Libtorch C++实现人像抠图——面向Windows(部署教程)
目录
一、环境安装
1.1 基本环境介绍
1.2 pth模型序列化导出转pt
1.2 下载libtorch
1.3 安装OpenCV
1.4 创建win32 C++控制台工程
二、完整推理代码
三、测试
一、环境安装
1.1 基本环境介绍
本文实验环境为windows10,IDE选择VS 2019,最终开发win32 C++程序,可以批量对人像照片进行抠图处理,无需用户干预。本文重点在于部署Pytorch训练好的pth模型,能够脱离python平台实现C++调用,完成真正的生产级部署。如何通过Pytorch训练人像抠图模型可以参考我的其它博客教程1、博客教程2。
1.2 pth模型序列化导出转pt
训练完模型以后可以得到pth模型,然后使用下面的python代码将其序列化导出(即将动态图转静态图):
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@文件 :pth2pt.py
@说明 :模型序列化导出,pth文件转pt文件
@时间 :2020/05/08 14:18:55
@作者 :钱彬
@版本 :1.0
'''
import torch.backends.cudnn as cudnn
import torch
from torch import nn
from model.shm import SHM
from utils import *
import time
import cv2
# 测试图像
img_id='16'
imgPath = './results/'+img_id+'.png'
# 模型参数
#device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
if __name__ == '__main__':
# 预训练模型
checkpoint = "./results/shm_temp.pth"
# 加载模型
checkpoint = torch.load(checkpoint)
model = SHM()
model = model.to(device)
model.load_state_dict(checkpoint['model'])
model.eval()
# 加载图像
img_org = cv2.imread(imgPath, cv2.IMREAD_COLOR)
width = img_org.shape[1]
height = img_org.shape[0]
# 图像预处理
img = cv2.resize(img_org, (320,320), interpolation = cv2.INTER_CUBIC)
img = (img.astype(np.float32) - (114., 121., 134.,)) / 255.0
h, w, c = img.shape
img = torch.from_numpy(img.transpose((2, 0, 1))).view(c, h, w).float()
img= img.view(1, 3, h, w)
# 转移数据至设备
img = img.to(device)
# 模型推理并序列化导出
with torch.no_grad():
alpha = model(img)
alpha = alpha.squeeze(0).float().mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()
traced_script_module = torch.jit.trace(model, img)
traced_script_module.save("./results/matting.pt")1.2 下载libtorch
在官网下载libtorch,由于后面我们需要使用GPU进行推理,因此下载对应cuda版本的libtorch。下载时尤其要注意版本一致问题,即最终的推理平台用的是哪个版本的cuda,那么这里也需要下载对应版本的cuda,本文下载cuda10.1对应的版本。具体如下图所示:

1.3 安装OpenCV
由于需要进行图像加载等操作,这里选择开源框架OpenCV实现。具体安装过程可以参考我的另一篇博客。本文使用opencv4.2版本。
1.4 创建win32 C++控制台工程
本文使用VS2019来创建C++工程,具体如下:
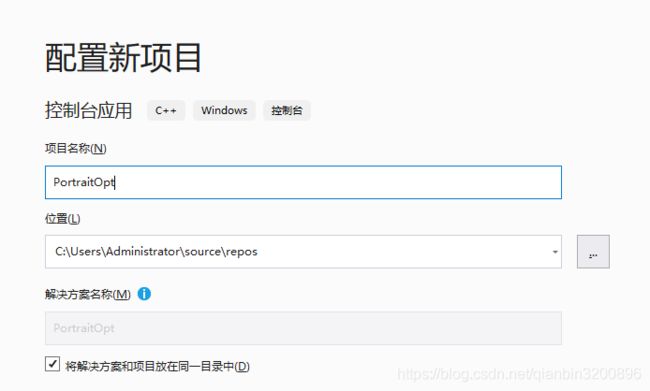
创建完成后切换成64位平台:

然后进行项目配置如下:
(1)属性配置——VC++目录

这里我将前面下载的libtorch放置在了本工程目录下,读者按照上面的路径然后结合自己的路劲进行对应的修改即可。
(2)属性配置——库目录
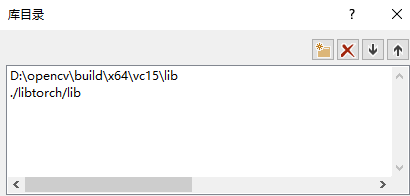
(3)链接器——输入
添加lib文件如下:
opencv_world420.lib
asmjit.lib
c10.lib
c10_cuda.lib
caffe2_detectron_ops_gpu.lib
caffe2_module_test_dynamic.lib
caffe2_nvrtc.lib
clog.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
gloo.lib
gloo_cuda.lib
libprotobuf.lib
libprotobuf-lite.lib
libprotoc.lib
mkldnn.lib
torch.lib
torch_cpu.lib
torch_cuda.lib这里我将libtorch中的所有lib文件全部包含了进入,实际使用时可以不用这么多,这里为了不出问题可以先全部包含进来,等后面程序调通了后再逐步删除。接下来将libtorch中的所有dll文件拷贝到项目根目录下即可。如下图所示:
最后很重要的一点,在高版本VS中有个bug,需要手动添加点东西我们的代码才能正常的调用GPU。找到链接器——命令行——其它选项,然后输入: /INCLUDE:?warp_size@cuda@at@@YAHXZ
具体如下图所示:
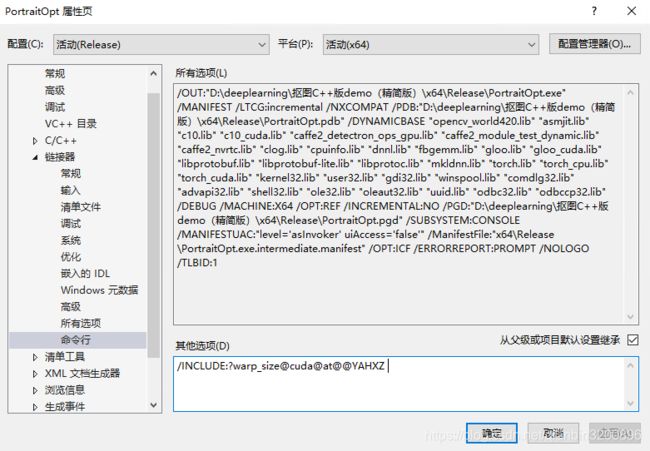
如果不实现上述操作我们的代码后面会无法调用GPU。
二、完整推理代码
完成前面的配置以后就可以进行代码编辑了,完整代码如下,主要实现端到端抠图:
/*********************************************************************************************************************************
* Copyright(c) 2020-2025
* All rights reserved.
*
* 文件名称:PortraitOpt
* 简要描述:基于C++实现证件人像抠图(GPU和CPU通用)
*
* 创建日期:2020-10-09
* 作者:钱彬
* 版本:V1.0.0
*********************************************************************************************************************************/
//导入深度学习torch库
#undef UNICODE
#include // 引入libtorch头文件
#include // cuda相关函数头文件
//导入系统库
#include
#include "time.h"
//导入opencv图像处理库
#include
#include
#include
#include
#include
#include
//定义命名空间
using namespace std;
using namespace cv;
int main()
{
//确定当前设备类型(CPU或GPU)
torch::DeviceType device_type = at::kCPU; // 定义设备类型
if (torch::cuda::is_available())
device_type = at::kCUDA;
// 加载抠图模型
torch::jit::script::Module model;
try {
model = torch::jit::load("matting.pt"); //加载模型
}
catch (const c10::Error& e) {
cout << "无法加载模型" << endl;
return 0;
}
model.eval();
model.to(device_type);
//查找文件夹中所有jpg格式图片
cv::String pattern = "imgs/*.jpg";
vector fn;
glob(pattern, fn, false);
vector images;
int imgNum = fn.size();
std::cout << "当前需要处理的图像总数: " << imgNum << endl;
//----------------------------------------------循环处理图片-------------------------------------------------
for (int picIndex = 0; picIndex < imgNum; picIndex++)
{
//读取图像
Mat img = imread(fn[picIndex]);
clock_t start, finish;
double duration;
char imgpath[256];
start = clock();
Mat orgimg = img.clone();
// 压缩图像
int org_width = img.cols;
int org_height = img.rows;
resize(img, img, Size(320, 320), 0, 0, INTER_CUBIC);
//数据预处理
std::vector sizes = { 1, img.rows, img.cols,3 };
at::TensorOptions options(at::ScalarType::Byte);
at::Tensor tensor_image = torch::from_blob(img.data, at::IntList(sizes), options);//将opencv的图像数据转为Tensor张量数据
tensor_image = tensor_image.toType(at::kFloat);//转为浮点型张量数据
tensor_image = tensor_image.permute({ 0, 3, 1, 2 });
tensor_image[0][0] = tensor_image[0][0].sub(114).div(255.0);
tensor_image[0][1] = tensor_image[0][1].sub(121).div(255.0);
tensor_image[0][2] = tensor_image[0][2].sub(134).div(255.0);
tensor_image = tensor_image.to(device_type);
// 推理
std::vector inputs;
inputs.push_back(tensor_image);
at::Tensor out_tensor = model.forward(inputs).toTensor();
out_tensor = out_tensor.squeeze().detach();
out_tensor = out_tensor.mul(255).add_(0.5).clamp_(0, 255).to(torch::kU8);
out_tensor = out_tensor.to(torch::kCPU);
cv::Mat alphaImg(img.rows, img.cols, CV_8UC1);
std::memcpy((void*)alphaImg.data, out_tensor.data_ptr(), sizeof(torch::kU8) * out_tensor.numel());
// 调整抠图结果大小
resize(alphaImg, alphaImg, Size(org_width, org_height), 0, 0, INTER_CUBIC);
// 与白背景合成
Mat bg(orgimg.size(), orgimg.type(), Scalar(255, 255, 255));//全白图
Mat alpha, comp;
cvtColor(alphaImg, alpha, COLOR_GRAY2BGR);
comp = orgimg.clone();
for (int i = 0; i < alpha.rows; i++)
for (int j = 0; j < alpha.cols; j++)
{
Vec3b alpha_p = alpha.at(i, j);
Vec3b bg_p = bg.at(i, j);
Vec3b img_p = orgimg.at(i, j);
if (alpha_p[0] > 210)
{
alpha_p[0] = 255;
alpha_p[1] = 255;
alpha_p[2] = 255;
}
else
{
alpha_p[0] = 0;
alpha_p[1] = 0;
alpha_p[2] = 0;
}
comp.at(i, j)[0] = int(img_p[0] * (alpha_p[0] / 255.0) + bg_p[0] * (1.0 - alpha_p[0] / 255.0));
comp.at(i, j)[1] = int(img_p[1] * (alpha_p[1] / 255.0) + bg_p[1] * (1.0 - alpha_p[1] / 255.0));
comp.at(i, j)[2] = int(img_p[2] * (alpha_p[2] / 255.0) + bg_p[2] * (1.0 - alpha_p[2] / 255.0));
}
finish = clock();
duration = (double)(finish - start) / CLOCKS_PER_SEC;
printf("抠图推理耗时 %f 毫秒\n", duration * 1000);
//保存抠图结果
sprintf_s(imgpath, "results/%d_matting.jpg", picIndex);
imwrite(imgpath, comp);
//手动释放内存资源
inputs.clear();
img.release();
orgimg.release();
alphaImg.release();
alpha.release();
comp.release();
}
return 0;
}
三、测试
测试效果如下:
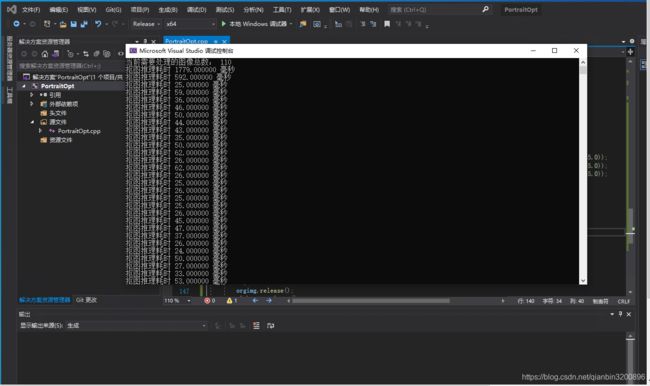
第一两张图像速度会比较慢,猜测可能正在执行一些GPU调度之类的,后面的每张图像推理速度就正常了。抠图效果如下所示:
原图:
抠图结果:
