- max_samples,batch_size,gradient_accumulation_steps这三个分别的联系和区别
背太阳的牧羊人
模型微调batch机器学习人工智能
这三个参数都是控制训练数据如何被处理的,它们的作用和区别如下:1.max_samples(最大样本数)定义:限制每个数据集最多使用多少条数据。作用:控制总共参与训练的数据量,减少max_samples可以加快训练速度。你的代码示例:max_samples=300#每个数据集最多用300条样本解释:假设你的dataset里包含:identity数据集有10,000条数据alpaca_en_demo数
- llama源码学习·model.py[1]RMSNorm归一化
小杜不吃糖
llamapython
一、model.py中的RMSNorm源码classRMSNorm(torch.nn.Module):def__init__(self,dim:int,eps:float=1e-6):super().__init__()self.eps=epsself.weight=nn.Parameter(torch.ones(dim))def_norm(self,x):returnx*torch.rsqrt(
- scaled_dot_product_attention实现逻辑
凤梧长宜放眼量
人工智能深度学习计算机视觉
torch.nn.functional.scaled_dot_product_attention(query,key,value,attn_mask=None,dropout_p=0.0,is_causal=False,scale=None,enable_gqa=False)->Tensor:参数:query(Tensor)–Querytensor;shape(batch_size,...,hea
- 【PyTorch】PyTorch 中改变张量形状的几种方法
shengchao0920
pytorch人工智能python
PyTorch中改变张量形状的几种方法在深度学习领域,PyTorch是一个广泛使用的框架,它提供了丰富的API来处理张量(tensor)。在模型开发过程中,我们经常需要改变张量的形状以满足特定的需求。本文将介绍在PyTorch中改变张量形状的几种方法,并给出推荐的使用场景。比如:我们想合并一个张量的最后两个维度。一、方法1.使用reshape方法reshape方法可以改变张量的形状而不改变其数据。
- PyTorch 中的维度操作详解
萝卜小白
pytorch人工智能python
在PyTorch中,维度(dimension)是描述张量形状的一种方式。维度操作是PyTorch中非常重要的功能,常用于调整张量的形状以适配各种计算需求。以下是常见的维度操作及其示例。1.维度的概念回顾一个二维张量(矩阵)的形状是(行数,列数)。一个三维张量的形状是(深度,行数,列数)。维度的索引从0开始,最外层是axis=0,向内依次递增。2.维度的操作(1)求和(Sum)sum(dim)的作用
- torch.logical_and()方法
CodeWang_NC
pytorch深度学习python
torch.logical_and()计算给定输入张量的元素逻辑AND。零被视为False,非零被视为True官方文档说明:https://pytorch.org/docs/stable/generated/torch.logical_and.html#torch.logical_andtorch.logical_and(input,other,*,out=None)→返回张量input(张量)–
- [Pytorch] Error:module ‘torch‘ has no attribute ‘logical_and‘
江南蜡笔小新
杂记pytorch深度学习神经网络
最近学习的模型用到了这个逻辑与的操作,Pytorch1.3.x报错。查阅官方文档,只有logical_not和logical_xor的实现。但在1.9的文档中有logical_and遂查阅相关更新,得知logical_and在1.5之后的新功能,pytorch更新到>=1.5即可解决问题。1.3.1搜索结果1.5.1搜索结果
- Orin NX 安装Jetpack 6.2 及部署pytorch tips
MYVision_ MY视界
Pythonpytorch人工智能python
刷机tips:刷完系统之后,如果需要安装其它软件,这个时候不需要跳线,然后输入真实的IP,确保你的x86ubuntu能ping通OrinNX.其它安装环境时遇到的问题如下:1.GPUenable=False-installtorch-2.3.0-cp310-cp310-linux_aarch64.whl2.ImportError:/home/platform/miniconda3/envs/cel
- 一文讲清楚CUDA与PyTorch、GPU之间的关系
平凡而伟大.
编程语言人工智能架构设计pytorch人工智能python
CUDA(ComputeUnifiedDeviceArchitecture)是由NVIDIA开发的一个并行计算平台和编程模型。它允许软件开发人员和研究人员利用NVIDIA的GPU(图形处理单元)进行高性能计算。CUDA提供了一系列API和工具,使得开发者能够编写和优化在GPU上运行的计算密集型任务。CUDA与PyTorch、GPU之间的关系可以这样理解:1.CUDA与GPU:GPU:是一种专门用于
- 【eNSP实战】基本ACL实现网络安全
敲键盘的Q
网络
拓扑图要求:PC3不允许访问其他PC和Server1PC2允许访问Server1服务器,不允许其他PC访问各设备IP配置如图所示,这里不做展示AR1接口vlan配置vlanbatch102030#interfaceVlanif10ipaddress192.168.1.254255.255.255.0#interfaceVlanif20ipaddress192.168.2.254255.255.25
- 【Transformer-Hugging Face手册 07/10】 微调预训练模型
无水先生
人工智能高级阶段人工智能综合transformer深度学习人工智能
微调预训练模型-目录一、说明二、在本机PyTorch中微调预训练模型。2.1加载数据2.2训练2.2.1使用PyTorchTrainer进行训练2.3训练超参数2.4评价2.5训练类三、使用Keras训练TensorFlow模型3.1为Keras加载数据3.2将数据加载为tf.data.Dataset3.3数据加载器3.4优化器和学习率调度器3.5训练循环3.6评价四、结论一、说明 使用预训练模
- 草根版外卖避雷计划「数据库寄生 2.0」优化方案
cainiaojunshi
预算方案智慧城市
接上回计划省钱版【打败美团和饿了吗的机会越来越大了!#外卖避雷计划#】[特殊字符][特殊字符]-CSDN博客(含三端流程图+预算穿透表+风险应对)一、策划目标(草根版核心)实现单城外卖后厨监督轻量化:✅创作端:骑手/打假人扫码接单,视频自动同步(省90%录入时间)✅服务端:AI+算法自动跑批,日省2小时人工干预(年省2.22万)✅观看端:实时暴雷指数+悬赏助力,用户信任度提升40%✅终极目标:单城
- Development Problems Based On PyTorch
woxiwangxuehaocpp
pytorch深度学习人工智能
问题解决RuntimeError:unabletowritetofile:Nospaceleftondevice(28)问题描述:Traceback(mostrecentcalllast):File"/opt/conda/lib/python3.10/multiprocessing/queues.py",line244,in_feedobj=_ForkingPickler.dumps(obj)Fi
- Pycharm中import torch报错解决方案(Python+Pycharm+Pytorch cpu版)
波波仔86
人工智能pythonpycharmpytorchimport解释器配置
pycharm环境搭建完毕后,编写一个py文件demo,importtorch报错,提示没有。设置python解释器:选择conda环境,使用现有环境,conda执行文件找到Anaconda安装路径下Scripts文件夹内的conda.exe,最后选择含有torch软件包的虚拟环境,题主创建名为pytorch。创建完解释器后,下方会显示出该解释器/虚拟环境下的所有软件包,看到有pytorch包即选
- 【python error】cannot import name ‘TorchDispatchMode‘ from ‘torch.utils._python_dispatch‘
Eternal-Student
JetsonOrinNXPythonpython开发语言
报错:cannotimportname‘TorchDispatchMode’from‘torch.utils._python_dispatch’(/home/nvidia/.conda/envs/pytorch/lib/python3.8/site-packages/torch/utils/_python_dispatch.py)File“/media/nvidia/Ubuntu/xxxxx/ev
- 梯度下降法以及随机梯度下降法
HKkuaidou
人工智能深度学习pythonpytorch
梯度下降法就是在更新weight的时候,向函数值下降的最快方向进行更新,具体的原理我就不再写了,就是一个求偏导的过程,有高数基础的都能够很快的理解过程。我在我的github里面会一直更新自己学习pytorch的过程,地址为:https://github.com/00paning/Pytorch_Learning这里我直接展示一个简易实现的python代码,我们还是先看一下运行的效果图:相关pyth
- pytorch实现cifar10多分类总结
L_pyu
人工智能pytorch分类
cifar-10简介:CIFAR-10是一个常用的图像分类数据集,每张图片都是3×32×32,3通道彩色图片,分辨率32×32。它包含了10个不同类别,每个类别有6000张图像,其中5000张用于训练,1000张用于测试。这10个类别分别为:飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。CIFAR-10分类任务是将这些图像正确地分类到它们所属的类别中。对于这个任务,可以使用深度学习模型,如卷积
- 【PyTorch】torch.nn.functional.log_softmax() 函数:计算 log(softmax),用于多分类任务
彬彬侠
PyTorch基础log_softmax多分类交叉熵损失分类pytorchpython深度学习
torch.nn.functional.log_softmaxtorch.nn.functional.log_softmax是PyTorch提供的用于计算log(softmax)的函数,通常用于多分类任务和计算交叉熵损失,可以提高数值稳定性并防止数值溢出。1.log_softmax的数学公式对于输入张量XXX,softmax计算如下:softmax(Xi)=eXi∑jeXj\text{softma
- 【PyTorch】torch.nn.functional.cross_entropy() 函数:分类任务的交叉熵损失函数
彬彬侠
PyTorch基础cross_entropy交叉熵损失函数分类pytorchpython深度学习
torch.nn.functional.cross_entropytorch.nn.functional.cross_entropy是PyTorch中用于分类任务的交叉熵损失函数,用于衡量预测概率分布与真实类别分布之间的差异,常用于多分类任务(multi-classclassification)。1.交叉熵损失的数学公式对于单个样本,交叉熵损失的计算公式为:L=−∑i=1Cyilog(yi^)\
- 图神经网络学习笔记—高级小批量处理(专题十四)
AI专题精讲
图神经网络入门到精通人工智能
小批量(mini-batch)的创建对于让深度学习模型的训练扩展到海量数据至关重要。与逐条处理样本不同,小批量将一组样本组合成一个统一的表示形式,从而可以高效地并行处理。在图像或语言领域,这一过程通常通过将每个样本缩放或填充为相同大小的形状来实现,然后将样本在一个额外的维度中分组。该维度的长度等于小批量中分组的样本数量,通常称为batch_size。由于图是能够容纳任意数量节点或边的最通用的数据结
- 每天五分钟玩转深度学习PyTorch:基于GoogLeNet完成CAFIR10分类
每天五分钟玩转人工智能
深度学习框架pytorch深度学习pytorch分类GoogLeNet人工智能CAFIR10
本文重点前面我们终于使用pytorch搭建了GoogLeNet,本文我们使用该网络模型解决一个实际问题,也就是使用它完成CAFIR10分类,其实就这些任务而言,我们只要搭建好模型,然后把数据喂进去就行了,其它的地方都是一样的,就是网络模型不一样。代码
- Batch Normalization理解
zhimengxiang
图像处理人工智能图像处理
BatchNormalization理解BatchNormalization:批归一化我们在图像预处理过程中通常会对图像进行标准化处理,这样能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的featuremap就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个featuremap的数据要满足分布规律,理论上是指整个训练
- 深度学习项目--基于DenseNet网络的“乳腺癌图像识别”,准确率90%+,pytorch复现
羊小猪~~
深度学习网络pytorch人工智能python机器学习分类
本文为365天深度学习训练营中的学习记录博客原作者:K同学啊前言如果说最经典的神经网络,ResNet肯定是一个,从ResNet发布后,很多人做了修改,denseNet网络无疑是最成功的一个,它采用密集型连接,将通道数连接在一起;本文是基于上一篇复现DenseNet121模型,做一个乳腺癌图像识别,效果还行,准确率0.9+;CNN经典网络之“DenseNet”简介,源码研究与复现(pytorch):
- PyTorch 深度学习实战(13):Proximal Policy Optimization (PPO) 算法
进取星辰
PyTorch深度学习实战深度学习pytorch算法
在上一篇文章中,我们介绍了Actor-Critic算法,并使用它解决了CartPole问题。本文将深入探讨ProximalPolicyOptimization(PPO)算法,这是一种更稳定、更高效的策略优化方法。我们将使用PyTorch实现PPO算法,并应用于经典的CartPole问题。一、PPO算法基础PPO是OpenAI提出的一种强化学习算法,旨在解决策略梯度方法中的训练不稳定问题。PPO通过
- 机器学习(二) 本文(2.5万字) | KNN算法原理及Python复现 |
小酒馆燃着灯
机器学习算法k近邻算法
文章目录一KNN算法原理二KNN三要素三机器学习中标准化四KNN分类预测规则五KNN回归预测规则六KNN算法实现方式七KDTree7.1构造KDtree7.2KDtree查找最近邻八KNN特点九KNN算法实现案例一案例二1.机器学习2.深度学习与目标检测3.YOLOv54.YOLOv5改进5.YOLOv8及其改进6.Python与PyTorch7.工具8.小知识点9.杂记一KNN算法原理K近邻分类
- 【大模型LLM面试合集】分布式训练_总结
X.AI666
大模型LLM面试合集面试分布式人工智能语言模型
9.总结1.数据并行数据并行,由于其原理相对比较简单,是目前使用最广泛的分布式并行技术。数据并行不仅仅指对训练的数据并行操作,还可以对网络模型梯度、权重参数、优化器状态等数据进行并行。我们首先以PyTorch数据并行的发展(DataParallel、DistributedDataParallel、FullyShardedDataParallel)为主线进行讲述了数据并行的技术原理。同时,也简述了D
- 【vLLM 学习】使用 TPU 安装
HyperAI超神经
vLLM学习人工智能vLLM深度学习TPU机器学习教程
vLLM是一款专为大语言模型推理加速而设计的框架,实现了KV缓存内存几乎零浪费,解决了内存管理瓶颈问题。更多vLLM中文文档及教程可访问→https://vllm.hyper.ai/vLLM使用PyTorchXLA支持GoogleCloudTPU。依赖环境GoogleCloudTPUVM(单主机和多主机)TPU版本:v5e、v5p、v4Python:3.10安装选项:href=“https://v
- 从LayerNorm到RMSNorm:深度学习归一化技术的进化!qwen2.5的技术。
KangkangLoveNLP
qwen2.5深度学习人工智能transformerpytorch自然语言处理python神经网络
RMSNorm(RootMeanSquareNormalization,均方根归一化)是一种用于深度学习的归一化技术,是LayerNorm(层归一化)的一种改进。它通过计算输入数据的均方根(RootMeanSquare,RMS)来进行归一化,避免了传统归一化方法中均值和方差的计算1.LayerNorm(层归一化)LayerNorm(层归一化)是一种用于深度学习的归一化技术,主要用于稳定训练过程、加
- 十种处理权重矩阵的方法及数学公式
阳光明媚大男孩
矩阵机器学习线性代数
1.权重归一化(WeightNormalization)目的:通过分离权重向量的范数和方向来加速训练。公式:对于权重向量w\mathbf{w}w,归一化后的权重w′\mathbf{w}'w′为:w′=w∥w∥\mathbf{w}'=\frac{\mathbf{w}}{\|\mathbf{w}\|}w′=∥w∥w其中∥w∥\|\mathbf{w}\|∥w∥是w\mathbf{w}w的欧几里得范数。2
- 上万个Map运行时链接ApplicationMaster超时FAILED
500佰
大数据云计算bigdatamapreduce
#MapReduce业务常见故障#大数据#生产环境真实案例#MapReduce#批计算#离线业务#整理#经验总结说明:此篇总结MapReduce业务常见故障案例处理方案结合自身经历总结不易+关注+收藏欢迎留言更多专题(详见):MapReduce计算引擎详解--项目优化(指导书)上万个Map运行时链接ApplicationMaster超时FAILED症状Mapreduce任务会并发起几万个map,会
- JAVA中的Enum
周凡杨
javaenum枚举
Enum是计算机编程语言中的一种数据类型---枚举类型。 在实际问题中,有些变量的取值被限定在一个有限的范围内。 例如,一个星期内只有七天 我们通常这样实现上面的定义:
public String monday;
public String tuesday;
public String wensday;
public String thursday
- 赶集网mysql开发36条军规
Bill_chen
mysql业务架构设计mysql调优mysql性能优化
(一)核心军规 (1)不在数据库做运算 cpu计算务必移至业务层; (2)控制单表数据量 int型不超过1000w,含char则不超过500w; 合理分表; 限制单库表数量在300以内; (3)控制列数量 字段少而精,字段数建议在20以内
- Shell test命令
daizj
shell字符串test数字文件比较
Shell test命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。 数值测试 参数 说明 -eq 等于则为真 -ne 不等于则为真 -gt 大于则为真 -ge 大于等于则为真 -lt 小于则为真 -le 小于等于则为真
实例演示:
num1=100
num2=100if test $[num1]
- XFire框架实现WebService(二)
周凡杨
javawebservice
有了XFire框架实现WebService(一),就可以继续开发WebService的简单应用。
Webservice的服务端(WEB工程):
两个java bean类:
Course.java
package cn.com.bean;
public class Course {
private
- 重绘之画图板
朱辉辉33
画图板
上次博客讲的五子棋重绘比较简单,因为只要在重写系统重绘方法paint()时加入棋盘和棋子的绘制。这次我想说说画图板的重绘。
画图板重绘难在需要重绘的类型很多,比如说里面有矩形,园,直线之类的,所以我们要想办法将里面的图形加入一个队列中,这样在重绘时就
- Java的IO流
西蜀石兰
java
刚学Java的IO流时,被各种inputStream流弄的很迷糊,看老罗视频时说想象成插在文件上的一根管道,当初听时觉得自己很明白,可到自己用时,有不知道怎么代码了。。。
每当遇到这种问题时,我习惯性的从头开始理逻辑,会问自己一些很简单的问题,把这些简单的问题想明白了,再看代码时才不会迷糊。
IO流作用是什么?
答:实现对文件的读写,这里的文件是广义的;
Java如何实现程序到文件
- No matching PlatformTransactionManager bean found for qualifier 'add' - neither
林鹤霄
java.lang.IllegalStateException: No matching PlatformTransactionManager bean found for qualifier 'add' - neither qualifier match nor bean name match!
网上找了好多的资料没能解决,后来发现:项目中使用的是xml配置的方式配置事务,但是
- Row size too large (> 8126). Changing some columns to TEXT or BLOB
aigo
column
原文:http://stackoverflow.com/questions/15585602/change-limit-for-mysql-row-size-too-large
异常信息:
Row size too large (> 8126). Changing some columns to TEXT or BLOB or using ROW_FORMAT=DYNAM
- JS 格式化时间
alxw4616
JavaScript
/**
* 格式化时间 2013/6/13 by 半仙
[email protected]
* 需要 pad 函数
* 接收可用的时间值.
* 返回替换时间占位符后的字符串
*
* 时间占位符:年 Y 月 M 日 D 小时 h 分 m 秒 s 重复次数表示占位数
* 如 YYYY 4占4位 YY 占2位<p></p>
* MM DD hh mm
- 队列中数据的移除问题
百合不是茶
队列移除
队列的移除一般都是使用的remov();都可以移除的,但是在昨天做线程移除的时候出现了点问题,没有将遍历出来的全部移除, 代码如下;
//
package com.Thread0715.com;
import java.util.ArrayList;
public class Threa
- Runnable接口使用实例
bijian1013
javathreadRunnablejava多线程
Runnable接口
a. 该接口只有一个方法:public void run();
b. 实现该接口的类必须覆盖该run方法
c. 实现了Runnable接口的类并不具有任何天
- oracle里的extend详解
bijian1013
oracle数据库extend
扩展已知的数组空间,例:
DECLARE
TYPE CourseList IS TABLE OF VARCHAR2(10);
courses CourseList;
BEGIN
-- 初始化数组元素,大小为3
courses := CourseList('Biol 4412 ', 'Psyc 3112 ', 'Anth 3001 ');
--
- 【httpclient】httpclient发送表单POST请求
bit1129
httpclient
浏览器Form Post请求
浏览器可以通过提交表单的方式向服务器发起POST请求,这种形式的POST请求不同于一般的POST请求
1. 一般的POST请求,将请求数据放置于请求体中,服务器端以二进制流的方式读取数据,HttpServletRequest.getInputStream()。这种方式的请求可以处理任意数据形式的POST请求,比如请求数据是字符串或者是二进制数据
2. Form
- 【Hive十三】Hive读写Avro格式的数据
bit1129
hive
1. 原始数据
hive> select * from word;
OK
1 MSN
10 QQ
100 Gtalk
1000 Skype
2. 创建avro格式的数据表
hive> CREATE TABLE avro_table(age INT, name STRING)STORE
- nginx+lua+redis自动识别封解禁频繁访问IP
ronin47
在站点遇到攻击且无明显攻击特征,造成站点访问慢,nginx不断返回502等错误时,可利用nginx+lua+redis实现在指定的时间段 内,若单IP的请求量达到指定的数量后对该IP进行封禁,nginx返回403禁止访问。利用redis的expire命令设置封禁IP的过期时间达到在 指定的封禁时间后实行自动解封的目的。
一、安装环境:
CentOS x64 release 6.4(Fin
- java-二叉树的遍历-先序、中序、后序(递归和非递归)、层次遍历
bylijinnan
java
import java.util.LinkedList;
import java.util.List;
import java.util.Stack;
public class BinTreeTraverse {
//private int[] array={ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
private int[] array={ 10,6,
- Spring源码学习-XML 配置方式的IoC容器启动过程分析
bylijinnan
javaspringIOC
以FileSystemXmlApplicationContext为例,把Spring IoC容器的初始化流程走一遍:
ApplicationContext context = new FileSystemXmlApplicationContext
("C:/Users/ZARA/workspace/HelloSpring/src/Beans.xml&q
- [科研与项目]民营企业请慎重参与军事科技工程
comsci
企业
军事科研工程和项目 并非要用最先进,最时髦的技术,而是要做到“万无一失”
而民营科技企业在搞科技创新工程的时候,往往考虑的是技术的先进性,而对先进技术带来的风险考虑得不够,在今天提倡军民融合发展的大环境下,这种“万无一失”和“时髦性”的矛盾会日益凸显。。。。。。所以请大家在参与任何重大的军事和政府项目之前,对
- spring 定时器-两种方式
cuityang
springquartz定时器
方式一:
间隔一定时间 运行
<bean id="updateSessionIdTask" class="com.yang.iprms.common.UpdateSessionTask" autowire="byName" />
<bean id="updateSessionIdSchedule
- 简述一下关于BroadView站点的相关设计
damoqiongqiu
view
终于弄上线了,累趴,戳这里http://www.broadview.com.cn
简述一下相关的技术点
前端:jQuery+BootStrap3.2+HandleBars,全站Ajax(貌似对SEO的影响很大啊!怎么破?),用Grunt对全部JS做了压缩处理,对部分JS和CSS做了合并(模块间存在很多依赖,全部合并比较繁琐,待完善)。
后端:U
- 运维 PHP问题汇总
dcj3sjt126com
windows2003
1、Dede(织梦)发表文章时,内容自动添加关键字显示空白页
解决方法:
后台>系统>系统基本参数>核心设置>关键字替换(是/否),这里选择“是”。
后台>系统>系统基本参数>其他选项>自动提取关键字,这里选择“是”。
2、解决PHP168超级管理员上传图片提示你的空间不足
网站是用PHP168做的,反映使用管理员在后台无法
- mac 下 安装php扩展 - mcrypt
dcj3sjt126com
PHP
MCrypt是一个功能强大的加密算法扩展库,它包括有22种算法,phpMyAdmin依赖这个PHP扩展,具体如下:
下载并解压libmcrypt-2.5.8.tar.gz。
在终端执行如下命令: tar zxvf libmcrypt-2.5.8.tar.gz cd libmcrypt-2.5.8/ ./configure --disable-posix-threads --
- MongoDB更新文档 [四]
eksliang
mongodbMongodb更新文档
MongoDB更新文档
转载请出自出处:http://eksliang.iteye.com/blog/2174104
MongoDB对文档的CURD,前面的博客简单介绍了,但是对文档更新篇幅比较大,所以这里单独拿出来。
语法结构如下:
db.collection.update( criteria, objNew, upsert, multi)
参数含义 参数
- Linux下的解压,移除,复制,查看tomcat命令
y806839048
tomcat
重复myeclipse生成webservice有问题删除以前的,干净
1、先切换到:cd usr/local/tomcat5/logs
2、tail -f catalina.out
3、这样运行时就可以实时查看运行日志了
Ctrl+c 是退出tail命令。
有问题不明的先注掉
cp /opt/tomcat-6.0.44/webapps/g
- Spring之使用事务缘由(3-XML实现)
ihuning
spring
用事务通知声明式地管理事务
事务管理是一种横切关注点。为了在 Spring 2.x 中启用声明式事务管理,可以通过 tx Schema 中定义的 <tx:advice> 元素声明事务通知,为此必须事先将这个 Schema 定义添加到 <beans> 根元素中去。声明了事务通知后,就需要将它与切入点关联起来。由于事务通知是在 <aop:
- GCD使用经验与技巧浅谈
啸笑天
GC
前言
GCD(Grand Central Dispatch)可以说是Mac、iOS开发中的一大“利器”,本文就总结一些有关使用GCD的经验与技巧。
dispatch_once_t必须是全局或static变量
这一条算是“老生常谈”了,但我认为还是有必要强调一次,毕竟非全局或非static的dispatch_once_t变量在使用时会导致非常不好排查的bug,正确的如下: 1
- linux(Ubuntu)下常用命令备忘录1
macroli
linux工作ubuntu
在使用下面的命令是可以通过--help来获取更多的信息1,查询当前目录文件列表:ls
ls命令默认状态下将按首字母升序列出你当前文件夹下面的所有内容,但这样直接运行所得到的信息也是比较少的,通常它可以结合以下这些参数运行以查询更多的信息:
ls / 显示/.下的所有文件和目录
ls -l 给出文件或者文件夹的详细信息
ls -a 显示所有文件,包括隐藏文
- nodejs同步操作mysql
qiaolevip
学习永无止境每天进步一点点mysqlnodejs
// db-util.js
var mysql = require('mysql');
var pool = mysql.createPool({
connectionLimit : 10,
host: 'localhost',
user: 'root',
password: '',
database: 'test',
port: 3306
});
- 一起学Hive系列文章
superlxw1234
hiveHive入门
[一起学Hive]系列文章 目录贴,入门Hive,持续更新中。
[一起学Hive]之一—Hive概述,Hive是什么
[一起学Hive]之二—Hive函数大全-完整版
[一起学Hive]之三—Hive中的数据库(Database)和表(Table)
[一起学Hive]之四-Hive的安装配置
[一起学Hive]之五-Hive的视图和分区
[一起学Hive
- Spring开发利器:Spring Tool Suite 3.7.0 发布
wiselyman
spring
Spring Tool Suite(简称STS)是基于Eclipse,专门针对Spring开发者提供大量的便捷功能的优秀开发工具。
在3.7.0版本主要做了如下的更新:
将eclipse版本更新至Eclipse Mars 4.5 GA
Spring Boot(JavaEE开发的颠覆者集大成者,推荐大家学习)的配置语言YAML编辑器的支持(包含自动提示,
 和
和 ,否则不包含这两个变量,变量名是weight和bias,详情见下文。
,否则不包含这两个变量,变量名是weight和bias,详情见下文。![E[x]](http://img.e-com-net.com/image/info8/4258d3def055440bace942b6e67749a4.gif) 和
和![Var[x]](http://img.e-com-net.com/image/info8/4d7e3df6576a430bbca7c4b8df2fc25a.gif) ,并用这两个结果把batch归一化,使其均值为0,方差为1。归一化公式用到了eps(
,并用这两个结果把batch归一化,使其均值为0,方差为1。归一化公式用到了eps( ),即
),即![y=\frac{x-E[x]}{\sqrt{Var[x]+\epsilon }}](http://img.e-com-net.com/image/info8/0741143f3a854dc0869acdb3df4c9647.gif) 。如下输入内容,shape是(3, 4),即batch_size=3,此时num_features需要传入4。
。如下输入内容,shape是(3, 4),即batch_size=3,此时num_features需要传入4。 ![E[x]=[3, 3, 4, 2]](http://img.e-com-net.com/image/info8/880fc980914e4e65af42b02a7392a8a8.gif) ,
,![Var[y]_{unbiased}=[7, 1, 4, 3]](http://img.e-com-net.com/image/info8/9117b6a9a9eb4faa8a464424539755ed.gif) (无偏样本方差)和
(无偏样本方差)和![Var[y]_{biased}=[4.6667, 0.6667, 2.6667, 2.0000]](http://img.e-com-net.com/image/info8/84c6b1ad2ecb41c3888e44dc2409153a.gif) (有偏样本方差),有偏和无偏的区别在于无偏的分母是N-1,有偏的分母是N。注意在BatchNorm中,用于更新running_var时,使用无偏样本方差即,但是在对batch进行归一化时,使用有偏样本方差,因此如果batch_size=1,会报错。归一化后的内容如下。
(有偏样本方差),有偏和无偏的区别在于无偏的分母是N-1,有偏的分母是N。注意在BatchNorm中,用于更新running_var时,使用无偏样本方差即,但是在对batch进行归一化时,使用有偏样本方差,因此如果batch_size=1,会报错。归一化后的内容如下。 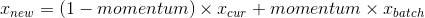 ,其中
,其中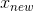 代表更新后的running_mean和running_var,
代表更新后的running_mean和running_var,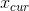 表示更新前的running_mean和running_var,
表示更新前的running_mean和running_var,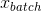 表示当前batch的均值和无偏样本方差。
表示当前batch的均值和无偏样本方差。![y=\frac{x-\hat{E}[x]}{\sqrt{\hat{Var}[x]+\epsilon }}](http://img.e-com-net.com/image/info8/3a2cafbce59e4c58bad68da102a82f84.gif) ,注意这里的均值和方差是running_mean和running_var,在网络训练时统计出来的全局均值和无偏样本方差。
,注意这里的均值和方差是running_mean和running_var,在网络训练时统计出来的全局均值和无偏样本方差。![y=\frac{x-{E}[x]}{\sqrt{{Var}[x]+\epsilon }}](http://img.e-com-net.com/image/info8/4295306ea3514a2da19daf527aa72273.gif) ,注意这里的均值和方差是batch自己的mean和var,此时BatchNorm里不含有running_mean和running_var。注意此时使用的是无偏样本方差(和训练时不同),因此如果batch_size=1,会使分母为0,就报错了。
,注意这里的均值和方差是batch自己的mean和var,此时BatchNorm里不含有running_mean和running_var。注意此时使用的是无偏样本方差(和训练时不同),因此如果batch_size=1,会使分母为0,就报错了。