python爬虫 知乎热榜、微博热搜并发送邮件至邮箱
目录
- 爬取知乎热榜、微博热搜并发送邮件至邮箱
-
- 1.获取网页
-
- 1.1获取url
- 1.2构造headers
- 1.3代码
- 2.提取信息
-
- 2.1 XPath规则
- 2.2 定位到节点
- 2.3 提取标题和url
- 2.4 代码
- 3.发送邮件
- 4. 完整代码
爬取知乎热榜、微博热搜并发送邮件至邮箱
以此项目为例,借机了解爬虫。本文通过requests请求,XPath解析,只涉及操作与代码,未涉及相关基础知识讲解。
1.获取网页
以知乎热榜为例
1.1获取url
知乎热榜的url:https://www.zhihu.com/hot
由于需要爬取的内容都在这页,并不需要再做改动
1.2构造headers
首先user-agent是肯定需要包含的
打开发现需要登陆才能进入热榜,因此还需要在请求头里包含cookie。
这里用的是chrome来展示如何获取
- 右键 -> 检查
- 点开Network
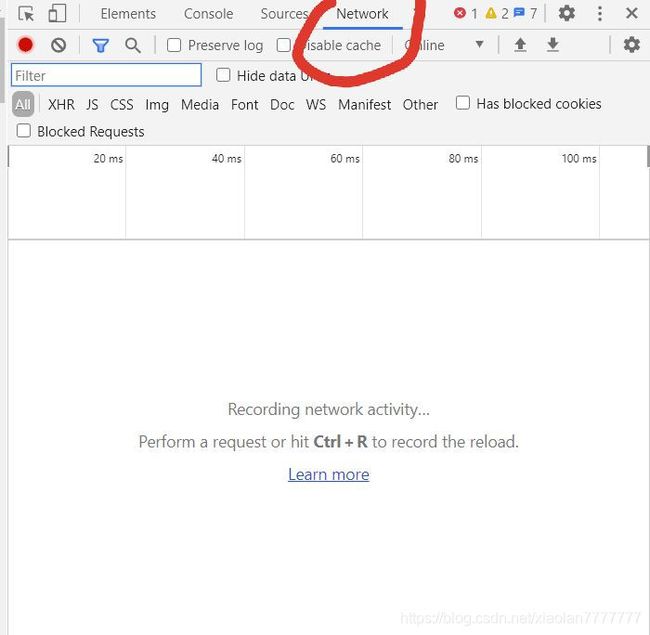
- 刷新浏览器

- 点暂停 -> 选取时间结点 -> 找到hot
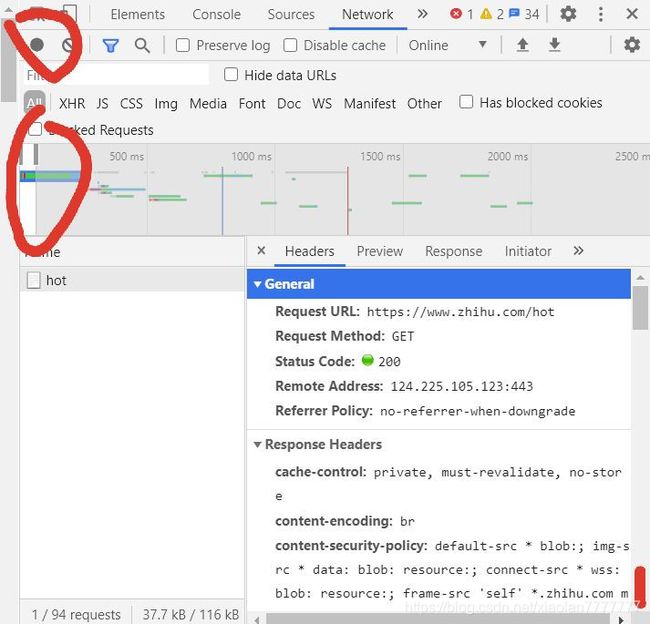
- 点开找到 cookie 和 user-agent并复制下来
1.3代码
import requests
import random
url = 'https://www.zhihu.com/hot'
headers = {
'cookie': '_zap=2a9ae3ab-f2e0-40ff-8a2e-02429c9f0453; d_c0="AGBYvpm7gxGPTiIzHTJtlff00GVsElpFRn0=|1593678215"; _ga=GA1.2.646074918.1593678215; q_c1=a1321aa361ac4df2a0709bb3660b1f60|1596371586000|1596371586000; _gid=GA1.2.1339168512.1596893630; tst=h; tshl=; _xsrf=3woUaVZtwUGqsDKF39WzhwXpU4DZsUV3; SESSIONID=RvdKKA5NNC2mAzAPi145hK2I2IHUIp0Zz16MOt1aWLb; JOID=UloUB0kg0XEVGHmbLiThaxIUcxU-cKQQWFE6rWVskEB9XwHYffEkXU4YeJ0tDY26KUIJ-175v2eF9D1gw2yF8Yk=; osd=W1gdAE8p03gSHnCZJyPnYhAddBM3cq0XXlg4pGJqmUJ0WAfRf_gjW0cacZorBI-zLkQA-Vf-uW6H_Tpmym6M9o8=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1596977420,1596978055,1596978079,1596978130; capsion_ticket="2|1:0|10:1596979172|14:capsion_ticket|44:OWI2NWE3MTVhZDIxNDFiNGI5ZDliZTkzZTE5ZDA1Zjg=|4be161b423d84930ff865a122e22fff3d030d468f49953b4a4dce73318c457e4"; z_c0="2|1:0|10:1596979174|4:z_c0|92:Mi4xNDhPdkFnQUFBQUFBWUZpLW1idURFU1lBQUFCZ0FsVk41a1VkWUFBR0N4dXF4Y2lkdnJDZ2c3bmMtaFhZQ0JjT25B|5020e8ce44cadc7cc35f2ee7b5d1c3f30f85c212d5e4fac081894b11c05110b6"; KLBRSID=d6f775bb0765885473b0cba3a5fa9c12|1596979708|1596977420; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1596979708',
'User-Agent': 'Mozilla%d/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36' % random.randint(
55, 100),
}
r = requests.get(url, headers=headers)
print(r.text)
运行结果应是打印出知乎热榜的html。
2.提取信息
2.1 XPath规则

2.2 定位到节点
如果使用chrome则可以偷工减料一步。
进入知乎热榜 -> 右键检查 -> 找到需要提取信息的标签 -> 右键Copy -> Copy XPath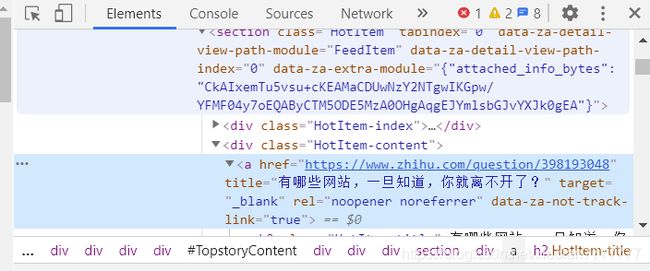
copy的结果定位到这个节点的XPath路径,之后可以直接进行提取了。
2.3 提取标题和url
在提取之前我们先观察XPath路径
热榜第一的XPath
//*[@id="TopstoryContent"]/div/div/div[2]/section[1]/div[2]/a
热榜第二的XPath
//*[@id="TopstoryContent"]/div/div/div[2]/section[2]/div[2]/a
由此易观察出它们只有section[i]变化,i 代表热榜的排名。
因此可以构造出提取标题和url的XPath了
path = '//*[@id="TopstoryContent"]/div/div/div[2]/section/div[2]/a'
titles = html.xpath(path + '/h2/text()')
links = html.xpath(path + '/@href')
2.4 代码
import requests
import random
from lxml import etree
url = 'https://www.zhihu.com/hot'
headers = {
'cookie': '_zap=2a9ae3ab-f2e0-40ff-8a2e-02429c9f0453; d_c0="AGBYvpm7gxGPTiIzHTJtlff00GVsElpFRn0=|1593678215"; _ga=GA1.2.646074918.1593678215; q_c1=a1321aa361ac4df2a0709bb3660b1f60|1596371586000|1596371586000; _gid=GA1.2.1339168512.1596893630; tst=h; tshl=; _xsrf=3woUaVZtwUGqsDKF39WzhwXpU4DZsUV3; SESSIONID=RvdKKA5NNC2mAzAPi145hK2I2IHUIp0Zz16MOt1aWLb; JOID=UloUB0kg0XEVGHmbLiThaxIUcxU-cKQQWFE6rWVskEB9XwHYffEkXU4YeJ0tDY26KUIJ-175v2eF9D1gw2yF8Yk=; osd=W1gdAE8p03gSHnCZJyPnYhAddBM3cq0XXlg4pGJqmUJ0WAfRf_gjW0cacZorBI-zLkQA-Vf-uW6H_Tpmym6M9o8=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1596977420,1596978055,1596978079,1596978130; capsion_ticket="2|1:0|10:1596979172|14:capsion_ticket|44:OWI2NWE3MTVhZDIxNDFiNGI5ZDliZTkzZTE5ZDA1Zjg=|4be161b423d84930ff865a122e22fff3d030d468f49953b4a4dce73318c457e4"; z_c0="2|1:0|10:1596979174|4:z_c0|92:Mi4xNDhPdkFnQUFBQUFBWUZpLW1idURFU1lBQUFCZ0FsVk41a1VkWUFBR0N4dXF4Y2lkdnJDZ2c3bmMtaFhZQ0JjT25B|5020e8ce44cadc7cc35f2ee7b5d1c3f30f85c212d5e4fac081894b11c05110b6"; KLBRSID=d6f775bb0765885473b0cba3a5fa9c12|1596979708|1596977420; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1596979708',
'User-Agent': 'Mozilla%d/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36'
% random.randint(55, 100),
}
r = requests.get(url, headers=headers)
html = etree.HTML(r.text) # 调用HTML类初始化,构造XPath解析对象
path = '//*[@id="TopstoryContent"]/div/div/div[2]/section/div[2]/a'
titles = html.xpath(path + '/h2/text()')
links = html.xpath(path + '/@href')
for i in range(10):
print(i + 1, links[i], titles[i], sep=" ")
3.发送邮件
要注意开启smtp服务
参考博客
代码
from_addr = '[email protected]'
password = 'XXX'
to_addr = '[email protected]'
smtp_server = 'smtp.qq.com'
# 邮件内容
msg = MIMEText(text, 'plain', 'utf-8')
msg['From'] = Header(from_addr)
msg['To'] = Header(to_addr)
msg['Subject'] = Header('知乎微博热门话题')
# 开启发信服务,这里使用的是加密传输
server = smtplib.SMTP_SSL(smtp_server)
server.connect(smtp_server, 465)
server.login(from_addr, password)
server.sendmail(from_addr, to_addr, msg.as_string())
# 关闭服务器
server.quit()
4. 完整代码
需要修改发件人和收件人
import requests
from lxml import etree
import random
import smtplib
from email.mime.text import MIMEText
from email.header import Header
def get_data(url, num):
# 解析格式与基础信息
path = ['//*[@id="TopstoryContent"]/div/div/div[2]/section/div[2]/a',
'//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a']
web_name = ["知乎热榜",
"微博热搜"]
pre = ['',
'https://s.weibo.com/']
get_title = ['/h2/text()',
'/text()']
get_link = ['/@href',
'/@href']
# 获取网页
headers = {
'cookie' : '_zap=2a9ae3ab-f2e0-40ff-8a2e-02429c9f0453; d_c0="AGBYvpm7gxGPTiIzHTJtlff00GVsElpFRn0=|1593678215"; _ga=GA1.2.646074918.1593678215; q_c1=a1321aa361ac4df2a0709bb3660b1f60|1596371586000|1596371586000; _gid=GA1.2.1339168512.1596893630; tst=h; tshl=; _xsrf=3woUaVZtwUGqsDKF39WzhwXpU4DZsUV3; SESSIONID=RvdKKA5NNC2mAzAPi145hK2I2IHUIp0Zz16MOt1aWLb; JOID=UloUB0kg0XEVGHmbLiThaxIUcxU-cKQQWFE6rWVskEB9XwHYffEkXU4YeJ0tDY26KUIJ-175v2eF9D1gw2yF8Yk=; osd=W1gdAE8p03gSHnCZJyPnYhAddBM3cq0XXlg4pGJqmUJ0WAfRf_gjW0cacZorBI-zLkQA-Vf-uW6H_Tpmym6M9o8=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1596977420,1596978055,1596978079,1596978130; capsion_ticket="2|1:0|10:1596979172|14:capsion_ticket|44:OWI2NWE3MTVhZDIxNDFiNGI5ZDliZTkzZTE5ZDA1Zjg=|4be161b423d84930ff865a122e22fff3d030d468f49953b4a4dce73318c457e4"; z_c0="2|1:0|10:1596979174|4:z_c0|92:Mi4xNDhPdkFnQUFBQUFBWUZpLW1idURFU1lBQUFCZ0FsVk41a1VkWUFBR0N4dXF4Y2lkdnJDZ2c3bmMtaFhZQ0JjT25B|5020e8ce44cadc7cc35f2ee7b5d1c3f30f85c212d5e4fac081894b11c05110b6"; KLBRSID=d6f775bb0765885473b0cba3a5fa9c12|1596979708|1596977420; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1596979708',
'User-Agent': 'Mozilla%d/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36' % random.randint(
55, 100),
}
r = requests.get(url, headers=headers)
# print(r.status_code)
html = etree.HTML(r.text) # 调用HTML类初始化,构造XPath解析对象
# 获取数据
titles = html.xpath(path[num] + get_title[num])
links = html.xpath(path[num] + get_link[num])
# num==1是微博,由于微博的会出现推荐的话题,这里将其舍去
if num == 1:
error = 'javascript:void(0);'
for j in range(20):
if links[j] == error:
del links[j]
del titles[j]
# 将前15个结果存到res里
res = web_name[num] + "\n"
for i in range(15):
res = res + str(i+1) + " " + titles[i] + "\n" + pre[num] + links[i] + "\n\n"
return res
def send_email(text):
# 初始信箱设置
from_addr = '[email protected]' # 发件人邮箱(需要开启smtp服务)
password = 'XXX' # 邮箱密钥
to_addr = '[email protected]' # 收件人邮箱
smtp_server = 'smtp.qq.com'
# 邮件内容
msg = MIMEText(text, 'plain', 'utf-8')
msg['From'] = Header(from_addr)
msg['To'] = Header(to_addr)
msg['Subject'] = Header('知乎微博热门话题')
# 开启发信服务,这里使用的是加密传输
server = smtplib.SMTP_SSL(smtp_server)
server.connect(smtp_server, 465)
server.login(from_addr, password)
server.sendmail(from_addr, to_addr, msg.as_string())
# 关闭服务器
server.quit()
# 爬取url
url = ['https://www.zhihu.com/hot',
'https://s.weibo.com/top/summary']
n = len(url)
res = ""
for i in range(n):
res = res + get_data(url[i], i) + "\n\n"
print(res)
# 发送邮件
send_email(res)