数理统计——推断统计假设检验与python实现
文章目录
- 前言
- 一、假设检验是什么?
-
- 1.概念
- 2.假设检验的步骤
- 二、常用假设检验
-
- 1.Z检验
- 2.t检验
- 3.双边检验与单边检验
- 作业
前言
一台机器包装糖,袋里的糖是一个随机变量,服从正态分布,当机器正常时,其均值为0.5kg,标准差为0.015kg,某天开工后检查机器包装是否正常,随机抽取了下面9袋(0.497,0.506,0.518,0.524,0.498,0.511,0.520,0.515,0.512),问机器是否正常?
如果采用区间估计的思想,其思路和代码实现如下:
1、计算出9袋糖的均值、标准误差;
2、计算出9袋糖的置信区间;
3、比较总体均值与区间的关系,通过可视化表现出来,进行判断;
#检验装糖机器是否正常?
import numpy as np
a=np.array([0.497,0.506,0.518,0.524,0.498,0.511,0.520,0.515,0.512])
mean,std=0.5,0.015 #已知总体均值、标准差
#计算样本均值
sample_mean=a.mean()
#计算标准误差:
se=std/np.sqrt(len(a))
#计算置信区间:(95%的置信度)
left,right=sample_mean-1.96*se,sample_mean+1.96*se
print(f"置信区间:({left:.3f},{right:.3f})")
#将结果进行可视化
import matplotlib.pyplot as plt
plt.rcParams["font.family"]="SimHei"
plt.rcParams["axes.unicode_minus"]=False
plt.plot(mean,0,marker="*",color="orange",ms=15,label="总体均值")
plt.plot(sample_mean,0,marker="o",color="r",label="样本均值")
plt.hlines(0,xmin=left,xmax=right,colors="b",label="置信区间")
plt.axvline(left,0.4,0.6,color="r",ls="--",label="左边界")
plt.axvline(right,0.4,0.6,color="g",ls="--",label="右边界")
plt.legend()
输出:置信区间:(0.501,0.521)
可视化结果:
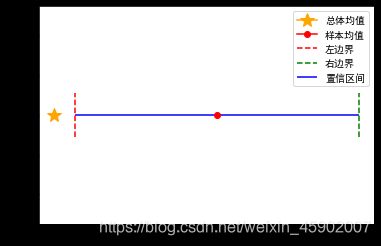
可以看到,总体均值没有落在置信区间,也就意味着机器运作不正常。
虽然成功求解了本题,但程序有些繁琐,本节知识点尝试一种新的思路——检验检验来求解这类题。
一、假设检验是什么?
1.概念
(1)假设检验:也叫显著性检验,通过样本统计量来判断与总体参数之间是否存在差异(差异是否显著),即我们对总体参数进行一定假设,然后通过收集到的数据,来验证我们之前所做的假设,是否合理。在假设检验中会建立两个假设:1、原假设(零假设)2、备择假设(对立假设)。然后根据样本信息判断时接受原假设还是接受备择假设。
(2)反证法。假设检验就是基于反证法,假设原假设为真,如果在此基础上得出了违反常理的结果,那么表明原假设为假,此时接受备择假设,反之……
(3)小概率事件:在假设检验中,违反逻辑与常理的结论就是小概率事件。
(4)接受原假设不一定代表原假设为真,此处涉及到两类错误:存真和取伪错误。
(5)p值与显著性水平:p值即为支持原假设的概率;α就是我们事先设定的一个阈值,也就是显著性水平,通常α的取值为0.05,(1-α)即为置信度,当p值大于α时,支持原假设,反之。
2.假设检验的步骤
(1)设置原假设与备择假设;
(2)设置显著性水平;
(3)根据问题选择假设检验的方式;
(4)计算统计量,并通过统计量获得p值;
(5)根据p值和α值,决定是否接受原假设还是备择假设。
二、常用假设检验
1.Z检验
Z检验用来判断样本均值与总体均值是否有显著性差异。有以下使用条件:
(1)总体正态分布;
(2)总体方差已知;
(3)样本容量够大(一般大于30);
Z检验计算方式:

使用假设检验代码实现本节开始的那道题:
from scipy import stats
a=np.array([0.497,0.506,0.518,0.524,0.498,0.511,0.520,0.515,0.512])
#总体均值与标准差
mean,std=0.5,0.015
#计算样本均值
sample_mean=a.mean()
#计算样本标准误
se=std/np.sqrt(len(a))
#计算z统计量
z=(sample_mean-mean)/se
print("统计量z:",z)
#计算p值
p=2*stats.norm.sf(abs(z))
print("P-Value值: ",p)
输出:
统计量z: 2.244444444444471
P-Value值: 0.02480381963225589
从结果可以看出,p值小于0.05,所以我们拒绝原假设,接受备择假设,即认为机器运作不正常。
2.t检验
t检验和z检验一样,用来判断样本与总体之前的差异是否显著,有以下使用条件:
(1)总体分布呈正态;
(2)总体方差未知;
(3)样本数量较少;
t检验随着样本数量逐渐变大,也慢慢接近正态分布。
计算方式:
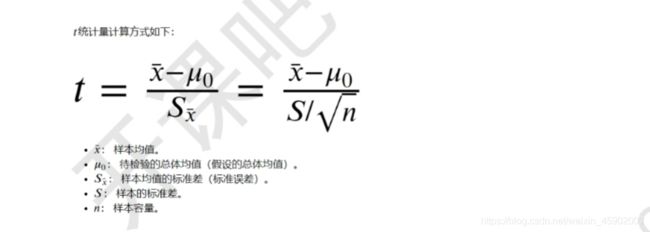
如果说鸢尾花的平均花瓣长度是3.5,这种说法是否正确——我们采用t检验的方式进行解决:

代码实现:
import pandas as pd
from sklearn.datasets import load_iris
iris=load_iris()
data=pd.DataFrame(iris.data,
columns=["sepal_length","sepal_width","petal_length","petal_width"])
#计算样本均值
mean=data["petal_length"].mean()
#计算样本均值
std=data["petal_length"].std()
print("样本均值:",mean)
print("样本标准差:",std)
#计算t统计量
t=(mean-3.5)/(std/np.sqrt(len(data)))
print("t统计量:",std)
#计算p值
#df:自由度,即变量可以自由取值的个数;
p=2*stats.t.sf(abs(t),df=len(data["petal_length"])-1)
print("p值:",p)
输出:
样本均值: 3.7580000000000027
样本标准差: 1.7652982332594667
t统计量: 1.7652982332594667
p值: 0.07548856490783468
从结果中可以看到,p值是大于0.05的,所以在α=0.05下,不能拒绝原假设。
同时我们还可以根据scipy提供的方法来进行t检验的计算,无需自行计算。
stats.ttest_1samp(data["petal_length"],3.5)
输出:
Ttest_1sampResult(statistic=1.7899761687043318,pvalue=0.07548856490783705)
3.双边检验与单边检验
双边假设检验;
单边假设检验:
1、左边假设检验
2、右边假设检验
以刚才鸢尾花例子为例,进行一次单边假设假设,看看结果如何?
print(t)
P=stats.t.sf(t,df=len(data["petal_length"])-1)
print("p值:",P)
输出:
1.7899761687043467
p值: 0.03774428245391734
作业
1、假设检验中,α的取值会影响到什么?
2、某公司要求,平均日投诉量均值不得超过1%,现检查一个部门的服务情况.在该部门维护的一个500人客户群中,近7天的投诉量分别为5,6,8,4,4,7,0.请问该部门是否达标?
#原假设:平均日投诉量均值不超过1%
import numpy as np
arr=np.array([5/500,6/500,8/500,4/500,4/500,7/500,0])
arr
#样本均值
mean=arr.mean()
mean
#样本标准差
std=arr.std()
std
# 1%即0.01
t=(mean-0.01)/(std/np.sqrt(len(arr)))
t
from scipy import stats
P=stats.t.sf(t,df=len(arr)-1)
P
输出:0.5595938210714404
stats.ttest_1samp(arr,0.01)
输出:
Ttest_1sampResult(statistic=-0.1448413648755799, pvalue=0.8895790719189121)
可以从两个结果中看出,p值是大于0.05的,所以不能拒绝原假设。