书名信息在其下h3 > a元素的title属性中,如A Light in the...; 书价信息在其下元素的文本中,如
£51.77
。
【爬虫】2.scrapy简介&示例
文章目录
- 简介
- 使用
-
- 需求
- 创建项目
- 分析界面
- 实现Spider
- 运行spider
简介
Scrapy是一个使用Python语言(基于Twisted框架)编写的开源网络爬虫框架,目前由Scrapinghub Ltd维护。Scrapy简单易用、灵活易拓展、开发社区活跃,并且是跨平台的。在Linux、MaxOS以及Windows平台都可以使用。
安装验证:
pip install scrapy
import scrapy
scrapy.version_info
使用
需求
抓取在专门供爬虫初学者训练爬虫技术的网站 上爬取书籍信息,如图所示。

创建项目
首先,我们要创建一个Scrapy项目,在shell中使用scrapy startproject命令:

分析界面
编写爬虫程序之前,首先需要对待爬取的页面进行分析,主流的浏览器中都带有分析页面的工具或插件分析页面。
1.数据信息 在浏览器中打开页面http://books.toscrape.com,选中其中任意 一本书并右击,然后选择“审查元素”,查看其HTML代码,如图1-2所示。
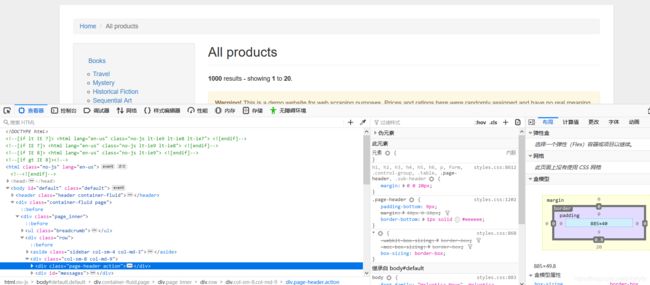 可以看到,每一本书的信息包裹在
可以看到,每一本书的信息包裹在
2.链接信息为第一页书籍列表页面,可以通过单击next按钮访问下一 页,选中页面下方的next按钮并右击,然后选择“审查元素”,查看其HTML代码
可以发现,下一页的URL在ul.pager > li.next > a元素的href属性中,是 一个相对URL地址,如
实现Spider
分析完页面后,接下来编写爬虫。在Scrapy中编写一个爬虫,即实现一个scrapy.Spider的子类。 实现爬虫的Python文件应位于exmaple/spiders目录下,在该目录下创建新文件book_spider.py。然后,在book_spider.py中实现爬虫BooksSpider, 代码如下:
import scrapy
class BooksSpider(scrapy.Spider):
# 定义唯一标识
name = "books"
# 爬虫爬取起点网页
start_urls = [
'http://books.toscrape.com/',
]
def parse(self, response):
# 提取数据
# 每一本书的信息在中
# css()方法找到所有这样的article元素,并依次迭代
for book in response.css('article.product_pod'):
# 选择器可以通过命令行工具就行调试
# 书名信息在article>h3>a元素的title属性里
# 例 如:A Light in the...
# 书价信息在的TEXT中。
# 例如:£51.77
yield {
# xpath 语法 @ATTR 为选中为名ATTR的属性节点
'name': book.xpath('h3/a/@title').get(),
'price': book.css('p.price_color::text').get(),
}
# 检查分页
# 提取下一页的链接
#例如:next
next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
if next_url:
next_url = response.urljoin(next_url)
# 构造新的 Request 对象
yield scrapy.Request(next_url, callback=self.parse)
下面对BooksSpider的实现做简单说明。
- name属性 一个Scrapy项目中可能有多个爬虫,每个爬虫的name属 性是其自身的唯一标识,在一个项目中不能有同名的爬 虫,本例中的爬虫取名为’books’。
- start_urls属性 一个爬虫总要从某个(或某些)页面开始爬取,我们称 这样的页面为起始爬取点,start_urls属性用来设置一个 爬虫的起始爬取点。在本例中只有一个起始爬取 点’http://books.toscrape.com’。
- parse方法 当一个页面下载完成后,Scrapy引擎会回调一个我们指 定的页面解析函数(默认为parse方法)解析页面。
一个 页面解析函数通常需要完成以下两个任务:
⇒ \mathop \Rightarrow ⇒ (1)提取页面中的数据(使用XPath或CSS选择器)。
⇒ \mathop \Rightarrow ⇒ (2)提取页面中的链接,并产生对链接页面的下载请求。
页面解析函数通常被实现成一个生成器函数,每一项从页面中提取的数据以及每一个对链接页面的下载请求都由yield语句提交给Scrapy引擎
运行spider
在 shell命令中运行 scrapy crawl 。
 其中 SPIDER NAME 是指在代码中设置的唯一标识,例如本例中的books。
其中 SPIDER NAME 是指在代码中设置的唯一标识,例如本例中的books。