爬虫学习笔记13-scrapy模拟登陆
1、之前用过的模拟登陆方法
(1)request模块模拟登陆
①直接携带cookies请求页面
②找url地址,发送post(携带登陆用户账号和密码)请求存储cookie
(2)selenium模拟登陆
找到对应的input标签,输入文本点击登陆
2、scrapy框架模拟登陆
(1)直接携带cookies(需要先登录上GitHub)
1)适用场景
①cookie过期时间很长,常见于一些不规范的网站
②能在cookie过期之前把所有的数据拿到
③配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
2)实现思路
①重构scrapy的starte_rquests方法,手动添加cookies
②在setting中设置ROBOTS协议、USER_AGENT
3)案例分析:携带cookies模拟登陆GitHub
①找到cookies参数,在YourProfile中找
_octo=GH1.1.1188014201.1599361351; _device_id=ddcddf64a4465debb4c6982673560539; logged_in=yes; dotcom_user=Amen-bang; ……WO7W9qfLFSLIn9BgYEb7vtKBw0W6FO7Xgf3w%3D%3D--HHJYa4uQF0Hebo4X--RJophzYTyzzrWghWlH6gCg%3D%3D
②重构starte_rquests方法,携带cookie登陆GitHub
import scrapy
class Git1Spider(scrapy.Spider):
name = 'git1'
# 2. 检查域名
allowed_domains = ['github.com']
# 1. 修改起始url
start_urls = ['https://github.com/Amen-bang']
def start_requests(self):
url = self.start_urls[0]
temp ='_octo=GH1.1.1188014201.1599361351; _device_id=ddcddf64a4465debb4c6982673560539; ……7W9qfLFSLIn9BgYEb7vtKBw0W6FO7Xgf3w%3D%3D--HHJYa4uQF0Hebo4X--RJophzYTyzzrWghWlH6gCg%3D%3D'
cookies = {
data.split('=')[0]:data.split('=')[-1]for data in temp.split('; ')}
yield scrapy.Request(
url=url,
cookies=cookies
)
# 3. 在parse方法中实现爬取逻辑
def parse(self, response):
print(response.xpath('/html/head/title/text()').extract_first())
③在setting中设置ROBOTS协议、USER_AGENT
#USER_AGENT = 'github (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
# Obey robots.txt rules
#ROBOTSTXT_OBEY = True
![]()
(2)scrapy.Request发送post请求
1)scrapy.FormRequest(): 能够发送表单和ajax请求,参考阅读 https://www.jb51.net/article/146769.htm
2)实现思路
①找到post的url地址:点击登录按钮进行抓包,然后定位url地址为https://github.com/session
②找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
③能否登录成功:通过请求个人主页,观察是否包含用户名
3)案例分析:发送post请求模拟登陆GitHub
①从登陆页面进行登陆抓取响应,解析post数据
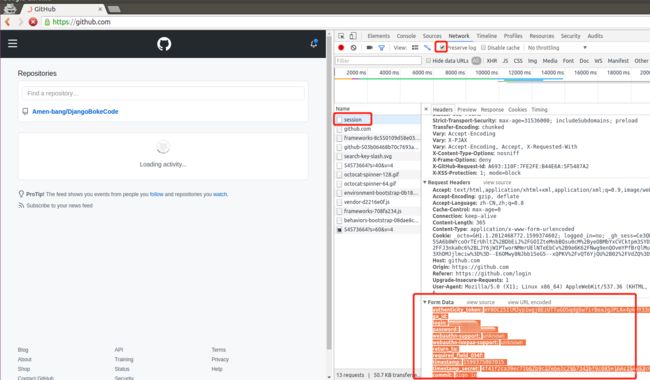
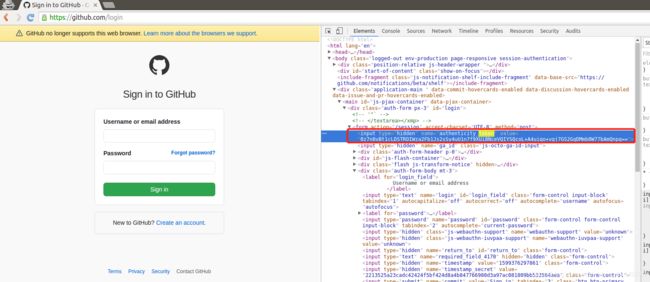
②找到变化的authenticity_token值,定位到他的位置获取每次的值
②构建一个post请求字典,发送post请求模拟登陆
import scrapy
class Git2Spider(scrapy.Spider):
name = 'git2'
allowed_domains = ['github.com']
start_urls = ['http://github.com/login']
def parse(self, response):
# 从登陆页面获取响应中的post请求
token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
post_data = {
'authenticity_token': token,
'login':'账号',
'password':'密码',
'commit':'Sign in',
'utf8': 'utf8',
'webauthn - support': 'webauthn'
}
# print(post_data)
# 针对登陆url发送请求
yield scrapy.FormRequest(
url='https://github.com/session',
callback = self.login,
formdata=post_data
)
#登陆完成后交给login函数,login函数请求主页,再交给check_login函数,check_login函数返回请求头数据
def login(self, response):
yield scrapy.Request(
url='https://github.com/Amen-bang',
callback=self.check_login,
)
def check_login(self, response):
print(response.xpath('/html/head/title/text()').extract_first())
![]()