Tmall爬虫实战记录
Tmall爬虫工作笔记
我们的这个爬虫功能是爬取店铺所有商品。
一、流程分析
- 输入搜索店铺的名称抓取搜索结果(包含了一些店铺推荐商品)
- 获取店铺id(通过推荐商品来获取)
- 获取店铺商品总页数
- 获取店铺每页的产品url
- 获取产品详情数据
- 获取商品评论
二、代码部分
1.店铺抓取
1.1目标url分析
search_url = 'https://list.tmall.com/search_product.htm?q=三只松鼠&type=p&spm=a220m.8599659.a2227oh.d100&from=mallfp..m_1_searchbutton&searchType=default&style=w'
分析:注意我们的红色部分是我们需要输入的店铺名称。
1.2抓取过程
(1)在谷歌浏览器我们登录我们的tmall,淘宝
(2)打开Tmall的店铺搜索界面(https://list.tmall.com/search_product.htm?q=kindle&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest)

(3) 自行打开抓包工具进行分析(在此不多赘述,下面直接说结果)
(4)店铺的搜索结果在当前url中包含,所以我们就选择这个url进行爬取
(5)构造请求包
这一步是为今后爬取其他页面奠定基础,所以需要仔细设计请求包。
class request_url(object):
"""请求网页,以及反爬处理"""
def __init__(self,url):
self.url = url我们编写一个类用来处理在请求页面的过程中的各种问题。接下里我们构造请求头。(这里我犯了一个错误,用的网页版tmall来分析,用的移动端的请求头,当headers为pc版时,下面的代码会提取不到信息。)
import random
class request_url(object):
"""请求网页,以及反爬处理"""
def __init__(self, url):
self.url = url
def construct_headers(self):
agent = ['Dalvik/2.1.0 (Linux; U; Android 10; Redmi K30 5G MIUI/V11.0.11.0.QGICNXM)',
'TBAndroid/Native',
'Mozilla/5.0 (Linux; Android 7.1.1; MI 6 Build/NMF26X; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/6.2 TBS/043807 Mobile Safari/537.36 MicroMessenger/6.6.1.1220(0x26060135) NetType/WIFI Language/zh_CN',
]
with open('cookie/search_cookie.txt', 'r') as f:
cookie = f.readline()
self.headers = {
'user-agent': random.choice(agent),
'cookie': cookie,
'Connection': 'close',
# 'referer': 'https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.1.48c37111IiH0Ml&id=578004651332&skuId=4180113216736&areaId=610100&user_id=2099020602&cat_id=50094904&is_b=1&rn=246062bfaa1943ec6b72afcd1ff3ded8',
}较上一步我们构造construct_headers方法来构造请求头。
| agent | 存有我们的各种请求头,自己可以在网上搜一些添加进去 |
| cookie | cookie是我在当前项目的文件夹下创建了一个cookie文件夹来存放search_cookie |
接下来写请求方法。
import requests
import random
from lxml import etree
from fake_useragent import UserAgent
import time
class request_url(object):
"""请求网页,以及反爬处理"""
def __init__(self, url):
self.url = url
def construct_headers(self):
agent = ['Dalvik/2.1.0 (Linux; U; Android 10; Redmi K30 5G MIUI/V11.0.11.0.QGICNXM)',
'TBAndroid/Native',
'Mozilla/5.0 (Linux; Android 7.1.1; MI 6 Build/NMF26X; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/6.2 TBS/043807 Mobile Safari/537.36 MicroMessenger/6.6.1.1220(0x26060135) NetType/WIFI Language/zh_CN',
]
with open('cookie/search_cookie.txt', 'r') as f:
cookie = f.readline()
self.headers = {
'user-agent': random.choice(agent), # 随机选择一个请求头部信息
'cookie': cookie,
'Connection': 'close',
# 'referer': 'https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.1.48c37111IiH0Ml&id=578004651332&skuId=4180113216736&areaId=610100&user_id=2099020602&cat_id=50094904&is_b=1&rn=246062bfaa1943ec6b72afcd1ff3ded8',
}
def request(self):
self.construct_headers()
response = requests.get(self.url,headers=self.headers)
xml = etree.HTML(response.text) # 转换成xml,为了使用xpath提取数据
return response.text,xml
def mainRquest(url):
RU = request_url(url)
response,xml = RU.request()
return response,xml至此我们的请求包初步构造完成,然后我们将这个python文件命名为Elements.py
(6)店铺搜索结果爬取
首先创建一个名为Tmall.py的文件。
我们在这个文件中还是构造一个类来爬取Tmall。
from Elements import mainRquest
class Tmall():
def __init__(self):
self.search = input('请输入店铺名:')
self.url = 'https://list.tmall.com/search_product.htm?q=%s&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'%(self.search)
# 1.0搜索店铺
def shop_search(self):
response,xml = mainRquest(self.url)
print(response)
def main():
tmall = Tmall()
tmall.shop_search()
if __name__ == '__main__':
main()执行结果:

下一步我们利用xpath,或者正则表达式进行内容筛选。
from Elements import mainRquest
class Tmall():
def __init__(self):
self.search = input('请输入店铺名:')
self.url = 'https://list.tmall.com/search_product.htm?q=%s&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'%(self.search)
# 1.0搜索店铺
def shop_search(self):
response,xml = mainRquest(self.url)
title = xml.xpath('//div[@class="shop-title"]/label/text()')
print(title)
def main():
tmall = Tmall()
tmall.shop_search()
if __name__ == '__main__':
main()执行结果:
['kindle官方旗舰店', '天猫国际进口超市', '锦读数码专营店', '苏宁易购官方旗舰店', '天佑润泽数码专营店', 'boox曼尼金专卖店', 'kindle海江通专卖店', '洋桃海外旗舰店', '志赟数码专营店', '天猫国际小酒馆'] (7)店铺产品基本信息抓取
经过小编的分析,我们会发现店铺产品的链接就在:
![]()
我们点击这个url就到达:
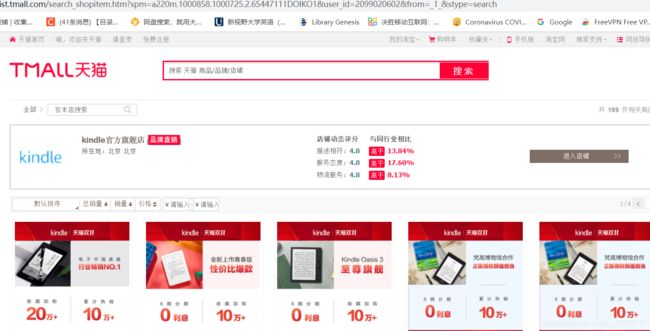
把网页往下滑,会有第几页,我们紧接着点击第几页,便可以进行翻页,然后我们观察网址的变化:
https://list.tmall.com/search_shopitem.htm?spm=a220m.1000862.0.0.6135657ffcj9sU&s=60&style=sg&sort=s&user_id=2099020602&from=_1_&stype=search#grid-column # 第二页
https://list.tmall.com/search_shopitem.htm?spm=a220m.1000862.0.0.3822657f0J7RJx&s=120&style=sg&sort=s&user_id=2099020602&from=_1_&stype=search#grid-column # 第三页
分析url我们发现,我们可以通过构造url来爬取店铺所有的产品。那接下来让我们来写代码吧!
第一步在上一个店铺搜索结果获取中,我们需要提取出user_id。
# 1.0搜索店铺
def shop_search(self):
response,xml = mainRquest(self.url)
title = xml.xpath('//div[@class="shop-title"]/label/text()')
user_id = re.findall('user_id=(\d+)',response)
print(user_id)运行结果:
['2099020602', '2549841410', '3424411379', '2616970884', '3322458767', '3173040572', '2041560994', '2206736426581', '2838273504', '2200657974488']我们接下里要把这些爬下来的数据先创建一个变量存起来。(为了避免每次都要输入,小编在举例中将q=kindle写死)
from Elements import mainRquest
import re
class Tmall():
def __init__(self):
# self.search = input('请输入店铺名:')
# self.url = 'https://list.tmall.com/search_product.htm?q=%s&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'%(self.search)
self.url = 'https://list.tmall.com/search_product.htm?q=kindle&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'
self.shop_dict = {} # 用于存储店铺的信息
# 1.0搜索店铺
def shop_search(self):
response, xml = mainRquest(self.url)
title = xml.xpath('//div[@class="shop-title"]/label/text()')
user_id = re.findall('user_id=(\d+)', response)
assert (len(title) == len(user_id) and len(title) != []) # 确保我们的提取到了数据,若没有将会报错
self.shop_dict['shopTitle'] = title
self.shop_dict['userId'] = user_id
print('\r1.0店铺搜索结果处理完成!', end='')
def main():
tmall = Tmall()
tmall.shop_search()
if __name__ == '__main__':
main()
2.店铺内的商品抓取
在上面我们得到了店铺的userid,以及店铺的名称。接下来我们要利用userid来抓取店铺内的商品。
先来分析一下url:
https://list.tmall.com/search_shopitem.htm?spm=a220m.1000862.0.0.48813ec6huCom4&s=60&style=sg&sort=s&user_id=765321201&from=_1_&stype=search#grid-column| spm | 作用不明,可有可无 |
| s | 当前页面展示的第一个商品是店铺内第几个商品,用于翻页,间隔60 |
| sort | 排序,s是默认排序 |
其他暂且不分析,等后面用到再说,接下来构造店铺商品url。
from Elements import mainRquest
import re
class Tmall():
def __init__(self):
# self.search = input('请输入店铺名:')
# self.url = 'https://list.tmall.com/search_product.htm?q=%s&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'%(self.search)
self.url = 'https://list.tmall.com/search_product.htm?q=kindle&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'
self.shop_dict = {} # 用于存储店铺的信息
# 1.0搜索店铺
def shop_search(self):
response, xml = mainRquest(self.url)
title = xml.xpath('//div[@class="shop-title"]/label/text()')
user_id = re.findall('user_id=(\d+)', response)
assert (len(title) == len(user_id) and len(title) != []) # 确保我们的提取到了数据,若没有将会报错
self.shop_dict['shopTitle'] = title
self.shop_dict['userId'] = user_id
print('\r1.0店铺搜索结果处理完成!', end='')
# 2.0抓取店铺所有产品基本信息。
def all_product(self):
for id in self.shop_dict['userId']:
url = 'https://list.tmall.com/search_shopitem.htm?' \
'spm=a220m.1000862.0.0.48813ec6huCom4' \
'&s=0&style=sg&sort=s&user_id=%s&from=_1_&stype=search#grid-column'%(id)
def main():
tmall = Tmall()
tmall.shop_search()
if __name__ == '__main__':
main()
经过我多次实验发现在访问店铺内所有商品的信息时容易出现反爬,每次cookie会发生变化,因此我使用了pyautogui来打开浏览器访问所有产品页面,利用fiddler抓包保存到本地,在进行一次提取。
fiddler下载地址:链接:https://pan.baidu.com/s/1PqAOVO4Vwujf8loT37z4Tg
提取码:x0zm
fiddler抓包的配置教程请自行搜索,很多的,实在不会请私信我。
请在fiddler文件所在目录创建一个response.txt文件
操作截图:
下一步打开fiddler,打开FiddlerScript,转到beforeresponse,添加如下代码。
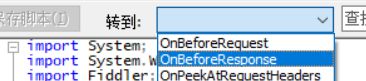

if (oSession.fullUrl.Contains("tmall.com/search_shopitem"))
{
oSession.utilDecodeResponse();
var fso;
var file;
fso = new ActiveXObject("Scripting.FileSystemObject");
//文件保存路径,可自定义
file = fso.OpenTextFile("response.txt",8 ,true, true);
file.writeLine(oSession.GetResponseBodyAsString());
file.close();
}记得保存脚本。
我们打开一个网站测试一下:https://list.tmall.com/search_shopitem.htm?spm=a220m.1000862.0.0.48813ec6huCom4&s=0&style=sg&sort=s&user_id=2099020602&from=_1_&stype=search#grid-column
记得登录你的tmall账号
测试后你的response.txt中会保存有:

在这里我们完成了对店铺所有产品的数据抓取,接下来进行提取:
(1)创建一个functions.py用于存储我们自定义的包。
(2)在functions.py中创建自动打开tmall店铺所商品的函数GetAllProduct()。
def GetAllProduct(url):
import pyautogui
import time
# 在运行本程序之前打开fiddler(配置完成的)
time.sleep(2) # 因为程序启动需要时间,在此等待2秒,防止出错。
x, y = 710, 1070 # 这是我的谷歌浏览器的在屏幕上的位置。
pyautogui.moveTo(x, y)
time.sleep(1)
pyautogui.click() # 左击
time.sleep(1)
x, y = 700, 70 # 这是谷歌浏览器的网址输入栏的位置,每台电脑略有不同,请自行测试。
pyautogui.moveTo(x + 100, y)
pyautogui.click()
time.sleep(1)
pyautogui.write(url, interval=0.01) # 在地址栏中输入url,0.01是输入速度
pyautogui.press('enter') # 按回车
time.sleep(5) # 根据自己的网速自行调节速度
# 切换回程序运行界面
pyautogui.keyDown('alt')
pyautogui.press('tab')
pyautogui.keyUp('alt')(3)response.txt读取与提取,创建函数GetResponseHtml()。
# url = 'https://list.tmall.com/search_shopitem.htm?spm=a220m.1000862.0.0.48813ec6huCom4&s=0&style=sg&sort=s&user_id=2099020602&from=_1_&stype=search#grid-column'
def GetAllProduct(url):
import pyautogui
import time
# 在运行本程序之前打开fiddler(配置完成的)
time.sleep(2) # 因为程序启动需要时间,在此等待2秒,防止出错。
x, y = 710, 1070 # 这是我的谷歌浏览器的在屏幕上的位置。
pyautogui.moveTo(x, y)
time.sleep(1)
pyautogui.click() # 左击
time.sleep(1)
x, y = 700, 70 # 这是谷歌浏览器的网址输入栏的位置,每台电脑略有不同,请自行测试。
pyautogui.moveTo(x + 100, y)
pyautogui.click()
time.sleep(1)
pyautogui.write(url, interval=0.01) # 在地址栏中输入url,0.01是输入速度
pyautogui.press('enter') # 按回车
time.sleep(5) # 根据自己的网速自行调节速度
# 切换回程序运行界面
pyautogui.keyDown('alt')
pyautogui.press('tab')
pyautogui.keyUp('alt')
# 将保存的数据读取并处理
def GetResponseHtml():
from lxml import etree
def check_charset(file_path):
# 此函数有用于防止数据编码出错,小编在这入坑几个小时
import chardet
with open(file_path, "rb") as f:
data = f.read(4)
charset = chardet.detect(data)['encoding']
return charset
your_path = r'D:\编程工具大全\独家汉化Fiddler5.0.20182\Fiddler5.0.20182\response.txt' # response.txt的路径
with open(your_path, 'r+', encoding=check_charset(your_path)) as f:
data = f.read()
html = etree.HTML(data) # 转换成html
with open('data/response.txt', 'a+') as q: # 这是我对抓取到的response.txt进行一个备份,可有可无
q.write(data)
f.truncate(0) # 清除response.txt中的内容
return data, html
(4)打开Tmall.py,创建方法self.all_product(),利用正则、xpath提取数据。
from Elements import mainRquest
from functions import GetAllProduct
from functions import GetResponseHtml
import re
import time
class Tmall():
def __init__(self):
# self.search = input('请输入店铺名:')
# self.url = 'https://list.tmall.com/search_product.htm?q=%s&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'%(self.search)
self.url = 'https://list.tmall.com/search_product.htm?q=手机&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'
self.shop_dict = {} # 用于存储店铺的信息
self.product_list = []
# 1.0搜索店铺
def shop_search(self):
response, xml = mainRquest(self.url)
title = xml.xpath('//div[@class="shop-title"]/label/text()')
user_id = re.findall('user_id=(\d+)', response)
assert (len(title) == len(user_id) and len(title) != []) # 确保我们的提取到了数据,若没有将会报错
self.shop_dict['shopTitle'] = title
self.shop_dict['userId'] = user_id
print('\r1.0店铺搜索结果处理完成!', end='')
# 2.0抓取店铺所有产品基本信息。
def all_product(self):
for id in self.shop_dict['userId']: # 店铺所有产品url构造
url = 'https://list.tmall.com/search_shopitem.htm?' \
'spm=a220m.1000862.0.0.48813ec6huCom4' \
'&s=0&style=sg&sort=s&user_id=%s&from=_1_&stype=search#grid-column' % (id)
GetAllProduct(url) # 自动打开构造的地址,
response, html = GetResponseHtml()
self.price = re.findall('¥(.*?)', response)
self.Msell = re.findall('月成交(\d+)笔', response)
self.product_title = html.xpath('//p[@class="productTitle"]/a/@title')
self.product_url = html.xpath('//p[@class="productTitle"]/a/@href')
if self.price == []:
print(response)
else:
print(self.product_title)
print(self.price)
print(self.Msell)
print(self.product_url)
time.sleep(20) # 用于测试,防止运行过快,后面会删掉。
def main():
tmall = Tmall()
tmall.shop_search()
tmall.all_product()
if __name__ == '__main__':
main()
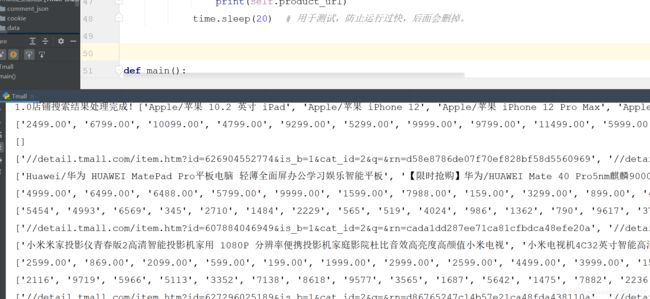
接下来要做的是爬取商品详情页面的信息。
(1)在cookie文件夹下面创建一个product_cookie.txt的文件;
(2)定义一个新的方法get_product_imformation();
(3)构造url,看代码。
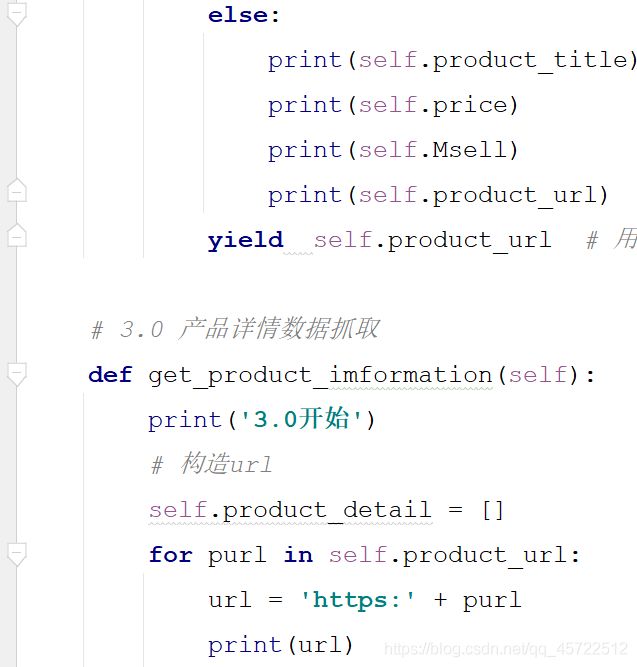
(4)请求,提取信息。
from Elements import mainRquest
from functions import GetAllProduct
from functions import GetResponseHtml,Replace,Compound
import re
import time
class Tmall():
def __init__(self):
# self.search = input('请输入店铺名:')
# self.url = 'https://list.tmall.com/search_product.htm?q=%s&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'%(self.search)
self.url = 'https://list.tmall.com/search_product.htm?q=手机&type=p&style=w&spm=a220m.1000858.a2227oh.d100&xl=kindle_2&from=.list.pc_2_suggest'
self.shop_dict = {} # 用于存储店铺的信息
self.product_list = []
# 1.0搜索店铺
def shop_search(self):
response, xml = mainRquest(self.url)
title = xml.xpath('//div[@class="shop-title"]/label/text()')
user_id = re.findall('user_id=(\d+)', response)
assert (len(title) == len(user_id) and len(title) != []) # 确保我们的提取到了数据,若没有将会报错
self.shop_dict['shopTitle'] = title
self.shop_dict['userId'] = user_id
print('\r1.0店铺搜索结果处理完成!', end='')
# 2.0抓取店铺所有产品基本信息。
def all_product(self):
print('2.0开始')
for id in self.shop_dict['userId']: # 店铺所有产品url构造
url = 'https://list.tmall.com/search_shopitem.htm?' \
'spm=a220m.1000862.0.0.48813ec6huCom4' \
'&s=0&style=sg&sort=s&user_id=%s&from=_1_&stype=search#grid-column' % (id)
GetAllProduct(url) # 自动打开构造的地址,
response, html = GetResponseHtml()
self.price = re.findall('¥(.*?)', response) # 价格
self.Msell = re.findall('月成交(\d+)笔', response) # 月销量
self.product_title = html.xpath('//p[@class="productTitle"]/a/@title') # 产品名称
self.product_url = html.xpath('//p[@class="productTitle"]/a/@href') # 产品链接
if self.price == []:
print(response)
else:
print(self.product_title)
print(self.price)
print(self.Msell)
print(self.product_url)
yield
# 3.0 产品详情数据抓取
def get_product_imformation(self):
print('3.0开始')
# 构造url
self.product_detail = []
for purl in self.product_url:
url = 'https:' + purl
print(url)
# 请求,下面的代码是我自己写的,你们可以根据需求自己写提取式子,
response,html = mainRquest(url)
self.brand = re.findall('li id="J_attrBrandName" title=" (.*?)">',response)
self.para = html.xpath('//ul[@id="J_AttrUL"]/li/text()')
specification = html.xpath('//table[@class="tm-tableAttr"]/tbody/tr/th/text()')
stitle = html.xpath('//table[@class="tm-tableAttr"]/tbody/tr[@class="tm-tableAttrSub"]/th/text()')
sanswer = html.xpath('//table[@class="tm-tableAttr"]/tbody/tr/td/text()')
if specification != []:
self.sparadict = Compound(specification,sanswer,stitle)
time.sleep(10)
def main():
tmall = Tmall()
tmall.shop_search()
for i in tmall.all_product():
tmall.get_product_imformation()
if __name__ == '__main__':
main()
(5)过滑块更新cookie。