论文阅读(一):Hierarchical LSTM for Sign Language Translation
Abstract
SLT (Sign Language Translation) 手语翻译
CTC (Connectionist temporal classification) 连接主义时间分类
linguistics /lɪŋ’gwɪstɪks/ n. 语言学
sequential gesture variation 连续的手势变化
解决的问题
连续手语翻译中
->帧级和word级的对齐问题,
->句子中 与视觉内容相对应的语序混乱 问题。(messing word order corresponding to visual content )
[句子中的单词标签与相应的视觉内容的顺序混乱]
granularity /grænjʊ’lærɪtɪ/ n. 颗粒度
spatiotemporal /,speɪʃɪəʊ’tempərəl/ adj. 时空的
提出的模型
一种具有可视化与文字嵌入的分层LSTM(HLSTM)自编/解码器。通过传输帧、剪辑和视素单元之间的时空转换来处理不同的粒度。
模型内容
1)首先利用3D-CNN研究视频片段的时空线索,通过自适应变长在线关键片段挖掘(online key clip mining),压缩合适的(appropriate)视素。
intrinsic /ɪn’trɪnsɪk/ adj.内在的
recurse v. 递归
2)在将HLSTM顶层的循环输出池化(Pooling)后,提出了一种时间注意加权机制来平衡视素源位置之间的内在关系
3)最后,利用另外两个LSTM层分别对视素向量进行递归和语义转换
模型效果
在保留了3D CNN和HLSTM顶层的原始视觉内容后,缩短了底层两层LSTM的编码时间步长(encoding time step ),使计算复杂度更低,同时获得了更多的非线性。
我们提出的模型在有可见句子的单点独立测试(singer-independent test with seen sentences )中表现出良好的性能,并且在无可见句子的比较算法中也有较好的表现。
Introduction
To be specific 具体地说
研究介绍------
研究目标:
将视频翻译成可理解的文本和语言
弱监督学习----缺乏对手语准确时间位置的监督
难点:
1)SLT是由单手势(sign)单词识别 衍生而来的,一种动作识别或视频分类
2)SLT类似于视频字幕(video captioning)----视频被直接翻译成文本序列
区别:视频字幕 使用语法知识和语义一致性,以对象、场景、动作或动作的特征表示来生成句子,而SLT则强调 独立子视频片段 的词转换。
3)难以将子视频clips与单词对齐;难以识别视觉语言
is consistent to 与…相一致
prerequisite /priː’rekwɪzɪt/ n. 先决条件
corresponding visual content 相应的XXXX
respectively /rɪ’spektɪvlɪ/ adv. 分别地
内容简介:
1)采用encoder-decoder框架,分别学习视觉内容和单词嵌入。
2)提出了HLSTM模型,有效地编码视觉语义
核心思想:建立一个具有不同粒度(different granularities)的多层可视化语义嵌入体系结构(multi-layered visual-semantic embedding architecture)
(不同粒度)如:帧、视素(sub-visual-word)、视觉词(visual-word)和整个video
特点:
处理子符号单元(视素)的视觉特征嵌入( visual feature embedding of subsign units )
我们寻求高层次(level)的视素表现,并关注这些视素之间的过渡,以避免直接连接整个视频帧和自然语言
换句话说,我们的模型具有层次性和变尺度的时间结构,它探索了变尺度视素芯片(variablesized chips of visemes.)的时空线索。
实验内容:多层编解码器框架(a hierarchical encoder-decoder framework to solve continuous SLT)

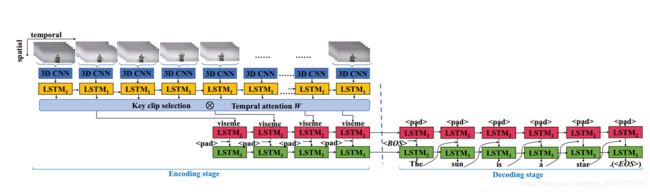
1.提取视觉特征:3D-CNN
attenuation /ə,tenjʊ’eɪʃən/ n. [物] 衰减
skeleton n. 骨架,骨骼
C3D首先被用来提取视觉特征,因为在我们的数据集中一个句子视频通常有许多连续的原始帧。
好处:三维CNN比二维CNN更能有效地学习时空背景,在LSTM学习中避免了长序列传输的依赖衰减。
2.Encoding:关键clips mining(online adaptive key clip mining method )
通过在视频中稀疏隐藏的有区别的手势或上半身骨骼变化,可以很容易地识别出信号。为了区别关键clips和less关键clips
优化之前连续的3D CNN特征与当前特征的残差平方和(residual square sum of previous successive 3D CNN features and current feature),并获取它们的线性相关关系
避免使用不太重要的剪辑(clips)进行过度训练——降低性能
3.Encoding:注意感知加权机制(attention-aware weighting mechanism )
intrinsic adj. 本质的,内在的
为了弱化less重要的clip,我们提出了三种pooling策略,通过LSTM1(模型的顶层LSTM层)进一步捕获视素的周期性特征。
在encoding阶段提出了一种基于时间维数的注意感知加权机制。它平衡了与整个翻译句子相关的源位置之间的内在关系
第二点中的key clips mining与此处得到的attention W 相结合作为Encoding层
4.Decoding:分别使用LSTM2和LSTM3实现了可视化和文字嵌入
相关工作
手工特征、传统识别模型、当前流行的深度特征和模型
特征表示:depth based feature || visual feature
auxiliary devices 辅助设备
depth sensors 深度传感器
isolated /'aɪsəleɪtɪd/ adj. 孤立的
discriminant ratio 判别率
joints between two temporal sequences 两个时间序列之间的关节
termed as XX 称为…
probability distribution 概率分布
1)基于深度的特征:point cloud点云、surface nomals 表面法线
缺点:成本高、较准不便
2)视觉特征:
HernandezVela等人提出了一种多模态特征融合的视觉深度词汇包
采用基于类似haar特征的AdaBoost算法,将较弱的分类器集成到较强的分类器中
HOG特征也被应用于手语识别
传统的识别模型
1)对于孤立符号或手势分类,采用SVM模型。例如,采用格拉斯曼协方差矩阵(Grassmann covariance matrix, GCM)模型作为SVM分类器的核心
2)考虑时间背景对序列动力学的影响。Celebi等人开发了加权动态时间扭曲(DTW)来优化两个时间序列之间关节的识别率
3)状态转移是用概率分布或图形模型来建模的(类似的特性可以分组成集群或块,称为状态)例如:各种隐马尔可夫模型(HMM) 、隐条件随机场、回归模型(AR),其中HMM应用最为广泛
深度特征/模型
prevalent adj. 流行的;普遍的
fuse v. 融合,
CNN、LSTM、RNN
提出了一种基于神经网络的多尺度手势检测框架
设计了一种三维CNN提取器,可以同时表示外观和运动变化
设计了两种流RNNs来融合多模态特征
提出了一种双向LSTM-RNN来处理动态变化的前后文
目前流行的趋势是将CNN特征提取器和序列学习模型的优点结合起来
比如deep DNN & HMM(DDNN) 、时序卷积与双向RNN 、递归三维卷积神经网络(R3DCNN)
这些混合方法有效地模拟了运动变化的时空背景。但它们大多是为孤立的手势或手语单词识别而设计的,不能方便地用于连续的手语句子翻译
时间边界上的连续SLT中的符号词得到了广泛的研究。
在深度学习中,嵌入了混合隐马尔可夫模型(HMM)和CTC等符号定位和单词对齐分析方法。与符号定位不同,我们的问题属于弱监督学习,缺乏对符号词的准确时间分离的监督
对于单词对齐,Koller等人将深度CNN嵌入到HMM框架中,解决了帧级对齐问题
Cui等人提出了一种LSTM & CTC来解决光泽(word)级对齐问题
问题:需要句子中的词序与视频相对应
我们的方法则没有这种限制
【词对齐】
【句子中的词序与video中词序】
【CNN 3D对视频特征的提取】
我们提出的方法
online heuristic algorithm 在线启发式算法
modality n. 形式
constituent n. 成分
使用神经网络完成对视素单元的编码和文本解码。输入为视频帧序列,输出文本单词序列
-> pretrained C3D提取卷积特征
-> 在线启发式算法分割key和less important 视频clips
-> 使用pooling和注意感知机制
-> HLSTM编码器压缩less important 视频clips 将关键剪辑总结为一个高层次的循环表示(viseme向量)
-> 解码器阶段输出一个长度可变的句子。
Online Key Clip Mining
low rank approximation 低秩估计
consecutive 连贯的
我们采用在线挖掘的方法自动获取可变长度的key clips。我们使用低秩近似方法得到连续帧流的线性相关。
计算前一帧与当前帧之间的特征的残差平方和(RSS)

利用相关矩阵M计算当前特征Fc处的
残差c。
计算相关系数βc
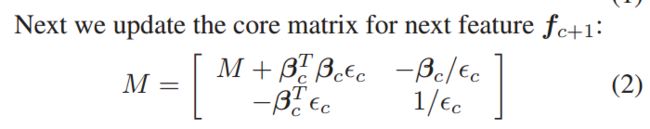
其中M总结了特征集的内在线性相关
βc 建立了Fc-1 and fc 之间的映射关系(每一帧上的相关权重)
Fc-1βc 则是对fc的近似重构,使用当了前时间c的Fc-1
【残差平方和计算】
【低秩近似】

optimal subset 最优子集
discrete frames 离散帧
accumulative error of consecutive variation 连续变化积累误差
monotonic increasing part单调增加的部分
保存单调上升的部分作为profit,因为残差不断增加使其无法被之前的帧所替代。同时这意味着在残差单调递减的部分,我们可以在误差不断下降的情况下,用之前的帧重构它们。
我们选择曲线单调递增的部分作为key clips
单调递减的部分作为less important clips
在HLSTM编码器中详细介绍了less important clips的策略
分层LSTM编码器Hierarchical LSTM Encoder
asymmetrical /eɪsɪ’metrɪkl adj. 非对称的
depict /dɪ’pɪkt/ vt. 描述;描画
如图1所示,我们的HLSTM模型是非对称的。
此外,编码和解码阶段有不同的长度,如:编码层是可变长度的。HLSTM旨在为符号语言学提供一种简洁有效的视觉表征。
cnn+3层LSTM encoding
输入:视频帧(f1,f2,…fn)
V=lstms[cnn(f1,f2…fn)]
输出:可视化嵌入表示V


本文将所有训练视频的特征平均个数表示为lave,集合n’’ = lave。LSTM2的编码时间步长
1.基于由著名的C3D模型提取的三维常规特征F = [f1, f2,…], fn]
利用顶部的LSTM1得到递归表示,
2.在采用集中策略和注意感知加权后,我们将LSTM1的周期性特征缩短为length-n’’
池化策略Pooling strategy
如果ht属于一个key clip,则除第一个时间步外,它都作为viseme向量。
如果ht属于一个不那么重要的剪辑,我们将对它的不那么重要的剪辑与下面相邻的关键剪辑的第一帧一起进行池化。三种池化策略选一种。池化后得到向量为n’维
池化后的向量n’ ->n’’。别问,少了就zero-padding,多了就systematic sampling
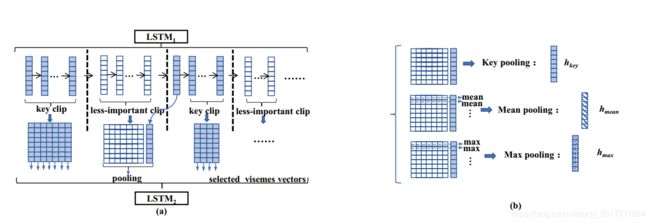
Attention-aware weighting
我们的注意感知机制将每个源位置与整个翻译句子进行加权
这意味着我们的注意力平衡了源位置之间的内在关系。
句子生成
conditional probability 条件概率
LSTM3递归地运行以输出长度不同的单词序列。
给定编码阶段的表示形式V,解码器估计输出序列的条件概率
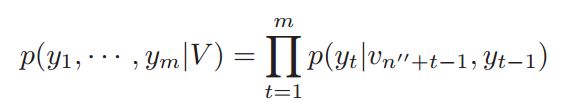
在解码阶段,LSTM2将补零向量作为空的视觉输入输入,LSTM3从开始标记()开始,依次输入单词嵌入向量
在训练过程中,LSTM3在每一步输入前一个ground truth word的嵌入向量
在测试时,使用LSTM3的输出(zt),softmax函数的最大概率来预测当前词(yt),我们选择词(yt)在词汇量中具有最大的概率,并将其单词嵌入向量输入到下一个时间步
本文利用生成句子的熵来学习模型参数。在训练过程中,只有在译码阶段才进行损耗优化。该方法利用随机梯度下降法对整个训练数据集的预测语句进行对数似然,使熵最大化。
当这个损失及时传播回来时,模型参数便更新。
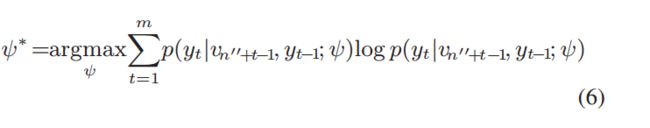
Experiment
1)Dataset
It contains 50*100=5000 videos. (Each sentence is played by 50 signers.)
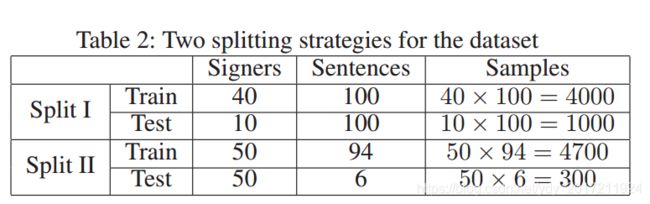
划分一:按手语表达者,同样的句子,40人作为training,10人作为test。
划分二:按句子。该策略精心选取6个句子作为测试集,其余94个句子作为训练集。分割满足了6个句子中的单词在其余94个句子中单独出现的约束条件,但每个单词的上下文、出现顺序和应用场景完全不同
2.Evaluation Metrics
1.准确率:翻译句子正确的概率
2.Acc-w :ratio of correct words to reference words in a sentence
3.Word error rate :the least number of operations to change translated sentence into the reference
4.BLEU, METEOR, ROUGE-L and CIDEr :semantics evaluation metrics widely used in NLP, NMT, and image Description Evaluation,
3.Comparison to Other Approache
比较模型
**1:compare HLSTM with the LSTM&CTC model **
比较模型(编解码器):
2.S2VT is a standard 2-layer stacked LSTM architecture with fixed encoder length
3.LSTM-E inputs deep 2D or 3D CNN features with mean pooling for visual sematic embedding
4.LSTM-Attention embeds an attention mechanism to capture the temporal relationship among frames
5.LSTM-global-Attention explores a global attention
mechanism for NMT
在接下来的实验中,如果没有指定,我们的HLSTM只使用C3D特性,没有时间注意机制。HLSTM为Split I选择均值池,为Spilt II选择最大值池
对于扩展,**HLSTM (SYS sampling)**删除了key clip的选择,并直接通过系统采样将LSTM1的output输入LSTM2, HLSTM-attn对HLSTM增加了时间上的关注。
结论
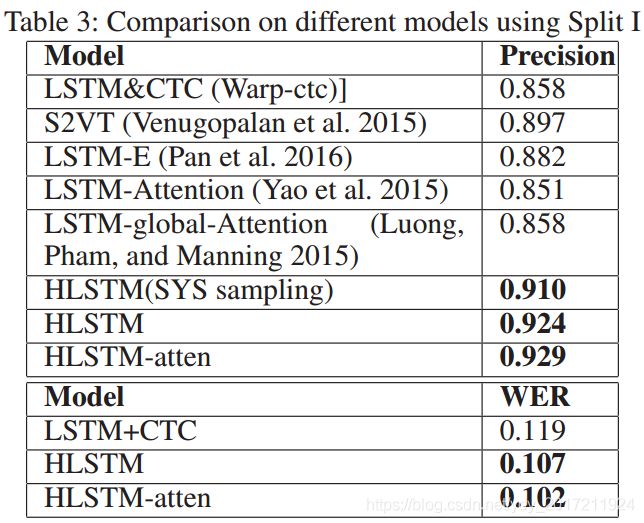
1.compared to LSTM&CTC, our model achieves better performance with higher precision and less WER
LSTM&CTC框架的目标是单词级对齐,这并不会很好地学习单词语义。
(1)Compared to S2VT with the fixed-length stacked architecture, our hierarchical architecture achieves better performance
(2)LSTM-E implements average pooling on whole features, while our model pools on subunit chunk (less-important volumes). Experimental result indicates our pooling approach has better performance.
(3)传统的关注机制侧重于源位置和当前目标位置的相关性,在我们的数据集上并不适用.如LSTM-Attention和LSTM-global-Attention.这些关注不断更新每次源位置的权重,并将全局影响扩散到当前目标位置.
不同的是,我们的注意策略强调沿时间维度的累积加权转移。它只是源位置的传递影响,直到当前位置.更加灵活
(4)最后,在我们的HLSTM中,HLSTM (SYS sampling)是最差的,
HLSTM优于HLSTM-attn,而HLSTM-attn的性能最好,这主要归功于密钥剪辑的选择和时间注意感知加权。
Model Validation
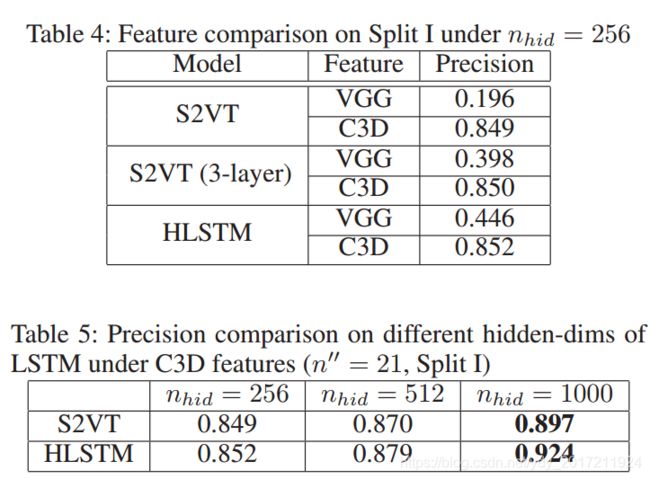
由表4:C3D和VGG特征比较
可以看出,无论是原始的S2VT、扩展的3层S2VT还是HLSTM, C3D特性都明显优于VGG特性。
由于具有紧凑的C3D特征,长序列学习中梯度消失的缺陷并不严重。在后续的实验中,采用C3D模型作为特征提取器
表5:nhid数量选择
当nhid设置较大时,精度提高。当nhid很小时,在多次随机试验下,实验结果是不稳定的。
但是,当nhid = 1000时,结果是稳定的
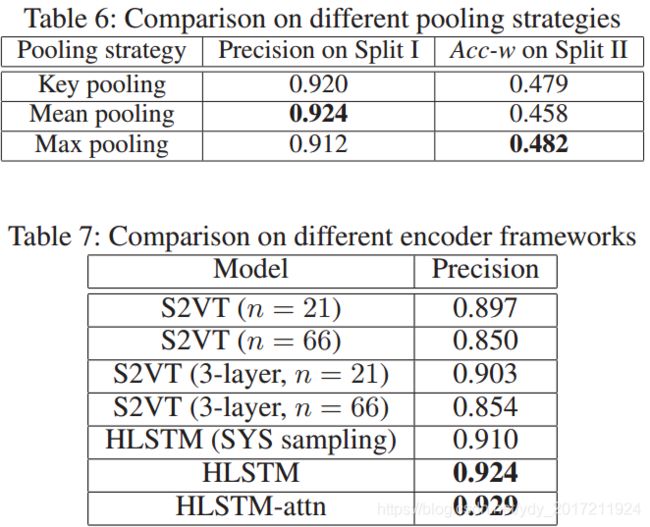
表6:不同池化策略
(split1)seen sentence:mean pooling is the best to remember the average response
(split2)unseen sentence :max pooling is the best to retain maximum response of discriminative gestures of distinct sign words
表7:不同n’'值的选择
66为所有训练样本下视频C3D特征的最大长度,21为平均长度。n = 21比n = 66得到更好的结果。紧凑的向量表示有助于实现更好的性能
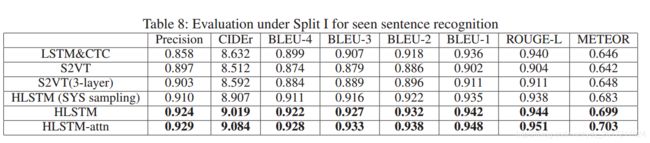
表8:不同评价指标下的结果

表9:在不可见句子下的结果