Python 多线程+多进程简单使用教程,如何在多进程开多线程
一、Python多进程多线程
关于python多进程多线程的相关基础知识,在我之前的博客有写过,并且就关于python多线程的GIL锁问题,也在我的一篇博客中有相关的解释。
为什么python多线程在面对IO密集型任务的时候会产生加速作用?
为什么python多线程在面对CPU计算密集型任务的时候不仅起不到加速作用,反而加长了计算时间?
相关传送门:
进程,线程,协程关系:https://blog.csdn.net/qq_35869630/article/details/105747155
python线程GIL:https://blog.csdn.net/qq_35869630/article/details/105876923
想了解一下原理的童鞋可以稍微看看~
虽然python多线程有很多局限性,但是在某些时候还是能起到作用的。
因此今天给大家简单介绍python多线程以及怎么结合多进程使用~
二、Python多线程使用
主要使用的基于exectuor基础模块,这是一个抽象类,其子类分为ThreadPoolExecutor和ProcessPoolExecutor,分别被用来创建线程池和进程池。
为什么要使用线程池,如果对池的概念有一定理解的应该都知道池的好处,数据库连接池,线程池,进程池等等。
废话不多说,直接上代码
import pandas
def get_df_thread_io(params):
print(params)
sql= """
SELECT *
from test
limit {params}
""".format(params = params)
data = get_data(sql, connection)
time.sleep(2)
return data
def get_slice_thread_io(params):
res_df = pd.DataFrame([])
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
future_list = {
executor.submit(get_df_thread_io,i): i for i in params}
for future in concurrent.futures.as_completed(future_list):
data = future.result()
res_df = res_df.append(data)
return res_df
if __name__ == '__main__':
params = [1,10,100,1000,10000,20000,20000,20000]
text_df = get_slice_thread_io(params)
print("result_len:",len(text_df))
仔细跟大家解释一下部分参数
max_workers参数来设置线程池中最多能同时运行的线程数目,如果线程数量超过这个数目则会等待线程执行完才可以拿到连接执行任务。
submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意 submit() 不是阻塞的,而是立即返回。
as_completed方法一次取出所有任务的结果。注意这个方法也是堵塞的,会等到所有线程执行完成才会终止。
通过submit函数返回的任务句柄,能够使用 done() 方法判断该任务是否结束。
result() 方法可以获取任务的返回值。这个方法是阻塞的。
{executor.submit(get_df_thread_io,i): i for i in params} 这个写法表示构建get_df_thread_io函数,i 为传入函数的参数,构建params长度个线程任务。
这里主要构建了一个get_df_thread_io函数用来读取数据库里面的数据,返回的条数为控制的参数。
因为python多线程有GIL锁,因此不管怎么样服务器总是只会用到单个核。
运行结果如下:

可以看到只占用一个核。

可以看到结果确实是所有线程返回的结果长度相加了,数据准确度我也校验过,没什么问题~
可以看到python多线程的使用确实是非常简单的。
但是终究是python,如果一直使用单核进行多线程计算,效率再怎么说也是会有很大的瓶颈,往往满足不了优秀的你的需要。
当python多线程满足不了需求的时候,就应该考虑一下多进程了。
多进程之间的空间资源是独立的,简单的说就是多进程可以利用到多个核进行计算。但多进程之间的资源没办法共享,多线程又可以共享资源。
三、Python多进程+多线程
在上面的代码情况下,多加一个多进程模块,如下
def process_pool(params):
from multiprocessing import Pool, cpu_count
NUMBER_OF_PROCESSES = cpu_count()
pool = Pool(NUMBER_OF_PROCESSES)
text_list = pool.map(get_slice_thread_io,params)
pool.close()
pool.join()
return text_list
if __name__ == '__main__':
params = [[1,10,100,1000,10000,20000],[20000,20000],[20000,20000]]
text_list = process_pool(params)
count_1 = 0
for data in text_list:
count_1 += len(data)
print("result_len:",count_1)
cpu_count() 表示现在服务器上可用的核数,当然你也可以自己设置数值。
Pool() 实例化多进程。
pool.map(func,args) map函数 跟平常的map函数意义是一样的,将参数传到func函数,然后根据传的函数进行分发多进程计算。
这里有个要注意的,args参数要注意写成列表格式,这样map会自动分发各个参数值到func中。
可以看到我这里是将args列表分成三个部分,也就是会启动三个进程,分别计算
[1,10,100,1000,10000,20000] ,[20000,20000],[20000,20000]
这三个部分。
还有多进程计算的速度同样取决于执行最久的那个进程。
进程的关闭要注意顺序:pool.close(),pool.join()
查看cpu的使用情况。

相应的三个进程占用了三个核数的计算资源。
另外当其中某个进程执行结束都会释放相应的资源。
看看执行结果
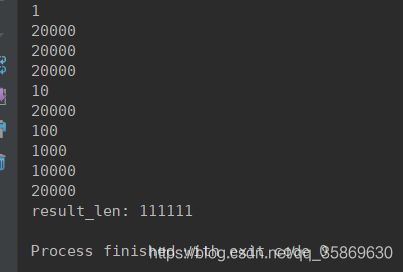
从params的数值打印就可以看出这三个进程之间是并发执行的,并且从最终返回数值中也可以看到结果跟我们想要的结果是一致的。长度是对的。
还有个需要注意小细节就是text_list 返回值也是呈现一个列表储存三个返回值,也就是text_list 列表的长度只有3,分别是三个进程执行完返回的res_df。
四、总结
Python多进程多线程的构建还算是比较简单的,这里面有一些函数属性需要各位童鞋自己去使用看熟悉的,毕竟在不同环境下有不同的需求。
不知道你们对python队列感不感兴趣,也可以考虑出一个简单的队列使用教程。
对了!!强烈建议看一下我的其他两篇相关博客,如果对线程进程协程原理感兴趣的话肯定会有收获的。
我是一只前进的蚂蚁,希望能一起前行。
如果对您有一点帮助,一个赞就够了,感谢!
注:如果本篇博客有任何错误和建议,欢迎各位指出,不胜感激!!!