如何用python实现聚类离散化
起始聚类离散化就是根据利用一定规则对数据进行分类,可以用分桶式或者k-means 等方法
这里用中医证型关联规则挖掘里面的离散化举例,k-means 举例
首先看下图的原数据,该病存在六种证型系数,为了后续的关联算法,需要先将其离散化。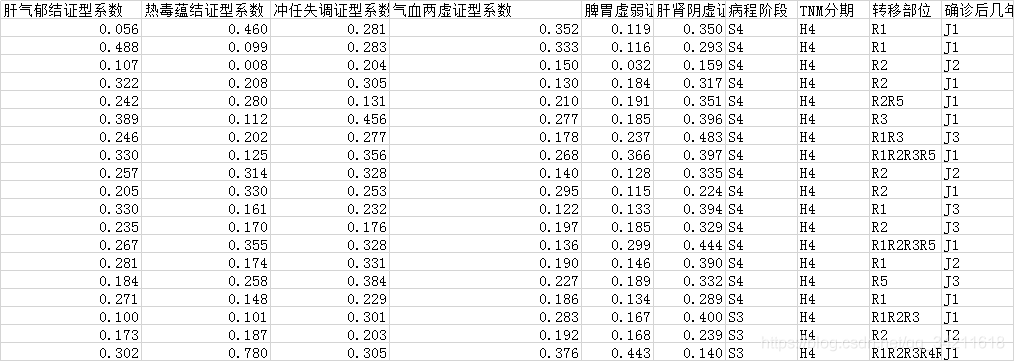
import pandas as pd
from sklearn.cluster import KMeans #导入K均值聚类算法
datafile = '../data/data.xls' #待聚类的数据文件
processedfile = '../tmp/data_processed.xls' #数据处理后文件
typelabel ={u'肝气郁结证型系数':'A', u'热毒蕴结证型系数':'B', u'冲任失调证型系数':'C', u'气血两虚证型系数':'D', u'脾胃虚弱证型系数':'E', u'肝肾阴虚证型系数':'F'}
k = 4 #需要进行的聚类类别数
#读取数据并进行聚类分析
data = pd.read_excel(datafile) #读取数据
keys = list(typelabel.keys())
result = pd.DataFrame()
if __name__ == '__main__': #判断是否主窗口运行,这句代码的作用比较神奇,有兴趣了解的读取请自行搜索相关材料。
for i in range(len(keys)):
#调用k-means算法,进行聚类离散化
print(u'正在进行“%s”的聚类...' % keys[i])
kmodel = KMeans(n_clusters = k, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data[[keys[i]]]) #训练模型
print(kmodel.cluster_centers_)
r1 = pd.DataFrame(kmodel.cluster_centers_, columns = [typelabel[keys[i]]]) #聚类中心
#print('r1',r1,kmodel.labels_)
r2 = pd.Series(kmodel.labels_).value_counts() #分类统计
r2 = pd.DataFrame(r2, columns = [typelabel[keys[i]]+'n']) #转为DataFrame,记录各个类别的数目
r = pd.concat([r1, r2], axis = 1).sort_values(typelabel[keys[i]]) #匹配聚类中心和类别数目
r.index = [1, 2, 3, 4]
print('r-1',r)
r[typelabel[keys[i]]] = r[typelabel[keys[i]]].rolling(2).mean() #rolling_mean()用来计算相邻2列的均值,以此作为边界点。
print('r-2', r)
r.iloc[0,0] = 0.0 #这两句代码将原来的聚类中心改为边界点。
print('r-3', r)
result = result.append(r.T)
result = result.sort_index() #以Index排序,即以A,B,C,D,E,F顺序排
result.to_excel(processedfile)
例子二,通过cut进行离散化
import pandas as pd
import numpy as np
index = pd.Index(data=["Tom", "Bob", "Mary", "James","kobe","kawayi"], name="name")
data = {
"age": [15, 28, 23, 37,33,11]
}
user_info = pd.DataFrame(data=data, index=index)
pd.cut(user_info.age,3) #分成3段,
#[(10.974, 19.667] < (19.667, 28.333] < (28.333, 37.0]] 按照数据的最大值最小值为区间分成3分
当然还可以自定义进行划分
比如
qujian=[5,15,25,40]
pd.cut(user_info.age,qujian,labels=['child','youth','middle'])
#此时就不会按最大值最小值分成3分,而是按照5-15,15-25,25-40的固定区间分,同时会按labels对区间命名
#若想查看各区间的人数,可以用groupyby函数
pdd=pd.cut(user_info['age'],qujian)
user_info['age'].groupby(pdd).count()
#可以通过遍历来查看某一区间有哪些值,pdd相当于一个列名,在翻阅其他例子时发现假如某列就是离散的,可以直接用#groupby("age")
for i in user_info['age'].groupby(pdd):
print(i)
参考文献:
1,Python数据分析与挖掘实战
2,本文借鉴了https://blog.csdn.net/weixin_37536446/article/details/82149772