- 斤斤计较的婚姻到底有多难?
白心之岂必有为
很多人私聊我会问到在哪个人群当中斤斤计较的人最多?我都会回答他,一般婚姻出现问题的斤斤计较的人士会非常多,以我多年经验,在婚姻落的一塌糊涂的人当中,斤斤计较的人数占比在20~30%以上,也就是说10个婚姻出现问题的斤斤计较的人有2-3个有多不减。在婚姻出问题当中,有大量的心理不平衡的、尖酸刻薄的怨妇。在婚姻中仅斤斤计较有两种类型:第一种是物质上的,另一种是精神上的。在物质与精神上抠门已经严重的影响
- 底层逆袭到底有多难,不甘平凡的你准备好了吗?让吴起给你说说
造命者说
底层逆袭到底有多难,不甘平凡的你准备好了吗?让吴起给你说说我叫吴起,生于公元前440年的战国初期,正是群雄并起、天下纷争不断的时候。后人说我是军事家、政治家、改革家,是兵家代表人物。评价我一生历仕鲁、魏、楚三国,通晓兵家、法家、儒家三家思想,在内政军事上都有极高的成就。周安王二十一年(公元前381年),因变法得罪守旧贵族,被人乱箭射死。我出生在卫国一个“家累万金”的富有家庭,从年轻时候起就不甘平凡
- 18-115 一切思考不能有效转化为行动,都TM是扯淡!
成长时间线
7月25号写了一篇关于为什么会断更如此严重的反思,然而,之后日更仅仅维持了一周,又出现了这次更严重的现象。从8月2号到昨天8月6号,5天!又是5天没有更文!虽然这次断更时间和上次一样,那为什么说这次更严重?因为上次之后就分析了问题的原因,以及应该如何解决,按理说应该会好转,然而,没过几天严重断更的现象再次出现,想想,经过反思,问题依然没有解决与改变,这让我有些担忧。到底是哪里出了问题,难道我就真的
- 少了生活气息
我爱大草莓
最近啊,总觉得自己日更的内容缺了点什么。我仔细地想,大概是少了些生活气息。这两三个月减少了许多与别人相处的时间,独自生活,偶尔只是出去买菜,总觉得生活好像变空了许多。买菜的时候会跟档口的阿姨聊一两句话,让自己感觉在真实地生活着。幸好我也不是一宅到底,偶尔周末也会约着跟好朋友见面,面对面交流跟隔着屏幕交流,效果还是不一样的,至少有更为真实的生活感。写作不仅需要有阅读量,有文笔,生活阅历也是非常重要的
- 2022-11-17
无奇君
又去了一次社康,这次是急性支气管炎……太难了。半夜就猛咳,天天咳醒,还好他戴海绵耳塞睡吵不到他,要不然对他来说也是种煎熬。一累也会猛咳,希望这次是最后一次吃药,吃完就好。又想把头发剪短了,顺便染个色。可是刚刚去看人家还没开门,不是休息日老板好佛系。理发店是个夫妻店,一年多前刚搬来的时候老板还没对象呢,当时聊天老板就说希望能找个对象一起两个人守着店都比上班强。不久后再去他已经有对象了,而且在店里帮忙
- 烟花美,但瞬间即逝的样子像极了爱情。
胡萝卜很甜
我见过烟花在天上绽放时绚烂的模样也目睹过爱情消逝曾经相爱的两人变冷漠的样子其实我特别喜欢烟花绽放的艳丽大年初一凌晨的烟花手机拍的没有眼睛看到的美但是烟花虽美,稍纵即逝,眼睛刚记录下它的美好,就转眼消失不见。天空又恢复一片黑。烟花的样子像极了爱情啊……不论曾经多么山盟海誓,海枯石烂。只要吵架或者分手。就变得那么冷漠,那么陌生。你甚至开始怀疑你有过爱情么?真正的爱情到底是什么样子。来的快去的也快么?对
- 心有蓝天白云,爱情便会晴空万里,然后有花香有鸟鸣有美好的未来
曹十二吖
丁南的婚姻,来自于一场她对生命的对比。她曾经说过,当她最爱的母亲用生命去逼迫她结婚的时候,她曾一度不理解到愤怒,甚至于想过用轻生来对抗母亲的不理智。庆幸的是,丁南是一个自我调节能力非常强的人,她想如果我连死亡都不怕,还怕不能经营好一段婚姻吗?抱着这样的念头,24年没有谈过恋爱的她,用短短三个月的时间,完成了少女到女人的蜕变。她曾经说过:“我要把自己最珍贵的东西留给自己命中注定的那个人。”闺蜜几人中
- 直返的东西正品吗?直返APP安全吗?直返是正规平台吗?
氧惠购物达人
亲们,你们是不是经常在直返APP上买东西呀?但是,你们有没有想过,里面的东西到底是不是正品呢?这个APP安全吗?它是不是一个正规的平台呀?别着急,今天我就来给大家揭秘一下!氧惠APP(带货领导者)——是与以往完全不同的抖客+淘客app!2023全新模式,我的直推也会放到你下面。主打:带货高补贴,深受各位带货团队长喜爱(每天出单带货几十万单)。注册即可享受高补贴+0撸+捡漏等带货新体验。送万元推广大
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
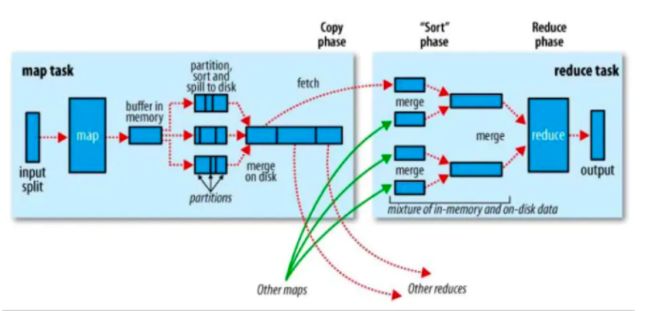
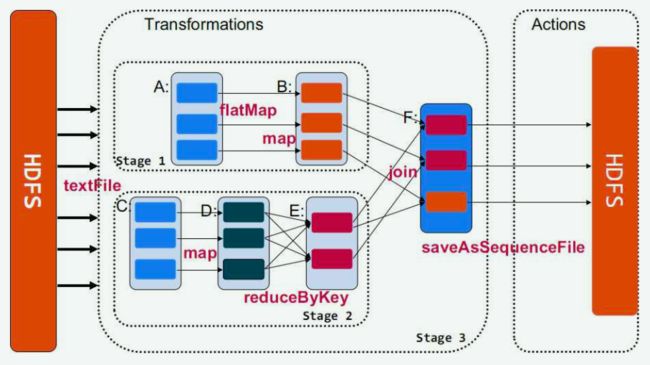
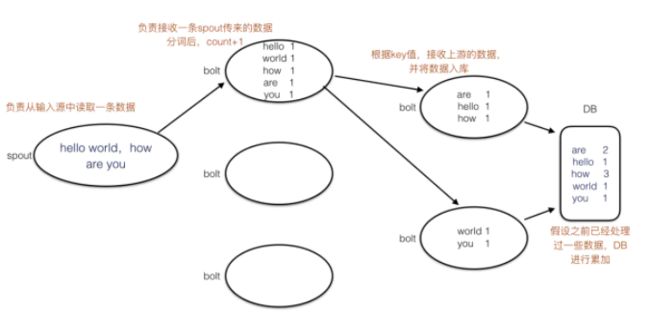
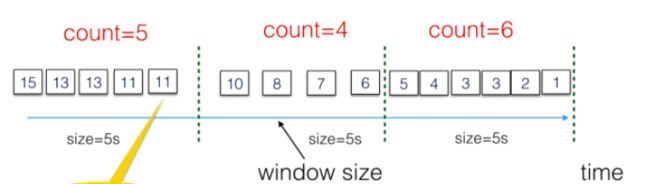
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 广州会刊小程序开发公司哪家好|开发多少钱费用|专业外包服务
红匣子实力推荐
在选择广州会刊小程序开发公司时,有几个关键因素需要考虑。首先,您应该确定自己的需求和目标,以便找到最合适的开发公司。其次,您需要考虑公司的经验和专业知识。最后,您还应该考虑公司的信誉和口碑。开发-联系电话:13642679953(微信同号)首先,您应该明确自己的需求和目标。会刊小程序是一种用于展示会议信息和日程安排的应用程序。在选择开发公司之前,您应该明确自己的需求,包括功能要求、设计风格和用户体
- 厉国刚:新闻学与传播学到底有何区别
微观大道
厉国刚:新闻学与传播学到底有何区别头几天,有人在知乎上问我:新闻学与传播学到底有何区别。他是一位想要跨专业考研的学生,对新闻传播学学科可谓了解甚少,甚至一头雾水,想要让我帮他解释解释。在研究生学硕层面,新闻传播学是一级学科,分成新闻学、传播学这两个二级学科。有些高校,还自设了广告学、出版发行学等其他二级学科,但从官方角度,新闻传播学一级学科下,正统的就是那两个二级学科。招生时,一般会按一级学科招,
- 提高教师信息素养,提高道德与法治课教学效益
长白159宋彦红
提高教师信息素养,提高道德与法治课教学效益随着经济和社会的发展,信息技术已经运用到课堂教学中,为课堂教学展示了一个崭新的天地。的确,信息技术形象、生动、直观性强,能够将课本中的一些抽想的概念直接展示在学生面前,从而调动学生的眼、耳、脑,让他们兴奋起来,变被动学习为主动学习,充分发挥教师的教育引导作用,创造一个可以使学生积极参与的场景。在制作、使用信息技术的实践过程中,本文拟就教师提升信息素养的必要
- 在一起的日子
少些期待
在一起已经三年多了,我是一个97年的摩羯座女生,他是一个89年的同样的摩羯座男生,刚开始是他追的我,我开始对他也挺有好感的,他从他朋友哪里,要到我的电话号,给我发信息,我没理他。然后我们的故事就这样开始了·····我不记得到底是什么,让我对他特别喜欢,想一心一意跟着他过日子,说白了我也就是个他的小跟班,又或者是个小跟屁虫,或者是个保姆,反正就是他在那里,我就得陪他到哪里,谈了半年多对象的时候,他因
- 安徽省这个湖,比西湖大8倍,称是安徽的北戴河, 合肥的后花园
旅游小号角
旅游爱好者都知道,安徽省是一个旅游资源十分丰富的省份,且不说黄山、九华山、天柱山这三大名山,单说湖泊就不比其它省份少,今天我们一起走遍世界将为大家说说一个号称安徽北戴河,合肥后花园的湖泊,看看到底是哪个湖泊?话说,这个湖泊位于安徽省六安市舒城县境内,东距合肥50千米,大约一个小时左右的车程,它号称是合肥的后花园,安徽的北戴河。相传,湖畔石壁之上有一奇石神似观音临湖,湖中漂动众多小岛栩栩如佛子,宛若
- 母亲节如何做小红书营销
美橙传媒
小红书的一举一动引起了外界的高度关注。通过爆款笔记和流行话题,我们可以看到“干货”类型的内容在小红书中偏向实用的生活经验共享和生活指南非常受欢迎。根据运营社的分析,这种现象是由小红书用户心智和内容社区背后机制共同决定的。首先,小红书将使用“强搜索”逻辑为用户提供特定的“搜索场景”。在“我必须这样生活”中,大量使用了满足小红书站用户喜好和需求的内容。内容社区自制的高质量内容也吸引了寻找营销新途径的品
- 二婚到底是领证好还是不领证好?
孟妃青
伟人讲过,不以结婚为目的的谈恋爱,都是耍流氓!离婚了,再找对象,感情到了一定程度,领证结婚是水到渠成的事,再说我中华泱泱大国,有礼仪之邦的称谓,领证更是体现了尊重男女双方的行为。如果认为二婚就没必要领证了,只能说明,男女之间都暗藏心思,心不往一处走,日子过不好的。即便他们感情再深,都不是合法夫妻,只是名不正言不顺的同居关系。假如不要二人共同的孩子还好,就怕有了孩子,没领证,到时给孩子上户口都成问题
- 读书笔记|《遇见孩子,遇见更好的自己》5
抹茶社长
为人父母意味着放弃自己的过去,不要对以往没有实现的心愿耿耿于怀,只有这样,孩子们才能做回自己。985909803.jpg孩子在与父母保持亲密的同时更需要独立,唯有这样,孩子才会成为孩子,父母才会成其为父母。有耐心的人生往往更幸福,给孩子留点余地。认识到养儿育女是对耐心的考验。为失败做好心理准备,教会孩子控制情绪。了解自己的底线,说到底线,有一点很重要,父母之所以发脾气,真正的原因往往在于他们自己,
- Java面试题精选:消息队列(二)
芒果不是芒
Java面试题精选javakafka
一、Kafka的特性1.消息持久化:消息存储在磁盘,所以消息不会丢失2.高吞吐量:可以轻松实现单机百万级别的并发3.扩展性:扩展性强,还是动态扩展4.多客户端支持:支持多种语言(Java、C、C++、GO、)5.KafkaStreams(一个天生的流处理):在双十一或者销售大屏就会用到这种流处理。使用KafkaStreams可以快速的把销售额统计出来6.安全机制:Kafka进行生产或者消费的时候会
- Java:爬虫框架
dingcho
Javajava爬虫
一、ApacheNutch2【参考地址】Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎.为了完成这一宏伟的目标,Nutch必须能够做到:每个月取几十亿网页为这些网页维护一个索引对索引文件进行每秒上千次的搜索提供高质量的搜索结果简单来说Nutch支持分
- 曼妙的盛景掩藏于岁月深处,用一颗清净心寻觅更加温馨的归宿
佳依我心
《大鱼·海棠》中曾这样说道:“只要你的心是善良的,对错都是别人的事。无论你经历过什么,都要活成自己喜欢的模样。对于不喜欢的人和事,要勇敢地拒绝,去追求自己所爱,永远不要丢失本心,永远要保持善良。”小的时候,不懂得什么是好与坏,善与恶,只是觉得拥有笑脸的人应该都是对自己好的,却并不知道那张笑脸的背后到底隐藏着怎样的阴暗与肮脏。不过我依旧相信:人的眼睛不会骗人,每当我看到亮晶晶的双眸,总是会想到它如同
- 离奇的投毒案(七)
蜗居山人
(接上文)庭审很快开始了,李妹坐在旁听席的第一排,她想看看丈夫到底是不是害死儿女的凶手。公诉人宣读起诉书后,审判长询问张春对起诉书指控的犯罪事实是否承认,张春矢口否认,当庭翻供。李妹心中一阵得意:“我早就判断丈夫不是凶手!刑警队弄错了,这下看武队长如何收场!这可是公开审理。”审判长问:“你怎么在公安机关承认犯罪事实呢?”“他们刑讯逼供,没有办法我只能承认。”李妹心里嘟囔:“俺丈夫爱我和孩子胜过爱他
- 屠龙决战沙城怎么才能当托 屠龙决战沙城如何可以申请内部福利号
诸葛村夫123
我2015年从事游戏行业,曾担任某游戏平台的运营负责人。很多朋友玩了一辈子手游可能都还不知道手游托这事儿。你们经常在游戏中遇到那些土豪玩家,进服就充几百,几千的玩家,十有八九都是托,也就是我们常说的内部号。每个人的钱都不是大风刮来的,并不是每个人都舍得在游戏里充这么多钱。那这些内部号的充值到底是哪儿来的呢?其实内部号由于运营商扶持,这种账号一开始就领先普通账号十倍不止。内部号进服运营商会给300-
- 【旅行故事】强个体与好组织相互成就@稀土永磁Amy@20220205@上海
稀土永磁Amy
我们每个人都在组织当中。当你来到组织中,都要理解个体跟组织的关系和组织中个体的关系。一个组织产生高绩效的时候,其实是需要组织个体的发展跟组织发展之间要有一个匹配程度。有时也会看到一个组织当中,一些个体会觉得发展的不够充分,原因就在于个体的发展速度超过了组织的发展速度。还有一些时候我们会发现,组织要淘汰很多个体,原因也在于组织发展的速度超越了个体发展的速度。按照这个逻辑,无论是组织的视角还是个体的视
- 生存还是生活
子非鱼2015
每个人都在忙忙碌碌,像小时候一看就是半天的在墙角来来往往的蚂蚁,每天疲于奔命。上班下班,吃饭睡觉。想做的事未必能做得到,不想做的事却时时刻刻非做不可。我们到底在忙些什么?想要什么?为了什么?生存还是生活?
- 2022-07-06学会放手
杨晓玲乐平市第十一小学
2022年7月5日星期一晴今天结束了国培培训,上午收拾好物品,带着孩子整理心情,带着憧憬去到孩子新的学校,因为从小我有意培养孩子自己整理自己内务,孩子很认真的把自己要用的都整理好,不用的都另外装好,这一点孩子的能力还是挺强的。把自己的行李按学校提出的要求认真的整理好,我们便出发了。我们早早的来到学校,时间还早,便让她到阿姨那休息了一会儿,每去到一个新的地方,能迅速的安顿下来,这是非常好的。时间很快
- ChatGPT 高效学习套路揭秘:让知识获取事半功倍的秘诀
kkai人工智能
chatgpt人工智能学习媒体ai
最近这段时间,AI热潮因ChatGPT的火爆再次掀起。如今,网上大部分内容都在调侃AI,但很少有人探讨如何正经使用ChatGPT做事情。作为一名靠搜索引擎和GitHub自学编程的开发者,第一次和ChatGPT深度交流后,我就确信:ChatGPT能够极大提高程序员学习新技术的效率。使用ChatGPT一个月后,我越发感受到它的颠覆性。因此,我想从工作和学习的角度,分享它的优势及我的一些使用技巧,而非娱
- 27岁儿子不结婚,父亲决定先给自己相亲找个伴:我要给儿子打个样
清白路人
你妈逼你结婚了吗?现在的年轻人普遍结婚都比较晚,有的三十好几了八字还没一撇,这个时候最操心的就是父母了,他们话里话外都是催促着子女找对象结婚,甚至还会用出让人意想不到的方法,其实说到底,这也是可怜天下父母心呐。亲自给儿子打样的大爷李荣国,54岁,离异,打工收入2000多左右,家住农村平房120平。李大爷年轻时一直在工厂和工地打工,4年前才回到村里在镇政府当起了保安。李大爷的收入来自于三个部分,第一
- 【自动化测试】UI自动化的分类、如何选择合适的自动化测试工具以及其中appium的设计理念、引擎和引擎如何工作
Lossya
ui自动化测试工具自动化测试appium
引言UI自动化测试主要针对软件的用户界面进行测试,以确保用户界面元素的交互和功能符合预期文章目录引言一、UI自动化的分类1.1基于代码的自动化测试1.2基于录制/回放的自动化测试1.3基于框架的自动化测试1.4按测试对象分类1.5按测试层次分类1.6按测试执行方式分类1.7按测试目的分类二、如何选择合适的自动化测试工具2.1项目需求分析2.2工具特性评估2.3成本考虑2.4团队技能2.5试用和评估
- 这样旅行的人,值得拥有丰富而饱满的体验
究竟
01“一张车票就实现了来拉萨的梦想。原以为很遥远,现也觉得旅途值得。也不过山河故人而已。”打开朋友圈,看到了强子新发的动态,配了两张图,一张图里是拉萨火车站,另一张图里是二十来张排列得整整齐齐的火车票,终点站都是拉萨。又想起几天前,姑娘秀了一波在青海湖的美照,照片里的她,身穿鲜艳的红色长裙,坐在牦牛背上,阳光打下来,她笑靥如花。橙色的旗子风中飘扬,那蓝绿色的青海湖和天空再美,也都成了陪衬。再看看自
- 华为云分布式缓存服务DCS 8月新特性发布
华为云PaaS服务小智
华为云分布式缓存
分布式缓存服务(DistributedCacheService,简称DCS)是华为云提供的一款兼容Redis的高速内存数据处理引擎,为您提供即开即用、安全可靠、弹性扩容、便捷管理的在线分布式缓存能力,满足用户高并发及数据快速访问的业务诉求。此次为大家带来DCS8月的特性更新内容,一起来看看吧!
- [黑洞与暗粒子]没有光的世界
comsci
无论是相对论还是其它现代物理学,都显然有个缺陷,那就是必须有光才能够计算
但是,我相信,在我们的世界和宇宙平面中,肯定存在没有光的世界....
那么,在没有光的世界,光子和其它粒子的规律无法被应用和考察,那么以光速为核心的
&nbs
- jQuery Lazy Load 图片延迟加载
aijuans
jquery
基于 jQuery 的图片延迟加载插件,在用户滚动页面到图片之后才进行加载。
对于有较多的图片的网页,使用图片延迟加载,能有效的提高页面加载速度。
版本:
jQuery v1.4.4+
jQuery Lazy Load v1.7.2
注意事项:
需要真正实现图片延迟加载,必须将真实图片地址写在 data-original 属性中。若 src
- 使用Jodd的优点
Kai_Ge
jodd
1. 简化和统一 controller ,抛弃 extends SimpleFormController ,统一使用 implements Controller 的方式。
2. 简化 JSP 页面的 bind, 不需要一个字段一个字段的绑定。
3. 对 bean 没有任何要求,可以使用任意的 bean 做为 formBean。
使用方法简介
- jpa Query转hibernate Query
120153216
Hibernate
public List<Map> getMapList(String hql,
Map map) {
org.hibernate.Query jpaQuery = entityManager.createQuery(hql);
if (null != map) {
for (String parameter : map.keySet()) {
jp
- Django_Python3添加MySQL/MariaDB支持
2002wmj
mariaDB
现状
首先,
[email protected] 中默认的引擎为 django.db.backends.mysql 。但是在Python3中如果这样写的话,会发现 django.db.backends.mysql 依赖 MySQLdb[5] ,而 MySQLdb 又不兼容 Python3 于是要找一种新的方式来继续使用MySQL。 MySQL官方的方案
首先据MySQL文档[3]说,自从MySQL
- 在SQLSERVER中查找消耗IO最多的SQL
357029540
SQL Server
返回做IO数目最多的50条语句以及它们的执行计划。
select top 50
(total_logical_reads/execution_count) as avg_logical_reads,
(total_logical_writes/execution_count) as avg_logical_writes,
(tot
- spring UnChecked 异常 官方定义!
7454103
spring
如果你接触过spring的 事物管理!那么你必须明白 spring的 非捕获异常! 即 unchecked 异常! 因为 spring 默认这类异常事物自动回滚!!
public static boolean isCheckedException(Throwable ex)
{
return !(ex instanceof RuntimeExcep
- mongoDB 入门指南、示例
adminjun
javamongodb操作
一、准备工作
1、 下载mongoDB
下载地址:http://www.mongodb.org/downloads
选择合适你的版本
相关文档:http://www.mongodb.org/display/DOCS/Tutorial
2、 安装mongoDB
A、 不解压模式:
将下载下来的mongoDB-xxx.zip打开,找到bin目录,运行mongod.exe就可以启动服务,默
- CUDA 5 Release Candidate Now Available
aijuans
CUDA
The CUDA 5 Release Candidate is now available at http://developer.nvidia.com/<wbr></wbr>cuda/cuda-pre-production. Now applicable to a broader set of algorithms, CUDA 5 has advanced fe
- Essential Studio for WinRT网格控件测评
Axiba
JavaScripthtml5
Essential Studio for WinRT界面控件包含了商业平板应用程序开发中所需的所有控件,如市场上运行速度最快的grid 和chart、地图、RDL报表查看器、丰富的文本查看器及图表等等。同时,该控件还包含了一组独特的库,用于从WinRT应用程序中生成Excel、Word以及PDF格式的文件。此文将对其另外一个强大的控件——网格控件进行专门的测评详述。
网格控件功能
1、
- java 获取windows系统安装的证书或证书链
bewithme
windows
有时需要获取windows系统安装的证书或证书链,比如说你要通过证书来创建java的密钥库 。
有关证书链的解释可以查看此处 。
public static void main(String[] args) {
SunMSCAPI providerMSCAPI = new SunMSCAPI();
S
- NoSQL数据库之Redis数据库管理(set类型和zset类型)
bijian1013
redis数据库NoSQL
4.sets类型
Set是集合,它是string类型的无序集合。set是通过hash table实现的,添加、删除和查找的复杂度都是O(1)。对集合我们可以取并集、交集、差集。通过这些操作我们可以实现sns中的好友推荐和blog的tag功能。
sadd:向名称为key的set中添加元
- 异常捕获何时用Exception,何时用Throwable
bingyingao
用Exception的情况
try {
//可能发生空指针、数组溢出等异常
} catch (Exception e) {
- 【Kafka四】Kakfa伪分布式安装
bit1129
kafka
在http://bit1129.iteye.com/blog/2174791一文中,实现了单Kafka服务器的安装,在Kafka中,每个Kafka服务器称为一个broker。本文简单介绍下,在单机环境下Kafka的伪分布式安装和测试验证 1. 安装步骤
Kafka伪分布式安装的思路跟Zookeeper的伪分布式安装思路完全一样,不过比Zookeeper稍微简单些(不
- Project Euler
bookjovi
haskell
Project Euler是个数学问题求解网站,网站设计的很有意思,有很多problem,在未提交正确答案前不能查看problem的overview,也不能查看关于problem的discussion thread,只能看到现在problem已经被多少人解决了,人数越多往往代表问题越容易。
看看problem 1吧:
Add all the natural num
- Java-Collections Framework学习与总结-ArrayDeque
BrokenDreams
Collections
表、栈和队列是三种基本的数据结构,前面总结的ArrayList和LinkedList可以作为任意一种数据结构来使用,当然由于实现方式的不同,操作的效率也会不同。
这篇要看一下java.util.ArrayDeque。从命名上看
- 读《研磨设计模式》-代码笔记-装饰模式-Decorator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.io.BufferedOutputStream;
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.Fi
- Maven学习(一)
chenyu19891124
Maven私服
学习一门技术和工具总得花费一段时间,5月底6月初自己学习了一些工具,maven+Hudson+nexus的搭建,对于maven以前只是听说,顺便再自己的电脑上搭建了一个maven环境,但是完全不了解maven这一强大的构建工具,还有ant也是一个构建工具,但ant就没有maven那么的简单方便,其实简单点说maven是一个运用命令行就能完成构建,测试,打包,发布一系列功
- [原创]JWFD工作流引擎设计----节点匹配搜索算法(用于初步解决条件异步汇聚问题) 补充
comsci
算法工作PHP搜索引擎嵌入式
本文主要介绍在JWFD工作流引擎设计中遇到的一个实际问题的解决方案,请参考我的博文"带条件选择的并行汇聚路由问题"中图例A2描述的情况(http://comsci.iteye.com/blog/339756),我现在把我对图例A2的一个解决方案公布出来,请大家多指点
节点匹配搜索算法(用于解决标准对称流程图条件汇聚点运行控制参数的算法)
需要解决的问题:已知分支
- Linux中用shell获取昨天、明天或多天前的日期
daizj
linuxshell上几年昨天获取上几个月
在Linux中可以通过date命令获取昨天、明天、上个月、下个月、上一年和下一年
# 获取昨天
date -d 'yesterday' # 或 date -d 'last day'
# 获取明天
date -d 'tomorrow' # 或 date -d 'next day'
# 获取上个月
date -d 'last month'
#
- 我所理解的云计算
dongwei_6688
云计算
在刚开始接触到一个概念时,人们往往都会去探寻这个概念的含义,以达到对其有一个感性的认知,在Wikipedia上关于“云计算”是这么定义的,它说:
Cloud computing is a phrase used to describe a variety of computing co
- YII CMenu配置
dcj3sjt126com
yii
Adding id and class names to CMenu
We use the id and htmlOptions to accomplish this. Watch.
//in your view
$this->widget('zii.widgets.CMenu', array(
'id'=>'myMenu',
'items'=>$this-&g
- 设计模式之静态代理与动态代理
come_for_dream
设计模式
静态代理与动态代理
代理模式是java开发中用到的相对比较多的设计模式,其中的思想就是主业务和相关业务分离。所谓的代理设计就是指由一个代理主题来操作真实主题,真实主题执行具体的业务操作,而代理主题负责其他相关业务的处理。比如我们在进行删除操作的时候需要检验一下用户是否登陆,我们可以删除看成主业务,而把检验用户是否登陆看成其相关业务
- 【转】理解Javascript 系列
gcc2ge
JavaScript
理解Javascript_13_执行模型详解
摘要: 在《理解Javascript_12_执行模型浅析》一文中,我们初步的了解了执行上下文与作用域的概念,那么这一篇将深入分析执行上下文的构建过程,了解执行上下文、函数对象、作用域三者之间的关系。函数执行环境简单的代码:当调用say方法时,第一步是创建其执行环境,在创建执行环境的过程中,会按照定义的先后顺序完成一系列操作:1.首先会创建一个
- Subsets II
hcx2013
set
Given a collection of integers that might contain duplicates, nums, return all possible subsets.
Note:
Elements in a subset must be in non-descending order.
The solution set must not conta
- Spring4.1新特性——Spring缓存框架增强
jinnianshilongnian
spring4
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- shell嵌套expect执行命令
liyonghui160com
一直都想把expect的操作写到bash脚本里,这样就不用我再写两个脚本来执行了,搞了一下午终于有点小成就,给大家看看吧.
系统:centos 5.x
1.先安装expect
yum -y install expect
2.脚本内容:
cat auto_svn.sh
#!/bin/bash
- Linux实用命令整理
pda158
linux
0. 基本命令 linux 基本命令整理
1. 压缩 解压 tar -zcvf a.tar.gz a #把a压缩成a.tar.gz tar -zxvf a.tar.gz #把a.tar.gz解压成a
2. vim小结 2.1 vim替换 :m,ns/word_1/word_2/gc
- 独立开发人员通向成功的29个小贴士
shoothao
独立开发
概述:本文收集了关于独立开发人员通向成功需要注意的一些东西,对于具体的每个贴士的注解有兴趣的朋友可以查看下面标注的原文地址。
明白你从事独立开发的原因和目的。
保持坚持制定计划的好习惯。
万事开头难,第一份订单是关键。
培养多元化业务技能。
提供卓越的服务和品质。
谨小慎微。
营销是必备技能。
学会组织,有条理的工作才是最有效率的。
“独立
- JAVA中堆栈和内存分配原理
uule
java
1、栈、堆
1.寄存器:最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制.2. 栈:存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在堆(new 出来的对象)或者常量池中(字符串常量对象存放在常量池中。)3. 堆:存放所有new出来的对象。4. 静态域:存放静态成员(static定义的)5. 常量池:存放字符串常量和基本类型常量(public static f