第十四课.随机森林
目录
- 算法流程
-
- 随机森林的生成
- 随机森林的预测
- 算法总结
-
- 随机森林的优点
- 随机森林的缺点
- 基于sklearn的随机森林
-
- 参数
- 实例方法
- 实例属性
- 实验:使用随机森林评估特征重要性
算法流程
随机森林的个体学习器为决策树(决策树回顾第十一课),并且在 Bagging(回顾第十三课) 的基础上增加了随机特征选择
随机森林的生成
- 1.输入训练数据 D D D,样本个数为 m m m ,待学习的决策树数量为 T T T;
- 2.对于 t = 1 , 2 , . . . , T t = 1,2,...,T t=1,2,...,T,从 D D D 中有放回地采样 m m m 次,每次随机抽取一个样本,得到样本子集 D t D_{t} Dt;
- 3.使用 D t D_{t} Dt 生成决策树 t t t 。在生成决策树 t t t 的过程中,从当前结点的特征候选集中随机选择 k k k 个特征进行最优特征的选择。
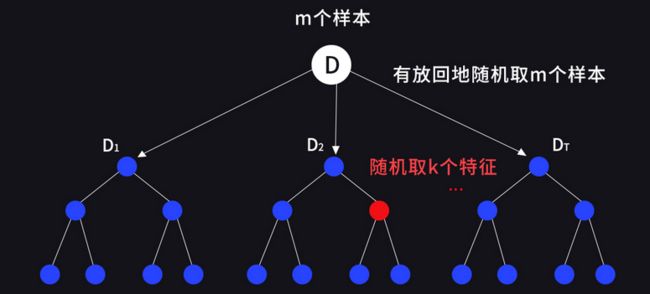
上述过程体现了两个随机性:随机选择样本集和随机选择特征集,生成的 T T T 个决策树通过特定的结合策略构成随机森林。
随机森林的预测
若是分类任务,则输出 T T T 个决策树中多数表决的类别;若是回归任务,则输出 T T T 个决策树预测结果的均值。例如,使用随机森林进行二分类的过程如下:
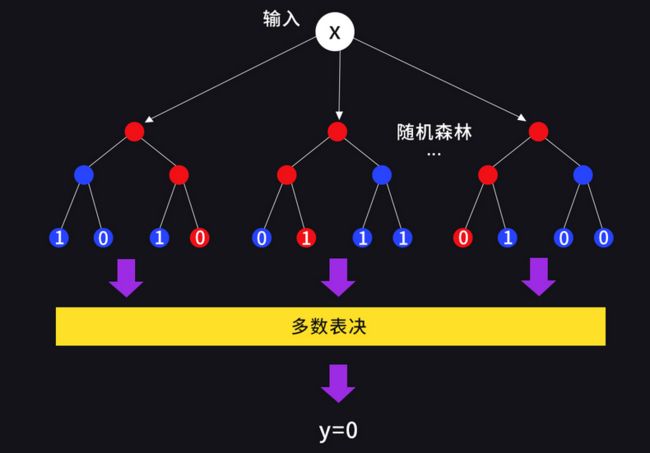
输入为样本的特征向量 X X X,随机森林中的每个决策树给出自己的分类结果,集成模块使用多数表决的方法判定最终的分类结果为 y = 0 y = 0 y=0
算法总结
随机森林的优点
-
随机森林的两个随机性有利于增大个体学习器之间的差异,增强模型的泛化性能。
-
由于随机森林的决策树是从一个特征子集中进行特征选择,所以训练效率要优于 Bagging。
-
相比 Boosting 类算法,随机森林实现简单,决策树之间相互独立,可以并行训练。
-
由于存在特征子集的随机选择,随机森林可以处理特征维度较高和部分特征缺失的情况。
-
随机森林可以评估特征的重要性,随机森林得到的特征重要性由各决策树生成时,通过各决策树的特征信息增益平均得到。
随机森林的缺点
-
在某些噪音比较大的样本集上,随机森林容易陷入过拟合。
-
在数据量较小、特征较少的数据集上预测效果不是很好。
基于sklearn的随机森林
基于 sklearn 中已经有相应的封装,本次不再像之前一样重复模型实现,下面是利用随机森林进行乳腺癌诊断的案例;
加载包和模块
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
加载数据集,训练,验证:
# 导入乳腺癌数据集
x,y = load_breast_cancer(return_X_y=True)
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)
# 实例化对象
rf = RandomForestClassifier(n_estimators=8, criterion='gini',max_depth=None, n_jobs=-1)
# 根据训练数据建立随机森林
rf = rf.fit(x_train, y_train)
# 模型预测
y_pred = rf.predict(x_test)
# 模型评估:计算准确率
accuracy = rf.score(x_test, y_test)
accuracy
# 0.9298245614035088
参数
随机森林分类算法被封装在sklearn.ensemble.RandomForestClassifier这个类中。在实例化对象时需要传入一些随机森林算法相关的参数,所以需要了解一下其中的几个主要参数含义:
- n_estimators
随机森林中决策树的数量,默认值为100 - criterion
决策树的分裂依据,可选值有基尼系数和信息熵:{“gini”, “entropy”},默认值为基尼系数 - max_depth
树的最大深度,默认值为 None,决策树分裂直到叶子结点只有一类样本或小于设定的样本数 - n_jobs
并行计算使用的 CPU 个数,默认值为 None,使用 1 个处理器;取-1表示使用所有处理器
实例方法
RandomForestClassifier 这个类中封装了一些有关模型训练、模型预测和模型评估的实例方法,可以通过实例化的对象来调用这些方法:
- fit(X,y)
从训练集(X,y)中建立一个随机森林,X是形状为(n_samples, n_features)的二维数组,y 是形状为(n_samples, )的一维数组 - predict(X)
返回样本数据 X 的类别标记,X是形状为(n_samples, n_features)的二维数组 - score(X, y)
给定样本数据 X 和标签 y 时,返回随机森林分类预测的准确率 - apply(X)
返回样本数据 X 分别归属于每颗决策树的叶子结点索引,X是形状为(n_samples, n_features)的二维数组,例如,只有一条测试样本数据时的输出如下:
x_test[1].shape # (30,)
# 测试样本分别归属于每颗决策树的叶子结点索引
rf.apply(x_test[1].reshape(1,-1))
# array([[31, 22, 19, 14, 29, 15, 20, 32]])
实例属性
类似地,通过随机森林分类算法类的实例化对象还可以访问其实例属性:
# 样本类别,样本类别数量,样本特征数量
rf.classes_,rf.n_classes_,rf.n_features_
# (array([0, 1]), 2, 30)
实验:使用随机森林评估特征重要性
实验基于 UCI 葡萄酒数据,使用随机森林进行特征重要性分析,这些数据是对意大利同一地区种植的三种不同品种葡萄酒的化学分析结果,分析确定了三种葡萄酒中13种成分的含量,数据的第一列是葡萄酒的类别。数据保存在个人资源处;
导入数据集:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
df = pd.read_csv('wine.data', header = None)
df.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
df.head()

划分训练集和测试集:
# 获取样本特征和标记值
x, y = df.iloc[:, 1:].values, df.iloc[:, 0].values
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
模型训练与评估:
# 实例化对象
RF = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
# 建立随机森林
RF = RF.fit(x_train, y_train)
# 计算测试集上的准确率
accuracy = RF.score(x_test, y_test)
accuracy
# 0.9814814814814815
特征重要性排序:
# 特征名列表
features = df.columns[1:]
# 特征重要性
importances = RF.feature_importances_
# 存储特征重要性降序排序的列表,每条记录的格式为:(feature,importance)
# sorted回顾Python笔记本第五课
sorted_feature_importances=sorted([(features[i],importances[i]) for i in range(13)],key=lambda x:x[1],reverse=True)
sorted_feature_importances
排序结果:
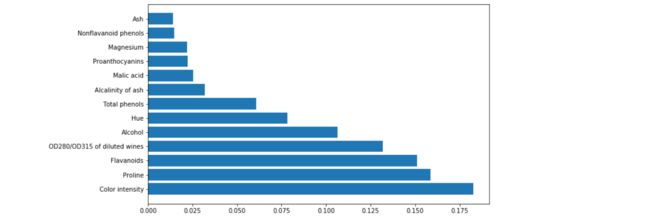
[('Color intensity', 0.18248261633081447),
('Proline', 0.15860977439208598),
('Flavanoids', 0.15094794797803848),
('OD280/OD315 of diluted wines', 0.13198679742764774),
('Alcohol', 0.1065890612251934),
('Hue', 0.07824278809689261),
('Total phenols', 0.060717598651490616),
('Alcalinity of ash', 0.032033191209174174),
('Malic acid', 0.025399678325383392),
('Proanthocyanins', 0.022351122470445416),
('Magnesium', 0.02207807404077184),
('Nonflavanoid phenols', 0.014645160876579336),
('Ash', 0.013916188975481122)]
特征重要性可视化:
# 按特征重要性降序排序的特征名
# map回顾Python笔记本第五课
features = list(map(lambda x:x[0],sorted_feature_importances))
# 特征重要性降序排序的取值
importances = list(map(lambda x:x[1],sorted_feature_importances))
# 设置画布大小
plt.figure(figsize=(10,6))
# 使用matplotlib.pyplot中的barh方法绘制特征重要性的条形图
plt.barh(features,importances)
plt.show()