运用scikit-learn库进行聚类分析
运用scikit-learn库进行聚类分析
-
-
- 一、 k-means聚类算法
-
- (一)k-means算法
- (二)使用肘方法确定簇的最佳数量
- (三)使用轮廓图定量分析聚类质量
- 二、层次聚类
-
- (一) 普通层次聚类步骤
- (二)通过scikit-learn 进行层次分析
- 三、 使用DBSCAN(基于空间密度的聚类算法)划分高密度区域
-
聚类分析常用的方法有 k-means聚类算法、 层次聚类算法、DBSCAN(基于空间密度的聚类算法)等,本文就这三种方法对聚类分析进行简单介绍。
一、 k-means聚类算法
(一)k-means算法
# 创建数据集
from sklearn.datasets import make_blobs
# n_features = 2设置X特征数量
X,y = make_blobs(n_samples = 150, n_features = 2, centers = 3, cluster_std = 0.5, shuffle = True, random_state = 0)
import matplotlib.pyplot as plt
# 使文字可以展示
plt.rcParams['font.sans-serif'] = ['SimHei']
# 使负号可以展示
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(X[:,0], X[:,1], c = 'blue', marker = 'o', s = 50)
plt.grid()
plt.show()
# 使用k-means进行聚类
from sklearn.cluster import KMeans
# tol = 1e-04设置容忍度
# n_clusters = 3设置的簇的数量
km = KMeans(n_clusters = 3, init = 'random',n_init = 10, max_iter = 300, tol = 1e-04, random_state = 0)
y_km = km.fit_predict(X)
# k-means++进行聚类
plt.scatter(X[y_km == 0, 0], X[y_km == 0, 1], s = 50, c = 'lightgreen', marker = 's', label = '簇 1')
plt.scatter(X[y_km == 1, 0], X[y_km == 1, 1], s = 50, c = 'orange', marker = 'o', label = '簇 2')
plt.scatter(X[y_km == 2, 0], X[y_km == 2, 1], s = 50, c = 'lightblue', marker = 'v', label = '簇 3')
plt.scatter(km.cluster_centers_[:,0], km.cluster_centers_[:,1], s = 250, marker = '*', c = 'red', label = '中心点')
plt.legend()
plt.grid()
plt.show()

(二)使用肘方法确定簇的最佳数量
distortions = []
for i in range(1,11):
km = KMeans(n_clusters = i, init = 'k-means++', n_init = 10, max_iter = 300, random_state = 0)
km.fit(X)
# km.inertia_ 获取每次聚类后误差
distortions.append(km.inertia_)
plt.plot(range(1,11), distortions, marker = 'o')
plt.xlabel('簇数量')
plt.ylabel('误差')
plt.show()

(三)使用轮廓图定量分析聚类质量
km = KMeans(n_clusters = 3, init = 'k-means++', n_init = 10, max_iter = 300, tol = 1e-04, random_state = 0)
y_km = km.fit_predict(X)
import numpy as np
from matplotlib import cm
# 导入轮廓库
from sklearn.metrics import silhouette_samples
cluster_labels = np.unique(y_km)
n_clusters = cluster_labels.shape[0]
silhouette_vals = silhouette_samples(X, y_km, metric = 'euclidean')
y_ax_lower, y_ax_upper = 0,0
yticks = []
for i, c in enumerate(cluster_labels):
c_silhouette_vals = silhouette_vals[y_km==c]
c_silhouette_vals.sort()
y_ax_upper += len(c_silhouette_vals)
color = cm.jet(i / n_clusters)
plt.barh(range(y_ax_lower, y_ax_upper), c_silhouette_vals, height=1.0,
edgecolor='none', color=color)
yticks.append((y_ax_lower + y_ax_upper) / 2)
y_ax_lower += len(c_silhouette_vals)
silhouette_avg = np.mean(silhouette_vals)
plt.axvline(silhouette_avg, color="red", linestyle="--")
plt.yticks(yticks, cluster_labels + 1)
plt.ylabel('簇')
plt.xlabel('轮廓系数')
plt.show()

二、层次聚类
(一) 普通层次聚类步骤
# 创建样本
import pandas as pd
import numpy as np
np.random.seed(123)
variables = ['X', 'Y', 'Z']
labels = ['ID_0', 'ID_1', 'ID_2', 'ID_3', 'ID_4']
X = np.random.random_sample([5,3])*10
df = pd.DataFrame(X, columns = variables, index = labels)
df

# 基于距离矩阵进行层次聚类
from scipy.spatial.distance import pdist, squareform
row_dist = pd.DataFrame(squareform(pdist(df, metric = 'euclidean')), columns = labels, index = labels)
row_dist

# 聚类正确的方式-1
from scipy.cluster.hierarchy import linkage
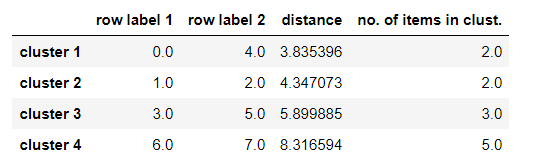
row_clusters = linkage(pdist(df, metric='euclidean'), method='complete')
pd.DataFrame(row_clusters,
columns=['row label 1', 'row label 2', 'distance', 'no. of items in clust.'],
index=['cluster %d' %(i+1) for i in range(row_clusters.shape[0])])
# 聚类正确的方式-2
row_clusters = linkage(df.values, method='complete', metric='euclidean')
pd.DataFrame(row_clusters,
columns=['row label 1', 'row label 2', 'distance', 'no. of items in clust.'],
index=['cluster %d' %(i+1) for i in range(row_clusters.shape[0])])

# 画树形图
from scipy.cluster.hierarchy import dendrogram
# make dendrogram black (part 1/2)
# from scipy.cluster.hierarchy import set_link_color_palette
# set_link_color_palette(['black'])
row_dendr = dendrogram(row_clusters,
labels=labels,
# make dendrogram black (part 2/2)
# color_threshold=np.inf
)
plt.ylabel('欧氏距离')
plt.show()

# 树状图与热力图关联
# 画树状图
fig = plt.figure(figsize = (8,8))
# 两个图形之间的距离(宽和高)、图形本身宽和高
axd = fig.add_axes([0.09, 0.1, 0.2, 0.6])
row_dendr = dendrogram(row_clusters, orientation = 'left')
# 重新排列数据
df_rowclust = df.ix[row_dendr['leaves'][::-1]]
# 画热力图
axm =fig.add_axes([0.23, 0.1, 0.6, 0.6])
cax = axm.matshow(df_rowclust, interpolation = 'nearest', cmap = 'hot_r')
# # 移除树状图的轴
axd.set_xticks([])
axd.set_yticks([])
for i in axd.spines.values():
i.set_visible(False)
# 加上颜色棒
fig.colorbar(cax)
# 设置热力图坐标轴
axm.set_xticklabels([''] + list(df_rowclust.columns))
axm.set_yticklabels([''] + list(df_rowclust.index))
plt.show()

(二)通过scikit-learn 进行层次分析
from sklearn.cluster import AgglomerativeClustering
ac = AgglomerativeClustering(n_clusters = 2, affinity = 'euclidean', linkage = 'complete')
labels = ac.fit_predict(X)
print('Cluster labels: % s' % labels)
三、 使用DBSCAN(基于空间密度的聚类算法)划分高密度区域
# 创建月半形的数据集
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
# 可视化
plt.scatter(X[:,0], X[:,1])
plt.show()

# 比较k-means++聚类, 层次聚类 和 DBSCAN 的区别
# 设置图形
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(8,3))
# k_means++聚类
km = KMeans(n_clusters=2, random_state=0)
y_km = km.fit_predict(X)
# 可视化
ax1.scatter(X[y_km==0,0], X[y_km==0,1], c='lightblue', marker='o', s=40, label='簇 1')
ax1.scatter(X[y_km==1,0], X[y_km==1,1], c='red', marker='s', s=40, label='簇 2')
ax1.set_title('K-means 聚类')
# 层次聚类
ac = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='complete')
y_ac = ac.fit_predict(X)
# 可视化
ax2.scatter(X[y_ac==0,0], X[y_ac==0,1], c='lightblue', marker='o', s=40, label='簇 1')
ax2.scatter(X[y_ac==1,0], X[y_ac==1,1], c='red', marker='s', s=40, label='簇 2')
ax2.set_title('层次聚类')
plt.legend()
plt.show()

# DBSCAN聚类
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=0.2, min_samples=5, metric='euclidean')
y_db = db.fit_predict(X)
# 可视化
plt.scatter(X[y_db==0,0], X[y_db==0,1], c='lightblue', marker='o', s=40, label='簇 1')
plt.scatter(X[y_db==1,0], X[y_db==1,1], c='red', marker='s', s=40, label='簇 2')
plt.legend()
plt.show()
