思考时间
start_time = time.time()
move = bot.select_move(game)
end_time = time.time()
print("AI思考时间:"+str(end_time-start_time)+"秒")
print_move(game.current_player,move)
game = game.apply_move(move)
if __name__ == '__main__':
main()
下图是我与该深度剪枝AI对弈的结果图
(1)一开始,我故意下在A1,看它会不会去吃,结果它真的去吃了,说明评估函数起作用了

( 2)我下在D5要吃掉D4,结果它没去跑D4,而是走在C2,因为它认为自己的最好结果是吃掉C1解救自己的5个子,这也是评估函数起到的作用

同时我们还可以看到AI的思考时间会越来越小,因为需要考虑的局面种类也变小了
4.4.2 使用alpha-beta剪枝减少搜索宽度
看下图,轮到黑棋落子了,现在你正在考虑下在方框处。如果你这样下,白棋就可以在A点吃掉你四颗棋子,很明显对于黑棋来说是一场灾难!当然白棋下在B点更好,但不管怎么样,对黑棋来说都很糟糕。从黑棋的角度来看,他并不关心A点是否是白棋肯定会下的最佳点,一旦你发现了你下在这会受到强有力的回击,你就可以不会下在那里,然后去思考新的选择。这就是alpha-beta剪枝背后的思想。


让我们来看看alpha-beta算法将如何应用于这一局面。alpha-beta剪枝就像一个常规的深度剪枝树搜索。图4.11显示了第一步。你挑第一个落子去评估黑棋的局面;该落子在图中用A来标记,然后你完全评估的深度设为3。你可以看到,无论白棋如何回应,黑棋都可以吃掉两棵棋子,因此你可以把这个分支评估为黑棋得2分。

现在您考虑黑棋下一个候选点,标记为B。就像深度剪枝搜索一样,你可以看到所有可能的白色回应,并且逐一去评估它们。白棋在左上角可以吃掉四个黑棋,因此该分支对黑棋来说应该是-4。而现在,你已经知道如果黑棋下在A点,保证至少得2分。如果黑棋下在B点,你只是看到白棋让你得-4分。当然白棋有更好地走法,但是由于-4已经比2更糟糕了,所以没有必要进一步搜索,这样你就可以跳过许多没有比较的评估,使得你计算速度变快

对于本例的目的,我们选择了一个特定的顺序来评估落子,以说明修剪是如何工作的。我们的实际执行是按照他们的棋盘坐标进行顺序评估。alpha-beta剪枝节省的时间取决于你找到好分支的速度。如果你碰巧在早期就评估到最好的分支,那你可以很快消除其他分支。最坏的情况是,您最后才能得到最好的分支,这样alpha-beta剪枝将不比完全深度剪枝搜索快。
要实现该算法,您必须在你的搜索过程中跟踪目前为止每个棋手的最佳结果。这些值传统上被称为alpha和beta,这就是算法的名称的由来。在我们的实施过程中,我们把价值叫做best_black和best_white
首先,检查是否需要更新best_white。接下来,您将检查是否可以停止评估白方的落子,其方法是将任意分支得到的黑棋最佳分数与你当前的分数进行比较。如果白棋能让黑棋不能得到最佳,那黑棋不会选择这个分支,这样你就不需要去找到绝对最好的分数。(alpha-beta思想的核心)
实现如下:
from dlgo.agent.base import Agent
from dlgo.gotypes import Player
Max_Score = 999999
Min_Score = -999999
# alpha-beta评估局面来说明是否停止搜索该分支
def alpha_beta_result(game_state, max_depth, best_black, best_white, eval_fn):
'''if game_state.is_over():
if game_state.winner() == game_state.black:
return Max_Score
elif game_state.winner() == game_state.white:
return Min_Score'''
# 当搜索完了就返回评估结果
if max_depth == 0:
return eval_fn(game_state)
best_result_so_far = Min_Score
for possible_move in game_state.legal_moves():
next_state = game_state.apply_move(possible_move)
opponent_result = alpha_beta_result(next_state,max_depth-1,best_black,best_white,eval_fn)
my_result = -1*opponent_result
if my_result>best_result_so_far:
best_result_so_far = my_result
# 上面和深度剪枝基本一致,下面是alpha-beta剪枝新增的
# 当前是白棋
if game_state.current_player == Player.white:
if best_white < best_result_so_far:
best_white = best_result_so_far
black_result = -1 * best_result_so_far
# 你在为白方挑选一个落子,一旦你找到了让黑棋的最佳选择变小,你就可以停止搜索了
if black_result 使用Alpha-Beta剪枝后的AI
# alpha-beta剪枝后的AI
class AlphaBetaAgent(Agent):
def __init__(self, max_depth, eval_fn):
Agent.__init__(self)
self.max_depth = max_depth
self.eval_fn = eval_fn
# 核心:选择落子
def select_move(self,game_state):
best_moves = []
best_score = 0
best_black = Min_Score
best_white = Min_Score
for possible_move in game_state.legal_moves():
next_state = game_state.apply_move(possible_move)
# 获取对手的最佳
opponent_best = alpha_beta_result(next_state,self.max_depth,best_black,best_white,self.eval_fn)
my_result = -1*opponent_best
if not best_moves or (my_result>best_score):
best_moves = [possible_move]
best_score = my_result
# 更新best_black和best_white
if game_state.current_player == Player.black:
best_black = best_score
elif game_state.current_player == Player.white:
best_white = best_score
elif my_result == best_score:
best_moves.append(possible_move)
return random.choice(best_moves)主文件(代码几乎和前面深度剪枝一样)
from dlgo.agent.alphabetaAgent.alphabetaAgent import AlphaBetaAgent
from dlgo.gotypes import Player,Point
from dlgo import goboard
from dlgo.utils import print_move,print_board,get_from_input
from six.moves import input
import time
# 用棋盘上黑白棋子数目来评估棋盘---最简单的评估
def capture_diff(game_state):
black_num = 0
white_num = 0
# 遍历棋盘获得黑白棋子个数
for r in range(1, game_state.board.num_rows):
for c in range(1, game_state.board.num_cols):
point = Point(row=r,col=c)
color = game_state.board.get(point)
if color == Player.black:
black_num += 1
elif color == Player.white:
white_num += 1
# 根据当前的落子方得出局面相应的评估
diff = black_num - white_num
if game_state.current_player == Player.black:
return diff
else:
return -1*diff
def main():
# 建一个5*5的棋盘
game = goboard.GameState.new_game(5)
bot = AlphaBetaAgent(2,capture_diff)
while not game.is_over():
print_board(game.board)
if game.current_player == Player.black:
human_input = input('-- ')
point = get_from_input(human_input)
move = goboard.Move.play(point)
else:
start_time = time.time()
move = bot.select_move(game)
end_time = time.time()
print("AI思考时间:"+str(end_time-start_time)+"秒")
print_move(game.current_player,move)
game = game.apply_move(move)
if __name__ == '__main__':
main()最后我们结果,发现alpha-beta剪枝后的AI速度明显快了不少,下面是我的截图
当人下在B1想吃A1时,AI在5秒内就做出逃的操作,即A2,要知道这可是在棋局刚开始阶段啊,按照深度剪枝需要25秒左右,因此可以得出结论:alpha-beta剪枝大大提升了速度

总结
- 树搜索算法评估许多可能的决策序列从而找到最佳决策序列。树搜索可以应对游戏中的一般的优化问题。
- 树搜索应用到游戏中一个变种就是极小极大树搜索。在极小极大树搜索中,两个棋手之间的目标刚好相反,即你想要最好下法,对于对方来说就是最差结果。
- 完整的极大极小树搜索在非常简单的游戏上是实用的(例如井字棋),但要将其应用于复杂的游戏(如国际象棋或围棋),您需要减少您的搜索树的大小。
- 局面评估函数是估计哪个玩家更有可能在当前局面下获胜。如果你有了一个好的局面评估函数,你就不需要一直搜索到游戏结束才能做出决定。这种策略称为深度剪枝
- Alpha-Beta剪枝减少了你需要考虑的每一个回合的落子数目,使其可以应用到如国际象棋这样的游戏重,其剪枝的概念是直观的:当评估一个可能的移动落子时,如果你发现你要是下了这步棋,你的对手可以让你不能得到最佳,那你可以就应该立即放弃这一落子,重新去考虑新的落子点,这样就大大减少了需要考虑的棋盘局面
- 评估函数暂时是最简单的根据棋盘上的黑白棋子树进行判定,显然不是一个很好的局面评估函数,下一节将介绍蒙特卡洛算法的应用,可以帮助我们建立一个更好地评估函数