定位图像中子图像:直方图方向投影与图像匹配。
本篇文章讲解直方图反向投影与子图像匹配,原理及代码角度讲解
文章目录
- 前言
- 一. 直方图反向投影
-
- 1. 原理浅析
- 2. 应用及代码层面
- 3. 代码讲解
- 二. 图像匹配
-
- 1. 浅显原理
- 2. 代码实践
-
- ①. 单对象模板匹配
- ②. 多对象模板匹配
- 3. 代码讲解
-
- ①. 单目标匹配
- ②. 多目标匹配
-
- * np.where()
- * python的 * 与 **
- * zip方法
- 三. 总结
前言
该篇文章的主要内容牵扯到了一些多目标识别的基础,同时也是学习OpenCV必须掌握的东西,不仅仅是代码层面的,原理层面也必须要有一定的了解。
一. 直方图反向投影
1. 原理浅析
直方图反向投影,是利用图像直方图计算图像像素点的特征,并投影的原图像对应的像素值上,其在每一个像素值的投影是该像素点在直方图上的对应的值,或者可以说,是原图像中该像素点数量的累加数。可应用于目标检测。
原理层面可以举个浅显的例子讲解。
假设某图像像素点如下:

其直方图如下:

原图变化之后:
之后对其进行归一化,将数据的范围规定在0~255之间,如此下来,像素点占比越多的点则对应的像素值越高,即亮度越大。
2. 应用及代码层面
之前说过,该技术可用于目标检测,利用两张图做代码讲解
原图像:
检测的区域:
 代码:
代码:
#直方图方向投影
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
import time
#构造2D直方图
def hist2D_demo(image):
#转化为HSV色彩空间
image=cv.cvtColor(image,cv.COLOR_BGR2HSV)
hist=cv.calcHist([image],[0,1],None,[180,256],[0,180,0,256])
plt.imshow(hist,interpolation='nearest')
plt.show()
return image
#建立直方图
def back_projection_demo():
#加载两张图 读取两张图片,第一张为需要搜寻的部分,第二张为目标图
'''
利用第一张图做直方图,利用第二张图匹配,对rolhist做归一化。将其映射到0~255上,得到的图像,匹配的概率更高,则像素点越大,表现在图像上
就表现的越白,而概率越小的越黑。
'''
src_1=cv.imread('find_temp.jpg')
src_2=cv.imread('big_1.jpg')
#转化为HSV色彩空间
src_1_hsv=cv.cvtColor(src_1,cv.COLOR_BGR2HSV)
src_2_hsv=cv.cvtColor(src_2,cv.COLOR_BGR2HSV)
#cv.imshow('simple',src_1_hsv)
#cv.imshow('target',src_2_hsv)
#cv.waitKey(0)
cv.destroyAllWindows()
#参数 1:原图 2:通道数 3:掩膜 4:bins数,emm柱子数,5:像素值范围
rol_hist=cv.calcHist([src_1_hsv],[0,1],None,[32,32],[0,180,0,256])
#归一化
rol_hist=cv.normalize(rol_hist,0,255,cv.NORM_MINMAX)
#cv.imshow
#参数 1:hsv图 2:通道数 3:直方图 4:范围 5:缩放因子
dst=cv.calcBackProject([src_2_hsv],[0,1],rol_hist,[0,180,0,256],1)
h,w=dst.shape[:2]
dst=cv.resize(dst,(int(w/2),int(h/3)))
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()
#展示
def show():
image=hist2D_demo(load_image())
#cv.imshow('input',image)
#cv.waitKey(0)
#cv.destroyAllWindows()
back_projection_demo()
先看结果:

如果白色的区域就是检测到的区域,算法可以调整,升高匹配的精度,不过需要读者自己检验。接下来我们看代码讲解。
3. 代码讲解
hist2D_demo()方法:自定义方法,利用API构建直方图。 首先第一个知识点,构建2D直方图需要将图像转化为灰度HSV色彩空间,利用cv.cvtColor()转化。利用cv.calcHist()方法构造图像直方图,该方法在前文细说过。
想细细了解的可直接去上一篇博客传送门

hist=cv.calcHist([image],[0,1],None,[180,256],[0,180,0,256])
有些小伙伴可能疑惑这里的参数写法似乎与先前的另一种写法有所不同,其实是由于这是色彩空间不同,参数写法本质上还是一样的,这里的[0,1]表示通道数0 1,因为是HSV色彩空间,它的通道与RBG不同,这里的[180,256]表示一二通道分别对应的柱子数,这里也就为前文解惑了,柱子数之所以要用括号括起来是因为,这里可能需要多数参数。而后面的数组,0~ 180,0 ~256就是两个数据的范围了。
该方法只是简单解释了如何去构造这样一个直方图,接下来我们来看重点。
back_projection_demo()
目标检测的步骤:
- 读入原图与匹配图
- 利用匹配图构造直方图
- 利用直方图在原图检测,并做处理
- 输出处理好的图像。
尝试把这些步骤带入代码中去读,需要讲解的就是直方图构建那里了,稍微看看应该就明白了。
小知识:
cv.resize():前文说过,这里再说一遍,该方法将图像进行尺寸的变化,一般情况下,如果需要两张尺寸相同的图片,或者图片过大在屏幕上显示不完的情况下,可以用该方法进行改进。
二. 图像匹配
1. 浅显原理
图像匹配,顾名思义,就是在图像中查找模板图像的位置,与2D卷积相同,其过程也是通过模板图像在原图中滑动,对每一个位置对应的子区域进行比较,需要注意的是,OpenCV提供了6种比较方法。
- 相关匹配
- 相关性匹配
- 平方差匹配
- 及以上三种对应的归一化。
三种方法得到的结果可能不会相差很大,但是原理上是完全不同的。
其公式如下:(节选自b站某老师的课程)
这里只是给大家看看,不必再这里纠结。

为什么要用OpenCV提供的API去算呢,如果将原理搞懂的话,很多人是可以自己写出来一个算法的,但是在效率上却远远不及其OpenCV内部API的速度,这是因为在空间域中,每一个子图像做这样一个运算会非常复杂,而OpenCV经过积分图,傅里叶变换等一系列变化,可以转化到平面域,这样效率会非常高。
2. 代码实践
①. 单对象模板匹配
图像如下:


#单对象模板匹配 在整个图像区域检测给定图像的区域
import cv2 as cv
import numpy as np
def load_image():
src=cv.imread('bi.jpg')
template=cv.imread('bi_template.jpg')
return src,template
def show_and_find():
src,temp=load_image()
cv.imshow('src',src)
cv.imshow('temp',temp)
#几种方法
methods=[cv.TM_SQDIFF_NORMED,cv.TM_CCORR_NORMED,cv.TM_CCOEFF_NORMED]
th,tw=temp.shape[:2]
for md in methods:
result=cv.matchTemplate(temp,src,md)
min_loc,max_loc=cv.minMaxLoc(result)[2:]
if md==cv.TM_SQDIFF_NORMED :
tl=min_loc
else:
tl=max_loc
br=(tl[0]+tw,tl[1]+th)
cv.rectangle(src,tl,br,(0,0,255),2)
cv.imshow('find'+np.str(md),src)
cv.waitKey(0)
cv.destroyAllWindows()
show_and_find()
结果如下:
②. 多对象模板匹配
图像如下:
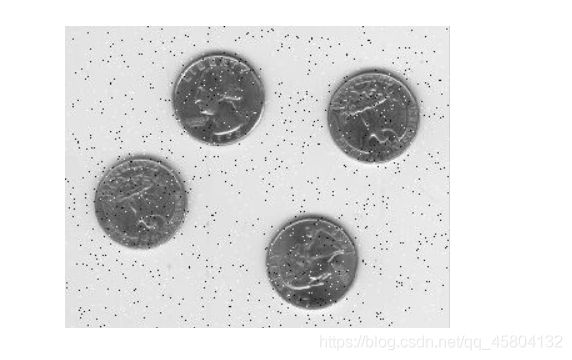
找出四枚硬币
#多目标匹配
import cv2 as cv
import numpy as np
def load_image():
src=cv.imread('noise.jpg')
h,w=src.shape[:2]
src=cv.resize(src,(int(3*w),int(h*3)))
temp=cv.imread('noise_template.jpg')
h,w=temp.shape[:2]
temp=cv.resize(temp,(int(3*w),int(h*3)))
return src,temp
def multiple_target_recognition():
#获取图像
src,temp=load_image()
#获取高宽
w,h=temp.shape[:2]
#匹配
res=cv.matchTemplate(src,temp,cv.TM_CCOEFF_NORMED)
threshold=0.65
loc=np.where(res>=threshold)
for pt in zip(*loc[::-1]):
cv.rectangle(src, pt, (pt[0]+w, pt[1]+h), (0,0,255),1)
cv.imshow('input',src)
cv.waitKey(0)
cv.destroyAllWindows()
multiple_target_recognition()
结果如下:
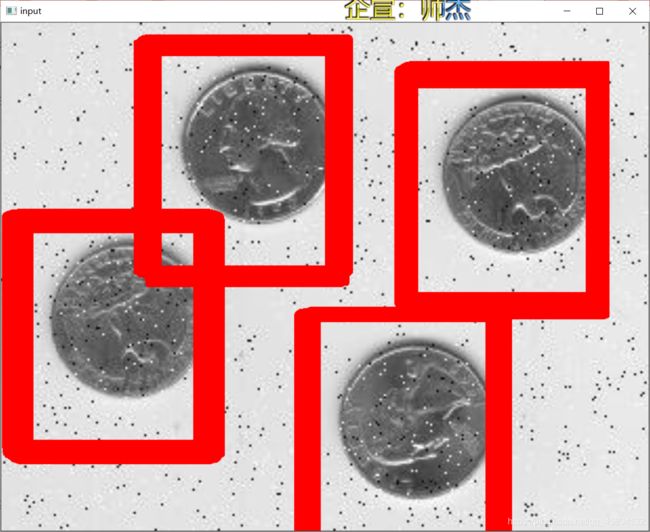
3. 代码讲解
①. 单目标匹配
重点11掌握的方法:
cv2.matchTemplate()
cv2.minMaxLoc()
[cv.TM_SQDIFF_NORMED,cv.TM_CCORR_NORMED,cv.TM_CCOEFF_NORMED]
这里就是用于判断的几种方法。直接从单词层面也很容易看出来吗,sqd就是平方差,ccoorr相关,ccoeff相关性
result=cv.matchTemplate(temp,src,md):
这里的三个参数分别为,模板,原图,方法。result是返回值,它是一张灰度图。
minMaxLoc()方法
返回一个四元组,分别为 1. 最小值对应的像素值 2. 最大值对应的像素值 3. 最小值对应的位置 4. 最大值对应的位置。
这里我们看到一处代码用到了if判断
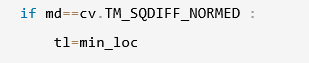
这里就要说到该判断方法作用于图像匹配的特殊之处了,平方差做判断最后得到的返回值,同样是一张灰度图,但它却与其他几张图反过来了,对它来说,从公式来看,越大则意味着该位置与模板图越是不合,所以这里用的获取最小位置。
之后用
cv.rectangle()画矩形将获取到的图像框起来。
②. 多目标匹配
重点:阈值的设置与np.where的应用。
如果将多目标中的res,imshow出来的话能得到这样一张图。
 可以看出,几个匹配到的区域都有很高的像素值。但是每一张图并不尽相同,因此我们必须要设置阈值。
可以看出,几个匹配到的区域都有很高的像素值。但是每一张图并不尽相同,因此我们必须要设置阈值。
* np.where()
该方法需要细讲。
import numpy as np
array=np.array([[2,3,5],[4,5,1]])
print(array)
#若有条件 有双值 改变元素
array_1=np.where(array>3,1,0)
print(array_1)
#纯有条件 输出坐标
array_2=np.where(array>3)
print(array_2)
结果如下:

这里肯定还有不足的地方也欢迎补充,因为这也是我试出来的。
* python的 * 与 **
同时代码中还存在一个*该符号与 **这两个符号都有其自己的含义,并非是C语言的指针(别想当然了,这只是一种传参的表现形式,如下)
def add(*a):
return a[0]+a[1]
a=(4,5)
print(add(*a))
结果如下:

它将函数以元组的形式传入了函数。
而**则是以字典的形式传入函数。如下:

* zip方法
zip方法:从多个元素中取元素组成一个新的迭代器

第二段多目标匹配的代码,其大部分内容也就是涵盖在上面解释的这些方法之中了,一个是这些方法都属于很基本的方法,是必要掌握的方法,在一个对方法的灵活运用需要长时间的练习,第二段代码要看懂可能对部分小伙伴来说还是需要一定的时间的。还是要多看看。这里的阈值设置为0.6619应该是最好的结果了,小伙伴们可以自己试一试。
三. 总结
本篇文章主要对图像匹配这里做讲解,原理方面讲的比较浅,感兴趣想深挖的小伙伴建议去看看书或者知乎里面的一些理论,我想法主要还是先清楚原理,会用方法,之后深挖原理。另外,利用图像匹配可以写出很多有意思的东西,包括简单的人脸识别之类的,大家可以尝试一下,篇幅太长了,我也就不讲了。