python unicode 标点范围_干货|Python基础入门 课程笔记(二)

目录
- 对象
- 字符串
一、对象
(1)什么是对象
在python中一切都是对象,每个对象都有三个属性分别是,(id)身份,就是在内存中的地址,类型(type),是int、字符、字典(dic)、列表(list)等,最后还有值,例如: a = 12 就是用 12 这个类型为整数的,值为 12,在内存空间中创建了一个空间(这个空间会用一个地址来表示,就是 id ),当对象被创建后,如果该对象的值可以被更改,那么就称之为可变对象(mutable),如果值不可更改,就称之为不可变对象(inmutable)
(2)不可变对象
什么是不可变对象?
不可变对象,该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。不可变对象:整数int、浮点数float、字符串str、元组tuple
举例说明:
a = 5
print(id(a))
a = 4
print(id(a)) # 重新赋值之后,内存地址发生改变实际操作:
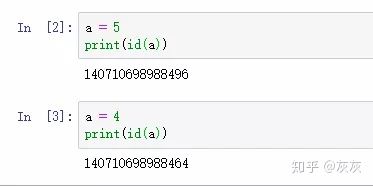
由于是不可变对象,变量对应内存的值不允许被改变。当变量要改变时,实际上是把原来的值复制一份后再改变,开辟一个新的地址,变量 a 再指向这个新的地址(所以前后变量 a 的id不一样),原来变量 a 对应的值 5 因为不再有对象指向它,就会被垃圾回收。这对于 str 和float 类型也是一样的。
(3)小整数池
整数在程序中的使用非常广泛, python 为了优化速度,使用了小整数对象池,避免为整数频繁申请和销毁内存空间.
Python 对小整数的定义是 [-5, 256] 这些整数对象是提前建立好的,不会被垃圾回收。在一个 Python 的程序中,无论这个整数处于 LEGB中 的哪个位置,所有位于这个范围内的整数使用的都是同一个对象。同理,单个字母也是这样的。
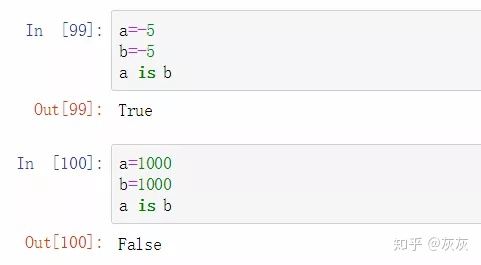
# 举个栗子
a=-5
b=-5
a is b:True
a=1000
b=1000
a is b:False实际操作:
(4)可变对象
什么是可变对象
可变对象,该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变。可变对象:列表list、字典dict、集合set
举例说明
# 举个例子
list1 = [1,2,3,4]
print(list1)
print(id(list1)) # 打印 id 地址
list1[2] = 5 # 对列表进行改值操作
print(list1) # 打印改值之后的列表内容
print(id(list1)) # 打印改值之后的 id 地址实际操作
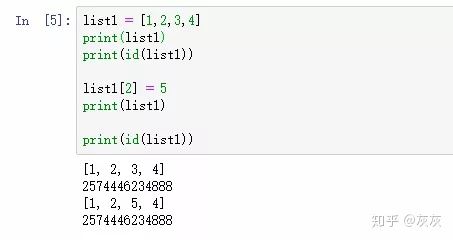
列表 list 在改变前后 id 并未发生改变,可变对象由于所指对象可以被修改,所以无需复制一份之后再改变,直接原地改变,所以不会开辟新的内存,改变前后 id 不变。
(5)编码
先说说什么是编码
编码(encoding)就是把一个字符映射到计算机底层使用的二进制码。编码方案(encoding scheme)规定了字符串是如何编码的。
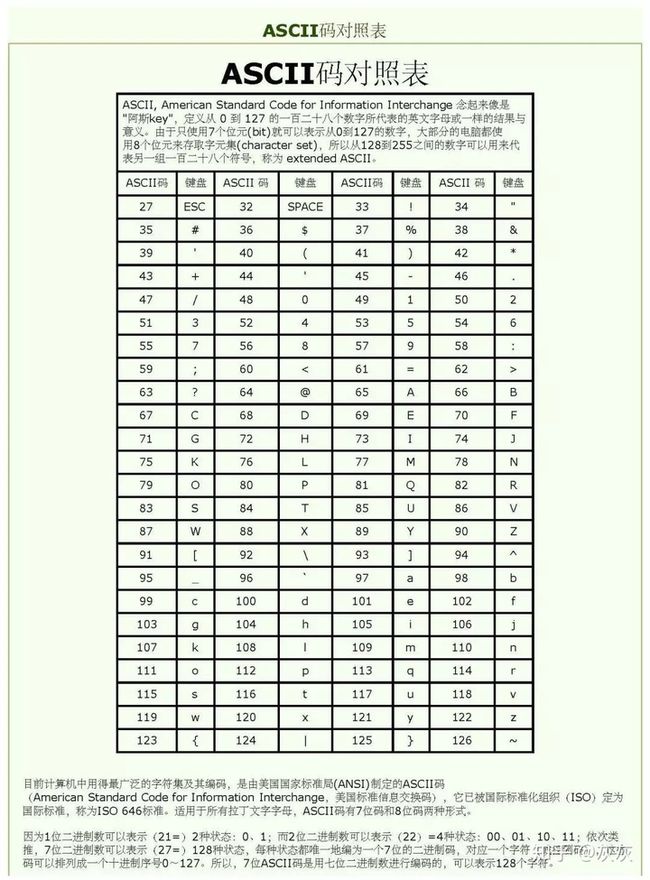
ASCII码:
美国信息互换标准代码,是一种7位编码方案来表示所有的大写字母、小写字母、数字、标点符号和控制字符。
UNICODE万国码:
Unicode 是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。
UTF-8码
UTF-8 是以 8 位为单元对 Unicode 进行编码。UTF-8 包含全世界所有国家需要用到的字符,是国际编码,通用性强。
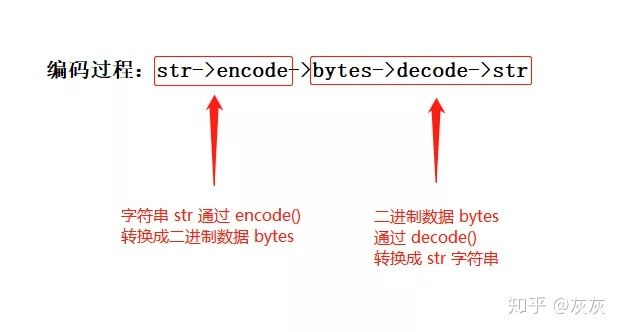
(6)bytes与str
使用 bytes 类型,实质上是告诉 Python ,不需要它帮你自动地完成编码和解码的工作,而是用户自己手动进行,并指定编码格式。Python 已经严格区分了 bytes 和 str 两种数据类型,你不能在需要 bytes 类型参数的时候使用 str 参数,反之亦然。
编码转换过程
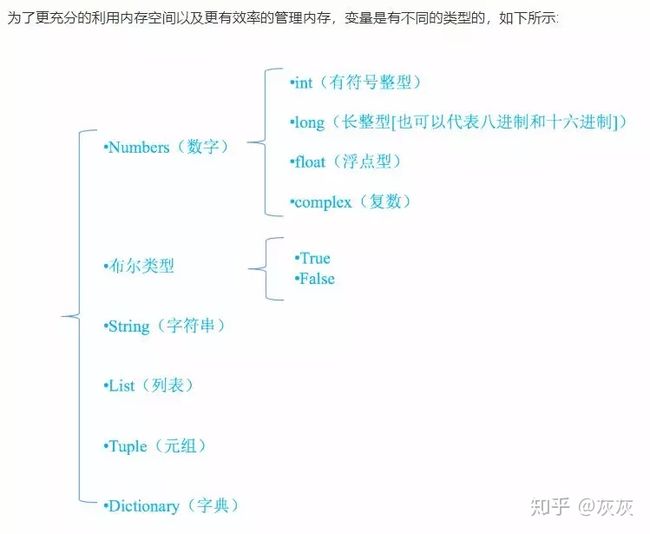
(7)数据类型
(8)下标(索引)
所谓“下标”,就是编号,就好比超市中的存储柜的编号,通过这个编号就能找到相应的存储空间
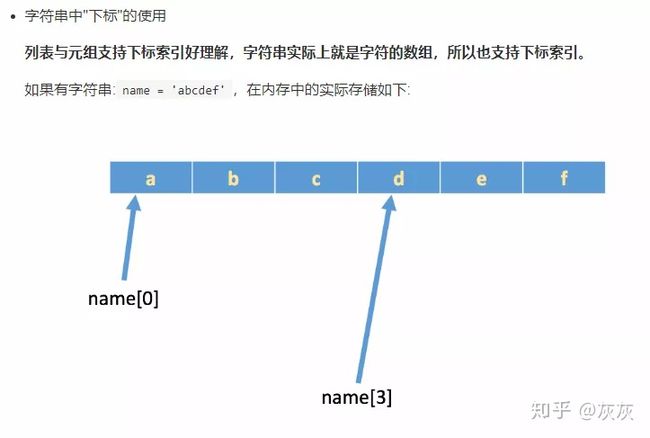
# 如果想取出部分字符,那么可以通过下标的方法,(注意 python 中下标从 0 开始)
name = 'abcdef'
print(name[0])
print(name[1])
print(name[2])
运行结果:
a
b
c(9)切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。切片的语法:[起始:结束:步长]
注意:选取的区间从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身),步长表示选取间隔。
# 我们以字符串为例讲解。如果取出一部分,则可以在中括号[]中,使用:
name = 'abcdef'
print(name[0:3]) # 取 下标0~2 的字符
结果为:
abc
s = 'Hello World!'
print(s[4])
print(s)
print(s[:]) # 取出所有元素(没有起始位和结束位之分),默认步长为1
print(s[1:]) # 从下标为1开始,取出 后面所有的元素(没有结束位)
print(s[:5]) # 从起始位置开始,取到 下标为5的前一个元素(不包括结束位本身)
print(s[:-1]) # 从起始位置开始,取到 倒数第一个元素(不包括结束位本身)
print(s[-4:-1]) # 从倒数第4个元素开始,取到 倒数第1个元素(不包括结束位本身)
print(s[1:5:2]) # 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身)
# python 字符串快速逆置
print(s[::-1]) # 从后向前,按步长为1进行取值
# 索引是通过下标取某一个元素
# 切片是通过下标取某一段元素(10)复制(拷贝)
python 中有三种赋值方式,分别是:
赋值:=
浅拷贝:copy
深拷贝:deepcopy
赋值:
在 Python中,等号 = 是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。
所以说,Python 是动态语言,即变量不用指定数据类型。
实际操作:
图片详解:
实际操作:
l = [1, 2, 3, 4, [1, 2, 3] ] # 列表中有整数数据类型,也有列表数据类型
new_l = l 对 对象 l 的引用
copy_l = copy.copy(l) 对 对象 l 的浅拷贝
deepcopy_l = copy.deepcopy(l) 对 对象 l 的深拷贝使用 id 这个方法来查看对象的内存地址
l = [1, 2, 3, 4, [1, 2, 3] ] id(l) ---> 1631063137352
new_l = l id(new_l) ---> 1631063137352
copy_l = copy.copy(l) id(copy_l) ---> 1631063137416
deepcopy_l = copy.deepcopy(l) id(deepcopy_l) ---> E1631063026632可以看到,使用 copy 这个模块创建的浅拷贝和深拷贝在内存中都有一个新的内存空间。
进一步查看四个列表中不可变类型的id值:
l = [1, 2, 3, 4, [1, 2, 3] ] id(l[1]) ---> 1400022144
new_l = l id(new_l[1]) ---> 1400022144
copy_l = copy.copy(l) id(copy_l[1]) ---> 1400022144
deepcopy_l = copy.deepcopy(l) id(deepcopy_l[1]) ---> 1400022144再查看可变类型的id值:
列表[-1] : 表示最后一个这个列表中的元素
l = [1, 2, 3, 4, [1, 2, 3] ] id(l[-1]) ---> 1631063137544
new_l = l id(new_l[-1]) ---> 1631063137544
copy_l = copy.copy(l) id(copy_l[-1]) ---> 1631063137544
deepcopy_l = copy.deepcopy(l) id(deepcopy_l[-1]) --->1631063186312可以看到,浅拷贝是不会对 l 中的数据结构进行深层次的拷贝的。也就是说,我要是在 l 列表,更改了 l[-1][索引] 列表其中的一个值,那么 copy_l 中的最后一个元素中的值是会跟着改变的,因为他跟 l 引用的地址是同一个,而 deepcopy_l 的值是不会变的。
浅拷贝 copy:
浅拷贝是对于一个对象的顶层拷贝,通俗的理解是:拷贝了引用,并没有拷贝内容。
深拷贝 deepcopy:
深拷贝是对于一个对象所有层次的拷贝(递归,相当于克隆了一下,产生了新的数据)。
浅拷贝对不可变类型和可变类型的 copy 不同
copy.copy对于可变类型(列表、字典),会进行浅拷贝。
copy.copy对于不可变类型(元祖、数字、字符串),不会拷贝,仅仅是指向。
基本上只要不是我们自已手动调用的 deepcopy 方法都是浅拷贝。
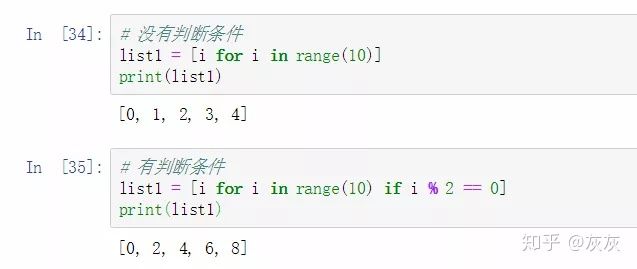
(10)列表推导式
所谓的列表推导式,就是指的轻量级循环创建列表
格式 : [表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]
实际操作:
二、字符串
(1)字符串的格式
定义变量 num,存储的是数字类型的值
num = 22定义变量 name,存储的是字符串
name = 'hello july'总结:
双引号或者单引号里面的数据就是字符串
(2)字符串输出
举个栗子
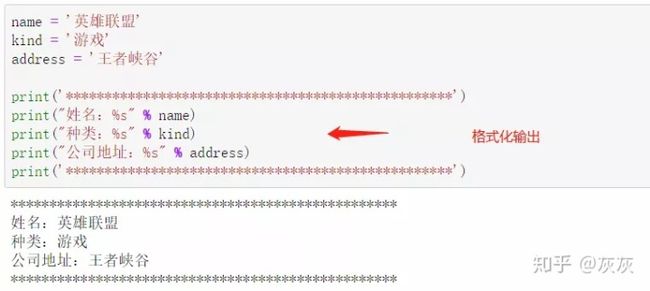
name = '英雄联盟'
kind = '游戏'
address = '王者峡谷'
print('**************************************************')
print("姓名:%s" % name)
print("种类:%s" % kind)
print("公司地址:%s" % address)
print('**************************************************')实际操作:
哈哈,接下来给你们看个好玩的~~.

(3)字符串输入
咱们之前在学习 input 输入的时候,通过它能够完成从键盘获取数据,然后保存到指定的变量中;
注意:input 获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
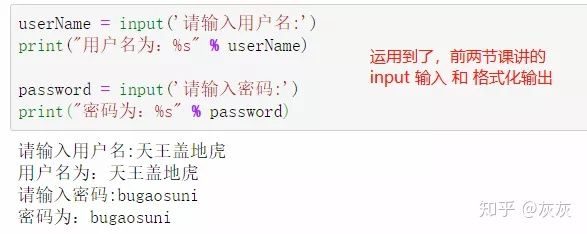
userName = input('请输入用户名:') # 命名规范 userName 简单易懂代表用户名字
print("用户名为:%s" % userName)
password = input('请输入密码:')
print("密码为:%s" % password)实际操作:
(4)下标和切片
所谓 “下标”,就是编号,就好比身份证信息中的身份证号码,通过这个号码就能找到相应的人。

字符串中"下标"的使用
列表与元组支持下标索引好理解,字符串实际上就是字符的数组,所以也支持下标索引。
如果有字符串:name = " http:// JULYEDU.COM ",在内存中的实际存储如下:

如果你想取出字符串中的某个值,可以通过方括号 [下标索引] 来获取
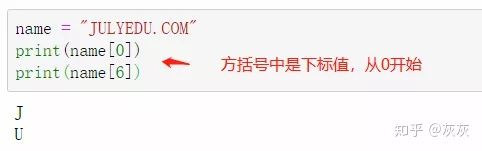
name = "JULYEDU.COM"
name[0]
name[6]实际操作:
(5)切片
在很多编程语言中,针对字符串提供了很多各种截取函数(例如,substring),其实目的就是对字符串切片。Python 没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:
[ 起始位置 : 结束位置 : 步长 ]
注意:选取的区间从 "起始" 位开始,到 "结束" 位的前一位结束(不包含结束位本身),步长表示选取间隔。
我们以字符串为例讲解。
如果取出一部分,则可以在中括号 [ ] 中,使用:
name = "JULYEDU.COM"
print(name[0:7]) # 取 下标0~7 的字符运行结果:

更多使用方法:
name = "JULYEDU.COM"
print(name[0:7]) # 取 下标 0~7 的字
print(name[3:5]) # 取 下标 3~5 的字
print(name[3:]) # 取 下标为 3 开始一直到最后的字
print(name[1:-1]) # 取 下标为 1 开始到最后第 2 个之间的字符
print(name[1::2]) # 取 下标为 1 开始一直到最后的字,每两个切一个运行结果:

(6)字符串常见操作
假设咱们现在有个字符串 web = " http://www. julyedu.com ",下面就是字符串的常见操作。
find()
find : 翻译成中文是查找的意思
检测你需要查找的字符串是否包含在 web 中,如果是则返回开始的索引值,否则返回-1
web.find('july') # 返回下标 4lower()
lower : 翻译成中文是减弱、减小,也可以翻译为小写的
将字符串中,所有大写字符转换成小写字符
name = 'Wo Zui Shuai !'
name.lower() # 结果返回:'wo zui shuai !'upper()
upper : 翻译成中文是上面的、大写的。
将字符串中所有小写转换成大写
name = 'Wo Zui Shuai !'
name.upper() # 返回结果:'WO ZUI SHUAI !'count()
count : 翻译成中文是计算、计数的意思
返回 字符串 在 开始 和 结束 之间 在 web 里面出现的次数
web.count('w') # 返回结果 3 ,表示 w 在 web 值中出现 3 次index()
index : 翻译成中文是指标、指数、索引的意思
跟 find() 方法一样,只不过如果查找的字符串不在 web 中会报一个异常.匹配成功的话也是返回下标值
web.index('a') # 举一个匹配失败得例子
split()
split : 翻译成中文是分离、分割的意思
以 str 为分隔符切片 web,如果 maxsplit 有指定值,则仅分隔 maxsplit 个子字符串
web.split('.',2) # split(以什么为切割点 ,切割几次)运行结果:

replace()
replace : 翻译成中文是取代、代替、替换的意思
把 web 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
web.replace('w','W',2)运行结果:

title()
title :翻译成中文是标题、冠军、头衔的意思
把字符串的每个单词首字母大写
web.title() # 返回 'Www.Julyedu.Com'【写在最后】本文是针对七月在线《Python基础入门第三期》的课程笔记第二篇,大家想了解关于本课程的更多内容,欢迎访问:AI算法工程师学习路线总结之Python篇 | 粉丝福利,学习和咨询。