【数据可视化】基于scattertext的“十二五和十三五规划”文本分析(2021-02-16)
基于scattertext的“十二五和十三五规划”文本分析
二〇二一年是十四五规划的开篇之年。十二五和十三五规划的对比研究对开展和实施十四五规划有着非常重要的指导意义。
本文我将利用scattertext对十二五和十三五规划进行文本可视化分析。
文本库:
- 国民经济和社会发展第十二个五年规划纲要:全文共16篇,每篇又分多个章节
- 国民经济和社会发展第十三个五年规划纲要:全文共20篇,每篇又分多个章节
我将对以上篇章进行分词和语料分析,最终呈现多角度分析的可视化效果。
本文所有代码和运行得到的HTML文件结果均已上传至我的GitHub,需要的朋友可以自行下载。
1.数据处理
!pip install scattertext
!pip install spacy
!python -m spacy download zh_core_web_sm
import scattertext as st
import pandas as pd
import spacy
from scattertext import SampleCorpora, PhraseMachinePhrases, dense_rank, RankDifference, AssociationCompactor, produce_scattertext_explorer
from scattertext.CorpusFromPandas import CorpusFromPandas
读入数据。需要提前将文本按照格式存入CSV文件中。
df = pd.read_csv('plan.csv')
df.head()

字段解释
- speaker:每段文本的标题。
- text:每段文本的内容。
- party:所属类别。因为最终的结果是呈现在x,y轴的一个坐标系上,所以类别只能为两类。
df.tail()

2.绘制文字散布图
import zh_core_web_sm
nlp = zh_core_web_sm.load()
corpus = st.CorpusFromPandas(df, category_col='party', text_col='text', nlp=nlp).build()
来看一下十二五规划中提到的前100个高频词吧。
term_freq_df = corpus.get_term_freq_df()
term_freq_df['twelve score'] = corpus.get_scaled_f_scores('十二五')
Twelve_most = list(term_freq_df.sort_values(by='twelve score',ascending=False).index[:100])
print(Twelve_most)

可以看到“社会 管理”、“加快”、“转变”等词是十二五规划中重点强调的内容。
再来看一下十三五规划提到的前100个高频词吧。
term_freq_df['thirteen score'] = corpus.get_scaled_f_scores('十三五')
Thirteen_most = list(term_freq_df.sort_values(by='thirteen score',ascending=False).index[:100])
print(Thirteen_most)

可以看到“数据”、“贫困”、“法治”等词是十三五规划重点强调的内容。
开始绘图,生成可视化的HTML格式的文件。
html = st.produce_scattertext_explorer(corpus, category='十二五', category_name='十二五', not_category_name='十三五',
width_in_pixels=1000, metadata=df['speaker'])
open("scattertext_01.html",'wb').write(html.encode('utf-8'))
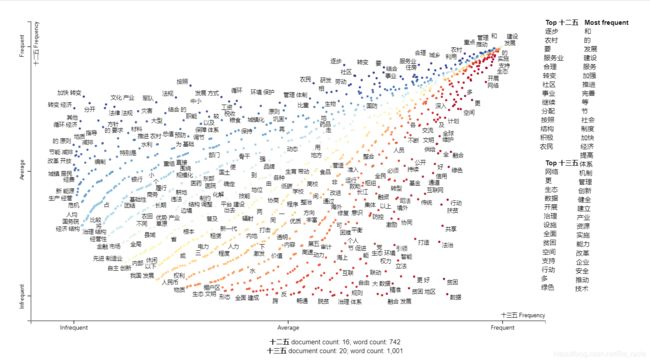
从上图可以看到十二五规划聚焦于转变、循环、节能等,十三五规划聚焦于数据、脱贫、法治等。建设和发展则是二者共同的主题。
在图中用鼠标点击“转变 经济”。

从上图可以看到关于“转变 经济”一词,十二五提到的频率要高于十三五。
在图中用鼠标点击“数据”。

显然,“数据”这个概念是十三五规划最新提出来的。
3.构建主题模型
接下来,我们构建主题模型。这里的主题是通过观察上面的可视化结果进行选择的。我一共选择了文化、民生、脱贫、生态、改革、科技六大主题。
topic_model = {
'文化':['文化','文明'],
'民生':['收入','社区','分配','管理'],
'脱贫':['脱贫','地区','农村','摘帽'],
'生态':['绿色','生态','环境','环保'],
'改革':['发展','转变','深入','循环','创新'],
'科技':['数据','互联网','网络','现代化','科技']
}
topic_feature_builder = st.FeatsFromTopicModel(topic_model)
topic_corpus = st.CorpusFromParsedDocuments(df,category_col='party',parsed_col='text',feats_from_spacy_doc=topic_feature_builder).build()
html = st.produce_scattertext_explorer(
topic_corpus,
category='十二五',
category_name='十二五',
not_category_name='十三五',
width_in_pixels=1000,
metadata=df['speaker'],
use_non_text_features=True,
use_full_doc=True,
pmi_threshold_coefficient=0,
topic_model_term_lists=topic_feature_builder.get_top_model_term_lists()
)
open('scattertext_02.html','wb').write(html.encode('utf-8'))

点击“科技”主题

可以看到“科技”这一主题在十二五和十三五中的提及情况。
4.利用SVD降维重绘图形
利用SVD降维,字词的向量表示。
from sklearn.feature_extraction.text import TfidfTransformer
from scipy.sparse.linalg import svds
df['parse'] = df['text'].apply(st.whitespace_nlp_with_sentences)
corpus = (st.CorpusFromParsedDocuments(df,category_col='party',parsed_col='parse').build()
.get_stoplisted_unigram_corpus()
.remove_infrequent_words(minimum_term_count=1,term_ranker=st.OncePerDocFrequencyRanker))
embeddings = TfidfTransformer().fit_transform(corpus.get_term_doc_mat())
corpus.get_num_docs()
corpus.get_num_terms()
embeddings = embeddings.T
U, S, VT = svds(embeddings, k=3, maxiter=20000, which='LM')
print(U.shape, S.shape, VT.shape)
x_dim=0
y_dim=1
projection = pd.DataFrame({
'term':corpus.get_terms(),'x':U.T[x_dim],'y':U.T[y_dim]}).set_index('term')
print(len(projection))
projection

html = st.produce_pca_explorer(corpus,
category='十二五',
category_name='十二五',
not_category_name='十三五',
projection=projection,
metadata=df['speaker'],
width_in_pixels=1000,
scaler = st.scale_neg_1_to_1_with_zero_mean,
x_dim=x_dim,
y_dim=y_dim)
open('scattertext_03.html','wb').write(html.encode('utf-8'))

5.以文章为单位绘图
#用句子断开文章
df['parse'] = df['text'].apply(st.whitespace_nlp_with_sentences)
corpus = (st.CorpusFromParsedDocuments(df,category_col='party',parsed_col='parse').build()
.get_stoplisted_unigram_corpus())
corpus = corpus.add_doc_names_as_metadata(corpus.get_df()['speaker'])
embeddings = TfidfTransformer().fit_transform(corpus.get_term_doc_mat())
#SVD降维
u, s, vt = svds(embeddings, k=3, maxiter=20000, which='LM')
projection = pd.DataFrame({
'term':corpus.get_metadata(), 'x':u.T[0], 'y':u.T[1]}).set_index('term')
category='十二五'
scores = (corpus.get_category_ids() == corpus.get_categories().index(category)).astype(int)
html = st.produce_pca_explorer(corpus,
category=category,
category_name='十二五',
not_category_name='十三五',
metadata=df['speaker'],
width_in_pixels=1000,
scaler = st.scale_neg_1_to_1_with_zero_mean,
show_axes=False,
use_non_text_features=True,
use_full_doc=True,
projection=projection,
scores=scores,
show_top_terms=True)
open('scattertext_04.html','wb').write(html.encode('utf-8'))

6.总结
从前面的可视化分析可以看出,也会出现一些“和”、“的”、“等”、“第一节”、“第二节”等不在我们期望范围内的词,原因在于我导入的是未经处理的文本信息,也就是没有经过分词的完整篇章,而scattertext会自动进行分词,且不会做出任何筛选。
为了保留语料的完整性,我保留下来了这些词,当然我们可以通过技术手段筛选掉这些词,从而达到更好的可视化分析效果。
接下来,我希望可以利用streamlit或者是dash基于本文的基础上构建一个文本可视化分析小系统,用户只需上传自己需要分析的文本就可以自动地得到分析结果。
本文所有的代码和运行得到的HTML文件结果均已上传至我的GitHub,需要的朋友可以自行下载。
https://github.com/Beracle/05-Scattertext-Twelve-and-Thirteen-Plan