python|爬虫|爬取豆瓣自己账号下的观影记录并可视化
提示:可以使用anaconda 创建爬虫专用的环境,再从pycharm里新建工程添加虚拟环境
文章目录
- 前言
- 一、爬虫部分
-
- 1. 程序思路
- 2. 代码部分
- 2.1 导入库
- 2.2 登陆豆瓣(selenium库)
- 2.3 模拟点击,进入目标页(selenium)
- 2.4 正式开爬 (request、xpath、pandas)
- 三 、数据可视化(Tableau)
-
- 3.1 观影类型饼状图、环状图、词云图
- 3.2 所看电影数量及分布图
- 四、总结
前言
本文主要讲述了如何使用python爬取豆瓣网自己账号下的观影记录,并进行简单的分析
提示:以下是本篇文章正文内容,没有用到scrpy框架,仅供参考娱乐。
一、爬虫部分
1. 程序思路
首先,打开豆瓣首页,找到登陆部分,发现需要切换登陆方式,需选择密码登陆方式(PS:不需要验证码,嘿嘿!),登陆进去需要点击网页导航栏的“我的豆瓣”,跳转之后再点击“看过的电影”,然后就是脚本翻页爬取电影,另存成csv导出了


2. 代码部分
2.1 导入库
from selenium import webdriver
import time
import requests
from lxml import etree
import pandas as pd
import numpy as np
2.2 登陆豆瓣(selenium库)
browser_object = webdriver.Chrome() # 选择Chrome
browser_object.maximize_window() # 最大化窗口
browser_object.get('https://www.douban.com') # 传入豆瓣网址
# 定位frame 因为这是登陆界面是嵌在整个网页当中
iframe_element = browser_object.find_element_by_tag_name('iframe')
browser_object.switch_to.frame(iframe_element)
button = browser_object.find_element_by_xpath('//li[text()="密码登录"]')
button.click()
user_name = browser_object.find_element_by_xpath('//*[@id="username"]')
user_name.clear()
user_name.send_keys('你的账号')
password = browser_object.find_element_by_xpath('//*[@id="password"]')
password.clear()
password.send_keys('你的密码')
login_button = browser_object.find_element_by_xpath("//a[text()='登录豆瓣']")
login_button.click()
time.sleep(2)
推荐Chrome浏览器,右键检查,点左上箭头,想知道哪里的xpath就点哪里,再选择右键复制,或者也可以看标签手写录入(本文手写、复制都用到了)
这里要睡个2秒,不然没等新页面打开,下面程序就会执行并报错
这里是强制延时方法(比较懒),还有隐式和显式共三种,各有优劣,可以自己百度。
2.3 模拟点击,进入目标页(selenium)
browser_object.find_element_by_xpath('//*[@id="db-nav-sns"]/div/div/div[3]/ul/li[2]/a').click()
time.sleep(2)
browser_object.find_element_by_xpath('//*[@id="movie"]/h2/span/a[2]').click()
time.sleep(2)
# 获取打开页的所有页柄,切换到最新打开的
handles = browser_object.window_handles
browser_object.switch_to.window(handles[-1])
time.sleep(2)
这里的延时时间自己估摸着填,一两秒足够了
2.4 正式开爬 (request、xpath、pandas)
def l_j(a, b, c): # 定义一个连接三个dataframe的函数
d = pd.concat([a, b, c], axis=1)
return d
film_name = []
film_see_time = []
film_star = []
for i in range(0, 10):
if i == 0:
web_ad = browser_object.current_url
cookies = browser_object.get_cookies()
cookie_dict = {
}
for j in cookies:
cookie_dict[j["name"]] = j["value"]
ua_pretend = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
react_data = requests.get(url=web_ad, headers=ua_pretend, cookies=cookie_dict).text
analysis = etree.HTML(react_data)
film_name.append(analysis.xpath('//li/a/em/text()'))
film_name = film_name[0]
df1 = pd.DataFrame(film_name)
film_see_time.append(analysis.xpath('//li/span[@class="date"]/text()'))
film_see_time = film_see_time[0]
df2 = pd.DataFrame(film_see_time)
film_star.append(analysis.xpath('//li[3]//@class'))
film_star = film_star[0]
film_star = [i for i in film_star if 'rating' in i]
film_star = [i.split('-')[-2][-1] for i in film_star]
df3 = pd.DataFrame(film_star)
f_l = pd.concat([df1, df2, df3], axis=1)
f_l.to_csv('G:/my_db_film.csv', header=['电影名称', '观影时间', '评价星级'], index=False, encoding='ANSI', mode='a')
else:
film_name = []
film_see_time = []
film_star = []
browser_object.find_element_by_xpath(f'//*[@id="content"]/div[2]/div[1]/div[3]/a[{i}]').click()
time.sleep(2)
web_ad = browser_object.current_url
ua_pretend = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
react_data = requests.get(url=web_ad, headers=ua_pretend, cookies=cookie_dict).text
analysis = etree.HTML(react_data)
film_name.append(analysis.xpath('//li/a/em/text()'))
film_name = film_name[0]
film_name = [i.split('/')[0] for i in film_name]
df1 = pd.DataFrame(film_name)
film_see_time.append(analysis.xpath('//li/span[@class="date"]/text()'))
film_see_time = film_see_time[0]
df2 = pd.DataFrame(film_see_time)
film_star.append(analysis.xpath('//li[3]//@class'))
film_star = film_star[0]
film_star = [i for i in film_star if 'rating' in i]
film_star = [i.split('-')[0][-1] for i in film_star]
df3 = pd.DataFrame(film_star)
new = l_j(df1, df2, df3)
new = np.array(new)
new = pd.DataFrame(new)
new.to_csv('G:/my_db_film.csv', header=False, index=False, encoding='ANSI', mode='a')
这里分成两步来,首页和其他页,总页数偷懒选择手输10,分别用三个列表保存爬取的电影名称,观看时间,评价星级,并用pandas的方法保存成csv文件
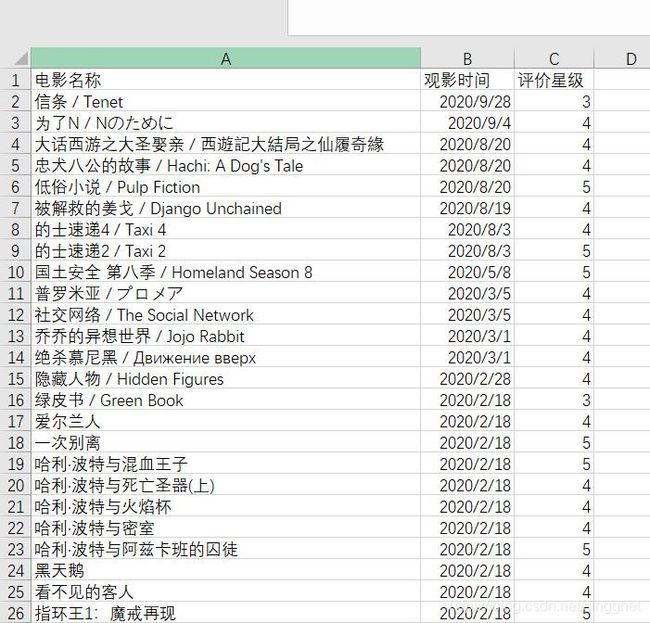
这里有几个坑,①提取电影名的时候利用split方法只提取中文名和英文名,其他语言因为编码格式问题容易报错,②记得所有的电影自己已经给出了星级评价!!
三 、数据可视化(Tableau)
利用Tableau,导入本地csv文件,进行数据可视化。(这里我有直接爬过的豆瓣榜单csv数据,有电影类型、上映时间、地区等信息之类的,直接两表连接一下)
3.1 观影类型饼状图、环状图、词云图



这里电影数量变少了,是因为有一些电影比较冷门并不在热门电影榜单上。
3.2 所看电影数量及分布图

四、总结
这个爬虫项目大概前前后后花了一周多的时间,一边学习一边动手实现,特别感谢B站孙兴华老师的爬虫和其他相关课程,强烈推荐基础薄弱的同学去观看学习,还有OneNote笔记。