数据库原理及其应用
数据库原理及其应用
- 第一章:数据库系统
-
- 数据库管理系统(DBMS)
- 数据库应用系统(DBAS)
- 数据库(DB)
- 第二章:关系运算
- 第三章:数据库应用系统设计概述
-
- 3.1生命周期
-
- 1、用户需求分析:逻辑描述
- 2、概念结构设计:生成信息结构
- 3、逻辑结构设计
- 4、物理结构设计:数据库在物理设备上存储结构和存取方法
- 5、软件维护
- 第五章:关系数据库语言SQL
- 第六章:关系数据库模式设计
- 第七章:T-SQL 语言
-
- 存储过程
- 触发器
- 第八章:数据库安全
-
- 8.1、用户标识与鉴别
- 8.2、存取控制
- 8.3、视图
- 8.4、审计
- 8.5、数据加密
- 第九章:数据库保护
-
- 9.1、事务
- 9.2、并发操作
- 9.3、数据库的恢复
第一章:数据库系统
数据库管理系统(DBMS)
定义、操作、控制、维护数据库以及通信功能
数据库应用系统(DBAS)
3个基本要素:
数据、物理存储器、数据库软件
数据库(DB)
1、数据库是可感知的数据库形体
2、数据是不可感知的数据库形体
3、数据库是按一定组织方式存储在一起相关的数据集合
关系模型是一种二维表格
学生关系S
专业关系SS
课程关系C
设置关系CS
学习关系SC
数据管理系统:DBMS
关系:一个二维表格
属性(字段):表格每列列名
元组(记录):每行数据
元组分量:一个元组在一个属性上的取值称为该元组的元组分量
属性值:表中的一个数据项
值域:某属性的取值范围
关系状态(关系实例):某个时期的关系内容
数据库的三级模式结构
1、外模式:视图、部分基本表
2、(逻辑)模式:所有基本表的集合
3、内模式:存储文件和索引
第二章:关系运算
投影:Π,得到结果后去除重复项

第三章:数据库应用系统设计概述
3.1生命周期

1、用户需求分析:逻辑描述
数据流图


2、概念结构设计:生成信息结构
1、属性表
2、实体-联系模型:E-R图
属性表:

E-R图:
1、实体集
2、联系集
3、属性集
3、逻辑结构设计
第三范式下ER图转关系模式:
对于1:1,合并者添加对方主码,或者用双方主码建立独立关系模式
对于1:N , 向N端添加1端主码
对于M:N,用双方主码建立独立关系模式
4、物理结构设计:数据库在物理设备上存储结构和存取方法
物理文件:
数据文件、日志文件、控制文件
数据文件:主数据文件,是数据库起点,指向其他次数据库文件,存储启动信息和部分数据
控制文件:存放DBMS控制信息,实现数据库安全性和完整性控制
索引:
1、线性索引
2、树形索引
线性索引:
1、稠密索引:索引项和记录一一对应,存放随机
2、稀疏索引:记录分为块,只有每个块最大主键值才对应索引项,存放按顺序
树形索引:
利用稀疏索引的性质将索引分块建立多级索引
B-树 结点:根节点、叶节点、内节点
根节点、内节点:存放索引项(索引存储块)
叶节点:存放记录索引项(记录索引块)
聚簇索引
叶节点改为存储数据记录,按顺序存储
非聚簇索引
叶节点改为存储数据记录,不按顺序存储
5、软件维护
改正性维护(软件本身)
适应性维护 (运行环境)
完善性维护(用户需求)
第五章:关系数据库语言SQL
常见事件:
DDL:操作数据库、表、列等对象:create、alter、drop
DML:操作数据:insert、update、delete
5.1、表的定义
create table 表名
列完整性约束
null 、not null 、 primary key 、default(缺省值) 、 check(条件)
表完整性约束
primary key(列名…)
foreign key(列名1)
reference 表名 (列名2) 在这里是主键
check() 在这里可以包含select语句
5.2、表的修改
改变表名
sp_rename 原表名 新表名
增加列(加到末尾)
alter table 表名 add 新列名 数据类型
删除列
alter table 表名 drop 删除列名 【cascade / restrict】
cascade 删除所有,包括引用 、视图
restrict 删除所有,前提它是最后一个
修改列名
alter table 表名 modify 列名 新数据类型及长度
删除表
drop table 表名 【cascade / restrict】
数据插入
insert into 表名 【列名表】 values(值表)
数据修改
update 表名
set 列名=表达式
【where 条件】
数据删除
delete from 表名
【where 条件】
数据查询 distinct的作用是去除重复行,默认是all不去除
select 【distinct】 列名表
from 表名表

5.3、查询
选择查询 where
包含 is null 是空值 is not null 不是空值
数值型列名 between 下限 and 上限
多条件 条件1 or 条件2
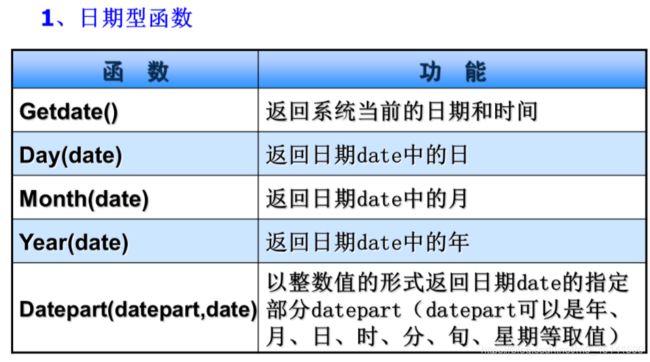

结果排序:asc 升序 desc 降序,默认升序
order by 列名1【asc /desc】, 列名2【asc /desc】,
模糊查询
列名 like ‘通配符’
通配符:
_ 任意单个字符
%任意长度字符串
分组查询
group bu 列名表
【having 分组条件】
将列的值分为好几组

在from中可指明连接的表名
在where中可知名连接的列名
第六章:关系数据库模式设计
用属性的值体现的:数据依赖
属性名体现:函数依赖
规范化设计的必要性:
因为存在:
1、数据冗余
2、更新异常
3、插入异常
4、删除异常

三大范式、部分依赖、完全依赖、传递依赖
第一范式1NF
单位不可再分
第二范式2NF
消除部分依赖,属性不能只依赖部分的主属性
第三依赖3NF
在第二范式基础上再消除传递依赖,数据表的每一列都与主键直接相关,而不依赖其他非主属性(因为其他非主属性可能依赖主属性,产生传递依赖)
BCNF
在第三范式基础上拓展到主属性,即主属性之间不能依赖
部分函数依赖

完全函数依赖

传递函数依赖
![]()
第七章:T-SQL 语言
局部变量定义:
declare @变量名 数据类型,…… --变量定义
set @变量名 = 值 --变量赋值
创建数据库
(
'create database 数据库名
on
(name=主数据库文件逻辑名,filename=操作系统文件名.mdf,size=大小,maxsize=最大值,filegrowth=5%)
log on
(name = 日志逻辑文件名,filename=日志文件名.ldfg, size=大小,maxsize=最大值,filegrowth=2MB)'
);
go
使用数据库
use 数据库名
删除数据库
drop database 数据库名
存储过程
存储过程有封装思想,接收用户信息,返回值
存储过程优点
1、实现了模块化编程
2、立即访问数据库
3、加快程序运行速度
4、减少网络流量
5、提高数据库的安全性
存储过程种类
1、系统存储过程(类似系统库):以sp_为前缀,存放在master数据库中
2、用户自定义存储过程:不需要前缀,存放在用户自己的数据库中
3、临时存储过程:#前缀表示是本地临时存储过程,##表示全局临时存储过程
4、拓展存储过程(类似第三方库):以xp_为前缀,添加到master数据库中
5、远程存储过程:从远程服务器调用的
触发器
一类特殊的存储过程,通过事件进行触发执行
常见事件:
DDL:操作数据库、表、列等对象:create、alter、drop
DML:操作数据:insert、update、delete
第八章:数据库安全
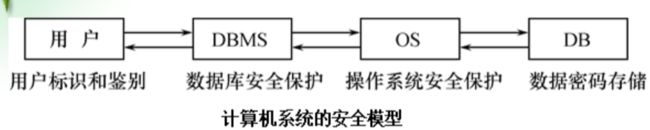
数据库安全性控制的五种常用方法
8.1、用户标识与鉴别
位于最外层
8.2、存取控制
由用户权限定义和合法权限检查组成
授权
grant 权限名,…… -- all priviliges 为全部权限,对某列授权必须指明 update(Sno)
on table 表名,……
to 用户名,…… -- public 为所有用户
with grant option --允许授权给其他用户这些权限(允许用户传播权限)
回收权限
revoke 权限名,……
on table 表名,……
from 用户名,…… 【cascade】 --级联,否则无法收回传播的权限(报错)
角色:权限集合
create role 角色名
grant 权限名,……
on table 表名,……
to 角色,……
8.3、视图
create view 视图名
as
select * --剩下的和前面的获取表一样
from student
where
8.4、审计
可选性
1、审计费时间和空间
2、DBA(数据库管理员)可以根据应用对安全性的要求来灵活打开和关闭审计功能
3、主要用于安全性要求较高的部门
审计事件
1、服务器事件
2、系统权限
3、语句事件
4、模式对象事件
audit 操作名,…… --开启审计
on 表名,……
noaudit 操作名,…… -- 取消审计
on 表名,……
8.5、数据加密
身份验证模式
1、windows身份验证模式–默认
2、混合验证模式
安全性主体的三个级别
1、服务器级别
2、数据库级别
3、架构级别
第九章:数据库保护
9.1、事务
事务是恢复和并发控制的基本单位
事务四个特性(ACID)
1、原子性:逻辑工作单位
2、一致性:不会因执行事务破坏数据库
3、隔离性:并发执行不互相干扰
4、持续性:改变是永久性的
9.2、并发操作
1、丢失更新:并发修改会覆盖
2、不可重复读
3、读“脏”数据
并发控制: 封锁(locking锁)、时标(时间戳)
9.3、数据库的恢复
1、转储和建立日志
2、数据库恢复
UNDO:未被破坏,撤销修改即可
REDO:已被破坏,加载数据库备份,利用日志库执行重做