爬虫实战:爬取相亲网站,看看当下年轻小姐姐的择偶观。
前言
到了一定年龄,父母可能会催你找女朋友,结婚。
大多数的父母催婚,是父母渐渐老了,想让你找个人照顾你,有热饭吃,生病了有人照顾。在外面不被人欺负。
当然,也有一部分来自周围人的压力,跟你同龄的孩子差不多都结婚了,你父母的压力自然就来了。跟父母给孩子报课外辅导班的心理一样。
很多时候让你成家立业,在父母看来,帮你完成成家的任务,父母的一大任务算是完成了。不然单身的男女每个家,在父母心里始终是个心结,这种心情,小城镇特别的突出。
父母帮你完成了结婚的任务,不需要像以前那样辛辛苦苦奔波赚钱了。
催婚,第一,是父母对你的关心。
第二,是父母的私心(虽然有时候这种私心是被动的私心)
第三,父母养育任务的完成,要开始享受生活了。
所以,今天作者就来爬取下交友网站,看看小姐姐的择偶观。
结合博主的年龄
所以博主的筛选条件是
重庆,年龄21-27岁,未婚小姐姐。
大姐姐们的择偶观我并不关心。
对技术不感兴趣的,下拉到后面看结论。
技术部分
网站选取
世纪佳缘得到的信息如图,对择偶条件未怎么提及。所以该网站放弃。
世纪佳缘爬取代码
```python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2021/2/15
#@email:[email protected]
# -*- coding: utf-8 -*-
import requests
import json
import pandas as pd
from requests.exceptions import ReadTimeout, ConnectionError, RequestException
def get_page(url):#获取请求并返回解析页面,
'''
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36',
'Cookie': 'guider_quick_search=on; SESSION_HASH=0ea6881596be6958acab86601f12c97fdc211b1d; jy_refer=www.baidu.com; accessID=20210215105936945652; user_access=1; Qs_lvt_336351=1613358012; _gscu_1380850711=133580687kjmry14; _gscbrs_1380850711=1; COMMON_HASH=03ccf3f907328da89142987423a9215b; stadate1=271766541; myloc=50%7C5001; myage=25; mysex=m; myuid=271766541; myincome=40; Qs_pv_336351=1107463009737048200%2C2408036345389375500%2C1494836557490850800%2C3408124253653422600%2C1396723355418865400; PHPSESSID=3699194bbb0a1fb7c7f3c46c813f162c; pop_avatar=1; PROFILE=272766541%3A%25E6%2580%25BB%25E8%25A3%2581%25E4%25BD%2599%3Am%3Aimages1.jyimg.com%2Fw4%2Fglobal%2Fi%3A0%3A%3A1%3Azwzp_m.jpg%3A1%3A1%3A50%3A10%3A3; main_search:272766541=%7C%7C%7C00; RAW_HASH=PBalPtMnGoSGsXuyDvb3BTznuvyG8MajCm%2AWrcDW%2Av1YkfseTjLUbLLCCHeQJ0B25bjAa%2Ak4IbveQI5X4uzQhvvD3qbP6ajy90MEyOpZDZzznTM.; is_searchv2=1; pop_1557218166=1613364302492; pop_time=1613363558012'
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'unicode_escape' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
if response.status_code == 200:
return response.text
except ReadTimeout: # 超时
#get_page(url)#如果是这行则是递归调用函数
return None
except ConnectionError: # 网络问题
#get_page(url)
return None
except RequestException: # 其他问题
#get_page(url)
return None
#解析网页
def pase_page(url):
html = get_page(url)
'''
功能:尝试解析其结构,获取所需内容并保存进CSV
'''
if html is not None:
html = str(html)
s = json.loads(html,strict=False) # ka添加参数 strict=False。否则会出现 错误信息如json.decoder.JSONDecodeError: Invalid control character at: line 1 column 4007 (char 4006)
usrinfolist = [] # 存放一页内所有小姐姐的信息
for key in s['userInfo']:
personlist = [] # 存放一个人的信息
uid = key['uid']
nickname = key['nickname']
sex = key['sex']
age = key['age']
work_location = key['work_location']
height = key['height']
education = key['education']
marriage = key['marriage']
income = key['income']
matchCondition = key['matchCondition']
shortnote = key['shortnote']
image = key['image']
personlist.append(uid)
personlist.append(nickname)
personlist.append(sex)
personlist.append(age)
personlist.append(work_location)
personlist.append(height)
personlist.append(education)
personlist.append(matchCondition)
personlist.append(marriage)
personlist.append(income)
personlist.append(shortnote)
personlist.append(image)
usrinfolist.append(personlist)
dataframe = pd.DataFrame(usrinfolist)
dataframe.to_csv('世纪佳缘小姐姐信息.csv', mode='a+', index=False, header=False) # mode='a+'追加写入
print('当前页数{0}'.format(page))
else:
print('解析失败')
import threading
if __name__ == '__main__':
for page in range(1, 5000,3):
url1 = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=%s&f=select'+str(page)
#pase_page(url1)
url2 = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=%s&f=select' + str(
page+1)
url3 = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=%s&f=select' + str(
page + 2)
t1 = threading.Thread(target=pase_page, kwargs={
'url':url1}) # 线程1
t2 = threading.Thread(target=pase_page, kwargs={
'url':url2}) # 线程2
t3 = threading.Thread(target=pase_page, kwargs={
'url':url3}) # 线程3
t1.start()
t2.start()
t3.start()
所以我爬取其他网站
http://www.lovewzly.com/jiaoyou.html
网站主页图

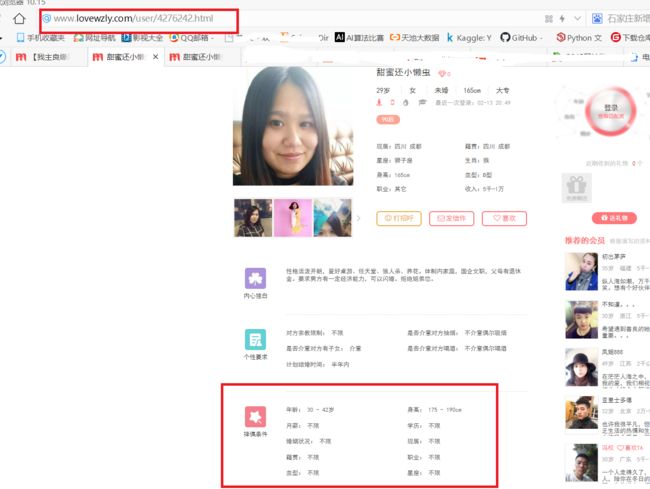
点开一个小姐姐,发现有择偶观信息可以提取。
发现该小姐姐的网址链接为http://www.lovewzly.com/user/4270839.html
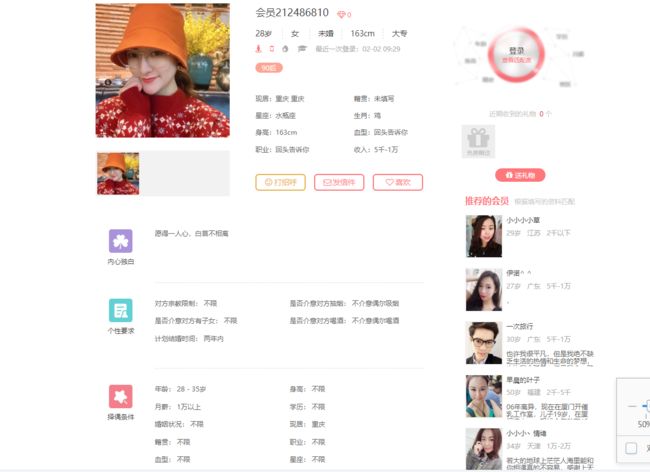
在主页中查看源码,我们可以发现小姐姐的网页地址链接可以从主页图data-uid分析得到。

于是我们可以认为,爬取主页,得到所有小姐姐的data-uid,然后遍历每一个data-uid,根据data-uid拼接小姐姐网页的地址。然后分析该小姐姐的择偶观。
网页分析
从sources,我们可以找到城市年龄,星座等的数字标签。这些我们用来自己动手写函数,用于筛选。
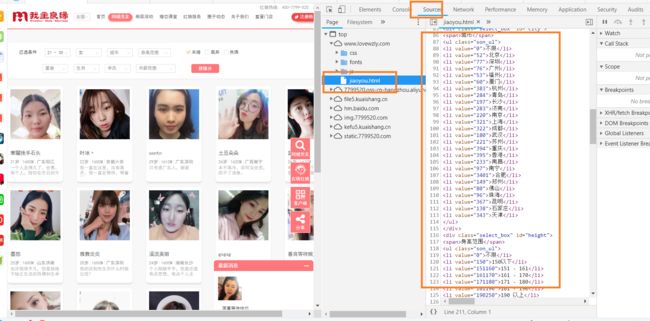
网页链接如图
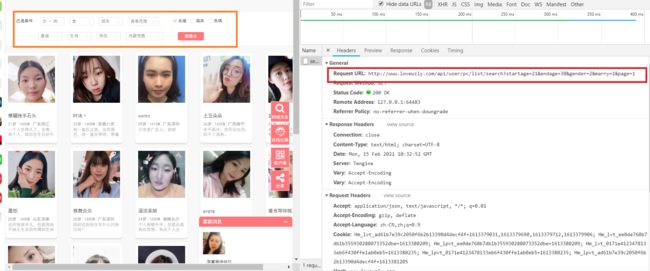
下拉查看参数。因为我只勾选了几个条件,所以网页链接呈现出的参数少。

查看数据,如图
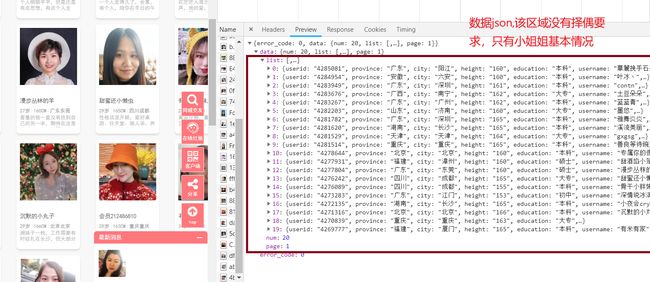 从上发现数据没有我想要的择偶要求。
所以我在此网页只取userid。然后构建小姐姐网页地址如http://www.lovewzly.com/user/4276242.html,再从该网页中提取小姐姐的信息和择偶条件.
从上发现数据没有我想要的择偶要求。
所以我在此网页只取userid。然后构建小姐姐网页地址如http://www.lovewzly.com/user/4276242.html,再从该网页中提取小姐姐的信息和择偶条件.
代码1:根据条件提取小姐姐的userid
本次编程语言:python。
其他语言也在学,但尚未成长为我的主语言,还不能杀敌。
该代码中我只设置了筛选条件:小姐姐年龄,性别,城市,是否婚配。
import requests
from requests.exceptions import ReadTimeout, ConnectionError, RequestException
import pandas as pd
import numpy as np
def set_age():
age = int(input("请输入对方的期望年龄:")) # 强制字符串转整型
if 21 <= age <= 30:
startage = 21
endage = 30
elif 31 <= age <= 40:
startage = 31
endage = 40
return startage, endage
# 设置性别
def set_sex():
sex = input("请输入对方的期望性别:")
if sex == '男':
gender = 1
elif sex == '女':
gender = 2
return gender
# 设置城市
def set_city():
city = input("请输入对方的期望城市:")
if city == '北京':
cityid = 52
elif city == '深圳':
cityid = 77
elif city == '广州':
cityid = 76
elif city == '福州':
cityid = 53
elif city == '厦门':
cityid = 60
elif city == '杭州':
cityid = 383
elif city == '青岛':
cityid = 284
elif city == '长沙':
cityid = 197
elif city == '济南':
cityid = 283
elif city == '南京':
cityid = 220
elif city == '香港':
cityid = 395
elif city == '上海':
cityid = 321
elif city == '成都':
cityid = 322
elif city == '武汉':
cityid = 180
elif city == '苏州':
cityid = 221
elif city == '重庆':
cityid = 394
elif city == '香港':
cityid = 395
elif city == '南昌':
cityid = 233
elif city == '南宁':
cityid = 97
elif city == '合肥':
cityid = 3401
elif city == '郑州':
cityid = 149
elif city == '佛山':
cityid = 80
elif city == '珠海':
cityid = 96
elif city == '昆明':
cityid = 397
elif city == '石家庄':
cityid = 138
elif city == '天津':
cityid = 143
return cityid
#是否婚配
def marry():
print('请输入是否婚配。输入字符如:未婚,离异,丧偶')
marry= input("输入是否婚配:")
if marry == '未婚':
marryid=1
elif marry=='离异':
marryid=3
elif marry=='丧偶':
marryid=2
return marryid
# 解析网页
def get_info(page, startage, endage, gender, cityid, marryid):
# http://www.lovewzly.com/api/user/pc/list/search?startage=21&endage=30&gender=2&cityid=394&marry=1&page=1
# 字符串格式化 %s
url = 'http://www.lovewzly.com/api/user/pc/list/search?startage={}&endage={}&gender={}&cityid={}&marry={}&page={}'.format(
startage, endage, gender, cityid, marryid, page)
try:
# response = requests.get(url).json() #简单写法
response = requests.get(url)
if response.status_code == 200:
result = response.json()
return result
except ReadTimeout: # 超时
print('Timeout')
return None
except ConnectionError: # 网络问题
print('Connection error')
return None
except RequestException: # 其他问题
print('Error')
return None
#主函数
# 主程序
def main():
print("请输入你的筛选条件,开始本次姻缘:")
# 调用上面编写的函数
startage, endage = set_age()#年龄
gender = set_sex()#性别
cityid = set_city()#城市
marryid=marry()#是否婚配
for i in range(1, 100): # 取1~100的内容。大多数情况下没有100页
# 获取抓取到的json数据
json = get_info(i, startage, endage, gender, cityid,marryid)
# print(json['data']['list'])
# 保存图片
for item in json['data']['list']:
userid = item['userid']
# print(userid)
userid = np.array(userid)
userid = pd.Series(userid)
userid.to_csv('小姐姐信息userid.csv', mode='a+', index=False, header=False) # # mode='a+'追加写入
if __name__ =='__main__':
main()
print('读取结束')
程序图

结果图。在此条件下,在该网站只找到454个重庆小姐姐。

再次运行程序,目标城市:成都,上海。将所有结果整合成一张

代码2:根据userid提取小姐姐的个人信息和择偶观
选项一个小姐姐单击,审查元素,发现信息直接显示在网页源代码中,没有经过渲染等。所以该部分信息提取没有难度,不再细讲。

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2021/2/15
#@email:[email protected]
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import re
def get_page(url):#获取请求并返回解析页面,offest,keyword为可变参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
try:
response = requests.get(url,headers = headers,timeout=10)
response.encoding = 'utf-8' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
if response.status_code == 200 :
return response.text
except ConnectionError:
print('程序错误')
return None
#解析网页
def pase_page(url,i):
html = get_page(url)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"----------------------------------小姐姐信息------------------------------"
"--昵称--"
nickname=soup.select('.view.fl.c6 .nick.c3e')
nickname=''.join([i.get_text() for i in nickname])
"--年龄--"
age=soup.select('.f18.c3e.p2 .age.s1')
age=''.join(i.get_text()for i in age)
"--身高--"
height=soup.select('.f18.c3e.p2 .height')
height=''.join(i.get_text()for i in height)
"--学历--"
education=soup.select('.f18.c3e.p2 .education')
education=''.join(i.get_text()for i in education)
"--现居地--"
present_address=soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div:nth-child(1) > div.view.fl.c6 > ul > li:nth-child(1) > span')
present_address=''.join(i.get_text() for i in present_address)
"--职业--"
professional=soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div:nth-child(1) > div.view.fl.c6 > ul > li:nth-child(7) > span')
professional=''.join(i.get_text() for i in professional)
"--收入--"
income=soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div:nth-child(1) > div.view.fl.c6 > ul > li:nth-child(8) > span')
income=''.join(i.get_text()for i in income)
"--个人照链接--"
photo=soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div:nth-child(1) > div.photo.fl > div.imgwrap > ul > li:nth-child(1) > img')
photo=str(photo)
pat1 = '.+src="(.+)"'
photo=re.compile(pat1).findall(photo)
"----------------------------------择偶要求------------------------------"
"--是否介意对方抽烟--"
smoking=soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(2) > div.body > ul > li:nth-child(2)')
smoking=''.join(i.get_text() for i in smoking)
"--是否介意对方喝酒--"
drinking = soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(2) > div.body > ul > li:nth-child(4)')
drinking=''.join(i.get_text() for i in drinking)
"--是否介意对方有子女--"
children = soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(2) > div.body > ul > li:nth-child(3)')
children=''.join(i.get_text()for i in children)
"--择偶年龄--"
age_man = soup.select('#userid > div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(3) > div.body > ul > li:nth-child(1)')
age_man=''.join(i.get_text()for i in age_man)
"--择偶身高--"
height_man = soup.select('#userid > div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(3) > div.body > ul > li:nth-child(2)')
height_man=''.join(i.get_text()for i in height_man)
"--择偶月薪--"
money_man = soup.select('#userid > div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(3) > div.body > ul > li:nth-child(3)')
money_man=''.join(i.get_text()for i in money_man)
"--择偶学历--"
study_man = soup.select('div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(3) > div.body > ul > li:nth-child(4)')
study_man=''.join(i.get_text()for i in study_man)
"--择偶职业--"
professional_man = soup.select('#userid > div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(3) > div.body > ul > li:nth-child(8)')
professional_man=''.join(i.get_text() for i in professional_man)
"--择偶现居地--"
present_addressman = soup.select('#userid > div.cm-wrapin.user-warpin > div.clearfix > div.users-left > div.clearfix.user-detail > div:nth-child(3) > div.body > ul > li:nth-child(6)')
present_addressman=''.join(i.get_text()for i in present_addressman)
"----------------------------------所有信息写入表格------------------------------"
information = [nickname,age,height,education,present_address,professional,income,photo,
smoking,drinking,children,age_man,height_man,money_man,study_man,professional_man, present_addressman]
information = np.array(information)
information = information.reshape(-1, 17)
information = pd.DataFrame(information,
columns=[nickname,age,height,education,present_address,professional,income,photo,
smoking,drinking,children,age_man,height_man,money_man,study_man,professional_man, present_addressman])
if i==0:
information.to_csv('相亲网站小姐姐数据.csv', mode='a+', index=False, header=0) # mode='a+'追加写入
else:
information.to_csv('相亲网站小姐姐数据.csv', mode='a+', index=False, header=False) # mode='a+'追加写入
else:
print('解析错误')
def main():
f = open('小姐姐信息.txt', encoding='gbk')
txt = []
for line in f:
txt.append(line.strip())
#txt = np.array(txt)[0]
i=0
for userid in txt: # 遍历userid
print(i)
#userid=4283676
base_url = 'http://www.lovewzly.com/user/'+str(userid)+'.html'
pase_page(base_url,i)
i+=1
#print(html)
if __name__ =='__main__':
main()
得到的数据如下,2500多条数据
数据分析部分
数据分析部分,我懒得写代码了,有些累了。
简单操作,通过表格的数据透视表来简单分析下。
数据透视表教程
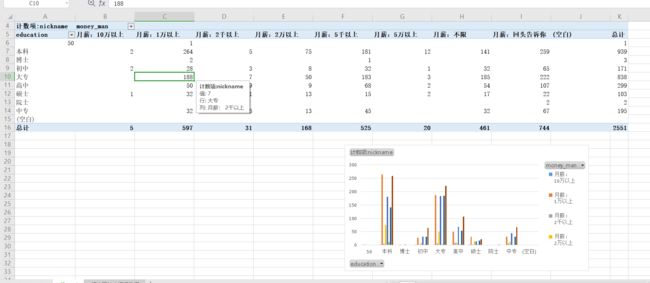
对对象工资分析
在有工资字段内,58.78%的小姐姐要求对象月入1万以上。
(钱果然还是万能的,前段时间听说离我很近的一个成功企业家出轨一个比他女儿稍微大点的小姐姐,禽兽呀)

单身小姐姐的学历分布
以本科和专科生居多。果然学历越低越不容易单身。

查看各个学历阶段小姐姐对对象工资要求
本科生和专科生要求对象月入1万的人数为294,188
查看小姐姐与对象工资的区别
横坐标为小姐姐的工资,纵坐标为对象工资统计个数。能月收入5千到1万的,基本都要求对象月收入1万以上。

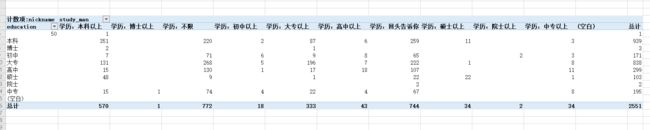
小姐姐对象学历要求
横坐标为小姐姐学历,纵坐标为对象学历
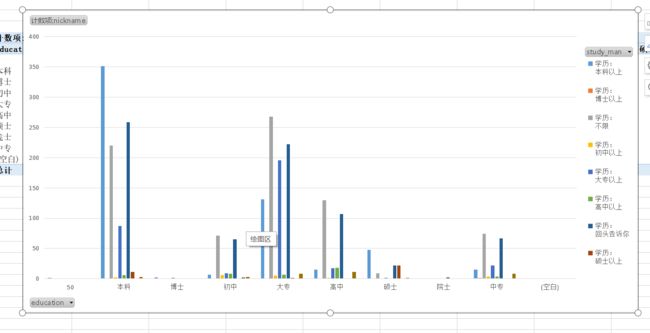
y轴为小姐姐学历,x轴为对象。学历为本科的小姐姐还有不少人要求对象为初高中专科。
小姐姐对象身高要求
字段太多了,简单截图看下,几个比较大的值170-180

![]()
通过此文,我发现了小姐姐们的择偶观。
此刻的我很膨胀,我觉得她们都配不上我。
![]()
![]()
![]()
![]()
![]()