FaceNet-A Unified Embedding for Face Recognition and Clustering 论文解读
~简要介绍
FaceNet在LFW数据集上,准确率为0.9963,在YouTube Faces DB数据集上,准确率为0.9512。
FaceNet是一个通用的系统,可以用于人脸验证(是否是同一人?),识别(这个人是谁?)和聚类(寻找类似的人?)。FaceNet采用的方法是通过卷积神经网络学习将图像映射到欧几里得空间。空间距离直接和图片相似度相关:同一个人的不同图像在空间距离很小,不同人的图像在空间中有较大的距离。只要该映射确定下来,相关的人脸识别任务就变得很简单。
当前存在的基于深度神经网络的人脸识别模型使用了分类层(classification layer):中间层为人脸图像的向量映射,然后以分类层作为输出层。这类方法的弊端是不直接和效率低。
与当前方法不同,FaceNet直接使用基于triplets的LMNN(最大边界近邻分类)的loss函数训练神经网络,网络直接输出为128维度的向量空间。我们选取的triplets(三联子)包含两个匹配脸部缩略图和一个非匹配的脸部缩略图,loss函数目标是通过距离边界区分正负类,如图1-1所示。

triplet loss
triplet loss 的启发是传统loss函数趋向于将有一类特征的人脸图像映射到同一个空间。而triplet loss尝试将一个个体的人脸图像和其它人脸图像分开。
模型的目的是将人脸图像X embedding入d维度的欧几里得空间。在该向量空间内,我们希望保证单个个体的图像 和该个体的其它图像 距离近,与其它个体的图像 距离远。如图5-1所示:

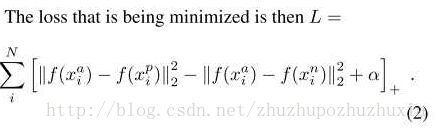
triplets筛选
triplets 的选择对模型的收敛非常重要。如公式1所示,对于,我们我们需要选择同一个体的不同图片,使;同时,还需要选择不同个体的图片,使得。在实际训练中,跨越所有训练样本来计算argmin和argmax是不现实的,还会由于错误标签图像导致训练收敛困难。实际训练中,有两种方法来进行筛选:
一,每隔n步,计算子集的argmin和argmax。
二,在线生成triplets,即在每个mini-batch中进行筛选positive/negative样本。
本文中,我们采用在线生成triplets的方法。我们选择了大样本的mini-batch(1800样本/batch)来增加每个batch的样本数量。每个mini-batch中,我们对单个个体选择40张人脸图片作为正样本,随机筛选其它人脸图片作为负样本。负样本选择不当也可能导致训练过早进入局部最小。为了避免,我们采用如下公式来帮助筛选负样本:![]()
深度卷积神经网络
采用adagrad优化器,使用随机梯度下降法训练CNN模型。在cpu集群上训练了1000-2000小时。边界值设定为0.2。
模型优点
模型对图像质量(像素值)不敏感,即使80*80像素的图片生成的结果也可以接受
作者测试了不同的embedding维度,结果如表5-3所示,发现128维度是最为合适的。
随着训练数据量的增加,准确率也随之增加。
FaceNet是一种直接将人脸图像embedding进入欧几里得空间的方法。该模型的优点是只需要对图片进行很少量的处理(只需要裁剪脸部区域,而不需要额外预处理,比如3d对齐等),即可作为模型输入。同时,该模型在数据集上准确率非常高。
待优化:
一,分析错误的样本,进一步提高识别精度,特别是增加模型在现实场景中的识别精度。
二,以该模型为基础,将其用于现实应用开发中。
三,减少模型大小,减少对cpu计算量的消耗,以及减少训练时间(作者在cpu集群上需要1000-2000小时的训练。)
~论文细节
- 三元组的目标函数并不是这篇论文首创,我在之前的一些Hash索引的论文中也见过相似的应用。可见,并不是所有的学习特征的模型都必须用softmax。用其他的效果也会好。
- 三元组比softmax的优势在于
- softmax不直接,(三元组直接优化距离),因而性能也不好。
- softmax产生的特征表示向量都很大,一般超过1000维。
- FaceNet并没有像DeepFace和DeepID那样需要对齐。
- FaceNet得到最终表示后不用像DeepID那样需要再训练模型进行分类,直接计算距离就好了,简单而有效。
- 论文并未探讨二元对的有效性,直接使用的三元对。
~代码细节
基于mtcnn和facenet的实时人脸检测与识别系统开发
采用opencv2实现从摄像头读取视频帧
对图片采用mtcnn方法,检测人脸;
采用预训练的facenet对检测的人脸进行embedding,embedding成128维度的特征;
对人脸embedding特征采用svm/knn进行分类,实现人脸识别;
opencv读取
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Display the resulting frame
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
mtcnn
对自然环境中光线,角度和人脸表情变化更具有鲁棒性,人脸检测效果更好;同时,内存消耗不大,可以实现实时人脸检测。
mtcnn检测出人脸后,对人脸进行剪切并resize为(96,96,3)作为facenet输入
#建立mtcnn人脸检测模型,加载参数
print('Creating networks and loading parameters')
gpu_memory_fraction=1.0
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = detect_face.create_mtcnn(sess, './davidsandberg_facenet-master/data/')
bounding_boxes, _ = detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
nrof_faces = bounding_boxes.shape[0]#人脸数目
print('找到人脸数目为:{}'.format(nrof_faces))
crop_faces=[]
for face_position in bounding_boxes:
face_position=face_position.astype(int)
print(face_position[0:4])
cv2.rectangle(img_color, (face_position[0], face_position[1]), (face_position[2], face_position[3]), (0, 255, 0), 2)
crop=img_color[face_position[1]:face_position[3],
face_position[0]:face_position[2],]
crop = cv2.resize(crop, (96, 96), interpolation=cv2.INTER_CUBIC )
print(crop.shape)
crop_faces.append(crop)
plt.imshow(crop)
plt.show()
plt.imshow(img_color)
plt.show()
facenet embedding
Facenet是谷歌研发的人脸识别系统,该系统是基于百万级人脸数据训练的深度卷积神经网络,可以将人脸图像embedding(映射)成128维度的特征向量。以该向量为特征,采用knn或者svm等机器学习方法实现人脸识别。Facenet在LFW数据集上识别准确率为0.9963
恢复预训练facenet模型和使用模型进行embedding
#建立facenet embedding模型
print('建立facenet embedding模型')
tf.Graph().as_default()
sess = tf.Session()
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
image_size,
image_size, 3), name='input')
phase_train_placeholder = tf.placeholder(tf.bool, name='phase_train')
embeddings = network.inference(images_placeholder, pool_type,
use_lrn,
1.0,
phase_train=phase_train_placeholder)
ema = tf.train.ExponentialMovingAverage(1.0)
saver = tf.train.Saver(ema.variables_to_restore())
#ckpt = tf.train.get_checkpoint_state(os.path.expanduser(model_dir))
#saver.restore(sess, ckpt.model_checkpoint_path)
model_checkpoint_path='./model-20160506.ckpt-500000'
#ckpt = tf.train.get_checkpoint_state(os.path.expanduser(model_dir))
#model_checkpoint_path='model-20160506.ckpt-500000'
#saver.restore(sess, ckpt.model_checkpoint_path)
saver.restore(sess, model_checkpoint_path)
print('facenet embedding模型建立完毕')
######省略部分代码
emb_data = sess.run([embeddings],
feed_dict={images_placeholder: face_data, phase_train_placeholder: False })[0]
人脸识别
对人脸进行embedding后,得到128维度的特征向量 。以该特征向量为基础,可以采用任何机器学习的方法进行分类和识别。本文中,选取了knn(k-NearestNeighbor)方法(你可以换其它任何分类方法,比如svm或者神经网络方法等)。本文中,采用了sklearn库实现knn模型的训练和预测。
首先,需要训练分类器。训练数据为:类别1:目标人脸1;类别2:目标人脸2…,类别n:其他人脸。本代码中,类别1:我的人脸数据(经过人脸检测和embedding,共98个样本);类别2:其它人脸(采用lfw数据集随机选取的人脸数据,共69个样本)。训练代码如下:
#训练KNN分类
from sklearn import metrics
from sklearn.externals import joblib
X_train, X_test, y_train, y_test = train_test_split(X, train_y, test_size=.3, random_state=42)
# KNN Classifier
def knn_classifier(train_x, train_y):
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(train_x, train_y)
return model
classifiers = knn_classifier
model = classifiers(X_train,y_train)
predict = model.predict(X_test)
accuracy = metrics.accuracy_score(y_test, predict)
print ('accuracy: %.2f%%' % (100 * accuracy) )
#保存模型
joblib.dump(model, 'knn.model')
训练后的分类器即可对人脸进行识别,代码如下:
model = joblib.load('knn.model')
predict = model.predict(X_test)
print ('识别结果为:{}'.format(predict))
待优化
mtcnn人脸检测方法精确度很高,但是依然存在一些问题。
一,该方法无法识别倾斜度大于45度的人脸和侧面的人脸。如图6-2所示,当倾斜度大于45度后,系统无法检测出人脸。该问题原因可能是mtcnn网络训练数据中没有大倾斜度的人脸照片。解决的方法可以有两种:(1)对训练照片进行旋转,在但前mtcnn网络的基础上进行finetune;(2)在视频帧读取后,旋转不同角度后,分别传入mtcnn进行人脸检测。前一种方法需要处理大量的人脸数据;后一种方法会影响实时检测的速度。
二,mtcnn人脸检测方法还存在另外的小问题:有时可能会被汪星人欺骗(好吧,汪星人的脸也是脸,该方法很强大,哦也!请忽略)。该问题不影响实际应用。
同时,当前系统的识别分类器是基于仅仅167个正负样本训练的knn分类器,测试准确率仅为94%左右。进一步改进可以考虑:(1)采集更多的类别与数量的训练样本训练分类器,实现多个类别的人脸识别; (2)选择其它分类方法(svm/神经网络等)。(3)将分类器训练部分集成,实现实时训练与识别。
~相关技术
face++,DeepID3,FaceNet
人脸检测方法有许多,比如opencv自带的人脸Haar特征分类器和dlib人脸检测方法等
对于opencv的人脸检测方法,有点是简单,快速;存在的问题是人脸检测效果不好。如图3-1所示,正面/垂直/光线较好的人脸,该方法可以检测出来,而侧面/歪斜/光线不好的人脸,无法检测。因此,该方法不适合现场应用。对于dlib人脸检测方法 ,效果好于opencv的方法,但是检测力度也难以达到现场应用标准。
1,face++(0.9950 );2,DeepFace(0.9735 );3,FR+FCN(0.9645 );4,DeepID(0.9745 );5,FaceNet(0.9963 );6, baidu的方法(0.9977 );7,pose+shape+expression augmentation(0.9807);8,CNN-3DMM estimation(0.9235 ,准确率没那么高,但是值得参考)。