- python里class转换_python实现class对象转换成json/字典的方法
八决子
python里class转换
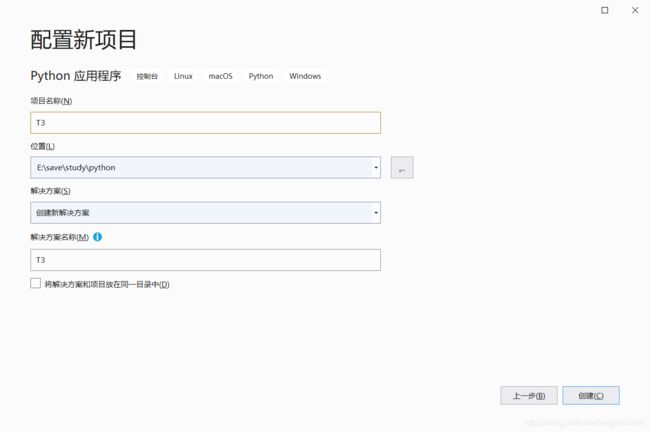
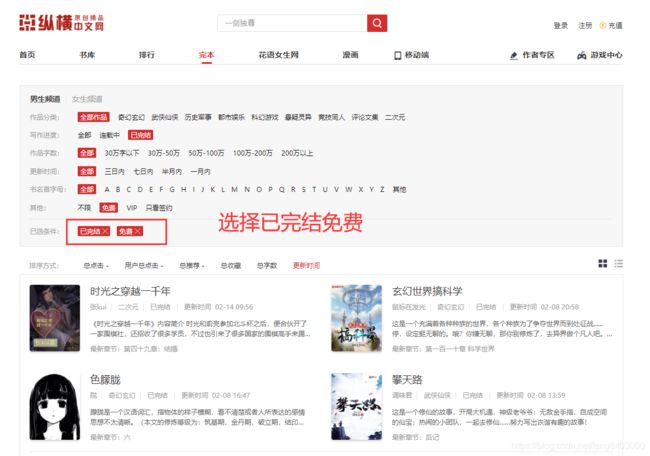
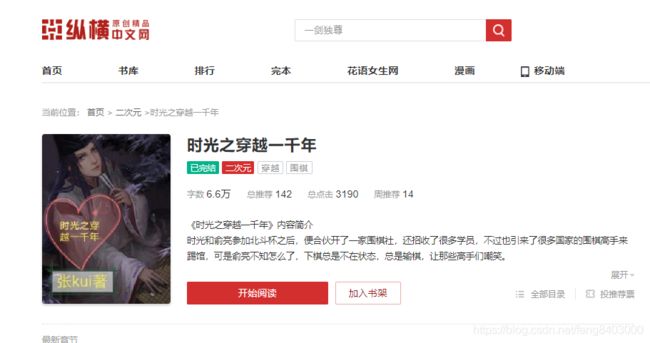
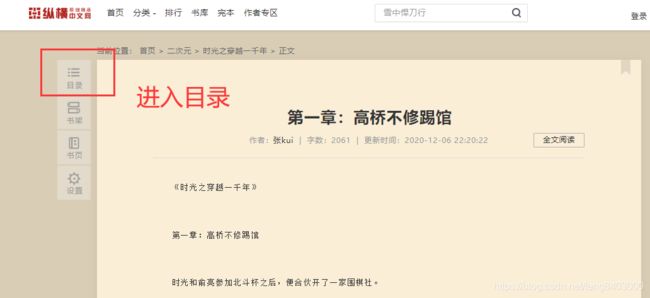
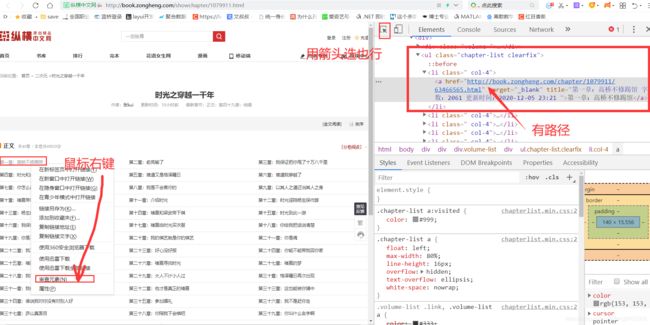
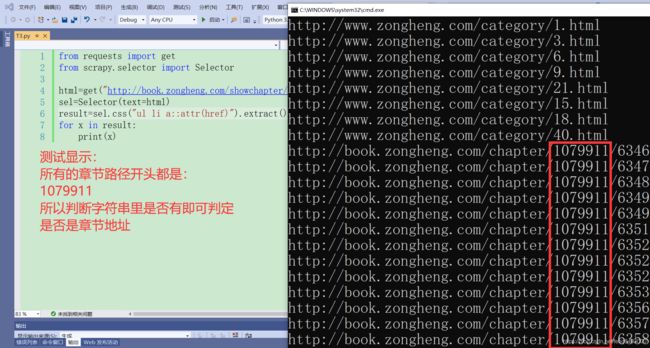
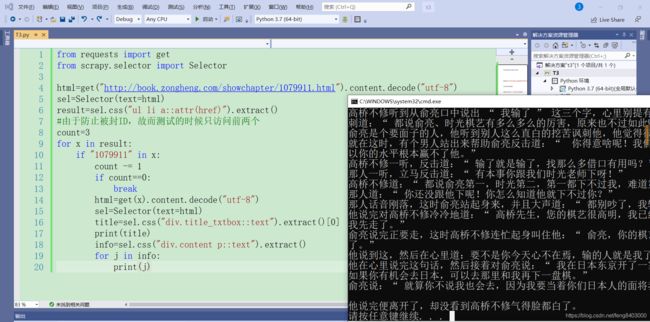
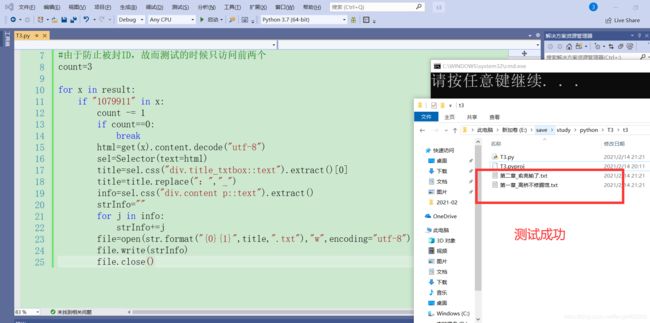
python实现class对象转换成json/字典的方法发布于2016-03-2808:05:44|153次阅读|评论:0|来源:网友投递Python编程语言Python是一种面向对象、解释型计算机程序设计语言,由GuidovanRossum于1989年底发明,第一个公开发行版发行于1991年。Python语法简洁而清晰,具有丰富和强大的类库。它常被昵称为胶水语言,它能够把用其他语言制作的各种模块
- 解密 Python 的 MRO:C3 线性化如何优雅解决多重继承的菱形难题》
《解密Python的MRO:C3线性化如何优雅解决多重继承的菱形难题》引言:继承的优雅与复杂在Python的面向对象编程中,继承是一种强大的机制,它让我们能够复用代码、构建抽象层次、实现多态行为。然而,当我们引入多重继承时,继承体系的复杂性也随之而来,尤其是著名的“菱形继承问题”。Python通过一种称为C3线性化(C3Linearization)的算法来解决方法解析顺序(MethodResolu
- 《深入理解 Python 的对象构造机制:__new__ 与 __init__ 的本质区别与实战应用》
清水白石008
开发语言学习笔记课程教程python开发语言
《深入理解Python的对象构造机制:new与init的本质区别与实战应用》引言:对象的诞生之谜在Python的面向对象编程中,我们习惯于使用__init__方法来初始化对象。但你是否曾注意到,还有一个鲜为人知却至关重要的魔法方法——__new__?它是对象构造过程的起点,掌控着类实例的真正创建。理解__new__与__init__的区别,不仅能帮助你掌握Python的对象模型,还能在构建不可变类
- Day9: OpenCV学习(一)—— 图像基础
系列文章目录上一篇:Day8:Python工程化——模块、包文章目录系列文章目录前言一、安装和导入1.安装二、图像认识1.图像2.图像分类三、基础图像操作1.图像读取2.图像显示3.图像裁剪4.图形尺寸修改5.图像保存6.图像绘制7.视频捕获即显示总结前言OpenCV(OpenSourceComputerVisionLibrary)是一个开源的计算机视觉和机器学习软件库。由一系列C++类和函数构成
- python基础语法复习04——函数
洛华363
pythonpython
python基础语法目录python基础语法01——基本类型python基础语法02——复合类型python基础语法03——语句构成文章目录python基础语法目录一、初识函数1.定义2.调用二、函数的传参1.位置传参2.关键词传参3.参数默认值4.可变位置参数5.可变关键词参数6.参数解包7.值传递与引用传递总结一、初识函数函数是Python中可重复使用的代码块,用于执行特定任务。通过将代码封装
- ubuntu18.04安装geemap
阿西是有梦想的咸鱼
python编程之路遥感影像处理可视化可视化pythonubuntu
文章目录安装测试GEE提供了JavaScript和PythonAPI,可以向EarthEngine服务器发出计算请求。与GEEJavaScriptAPI相比,PythonAPI缺乏易于理解的操作文档和交互式可视化结果的功能。由此,geemap诞生并填补了这一空白[1]。这里给大家介绍下我折腾了一晚上才搞定的geemap的安装及测试过程。这里是geemap的GitHub参考链接。安装如Github中
- python进行geeMap环境安装
箭梭_
python
近期需要利用geemap搭建一个界面,试了一下相应环境的配置,踏了挺多坑,下面我给大家具体介绍一下geemap的环境搭建:(1)geemap是基于googleearthengine的接口进行开发的,在安装geemap之前,需要先进行earthengie包的安装,参考链接如下:https://zhuanlan.zhihu.com/p/29186942#comment-549701602?notifi
- API开发全攻略:从入门到精通的企业级API架构与实战
Android洋芋
架构API设计RESTfulAPI微服务架构实战案例
简介API开发已成为现代软件架构的核心能力,掌握API设计与实现技术能显著提升开发效率和系统可扩展性。本文将从零开始,全面解析API的基础概念、架构设计、安全认证、性能优化等关键技术点,并提供完整的Python和Go语言代码实战示例,帮助开发者构建高性能、可扩展的企业级API系统。本文旨在为初学者和进阶开发者提供一份全面的API开发指南。内容涵盖API的基础概念、类型分类、架构设计、安全认证、性能
- 2023年NOC大赛创客智慧编程赛项Python 复赛模拟题(二)
青少儿编程课堂
少儿编程资料大全付费专栏pythonnumpy开发语言noc大赛真题noc试题
题目来自:NOC大赛创客智慧编程赛项Python复赛模拟题(二)NOC大赛创客智慧编程赛项Python复赛模拟题(二)第一题:编写一个成绩评价系统,当输入语文、数学和英语三门课程成绩时,输出三门课程总成绩及其等级。(1)程序提示用户输入三个数字,数字分别表示语文、数学、英语分数,对应的变量名称是Chinese、Math、English,并计算三个分数的和(score)进行输出。注:input()函
- 【RS】GEE(Python):大规模分析与导出数据
在前面的章节中,我们探讨了如何在GoogleEarthEngine(GEE)上进行数据加载、处理、分析和可视化。现在,我们将进一步扩展,探索如何处理大规模的数据集和执行复杂的分析任务。通过GEE的云计算能力,用户可以在全球范围内执行大规模的时空分析,并高效地将处理结果导出为所需的格式。大规模分析的基本原则在GEE中,大规模分析是通过ImageCollection和FeatureCollection
- 【Python篇】Python基础——08day.面向对象编程中类和对象的基本概念及属性和方法的常见分类和使用场景
WXX_s
python基础篇python分类开发语言学习
目录前言一、类和对象1.类→Class1.1概念1.2创建2.对象→Object2.1概念2.2创建二、属性和方法1.实例属性2.实例方法3.类属性4.类方法5.静态方法5.1综合应用6.构造方法7.初始化方法8.魔术方法8.1常用方法8.2案例参考总结前言这章讲的面向对象编程(Object-OrientedProgramming,简称OOP)是一种通过组织对象来设计程序的编程方法。为什么需要类和
- 【Python篇】Python基础——04day.Python中运算(简单部分,如果会的可以直接跳过)
文章目录前言一.运算符1.1算术运算符1.2比较运算符1.3逻辑运算符1.4赋值运算符1.5位运算符1.6身份运算符1.7成员运算符1.8三目运算符1.9优先级二.表达式2.1算术表达式2.2比较表达式2.3逻辑表达式2.4赋值表达式2.5成员表达式2.6身份表达式2.7三元表达式2.8函数调用表达式三.推导式3.1列表推导式3.2字典推导式3.3集合推导式总结前言这一章写的是在python中会用
- Python 现代时间序列预测第二版(五)
绝不原创的飞龙
默认分类默认分类
原文:annas-archive.org/md5/22eab741fce9c15dfad894ecf37bdd51译者:飞龙协议:CCBY-NC-SA4.0第十七章:概率预测及更多在整本书中,我们学习了生成预测的不同技术,包括一些经典方法,使用机器学习以及一些深度学习架构。但我们一直在关注一种典型的预测问题——为连续时间序列生成点预测,并且没有层级关系且历史数据足够丰富。我们之所以这样做,是因为这
- 自动化测试中,测试数据如何管理?
鱼鱼说测试
javalinux服务器
今晚在某个测试群,看到有人问了一个问题:把测试数据放配置文件读取和放文件通过函数调用读取有什么区别?Python接口自动化测试零基础入门到精通(2025最新版)当时我下意识的这么回答:数据量越大,配置文件越臃肿,放在专门的数据文件(比如excel,csv),方便针对性的维护。乍看没毛病,但回头和人讨论这个问题的时候,就认真思考了一下这个问题,下面是我的一些思考和讨论的一些结果,仅供参考。。。自动化
- 基于selenium的pyse自动化测试框架
鱼鱼说测试
selenium测试工具
Python接口自动化测试零基础入门到精通(2025最新版)介绍:pyse基于selenium(webdriver)进行了简单的二次封装,比selenium所提供的方法操作更简洁。特点:默认使用CSS定位,同时支持多种定位方法(id\name\class\link_text\xpath\css)。本框架只是对selenium(webdriver)原生方法进行了简单的封装,精简为大约30个方法,这些
- 自动化测试准备
鱼鱼说测试
自动化测试
什么是自动化测?Python接口自动化测试零基础入门到精通(2025最新版)首先理清自动化测试的概念,广义上来讲,自动化包括一切通过工具(程序)的方式来代替或辅助手工测试的行为都可以看做自动化,包括性能测试工具(loadrunner、jmeter),或自己所写的一段程序,用于生成1到100个测试数据。狭义上来讲,通工具记录或编写脚本的方式模拟手工测试的过程,通过回放或运行脚本来执行测试用例,从而代
- 重塑未来:AI如何重新定义全栈开发
熊猫钓鱼>_>
人工智能
在传统认知中,全栈开发者被誉为技术界的“全能选手”。——他们需要精通前端界面构建(HTML/CSS/JavaScript)、后端业务逻辑实现(Python/Java/Node.js)、数据库设计优化(MySQL/MongoDB)以及服务器部署运维(Linux/Docker)。这种“一人包打天下”的能力模型长期被视为高效开发的黄金标准,尤其受到创业公司和小型团队的青睐,因为它能大幅减少沟通成本,加速
- OpenCV稠密光流法可直接运行的例程(python)
indrrra
opencvpython人工智能
#dense_optical_flow.pyimportcv2importnumpyasnpimportargparsedefdense_optical_flow(method,video_path,params=[],to_gray=False):#读取视频cap=cv2.VideoCapture(video_path)#读取第一帧ret,old_frame=cap.read()#创建HSV并使
- 分布式锁特点、以及用python3实现redis分布式锁
数据知道
python3案例和总结分布式redis数据库python
更多内容请见:python3案例和总结-专栏介绍和目录文章目录一、Redis分布式锁核心原理1.1Redis锁机制1.2锁释放二、基础实现代码2.1使用`redis-py`客户端2.2分布式锁类三、使用示例3.1基础锁操作3.2装饰器模式四、高级特性实现4.1Redlock算法(高可用方案)五、生产环境最佳实践5.1锁粒度控制5.2异常处理5.3监控与调试5.4重试机制六、测试代码6.1并发测试6
- 【爬虫】05 - 爬虫攻防
是小崔啊
#爬虫学习爬虫
爬虫05-爬虫攻防文章目录爬虫05-爬虫攻防一:随机User-Agent爬虫1:fake-useragent2:高级反反爬策略3:生产环境建议二:代理IP爬虫1:获取代理IP2:高阶攻防3:企业级的代理实战三:动态数据的抓取1:动态页面技术全景2:动态页面逆向工程2.1:XHR请求追踪与解析2.2:websocket实时数据捕获3:无头浏览器控制技术3.1:Playwright详解3.2:反反爬虫
- php、go、python后端接口签名实现
奇华智能
后台开发linux签名接口安全
1.php实现/**生成签名,$args为请求参数,$key为私钥*/functionmakeSignature($args,$key){if(isset($args['sign'])){$oldSign=$args['sign'];unset($args['sign']);}else{$oldSign='';}ksort($args);$requestString='';foreach($arg
- python第一次作业
1.技术面试题(1)TCP与UDP的区别是什么?**答:1.TCP是面向连接的协议,而UDP是元连接的协议2.TCP协议传输是可靠的,而UDP协议的传输是“尽力而为3.TCP是可以实现流控,而UDP不行4.TCP可以实现分段,而UDP不行5.TCP的传输速率较慢,占用资源较大,UDP传输速率快,占用资源小。TCP/UDP的应用场景不同TCP适合可靠性高的效率要求低的,UDP可靠性低,效率高。(2)
- python
www_hhhhhhh
pythonjava面试
1.技术面试题(1)解释Linux中的进程、线程和守护进程的概念,以及如何管理它们?答:进程:是操作系统进行资源分配的基本单位,拥有独立的地址空间、进程控制块,每个进程之间相互隔离。例如,打开一个终端窗口会启动一个bash进程。线程:是操作系统调度的基本单位,隶属于进程,共享进程的资源,但有独立的线程控制块和栈。线程切换开销远小于进程。例如,一个Web服务器的单个进程中,多个线程可同时处理不同客户
- Python lambda表达式:匿名函数的适用场景与限制
梦幻南瓜
pythonpython服务器linux
目录1.Lambda表达式概述1.1Lambda表达式的基本语法1.2简单示例2.Lambda表达式的核心特点2.1匿名性2.2简洁性2.3即时性2.4函数式编程特性3.Lambda表达式的适用场景3.1作为高阶函数的参数3.2简单的数据转换3.3条件筛选3.4GUI编程中的回调函数3.5Pandas数据处理4.Lambda表达式的限制4.1只能包含单个表达式4.2没有语句4.3缺乏文档字符串4.
- 【python】
www_hhhhhhh
python面试职场和发展
1.技术面试题(1)TCP与UDP的区别是什么?答:TCP(传输控制协议)和UDP(用户数据报协议)是两种常见的传输层协议,主要区别在于连接方式和可靠性。TCP是面向连接的协议,传输数据前需建立连接,通过三次握手确保连接可靠,传输过程中有确认、重传和顺序控制机制,保证数据完整、按序到达,适用于网页浏览、文件传输等对可靠性要求高的场景。UDP是无连接的协议,无需建立连接即可发送数据,不保证数据可靠传
- Python函数的返回值
1.返回值定义及案例:2.返回值与print的区别:print仅仅是打印在控制台,而return则是将return后面的部分作为返回值作为函数的输出,可以用变量接走,继续使用该返回值做其它事。3.保存函数的返回值如果一个函数return返回了一个数据,那么想要用这个数据,那么就需要保存.#定义函数defadd2num(a,b): returna+b#调用函数,顺便保存函数的返回值result=
- python怎么把函数返回值_python函数怎么返回值
python函数使用return语句返回“返回值”,可以将其赋给其它变量作其它的用处。所有函数都有返回值,如果没有return语句,会隐式地调用returnNone作为返回值。python函数使用return语句返回"返回值",可以将其赋给其它变量作其它的用处。所有函数都有返回值,如果没有return语句,会隐式地调用returnNone作为返回值。一个函数可以存在多条return语句,但只有一条
- Python星球日记 - 第8天:函数基础
Code_流苏
Python星球日记python函数def关键字函数参数返回值
引言:上一篇:Python星球日记-第7天:字典与集合名人说:路漫漫其修远兮,吾将上下而求索。——屈原《离骚》创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder)目录一、函数的定义与调用1.什么是函数?2.如何定义函数-`def`关键字3.函数调用方式二、参数与返回值1.函数参数类型2.如何传递参数3.返回值和`return`语句三、局部变量与全局变量1.变量作用域概念2.局部变
- 华为OD机试2025C卷 - 小明的幸运数 (C++ & Python & JAVA & JS & GO)
无限码力
华为od华为OD机试2025C卷华为OD2025C卷华为OD机考2025C卷
小明的幸运数华为OD机试真题目录点击查看:华为OD机试2025C卷真题题库目录|机考题库+算法考点详解华为OD机试2025C卷100分题型题目描述小明在玩一个游戏,游戏规则如下:在游戏开始前,小明站在坐标轴原点处(坐标值为0).给定一组指令和一个幸运数,每个指令都是一个整数,小明按照指令前进指定步数或者后退指定步数。前进代表朝坐标轴的正方向走,后退代表朝坐标轴的负方向走。幸运数为一个整数,如果某个
- Python 函数返回值
落花雨时
Python基础
#返回值,返回值就是函数执行以后返回的结果#可以通过return来指定函数的返回值#可以之间使用函数的返回值,也可以通过一个变量来接收函数的返回值defsum(*nums):#定义一个变量,来保存结果result=0#遍历元组,并将元组中的数进行累加forninnums:result+=nprint(result)#sum(123,456,789)#return后边跟什么值,函数就会返回什么值#r
- java数字签名三种方式
知了ing
javajdk
以下3钟数字签名都是基于jdk7的
1,RSA
String password="test";
// 1.初始化密钥
KeyPairGenerator keyPairGenerator = KeyPairGenerator.getInstance("RSA");
keyPairGenerator.initialize(51
- Hibernate学习笔记
caoyong
Hibernate
1>、Hibernate是数据访问层框架,是一个ORM(Object Relation Mapping)框架,作者为:Gavin King
2>、搭建Hibernate的开发环境
a>、添加jar包:
aa>、hibernatte开发包中/lib/required/所
- 设计模式之装饰器模式Decorator(结构型)
漂泊一剑客
Decorator
1. 概述
若你从事过面向对象开发,实现给一个类或对象增加行为,使用继承机制,这是所有面向对象语言的一个基本特性。如果已经存在的一个类缺少某些方法,或者须要给方法添加更多的功能(魅力),你也许会仅仅继承这个类来产生一个新类—这建立在额外的代码上。
- 读取磁盘文件txt,并输入String
一炮送你回车库
String
public static void main(String[] args) throws IOException {
String fileContent = readFileContent("d:/aaa.txt");
System.out.println(fileContent);
- js三级联动下拉框
3213213333332132
三级联动
//三级联动
省/直辖市<select id="province"></select>
市/省直辖<select id="city"></select>
县/区 <select id="area"></select>
- erlang之parse_transform编译选项的应用
616050468
parse_transform游戏服务器属性同步abstract_code
最近使用erlang重构了游戏服务器的所有代码,之前看过C++/lua写的服务器引擎代码,引擎实现了玩家属性自动同步给前端和增量更新玩家数据到数据库的功能,这也是现在很多游戏服务器的优化方向,在引擎层面去解决数据同步和数据持久化,数据发生变化了业务层不需要关心怎么去同步给前端。由于游戏过程中玩家每个业务中玩家数据更改的量其实是很少
- JAVA JSON的解析
darkranger
java
// {
// “Total”:“条数”,
// Code: 1,
//
// “PaymentItems”:[
// {
// “PaymentItemID”:”支款单ID”,
// “PaymentCode”:”支款单编号”,
// “PaymentTime”:”支款日期”,
// ”ContractNo”:”合同号”,
//
- POJ-1273-Drainage Ditches
aijuans
ACM_POJ
POJ-1273-Drainage Ditches
http://poj.org/problem?id=1273
基本的最大流,按LRJ的白书写的
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
#define INF 0x7fffffff
int ma
- 工作流Activiti5表的命名及含义
atongyeye
工作流Activiti
activiti5 - http://activiti.org/designer/update在线插件安装
activiti5一共23张表
Activiti的表都以ACT_开头。 第二部分是表示表的用途的两个字母标识。 用途也和服务的API对应。
ACT_RE_*: 'RE'表示repository。 这个前缀的表包含了流程定义和流程静态资源 (图片,规则,等等)。
A
- android的广播机制和广播的简单使用
百合不是茶
android广播机制广播的注册
Android广播机制简介 在Android中,有一些操作完成以后,会发送广播,比如说发出一条短信,或打出一个电话,如果某个程序接收了这个广播,就会做相应的处理。这个广播跟我们传统意义中的电台广播有些相似之处。之所以叫做广播,就是因为它只负责“说”而不管你“听不听”,也就是不管你接收方如何处理。另外,广播可以被不只一个应用程序所接收,当然也可能不被任何应
- Spring事务传播行为详解
bijian1013
javaspring事务传播行为
在service类前加上@Transactional,声明这个service所有方法需要事务管理。每一个业务方法开始时都会打开一个事务。
Spring默认情况下会对运行期例外(RunTimeException)进行事务回滚。这
- eidtplus operate
征客丶
eidtplus
开启列模式: Alt+C 鼠标选择 OR Alt+鼠标左键拖动
列模式替换或复制内容(多行):
右键-->格式-->填充所选内容-->选择相应操作
OR
Ctrl+Shift+V(复制多行数据,必须行数一致)
-------------------------------------------------------
- 【Kafka一】Kafka入门
bit1129
kafka
这篇文章来自Spark集成Kafka(http://bit1129.iteye.com/blog/2174765),这里把它单独取出来,作为Kafka的入门吧
下载Kafka
http://mirror.bit.edu.cn/apache/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz
2.10表示Scala的版本,而0.8.1.1表示Kafka
- Spring 事务实现机制
BlueSkator
spring代理事务
Spring是以代理的方式实现对事务的管理。我们在Action中所使用的Service对象,其实是代理对象的实例,并不是我们所写的Service对象实例。既然是两个不同的对象,那为什么我们在Action中可以象使用Service对象一样的使用代理对象呢?为了说明问题,假设有个Service类叫AService,它的Spring事务代理类为AProxyService,AService实现了一个接口
- bootstrap源码学习与示例:bootstrap-dropdown(转帖)
BreakingBad
bootstrapdropdown
bootstrap-dropdown组件是个烂东西,我读后的整体感觉。
一个下拉开菜单的设计:
<ul class="nav pull-right">
<li id="fat-menu" class="dropdown">
- 读《研磨设计模式》-代码笔记-中介者模式-Mediator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/*
* 中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。
* 中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
*
* 在我看来,Mediator模式是把多个对象(
- 常用代码记录
chenjunt3
UIExcelJ#
1、单据设置某行或某字段不能修改
//i是行号,"cash"是字段名称
getBillCardPanelWrapper().getBillCardPanel().getBillModel().setCellEditable(i, "cash", false);
//取得单据表体所有项用以上语句做循环就能设置整行了
getBillC
- 搜索引擎与工作流引擎
comsci
算法工作搜索引擎网络应用
最近在公司做和搜索有关的工作,(只是简单的应用开源工具集成到自己的产品中)工作流系统的进一步设计暂时放在一边了,偶然看到谷歌的研究员吴军写的数学之美系列中的搜索引擎与图论这篇文章中的介绍,我发现这样一个关系(仅仅是猜想)
-----搜索引擎和流程引擎的基础--都是图论,至少像在我在JWFD中引擎算法中用到的是自定义的广度优先
- oracle Health Monitor
daizj
oracleHealth Monitor
About Health Monitor
Beginning with Release 11g, Oracle Database includes a framework called Health Monitor for running diagnostic checks on the database.
About Health Monitor Checks
Health M
- JSON字符串转换为对象
dieslrae
javajson
作为前言,首先是要吐槽一下公司的脑残编译部署方式,web和core分开部署本来没什么问题,但是这丫居然不把json的包作为基础包而作为web的包,导致了core端不能使用,而且我们的core是可以当web来用的(不要在意这些细节),所以在core中处理json串就是个问题.没办法,跟编译那帮人也扯不清楚,只有自己写json的解析了.
- C语言学习八结构体,综合应用,学生管理系统
dcj3sjt126com
C语言
实现功能的代码:
# include <stdio.h>
# include <malloc.h>
struct Student
{
int age;
float score;
char name[100];
};
int main(void)
{
int len;
struct Student * pArr;
int i,
- vagrant学习笔记
dcj3sjt126com
vagrant
想了解多主机是如何定义和使用的, 所以又学习了一遍vagrant
1. vagrant virtualbox 下载安装
https://www.vagrantup.com/downloads.html
https://www.virtualbox.org/wiki/Downloads
查看安装在命令行输入vagrant
2.
- 14.性能优化-优化-软件配置优化
frank1234
软件配置性能优化
1.Tomcat线程池
修改tomcat的server.xml文件:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" maxThreads="1200" m
- 一个不错的shell 脚本教程 入门级
HarborChung
linuxshell
一个不错的shell 脚本教程 入门级
建立一个脚本 Linux中有好多中不同的shell,但是通常我们使用bash (bourne again shell) 进行shell编程,因为bash是免费的并且很容易使用。所以在本文中笔者所提供的脚本都是使用bash(但是在大多数情况下,这些脚本同样可以在 bash的大姐,bourne shell中运行)。 如同其他语言一样
- Spring4新特性——核心容器的其他改进
jinnianshilongnian
spring动态代理spring4依赖注入
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- Linux设置tomcat开机启动
liuxingguome
tomcatlinux开机自启动
执行命令sudo gedit /etc/init.d/tomcat6
然后把以下英文部分复制过去。(注意第一句#!/bin/sh如果不写,就不是一个shell文件。然后将对应的jdk和tomcat换成你自己的目录就行了。
#!/bin/bash
#
# /etc/rc.d/init.d/tomcat
# init script for tomcat precesses
- 第13章 Ajax进阶(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Troubleshooting Crystal Reports off BW
blueoxygen
BO
http://wiki.sdn.sap.com/wiki/display/BOBJ/Troubleshooting+Crystal+Reports+off+BW#TroubleshootingCrystalReportsoffBW-TracingBOE
Quite useful, especially this part:
SAP BW connectivity
For t
- Java开发熟手该当心的11个错误
tomcat_oracle
javajvm多线程单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 正则表达式大全
yang852220741
html编程正则表达式
今天向大家分享正则表达式大全,它可以大提高你的工作效率
正则表达式也可以被当作是一门语言,当你学习一门新的编程语言的时候,他们是一个小的子语言。初看时觉得它没有任何的意义,但是很多时候,你不得不阅读一些教程,或文章来理解这些简单的描述模式。
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$